顺网Java

不足:
1、JVM垃圾回收、Gc Roots、垃圾回收器
2、HashMap如何实现线程安全;
3、数据库引擎,聚集索引和非聚集索引
4、CAS操作:cmpxchg
1、Java内存结构:五大组成:
线程共享:方法区、堆;
线程私有:虚拟机栈、本地方法栈、程序计数器
(Java内存模型;为了屏蔽不同平台底层细节所制定的规范,作用是:保证在Java层面上的操作再不同平台上能够产生相同的结果)
(Java内存模型的内容是:所有的变量保存在主内存中,每个线程拥有自己的工作内存,线程的工作内存中保留了,线程所使用到的变量的从主内存中来的副本,线程对变量的所有操作都是在自己的工作内存中进行,不能直接读写主内存中的变量,不同的线程之间也无法访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成)
(volatile:可见性+防止指令重排序)
2、类加载过程:细分五个过程:加载、验证、准备、解析、初始化
加载:全限定名、二进制字节流、生成代表这个类的java.lang.Class对象,作为这个类的数据访问入口
验证(连接第一阶段):确保被加载的类满足Java虚拟机规范,不会造成安全错误
准备(连接第二阶段):为类的静态成员分配内存,并设置默认初始值
解析(连接第三阶段):符号引用转化为直接引用
初始化:为静态变量分配正确的初始值,按指定顺序执行代码块
3、HashMap的hash()函数,生成扰动后的哈希值,增加随机性
return (h=key.hashCode())^h>>>16; //无符号右移
底层结构:1.7 数组+链表;1.8 数组+链表+红黑树
不是线程安全的;1.7,头插法,并发扩容,数据丢失+死循环;1.8,尾插法,并发插入,数据覆盖
如何线程安全:首选ConcurrentHashMap,HashTable,Collections.synchronizedMap()包装成线程安全的map对象
4、用synchorizedMap并发怎么样
synchronizedMap是Collections这个集合工具类的一个静态内部类,采用synchronized代码块的方式实现线程安全
5、ConcurrentHashMap如何线程安全
1.7,分段锁;Segments数组+HashEntry数组+链表,对Segments数组中元素上锁
1.8,synchronized + CAS;Node数组+链表+红黑树,在put过程中可能会对Node节点上锁,如果为null,则CAS插入,否则对链表头节点或红黑树根结点上synchronized锁
注意:get()操作都不用上锁,因为是用value和next指针都用volatile关键字修饰
6、CopyOnWriteArrayList具体实现:
它采用复制底层数组的方式来实现写操作;
当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞;
当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作;
由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的;
在所有线程安全的List中,它是性能最优的方案
7、LinkedList
底层:双向链表
具有链表的插入删除快的优点
既可以作为队列,也可以作为栈来使用
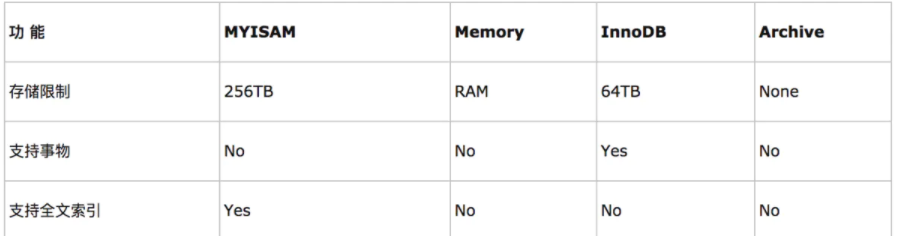
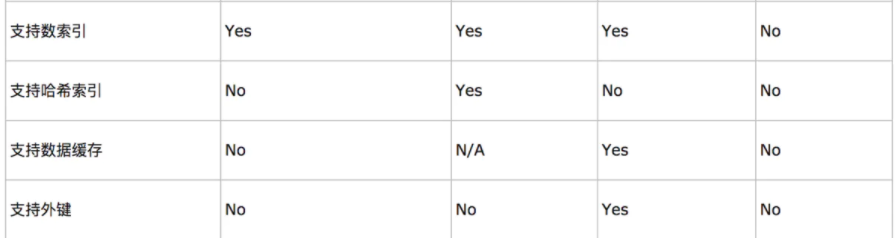
8、MySql
数据库引擎:InnoDB,事务型数据库的首选;MyISAM;MEMORY,Archive
只有InnoDB支持事务操作,和外键
9、数据库的索引:避免进行全表扫描,提高数据查找的速度,在经常需要搜索的列上建立索引,可以加快索引的速度
.可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性
mysql的索引分为 单列索引(主键索引,唯一索引,普通索引) 和 组合索引
单列索引:一个索引只包含一个列,一个表可以有多个单列索引
-
普通索引:普通索引的唯一任务是加快对数据的访问速度;普通索引允许被索引的数据列包含重复的值
-
唯一索引:如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用 关键字UNIQUE 把它定义为一个唯一索引;唯一索引能控制该列不能有相同值
-
主键索引:不允许有空值
组合索引:一个组合索引包含两个或两个以上的列
关于普通复合索引index这里就不再详细执行截图描述,只需要注意下面这形式的索引意义就OK了!!!!
当建立复合索引index(column1,column2,column3),这就相当于建立了以下三个索引:
index(column1),
index(column1,column2)
index(column1,column2,column3) // 跟三个字段的顺序没有关系 比如:index(column3,column1,column2),它们是一样的效果
聚集索引与非聚集索引:聚集索引:索引的逻辑顺序与物理顺序相同;非聚集索引:索引的逻辑顺序与物理排列顺序无关(通过一个指针指向真实的数据地址)
Myisam:.frm .myi .myb
InnoDB:.frm .ibd(索引和数据合并文件)
聚集索引:按照每张表的主键构建一棵B+树,同时叶子节点中存放的就是整张表的行记录数据;InnoDB通过主键聚集数据,如果没有定义主键,InnoDB也可以隐式地定义一个主键来聚集索引


B+树:B+树也是一棵多路平衡查找树;查询的时间复杂度O(log n)
只有叶子节点存储data,叶子节点包含了这棵树的所有数据,所有的叶子节点使用链表相连,便于区间查找和遍历,所有的非叶子节点起到了索引作用
对于一个 m 阶的 B+ 树:
1、关键字范围:根节点[1,m-1] 非根节点[m/2,m-1]
2、B+树中非叶子节点不存储数据,只存储索引,数据都存储在叶子节点中
3、对于非叶子节点中key都按照从小到大的顺序排列,非叶子节点中的每一个key,都会出现在子节点中,是子节点中最大或最小元素;叶子节点中的记录也按照key从小到大排列
4、叶子节点依据关键字的大小从小到大顺序链接,形成一个有序链表
5、每个结点至多有m个子女;除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女;有k个子女的结点必有k个关键字
6、所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同
最左匹配原则:最左优先,以最左边的为起点,任何连续的索引都能匹配上;同时遇到范围查询(>、<、between、like)就会停止匹配
10、CAS
底层使用CMPXCHG指令;
CAS 操作包含三个操作数 —— 内存位置(V)、预期值(A)和 新值(B)
如果内存位置V的值与预期值A相匹配,那么处理器会自动将该位置值更新为新值B;否则,处理器不做任何操作
通常将 CAS 用于同步的方式是从地址 V 读取值 A,执行多步计算来获得新 值 B,然后使用 CAS 将 V 的值从 A 改为 B。如果 V 处的值尚未同时更改,任然为B ,则 CAS 操作成功
缺点:ABA问;长时间不成功的CAS操作,增大系统开销;只能保证一个共享变量的原子操作


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程