
转载自: Java遍历List四种方法的效率对比
感觉这篇文章总结的很好,从底层原理讲的。懒得总结了,直接搬来了。建议直接看原文!!!
总结
(1)对于ArrayList和LinkedList,在size小于1000时,每种方式的差距都在几ms之间,差别不大,选择哪个方式都可以。
(2)对于ArrayList,无论size是多大,差距都不大,选择哪个方式都可以。
(3)对于LinkedList,当size较大时,建议使用迭代器或for-each的方式进行遍历,否则效率会有较明显的差距。
所以,综合来看,建议使用for-each,代码简洁,性能也不差。
另外,当效率不是重点时,应该在设计上花更多心思了。实际上,把大量对象放到List里面去,本身就应该是要考虑的问题。
Java遍历List四种方法的效率对比
遍历方法简介
Java遍历List的方法主要有:
(1)for each
for(bject o :list)
{
}
(2)Iterator
Iterator iter = list.iterator();
while(iter.hasNext()){
Object o = iter.next();
}
(3)loop without size
int size = list.size();
for(int i=0;i<size;i++){
Object o= list.get(i);
}
(4)loop with size
for(int i=0;i<list.size();i++){
Object o= list.get(i);
}
注:这里我们不比较while和for的形式,这对效率影响几乎是可以忽略的。
我们是否能简单的得出结论,哪个更快,哪个更慢呢?
严谨一点的方法是:基于实验与数据,才能作出判断。
ArrayList测试分析
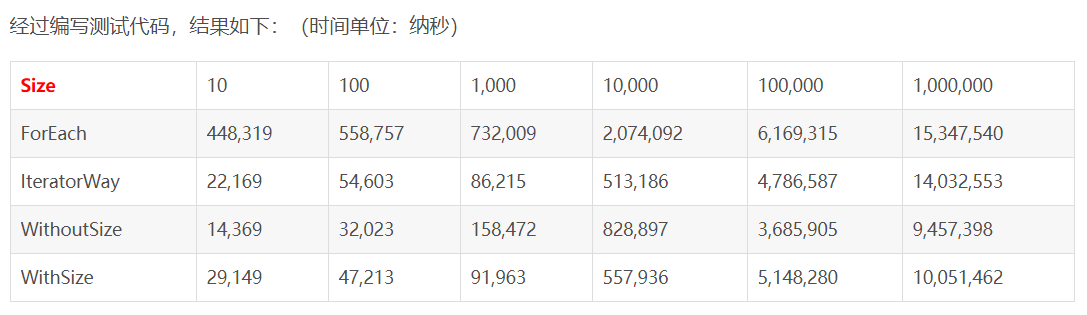
经过编写测试代码,结果如下:(时间单位:纳秒)
可以看出,直接用循环的方法,get(index)来获取对象,是最快的方式。而且把i<list.size()放到循环中去判断,会影响效率。
For Each的效率最差,用迭代器的效率也没有很好。但只是相对而言,其实从时间上看最多也就差几毫秒。
然而,这并不是事实的全部真相!!!
上面的测试,我们只是用了ArrayList来做为List的实现类。所以才有上面的结论。
For each其实也是用了迭代器来实现,因此当数据量变大时,两者的效率基本一致。也因为用了迭代器,所以速度上受了影响。不如直接get(index)快。
那为何get(index)会比较快呢?
因为ArrayList是通过动态数组来实现的,支持随机访问,所以get(index)是很快的。迭代器,其实也是通过数组名+下标来获取,而且增加了逻辑,自然会比get(index)慢。
看ArrayList的迭代器的源代码就清楚了:
public boolean hasNext()
{
return cursor != size;
}
public Object next()
{
checkForComodification();
int i = cursor;
if(i >= size)
throw new NoSuchElementException();
Object aobj[] = elementData;
if(i >= aobj.length)
{
throw new ConcurrentModificationException();
} else
{
cursor = i + 1;
return aobj[lastRet = i];
}
}
LinkedList测试分析
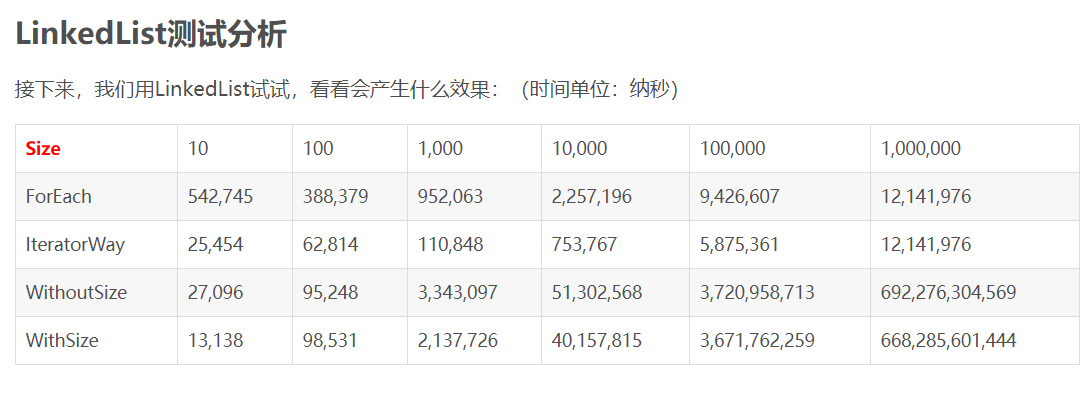
结果确实不简单,跟ArrayList完全不一样了。
最突出的就是get(index)的方式,随着size的增加,急剧上升。到10万数据量时,光遍历时间都要三四秒,这是很可怕的。
那为何会有这样的结果呢?还是和LinkedList的实现方式有关。
LinkedList是通过双向链表实现的,无法支持随机访问。当你要向一个链表取第index个元素时,它需要二分后从某一端开始找,一个一个地数才能找到该元素。这样一想,就能明白为何get(index)如此费时了。
public Object get(int i)
{
checkElementIndex(i);
return node(i).item;
}
Node node(int i)
{
if(i < size >> 1)
{
Node node1 = first;
for(int j = 0; j < i; j++)
node1 = node1.next;
return node1;
}
Node node2 = last;
for(int k = size - 1; k > i; k--)
node2 = node2.prev;
return node2;
}
而迭代器提供的是获取下一个的方法,时间复杂度为O(1),所以会比较快。
public boolean hasNext()
{
return nextIndex < size;
}
public Object next()
{
checkForComodification();
if(!hasNext())
{
throw new NoSuchElementException();
} else
{
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
}
看这迭代器的源代码还是很理解的。
总结
(1)对于ArrayList和LinkedList,在size小于1000时,每种方式的差距都在几ms之间,差别不大,选择哪个方式都可以。
(2)对于ArrayList,无论size是多大,差距都不大,选择哪个方式都可以。
(3)对于LinkedList,当size较大时,建议使用迭代器或for-each的方式进行遍历,否则效率会有较明显的差距。
所以,综合来看,建议使用for-each,代码简洁,性能也不差。
另外,当效率不是重点时,应该在设计上花更多心思了。实际上,把大量对象放到List里面去,本身就应该是要考虑的问题。
至于Vector或Map,就留给感兴趣的人去验证了。
系统信息
最后,附上系统信息:
-- listing properties --
java.vm.version=25.65-b01
java.vm.name=Java HotSpot(TM) 64-BitServer VM
java.runtime.version=1.8.0_65-b17
os.arch=amd64
os.name=Windows 10
java version"1.8.0_66"
Java(TM) SERuntime Environment (build 1.8.0_66-b18)
JavaHotSpot(TM) Client VM (build 25.66-b18, mixed mode)

