

五大组件
Eureka服务注册与发现
-
服务治理
在传统的RPC远程调用框架中,管理每个服务与服务之间的依赖关系比较复杂,管理也复杂,所以需要使用服务治理,管理服务于服务之间依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
-
服务注册
由于Eureka采用CS的设计架构,Eureka Server 作为服务注册功能的服务器,它是服务注册中心。而系统的其他微服务,使用Eureka连接到Eureka Server并维持心跳连接。这样子系统的维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常运行。
在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息 比如:服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者|服务提供者),以该别名的方式去注册中心获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用自己框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在如何RPC远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址))
Eureka系统架构和Dubbo的架构对比
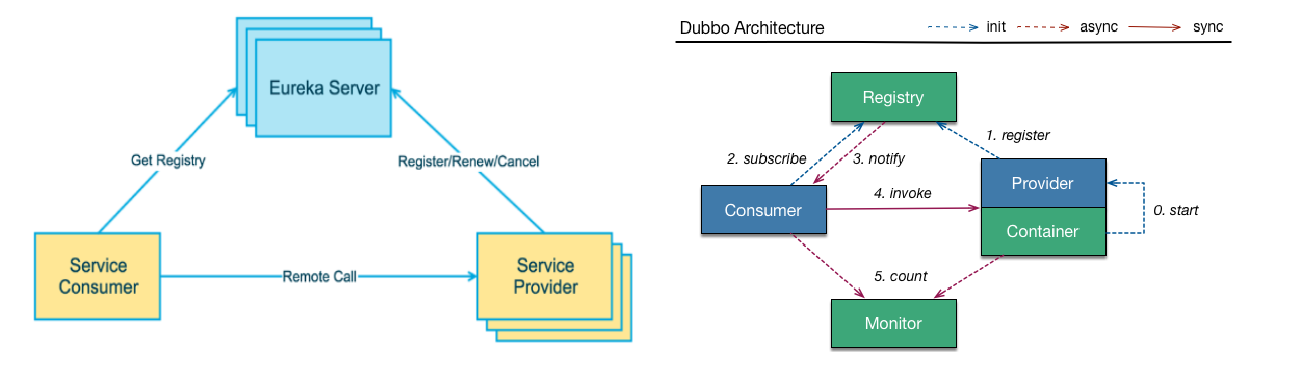
-
Eureka的保护模式
概述:保护模式主要用于一组客户端和Eureka Server之间存在网络分区场景下的保护。一旦进入保护模式,Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据,也就是不会注销任何微服务。属于CAP里面的AP分支。

在Eureka Server首页看到这段提示,说明Eureka进入保护模式。
导致原因
-
为什么会产生Eureka自我保护机制?
为了防止EurekaClient可以正常运行,但是与EurekaServer网络不通的情况下,EurekaServer不会立刻将EurekaClient服务剔除
-
什么是自我保护模式?
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为就变得很危险--因为微服务本身是健康的,此时不应该注销这个微服务。Eureka通过"自我保护模式"来解决这个问题--当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。
在自我保护模式中,Eureka Server会保护注册表中的信息,不在注销任何服务实例。设计的哲学就是宁可保留错误的服务注册信息,也不盲目注销任何健康的服务实例。自我保护模式是一种应对网络异常的安全保护措施。使用自我保护模式,可以让Eureka集群更加的健壮、稳定。
#关闭自我保护机制,保证不可用服务被及时踢除
enable-self-preservation
-
Ribbon 负载均衡服务调用
-
概述
Ribbon是Netfix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。
-
LB(负载均衡)
-
集中式LB
即在服务的消费方和提供方之间使用独立的LB设施(可以是硬件,如F5,也可以是软件,如Nginx),有该设施负责把访问请求通过某种策略转发至服务的提供方。
-
进程内LB
将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。Ribbon就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址。
-
-
Ribbon架构说明
Ribbon在工作时分为两步:
-
先选择EurekaServer,它优先选择在同一个区域内负载较少的server。
-
再根据用户指定的策略,在从server取到的服务注册列表中获取一个地址。
Ribbon提供了多种策略:比如轮询、随机和根据响应时间加权。
Ribbon = 负载均衡 + RestTemplate调用

-
-
RestTemplate方法
返回对象为响应体中数据转化成的对象,可以理解为JSON
restTemplate.getForObject();
返回对象为ResponseEntity对象,包含了响应中的一些重要信息,比如响应头、响应状态码、响应体等
restTemplate.getForEntity)(); -
核心组件IRule
根据特定算法中从服务列表选取一个要访问的服务
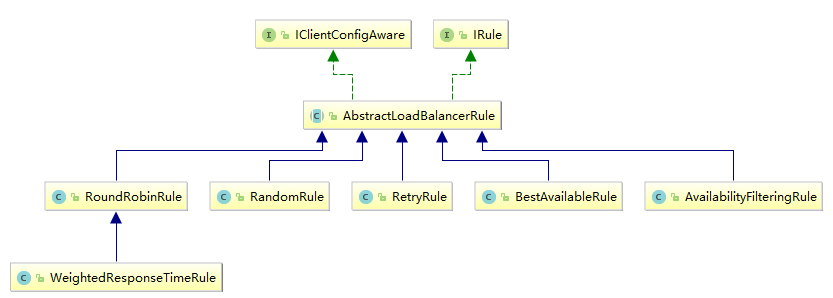
com.netflix.loadbalancer.RoundRobinRule ---- 轮询
com.netflix.loadbalancer.RandomRule ---- 随机
com.netflix.loadbalancer.RetryRule ---- 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务
WeightedResponseTimeRule ---- 对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
BestAvailableRule ---- 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
AvailabilityFilteringRule ---- 先过滤掉故障实例,再选择并发较小的实例
ZoneAvoidanceRule ---- 默认规则,复合判断server所在区域的性能和server的可用性选择服务器
需要更换特定算法:
主启动类添加 -
负载均衡算法
rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始。
OpenFeign服务接口调用
-
概述
Feign是一个声明式WebService客户端,让编写Web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可。
-
Feign的功能
-
使编写Java Http客户端变得更容易
-
在使用Ribbon+RestTemplate时,利用RestTemplate对http请求的封装处理,形成了一套模版化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring cloud Ribbon时,自动封装服务调用客户端的开发量
-
Feign集成了Ribbon,利用Ribbon维护了Payment的服务列表信息,并且通过轮询实现了客户端的负载均衡。而与Ribbon不同的是,通过feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
-
-
Feign和OpenFeign的区别

Feign自带负载均衡配置项
-
使用方式
接口 + 注解 (微服务调用接口+@FeignClient)
在主启动类上加@EnableFeignClients,在业务类上加@FeignClient
-
OpenFeign超时控制
默认Feign客户端只等待一秒钟,但是服务器处理需要超过一秒钟,导致Feign客户端不想等待了,直接返回报错。为了避免这样的情况,需要设置Feign客户端的超时控制。
#设置feign客户端超时时间(OpenFeign默认支持ribbon)
ribbon -
OpenFeign日志打印功能
-
概述
Feign提供了日志打印功能,我们可以通过配置来调整日志级别,对Feign接口的调用情况进行监控和输出。
-
日志级别
-
NONE:默认的,不显示任何日志;
-
BASIC:仅记录请求方法,URL、响应状态码及执行时间;
-
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息;
-
FULL:除了HEADRS中定义的信息之外,还有请求和响应的正文及元数据。
-
-
Yaml需要开启日志的Feign
logging
-
Hystrix断路器
分布式系统面临的问题
复制分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。 所以, 通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
-
Hystrix概述
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
-
Hystrix重要概念
-
服务降级
服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
哪些情况会发生降级?
-
程序运行异常
-
超时
-
服务熔断触发服务降级
-
线程池/信号量打满
降级配置:@HystrixCommand
-
-
服务熔断
熔断机制概述 熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时, 会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示
服务的降级->进而熔断->恢复调用链路
在主方法添加:@EnableCircuitBreaker #对hystrix熔断机制的支持
-
熔断打开
请求不再进行调用当前服务,内部设置时钟一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态
-
熔断关闭
熔断关闭不会对服务进行熔断
-
熔断半开
部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
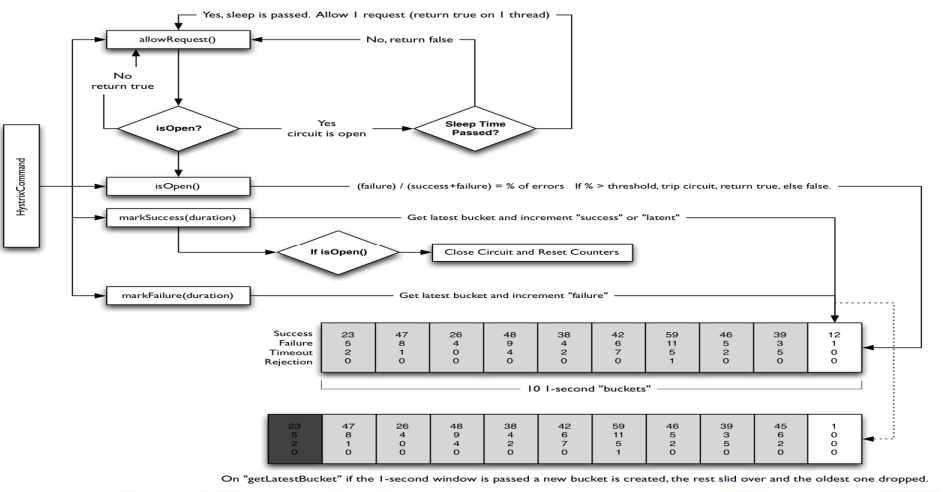
涉及到断路器的三个重要参数:快照时间窗、请求总数阀值、错误百分比阀值。
1:快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
2:请求总数阀值:在快照时间窗内,必须满足请求总数阀值才有资格熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
3:错误百分比阀值:当请求总数在快照时间窗内超过了阀值,比如发生了30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阀值情况下,这时候就会将断路器打开。
断路器开启或者关闭的条件
1.当满足一定的阀值的时候(默认10秒内超过20个请求次数)
2.当失败率达到一定的时候(默认10秒内超过50%的请求失败)
3.到达以上阀值,断路器将会开启
4.当开启的时候,所有请求都不会进行转发
5.一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
断路器打开之后
1:再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
2:原来的主逻辑要如何恢复呢?
对于这一问题,hystrix也为我们实现了自动恢复功能。
当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,
当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,
主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
ALL配置
@HystrixCommand(fallbackMethod = "str_fallbackMethod",
groupKey = "strGroupCommand",
commandKey = "strCommand",
threadPoolKey = "strThreadPool",
commandProperties = {
// 设置隔离策略,THREAD 表示线程池 SEMAPHORE:信号池隔离
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
// 当隔离策略选择信号池隔离的时候,用来设置信号池的大小(最大并发数)
@HystrixProperty(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 配置命令执行的超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutinMilliseconds", value = "10"),
// 是否启用超时时间
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
// 执行超时的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnTimeout", value = "true"),
// 执行被取消的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnCancel", value = "true"),
// 允许回调方法执行的最大并发数
@HystrixProperty(name = "fallback.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 服务降级是否启用,是否执行回调函数
@HystrixProperty(name = "fallback.enabled", value = "true"),
// 是否启用断路器
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
// 该属性用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为 20 的时候,
// 如果滚动时间窗(默认10秒)内仅收到了19个请求, 即使这19个请求都失败了,断路器也不会打开。
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"),
// 该属性用来设置在滚动时间窗中,表示在滚动时间窗中,在请求数量超过
// circuitBreaker.requestVolumeThreshold 的情况下,如果错误请求数的百分比超过50,
// 就把断路器设置为 "打开" 状态,否则就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
// 该属性用来设置当断路器打开之后的休眠时间窗。 休眠时间窗结束之后,
// 会将断路器置为 "半开" 状态,尝试熔断的请求命令,如果依然失败就将断路器继续设置为 "打开" 状态,
// 如果成功就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.sleepWindowinMilliseconds", value = "5000"),
// 断路器强制打开
@HystrixProperty(name = "circuitBreaker.forceOpen", value = "false"),
// 断路器强制关闭
@HystrixProperty(name = "circuitBreaker.forceClosed", value = "false"),
// 滚动时间窗设置,该时间用于断路器判断健康度时需要收集信息的持续时间
@HystrixProperty(name = "metrics.rollingStats.timeinMilliseconds", value = "10000"),
// 该属性用来设置滚动时间窗统计指标信息时划分"桶"的数量,断路器在收集指标信息的时候会根据
// 设置的时间窗长度拆分成多个 "桶" 来累计各度量值,每个"桶"记录了一段时间内的采集指标。
// 比如 10 秒内拆分成 10 个"桶"收集这样,所以 timeinMilliseconds 必须能被 numBuckets 整除。否则会抛异常
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "10"),
// 该属性用来设置对命令执行的延迟是否使用百分位数来跟踪和计算。如果设置为 false, 那么所有的概要统计都将返回 -1。
@HystrixProperty(name = "metrics.rollingPercentile.enabled", value = "false"),
// 该属性用来设置百分位统计的滚动窗口的持续时间,单位为毫秒。
@HystrixProperty(name = "metrics.rollingPercentile.timeInMilliseconds", value = "60000"),
// 该属性用来设置百分位统计滚动窗口中使用 “ 桶 ”的数量。
@HystrixProperty(name = "metrics.rollingPercentile.numBuckets", value = "60000"),
// 该属性用来设置在执行过程中每个 “桶” 中保留的最大执行次数。如果在滚动时间窗内发生超过该设定值的执行次数,
// 就从最初的位置开始重写。例如,将该值设置为100, 滚动窗口为10秒,若在10秒内一个 “桶 ”中发生了500次执行,
// 那么该 “桶” 中只保留 最后的100次执行的统计。另外,增加该值的大小将会增加内存量的消耗,并增加排序百分位数所需的计算时间。
@HystrixProperty(name = "metrics.rollingPercentile.bucketSize", value = "100"),
// 该属性用来设置采集影响断路器状态的健康快照(请求的成功、 错误百分比)的间隔等待时间。
@HystrixProperty(name = "metrics.healthSnapshot.intervalinMilliseconds", value = "500"),
// 是否开启请求缓存
@HystrixProperty(name = "requestCache.enabled", value = "true"),
// HystrixCommand的执行和事件是否打印日志到 HystrixRequestLog 中
@HystrixProperty(name = "requestLog.enabled", value = "true"),
},
threadPoolProperties = {
// 该参数用来设置执行命令线程池的核心线程数,该值也就是命令执行的最大并发量
@HystrixProperty(name = "coreSize", value = "10"),
// 该参数用来设置线程池的最大队列大小。当设置为 -1 时,线程池将使用 SynchronousQueue 实现的队列,
// 否则将使用 LinkedBlockingQueue 实现的队列。
@HystrixProperty(name = "maxQueueSize", value = "-1"),
// 该参数用来为队列设置拒绝阈值。 通过该参数, 即使队列没有达到最大值也能拒绝请求。
// 该参数主要是对 LinkedBlockingQueue 队列的补充,因为 LinkedBlockingQueue
// 队列不能动态修改它的对象大小,而通过该属性就可以调整拒绝请求的队列大小了。
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "5"),
}
)
-
-
服务限流
秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
-
-
工作流程
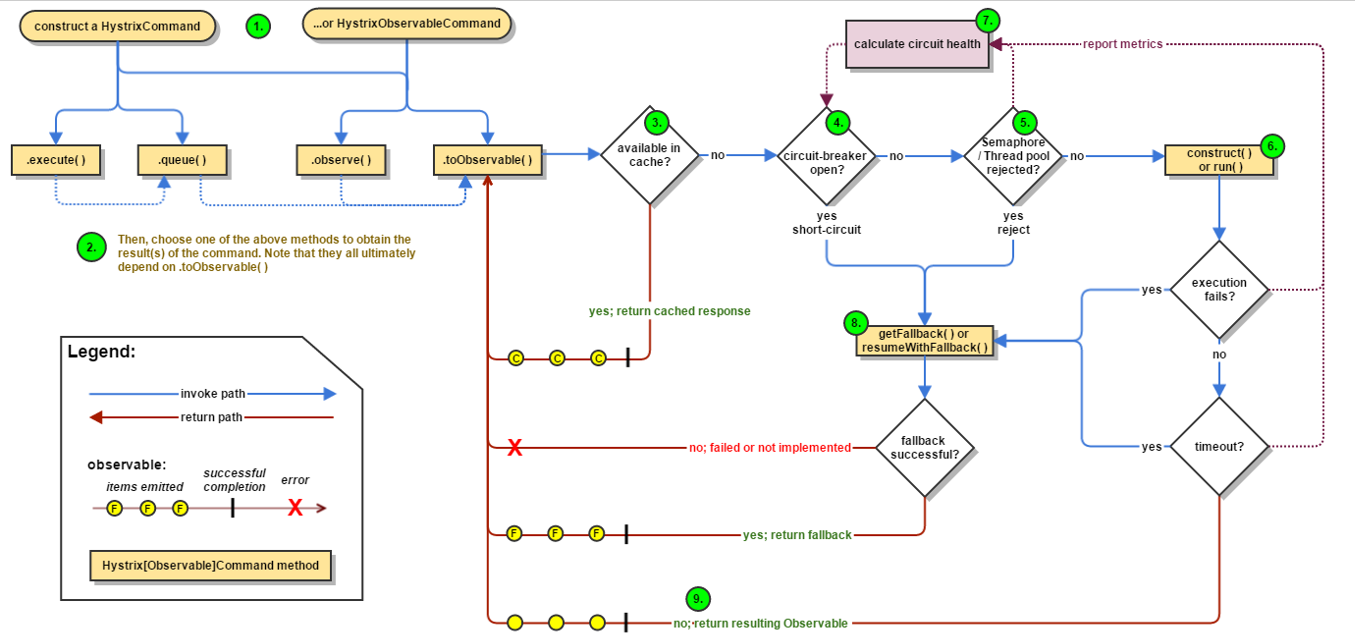
1 创建 HystrixCommand(用在依赖的服务返回单个操作结果的时候) 或 HystrixObserableCommand(用在依赖的服务返回多个操作结果的时候) 对象。
2 命令执行。其中 HystrixComand 实现了下面前两种执行方式;而 HystrixObservableCommand 实现了后两种执行方式:execute():同步执行,从依赖的服务返回一个单一的结果对象, 或是在发生错误的时候抛出异常。queue():异步执行, 直接返回 一个Future对象, 其中包含了服务执行结束时要返回的单一结果对象。observe():返回 Observable 对象,它代表了操作的多个结果,它是一个 Hot Obserable(不论 "事件源" 是否有 "订阅者",都会在创建后对事件进行发布,所以对于 Hot Observable 的每一个 "订阅者" 都有可能是从 "事件源" 的中途开始的,并可能只是看到了整个操作的局部过程)。toObservable(): 同样会返回 Observable 对象,也代表了操作的多个结果,但它返回的是一个Cold Observable(没有 "订阅者" 的时候并不会发布事件,而是进行等待,直到有 "订阅者" 之后才发布事件,所以对于 Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程)。
3 若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以 Observable 对象的形式 返回。
4 检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到 fallback 处理逻辑(第 8 步);如果断路器是关闭的,检查是否有可用资源来执行命令(第 5 步)。
5 线程池/请求队列/信号量是否占满。如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满, 那么 Hystrix 也不会执行命令, 而是转接到 fallback 处理逻辑(第8步)。
6 Hystrix 会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。HystrixCommand.run() :返回一个单一的结果,或者抛出异常。HystrixObservableCommand.construct(): 返回一个Observable 对象来发射多个结果,或通过 onError 发送错误通知。
7 Hystrix会将 "成功"、"失败"、"拒绝"、"超时" 等信息报告给断路器, 而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行 "熔断/短路"。
8 当命令执行失败的时候, Hystrix 会进入 fallback 尝试回退处理, 我们通常也称该操作为 "服务降级"。而能够引起服务降级处理的情况有下面几种:第4步: 当前命令处于"熔断/短路"状态,断路器是打开的时候。第5步: 当前命令的线程池、 请求队列或 者信号量被占满的时候。第6步:HystrixObservableCommand.construct() 或 HystrixCommand.run() 抛出异常的时候。
9 当Hystrix命令执行成功之后, 它会将处理结果直接返回或是以Observable 的形式返回。
tips:如果我们没有为命令实现降级逻辑或者在降级处理逻辑中抛出了异常, Hystrix 依然会返回一个 Observable 对象, 但是它不会发射任何结果数据, 而是通过 onError 方法通知命令立即中断请求,并通过onError()方法将引起命令失败的异常发送给调用者。 -
服务监控hystrixDashboard
-
概述
除了隔离依赖服务的调用以外,Hystrix还提供了准实时的调用监控(Hystrix Dashboard),Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少请求多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控。Spring Cloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面。
-
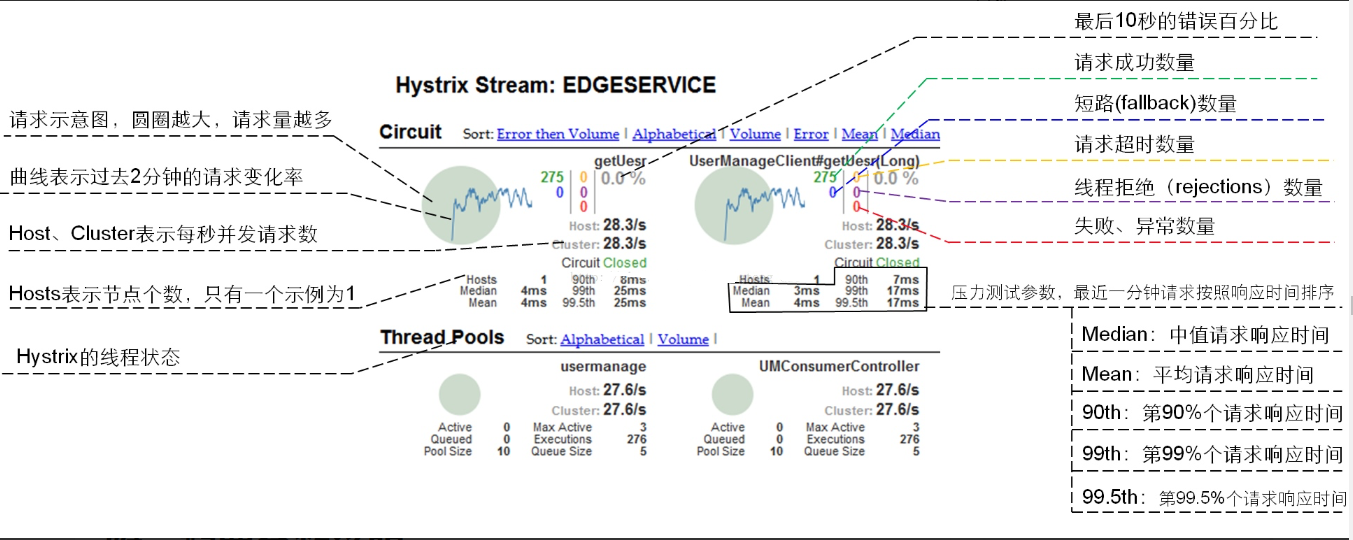
Hystrix监控界面
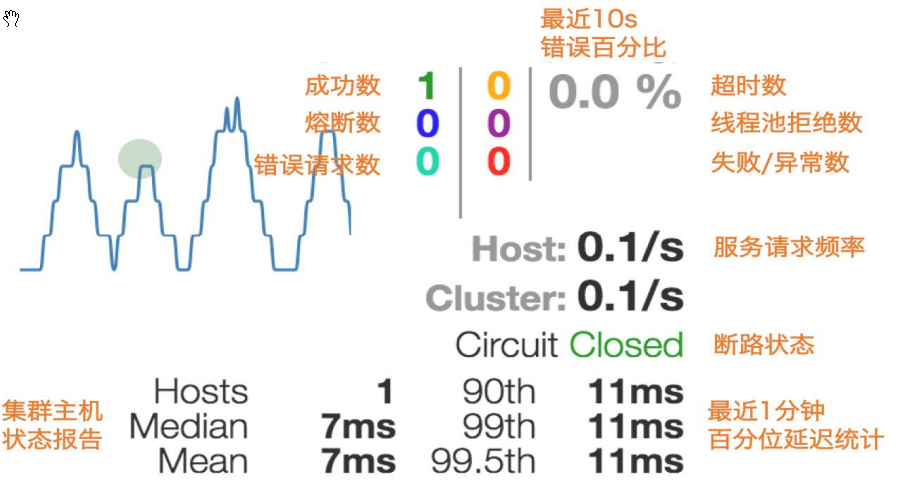
-
zuul路由网关
-
概述
Zuul是一种提供动态路由、监视、弹性、安全性等功能的边缘服务。 Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。
API网关为微服务架构中的服务提供了统一的访问入口,客户端通过API网关访问相关服务。API网关的定义类似于设计模式中的门面模式,它相当于整个微服务架构中的门面,所有客户端的访问都通过它来进行路由及过滤。它实现了请求路由、负载均衡、校验过滤、服务容错、服务聚合等功能。
Zuul包含了最主要的功能:代理 + 路由 + 过滤
-
负载均衡
网关为入口,由网关与微服务进行交互,所以网关必须要实现负载均衡的功能; 网关会获取微服务注册中心里面的服务连接地址,再配合一些算法选择其中一个服务地址,进行处理业务。 这个属于客户端侧的负载均衡,由调用方去实现负载均衡逻辑。
-
灰度发布
在灰度发布开始后,先启动一个新版本应用,但是并不直接将流量切过来,而是测试人员对新版本进行线上测试,启动的这个新版本应用,就是我们的金丝雀。如果没有问题,那么可以将少量的用户流量导入到新版本上,然后再对新版本做运行状态观察,收集各种运行时数据,如果此时对新旧版本做各种数据对比,就是所谓的A/B测试。新版本没什么问题,那么逐步扩大范围、流量,把所有用户都迁移到新版本上面来。
-
Zuul配置
在主启动类上加:@EnableZuulProxy
启用路由:zuul映射配置+注册中心注册后对外暴露的服务名称+rest调用地址
如果不想使用默认的路由规则,可以添加以下配置来忽略默认路由配置
zuul -
过滤器
过滤功能负责对请求过程进行额外的处理,是请求校验过滤及服务聚合的基础。
生命周期:
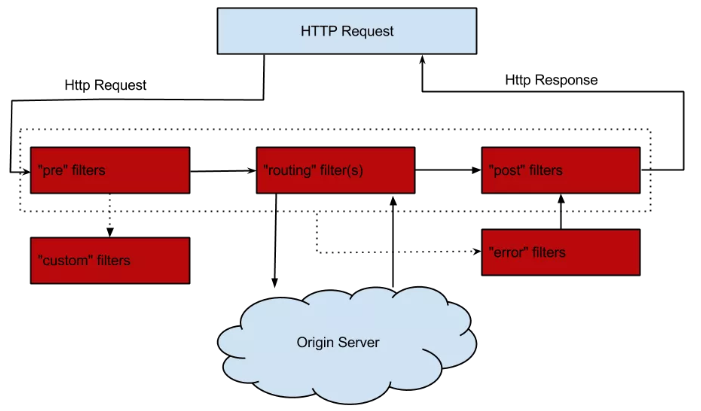
过滤类型:
-
pre:在请求被路由到目标服务前执行,比如权限校验、打印日志等功能;
-
routing:在请求被路由到目标服务时执行
-
post:在请求被路由到目标服务后执行,比如给目标服务的响应添加头信息,收集统计数据等功能;
-
error:请求在其他阶段发生错误时执行。
过滤顺序:数字小的先执行
-
Gateway新一代网关
-
概述
Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关; 但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,那就是SpringCloud Gateway一句话:gateway是原zuul1.x版的替代。
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5,Spring Boot 2和 Project Reactor等技术。 Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能, 例如:熔断、限流、重试等。
SpringCloud Gateway 使用的Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架。
-
微服务网关位置
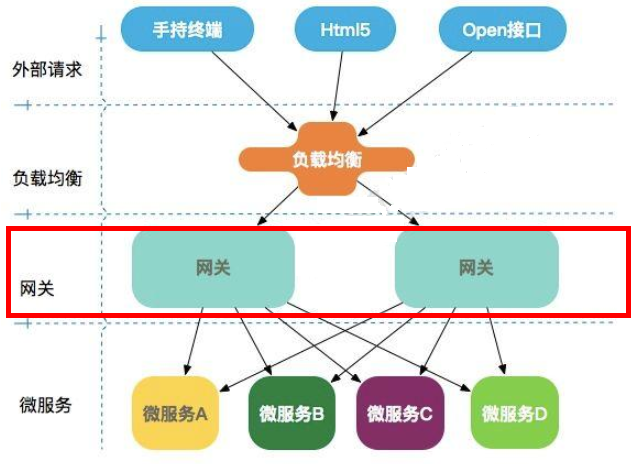
-
Gateway能做什么?
-
反向代理
-
鉴权
-
流量控制
-
熔断
-
日子监控
-
-
三大核心
-
Route(路由)
路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
-
Predicate(断言)
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由
-
Filter(过滤)
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
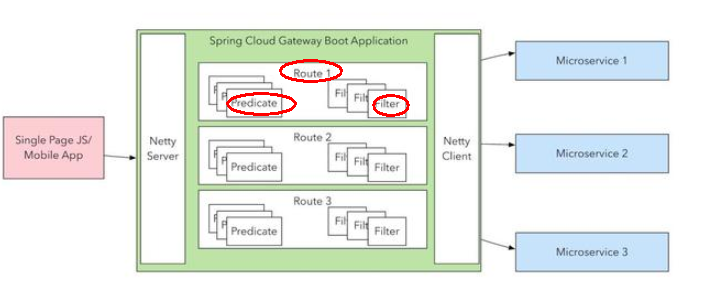
web请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过程的前后,进行一些精细化控制。predicate就是我们的匹配条件;而filter,就可以理解为一个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现一个具体的路由了
-
-
Gateway工作流程
核心逻辑:路由转发+执行过滤器链
-
Gatewey配置
Gateway网关路由有两种配置方式:
1.yaml文件形式
cloud:
gateway:
routes:
- id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:8001 #匹配后提供服务的路由地址
predicates:
- Path=/payment/get/** # 断言,路径相匹配的进行路由
- id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:8001 #匹配后提供服务的路由地址
predicates:
- Path=/payment/lb/** # 断言,路径相匹配的进行路由
2.代码中注入RouteLocator的Bean -
Predicate的使用
-
概述
Spring Cloud Gateway将路由匹配作为Spring WebFlux HandlerMapping基础架构的一部分。 Spring Cloud Gateway包括许多内置的Route Predicate工厂。所有这些Predicate都与HTTP请求的不同属性匹配。多个Route Predicate工厂可以进行组合
Spring Cloud Gateway 创建 Route 对象时, 使用 RoutePredicateFactory 创建 Predicate 对象,Predicate 对象可以赋值给 Route。 Spring Cloud Gateway 包含许多内置的Route Predicate Factories。
所有这些谓词都匹配HTTP请求的不同属性。多种谓词工厂可以组合,并通过逻辑and。
-
常用的Route Predicate
-
After Route Predicate
-
Before Route Predicate
-
Between Route Predicate
-
Cookie Route Predicate
-
Header Route Predicate
-
Host Route Predicate
-
Method Route Predicate
-
Path Route Predicate
-
Query Route Predicate
server -
-
-
Filter的使用
-
概述
路由过滤器可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用。
Spring Cloud Gateway 内置了多种路由过滤器,他们都由GatewayFilter的工厂类来产生
-
常用的GatewayFilter和yaml配置方式
AddRequestParameter
filters:
- AddRequestParameter=X-Request-Id,1024 #过滤器工厂会在匹配的请求头加上一对请求头,名称为X-Request-Id值为1024
-
SpringCloud Config分布式配置中心
分布式系统面临的---配置问题
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
Config
-
是什么
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。
-
怎么玩
SpringCloud Config分为服务端和客户端两部分。
服务端也称为分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密/解密信息等访问接口
客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过git客户端工具来方便的管理和访问配置内容。
-
功能
-
集中管理配置文件
-
不同环境不同配置,动态化的配置更新,分环境部署比如dev/test/prod/beta/release
-
运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
-
当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
-
将配置信息以REST接口的形式暴露
-
-
配置
@EnableConfigServer
配置读取规则
-
/{label}/{application}-{profile}.yml
-
/{application}-{profile}.yml
-
/{application}/{profile}[/{label}]
-
label:分支(branch)
-
name :服务名
-
profiles:环境(dev/test/prod)
-
-
动态刷新
POM引入actuaor监控
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>ymal修改,暴露监控端口
# 暴露监控端点
management:
endpoints:
web:
exposure:
include: "*"在业务类添加:RefreshScope
SpringCloud Bus消息总线
Spring Cloud Bus 配合 Spring Cloud Config 使用可以实现配置的动态刷新。
-
概述
Spring Cloud Bus是用来将分布式系统的节点与轻量级消息系统链接起来的框架, 它整合了Java的事件处理机制和消息中间件的功能。 Spring Clud Bus目前支持RabbitMQ和Kafka。
Bus支持两种消息代理:RabbitMQ 和 Kafka
Spring Cloud Bus能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改、事件推送等,也可以当作微服务间的通信通道。
-
总线
-
什么是总线 在微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消息主题,并让系统中所有微服务实例都连接上来。由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线。在总线上的各个实例,都可以方便地广播一些需要让其他连接在该主题上的实例都知道的消息。
-
基本原理 ConfigClient实例都监听MQ中同一个topic(默认是springCloudBus)。当一个服务刷新数据的时候,它会把这个信息放入到Topic中,这样其它监听同一Topic的服务就能得到通知,然后去更新自身的配置。
-
-
通知
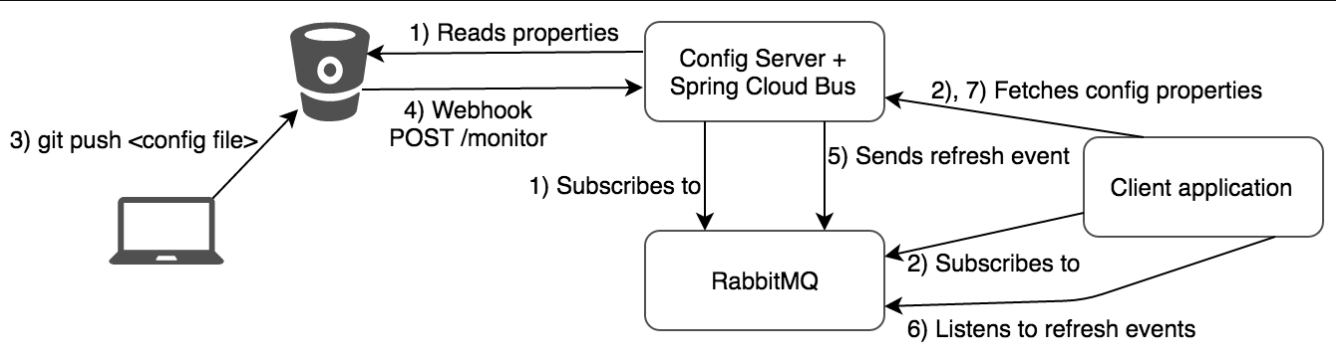
SpringCloud Stream消息驱动
-
概念
官方定义 Spring Cloud Stream 是一个构建消息驱动微服务的框架。
应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream中binder对象交互。 通过我们配置来binding(绑定) ,而 Spring Cloud Stream 的 binder对象负责与消息中间件交互。 所以,我们只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
通过使用Spring Integration来连接消息代理中间件以实现消息事件驱动。 Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引用了发布-订阅、消费组、分区的三个核心概念。
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
目前仅支持RabbitMQ、Kafka。
-
设计思想
-
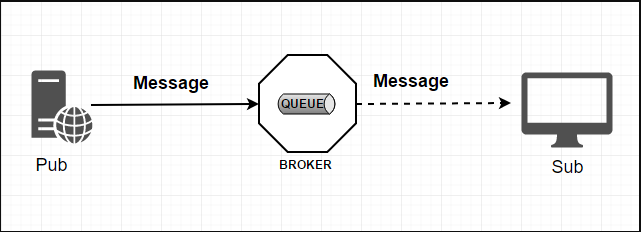
标准MQ
-
生产者/消费者之间靠消息媒介传递信息内容 --- Message
-
消息必须走特定的通道 --- 消息通道MessageChannel
-
消息通道里的消息如何被消费呢,谁负责收发处理 --- 消息通道MessageChannel的子接口SubscribableChannel,由MessageHandler消息处理器所订阅
-
-
为什么用Cloud Stream
RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,,这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候springcloud Stream给我们提供了一种解耦合的方式。
-
怎么统一底层差异

通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
Binder可以生成Binding,Binding用来绑定消息容器的生产者和消费者,它有两种类型,INPUT和OUTPUT,INPUT对应于消费者,OUTPUT对应于生产者。
-
Stream中的消息通信方式遵循了发布-订阅模式
Topic主题进行广播,在RabbitMQ就是Exchange,在Kakfa中就是Topic。
-
-
标准化流程
-
Binder
很方便的连接中间件,屏蔽差异
-
Channel
通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
-
Source和Sink
简单的可理解为参照对象是Spring Cloud Stream自身, 从Stream发布消息就是输出,接受消息就是输入。
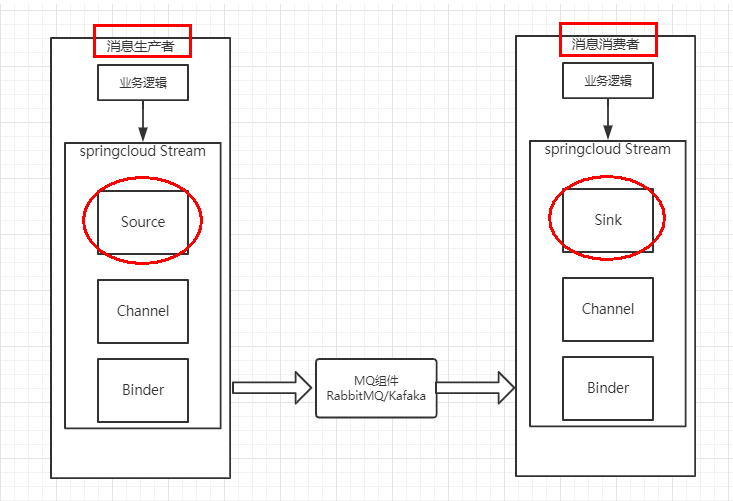
-
-
常用API和常用注解

SpringCloud Sleuth分布式请求链路跟踪
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
概述
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin。

