


# -*- coding:UTF-8 -*-
__autor__ = 'zhouli' __date__ = '2018/10/21 14:54' import numpy as np l = [1, 2, 3, 4, 5, 6] l2 = np.array(l) print(l, type(l), l2, type(l2)) print(l * 3, l2 * 3) # 普通列表再说相乘的时候是对列表的复制在相加,而,numpy的列表是挨个儿相乘之后再赋值 p = list(range(10)) print(p) p2 = list(np.arange(10)) print(p2) # 到这里基本上看不出来range和np.arange()的区别 p3 = np.arange(9).size # 使用size而不是使用len()主要是因为在多维的情况下,len()只能得出单维度参数 print(p3) # linspace的使用 print(np.linspace(5, 15, 8)) # 从5开始到15,中间要有8个元素,需要注意的是15是包括在内的 print(np.linspace(5, 15, 3, retstep=True)) # retstep 是打印出步长, ''' 结果如下: [5. 6.42857143 7.85714286 9.28571429 10.71428571 12.14285714 13.57142857 15. ] (array([ 5., 10., 15.]), 5.0),取值用下标 ''' ''' Examples -------- >>> np.linspace(2.0, 3.0, num=5) array([ 2. , 2.25, 2.5 , 2.75, 3. ]) >>> np.linspace(2.0, 3.0, num=5, endpoint=False) array([ 2. , 2.2, 2.4, 2.6, 2.8]) >>> np.linspace(2.0, 3.0, num=5, retstep=True) (array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25) ''' # zeros()方法 # 单维 np.zeros(6) # array([0., 0., 0., 0., 0., 0.]) # 二维 np.zeros((3, 4)) # 在这里一定需要注意的是需要加括号 ''' array([[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]]) ''' # 多维 np.zeros((2, 3, 4)) ''' array([[[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]], [[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]]]) ''' # ones() np.ones(3) # array([1., 1., 1.]) np.ones((3, 4)) # 默认创建float ''' array([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]]) ''' np.ones(5, dtype='int32') # array([1, 1, 1, 1, 1]) 指定为int()类型 # 获取多维数组的长度必须使用size方法,不可以使用len(),查看数组有几个维度使用shape # slice()学习 # 一维 new_list = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) # 无论是索引也好还是取值也好,和python的list完全一致 # 三维 my_list = np.arange(10) my_list.shape = (2, 5) # 这样通过对shape的定义就可以变成2维数组了 ''' array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) ''' print(my_list[0]) # array([0, 1, 2, 3, 4]) # 那么如何该取到里面的值呢? print(my_list[0, 1]) # 最终的值是1 ''' 规律是my_list[row,col],第一个参数是行,第二个参数是列,一般情况下是预先定义好的 ''' # 三维 s_3d_array = np.arange(100) s_3d_array.shape = (2, 10, 5) # 在这里需要注意的一定是shape参数相乘一定要等于数组的size print(s_3d_array) ''' [[[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19] [20 21 22 23 24] [25 26 27 28 29] [30 31 32 33 34] [35 36 37 38 39] [40 41 42 43 44] [45 46 47 48 49]] [[50 51 52 53 54] [55 56 57 58 59] [60 61 62 63 64] [65 66 67 68 69] [70 71 72 73 74] [75 76 77 78 79] [80 81 82 83 84] [85 86 87 88 89] [90 91 92 93 94] [95 96 97 98 99]]] ''' print(s_3d_array[0, 2, 4]) # 几维数组就需要具体定位到几个 # 数据广播和常用的矩阵操作 lisi = np.arange(70) lisi.shape = (2, 7, 5) print(lisi.ndim) # 直接告诉是属于几维 print(lisi.dtype) # 直接告诉是什么数据类型 print(5 * lisi - 2) == print(np.subtract(np.multiply(5, my_3d_array), 2)) # 后者高效 left = np.arange(6).reshape((2, 3)) # 将维度改变使用reshape right = np.arange(15).reshape((3, 5)) # 两个矩阵相乘必须是一个序列的列等于下一个的行 np.dot(left, right) # 左边每一行的数乘以右边列相加,因此得到数组讲师左行右列数 right.sum() # 对多维数组进行求和 # 如何让多维数组对应的元素相加? left.sum(axis=0) # array([3, 5, 7]) axis是指定哪一个维度,相当于多个维度求和 '''array([[ 35, 37, 39, 41, 43], [ 45, 47, 49, 51, 53], [ 55, 57, 59, 61, 63], [ 65, 67, 69, 71, 73], [ 75, 77, 79, 81, 83], [ 85, 87, 89, 91, 93], [ 95, 97, 99, 101, 103]])''' lisi.sum(axis=1) # 指定维度2 相当于多列一个单元竖向求和 '''array([[105, 112, 119, 126, 133], [350, 357, 364, 371, 378]])''' lisi.sum(axis=2) # 指定维度3,相当于单列横向求和 ''' array([[ 10, 35, 60, 85, 110, 135, 160], [185, 210, 235, 260, 285, 310, 335]]) ''' my_3d_array = np.arange(70) my_3d_array.shape = (2,7,5) my_2d_array = np.ones(35,dtype='int_').reshape((7,5)) my_2d_array*3 my_2d_random_array = np.random.random((7,5)) my_3d_array.shape my_3d_array * my_2d_random_array # 能够相乘是因为行和列相等!与前后的顺序无关1 person_data_def = [('name', 'S8'), ('height', 'f8'), ('weight', 'f8'), ('age', 'i8')] # 'S8'代表8个字符的意思 ''' '?' boolean 'b' byte 'B' unsigned byte 'i' integer 'u' unsigned integer 'f' float 'c' complex-floating point 'm' timedelta 'M' datetime 'O' python Objects 'S','a' zero-terminated bytes(not recommended) 'U' unicode string 'v' raw data ''' people_array = np.zeros((4,),dtype=person_data_def) # 上述是创造一个行数为4的数组,单个数组的样式是依据person_data_def people_array[0] = ('steven', 175, 70, 42) people_array[2] = ('Peter', 172, 70, 41) # 像python一样进行赋值操作 ''' array([(b'steven', 175., 70., 42), (b'', 0., 0., 0), (b'Peter', 172., 70., 41), (b'', 0., 0., 0)], dtype=[('name', 'S8'), ('height', '<f8'), ('weight', '<f8'), ('age', '<i8')]) ''' people_array['name'] # 打印出来所有name属性 ''' array([b'steven', b'', b'Peter', b''], dtype='|S8') ''' temp_age = people_array['age']/2 # 取到age属性然后除以二赋值给新的数组 ''' array([21. , 0. , 20.5, 0. ]) ''' people_big_array = np.zeros((4, 3, 5), dtype=person_data_def) people_big_array['height'] # 列出所有数组中的height属性的值 people_big_array[['height', 'age']] # 列出所有数组中的height和age属性的值,多个属性之间需要加上[] person_recode_array = np.rec.array([('steven', 175, 70, 42), ('Peter', 172, 70, 41)], dtype=person_data_def) print(person_recode_array) ''' rec.array([(b'steven', 175., 70., 42), (b'Peter', 172., 70., 41)], dtype=[('name', 'S8'), ('height', '<f8'), ('weight', '<f8'), ('age', '<i8')]) ''' print(person_recode_array.age) # array([42, 41], dtype=int64)类似pandas
下面是关于数据的可视化:
主要是用的matplotlib的模块:(二维图表主要)
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/22 21:30' import numpy as np import matplotlib.pyplot as plt mu, sigma = 100, 15 # mu 是平均数,sigma是标准差 data_set = mu + sigma * np.random.randn(10000) n, bins, patches = plt.hist(data_set, 50, normed=1, facecolor='k', alpha=0.75) ''' 在此处 facecolor='m' code color ________________________ 'k' black 'b' blue 'c' cyan 'g' green 'm' magenta 'r' red 'w' white 'y' yellow ''' plt.xlabel('Smarts') # 代表x轴上面的标签 plt.ylabel('Probability') # 代表y轴上面的标签 plt.title('Histogram of IQ') # 代表图标的表题 plt.text(60, .025, r'\mu=100,\ \sigma=15$') # 注释信息 plt.axis([40, 160, 0, 0.03]) # 轴之间的间隔x轴在前,y轴在后 plt.grid(True) # 选择是否出现网格 plt.show() # 画出图
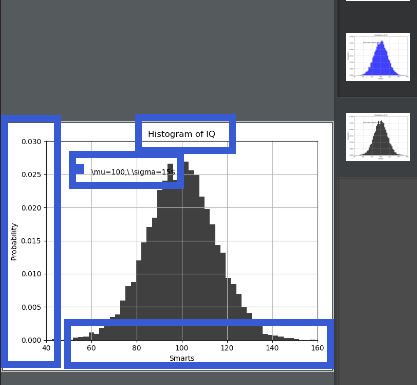
下面进入学习模式:
my_first_figure = plt.figure("my first figure") subplot1 = my_first_figure.add_subplot(2, 3, 1) # 定义整个figure是2行3列的模式,显示在第一个位置 # 切记figure下标是从1开始的而不是0 subplot1 = my_first_figure.add_subplot(2, 3, 6) # 目前两幅图是空的 plt.plot(np.random.rand(50).cumsum(), 'k--') # 随机,k后面加--是代表虚线 plt.show()
subplot2 = my_first_figure.add_subplot(2, 3, 2) plt.plot(np.random.rand(50), 'go') # 加一些点,使用原点图 plt.show()
曲线图:
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/23 22:40' import numpy as np import matplotlib.pyplot as plt data_set_size = 15 low_mu, low_sigma = 50, 4.3 low_data_set = low_mu + low_sigma * np.random.randn(data_set_size) high_mu, high_sigma = 57, 5.2 high_data_set = high_mu + high_sigma * np.random.randn(data_set_size) days = list(range(1, data_set_size + 1)) plt.plot(days,low_data_set) # days是x轴的数据集,low_data_set是Y轴的数据集
plt.show()
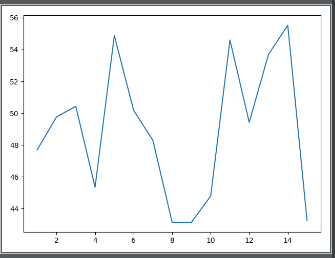
那如果需要在同一幅图中展示两个不同的曲线那就
__autor__ = 'zhouli' __date__ = '2018/10/23 22:40' import numpy as np import matplotlib.pyplot as plt data_set_size = 15 low_mu, low_sigma = 50, 4.3 low_data_set = low_mu + low_sigma * np.random.randn(data_set_size) high_mu, high_sigma = 57, 5.2 high_data_set = high_mu + high_sigma * np.random.randn(data_set_size) days = list(range(1, data_set_size + 1)) plt.plot(days, low_data_set, days, high_data_set) # days是x轴的数据集,low_data_set是Y轴的数据集,如果同时展示两条的话就像这样 plt.show()
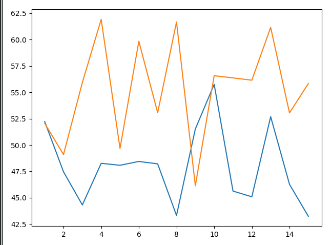
那如果需要在图像中生成顶点标识怎么办?
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/23 22:40' import numpy as np import matplotlib.pyplot as plt data_set_size = 15 low_mu, low_sigma = 50, 4.3 low_data_set = low_mu + low_sigma * np.random.randn(data_set_size) high_mu, high_sigma = 57, 5.2 high_data_set = high_mu + high_sigma * np.random.randn(data_set_size) days = list(range(1, data_set_size + 1)) plt.plot(days, low_data_set, days, low_data_set, "vm", days, high_data_set, days, high_data_set, "^k") # 加上^和v 后面的是颜色的不同 plt.show()
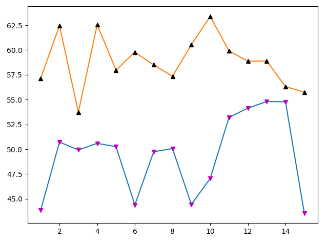 需要注意的是,在上方的代码中
需要注意的是,在上方的代码中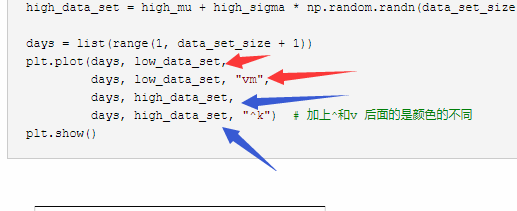
存在代码的重复,实际上是先生成一幅图,然后再生成一些三角形图拼接在一起的
不信的话把上面的全部去掉,滞留最后一个
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/23 22:40' import numpy as np import matplotlib.pyplot as plt data_set_size = 15 low_mu, low_sigma = 50, 4.3 low_data_set = low_mu + low_sigma * np.random.randn(data_set_size) high_mu, high_sigma = 57, 5.2 high_data_set = high_mu + high_sigma * np.random.randn(data_set_size) days = list(range(1, data_set_size + 1)) plt.plot( days, high_data_set, "^k") # 加上^和v 后面的是颜色的不同 plt.show()
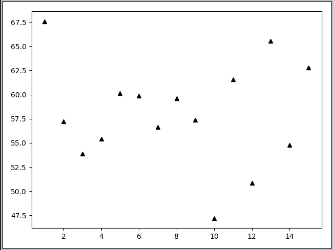 这个是图像!
这个是图像!
完善一下,添加x轴和y轴以及图表的信息
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/23 22:40' import numpy as np import matplotlib.pyplot as plt data_set_size = 15 low_mu, low_sigma = 50, 4.3 low_data_set = low_mu + low_sigma * np.random.randn(data_set_size) high_mu, high_sigma = 57, 5.2 high_data_set = high_mu + high_sigma * np.random.randn(data_set_size) days = list(range(1, data_set_size + 1)) plt.plot(days, low_data_set, days, low_data_set, "vm", days, high_data_set, days, high_data_set, "^k") plt.xlabel('Day') # x轴 plt.ylabel('Temperature: degrees Farenheit') # y轴 plt.title('Randomized temperature data') # 标题 plt.show()
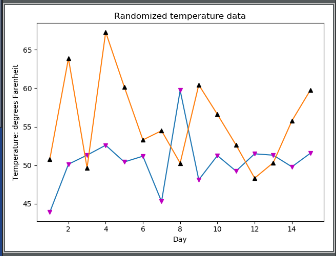
如图所示!
那如果采用figure的画法呢?
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/24 21:26' import numpy as np import matplotlib.pyplot as plt number_of_data_points = 1000 my_figure = plt.figure() subplot_1 = my_figure.add_subplot(1, 1, 1) subplot_1.plot(np.random.rand(number_of_data_points).cumsum()) # 累计每产生的随机数总和 number_of_ticks = 5 ticks = np.arange(0, number_of_data_points, number_of_data_points//number_of_ticks) subplot_1.set_xticks(ticks) # 设置x轴tick的数据 labels = subplot_1.set_xticklabels(['one', 'two', 'three', 'four', 'five'], rotation=45, fontsize='small') # 设置x轴的属性,并且设置,旋转rotation=45为45°,字体设置为small小号的 subplot_1.set_title("My First Ticked Plot") subplot_1.set_xlabel("Groups") subplot_1.grid(True) # 设置网格显示 gridlines = subplot_1.get_xgridlines() + subplot_1.get_ygridlines() for line in gridlines: line.set_linestyle(':') plt.show()
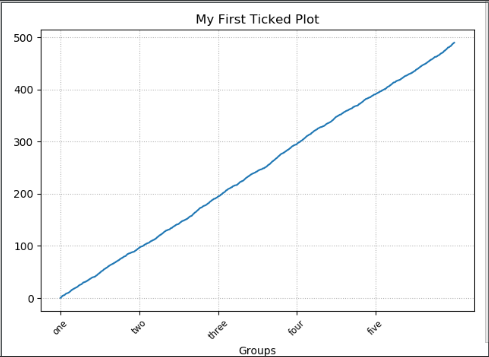 划重点的是,对于直接使用plt.的方法可以直接设置label,但是这种需要设置的set_label
划重点的是,对于直接使用plt.的方法可以直接设置label,但是这种需要设置的set_label
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/24 22:15' import numpy as np import matplotlib.pyplot as plt number_of_data_points = 10 data = np.random.rand(10) print(data) ''' [0.39370273 0.08955335 0.84195812 0.12299897 0.32809431 0.00442988 0.47879628 0.82446331 0.38921918 0.42591007] ''' print(data.cumsum()) ''' [0.39370273 0.48325608 1.3252142 1.44821317 1.77630748 1.78073736 2.25953364 3.08399695 3.47321612 3.89912619] ''' ''' 总结如下: cumsum()的含义为连续求和类似于3!这种类型 ''' # 开始绘图:1,构造一个figure my_figure = plt.figure() subplot_1 = my_figure.add_subplot(1, 1, 1) # 只增加一幅图 subplot_1.plot(data.cumsum()) subplot_1.text(1, 0.5, r'an equation: $E=mc^2$', fontsize=18, color='red') # 增加一个方程式E=mc²,字号18,颜色红色 subplot_1.text(1, 1.5, "Hello, Mountain Climbing!", fontsize=14, color='green') # 再次增加一个文本“hello……”,其中1,代表x轴坐标,1.5为y轴坐标 # see: http://matplotlib.org/users/transforms_tutorial.html # transform=subplot_1.transAxes; entire axis between zero and one 使用transform将x轴设置为0-1,那么0.5, 0.5就会在正中间 subplot_1.text(0.5, 0.5, "We are centered, now", transform=subplot_1.transAxes) # 此处的annotate(注释),意思是添加箭头,xy代表箭头 xytext代表箭尾,facecolor代表颜色,shrink代表粗细 subplot_1.annotate('shoot arrow', xy=(2, 1), xytext=(3, 4), arrowprops=dict(facecolor='red', shrink=0.05)) plt.show()
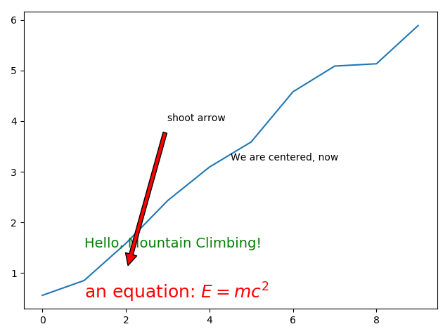 如图所示:使用text方法就可以在固定坐标点出定位提示文本,值得注意的是有一个正中间的是因为有了transform,进行了转换!
如图所示:使用text方法就可以在固定坐标点出定位提示文本,值得注意的是有一个正中间的是因为有了transform,进行了转换!
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/24 22:40' import numpy as np import matplotlib.pyplot as plt x = np.arange(0, 10, 0.005) y = np.exp(-x / 2.) * np.sin(2 * np.pi * x) # -2分之x次方乘以sin(2*π*x)的函数 fig = plt.figure() ax = fig.add_subplot(111) # 如果只有一幅图的情况下,我们就使用参数111 ax.plot(x, y) # 绘出x,y轴 ax.set_xlim(0, 10) # 设置x轴的坐标点 ax.set_ylim(-1, 1) # 设置y轴的坐标点 xdata, ydata = 5, 0 xdisplay, ydisplay = ax.transData.transform_point((xdata, ydata)) # 将这两个值通过transform转化为相应的坐标 bbox = dict(boxstyle="round", fc="0.8") # 箱子样式是圆角的,圆角的程度是0.8 arrowprops = dict( arrowstyle="->", connectionstyle="angle,angleA=0,angleB=90,rad=10") # 拐弯直角箭头 offset = 72 ax.annotate('data = (%.1f, %.1f)' % (xdata, ydata), xy=(xdata, ydata), xytext=(-2 * offset, offset), textcoords='offset points', bbox=bbox, arrowprops=arrowprops) # ±2代表箭头平直段的方向 disp = ax.annotate('display = (%.1f, %.1f)' % (xdisplay, ydisplay), (xdisplay, ydisplay), xytext=(0.5 * offset, -offset), xycoords='figure pixels', textcoords='offset points', bbox=bbox, arrowprops=arrowprops) plt.show()
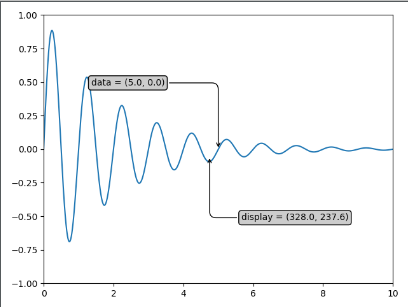
fig = plt.figure() for i, label in enumerate(('A', 'B', 'C', 'D')): ax = fig.add_subplot(2,2,i+1) ax.text(0.05, 0.95, label, transform=ax.transAxes, fontsize=16, fontweight='bold', va='top') plt.show()
 其中top是像顶端对齐!
其中top是像顶端对齐!
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/24 23:04' import numpy as np import matplotlib.pyplot as plt # 绘制饼状图和柱状图!
import numpy as np
import matplotlib.pyplot as plt
# 绘制饼状图和柱状图!
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' # 说明
sizes = [15, 30, 45, 10] # 比例
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'] # 颜色
explode = (0, 0.1, 0, 0) # only "explode" the 2nd slice (i.e. 'Hogs') # 分裂出来Hogs
plt.pie(x=sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=90)
# Set aspect ratio to be equal so that pie is drawn as a circle.
plt.axis('equal')
plt.show()
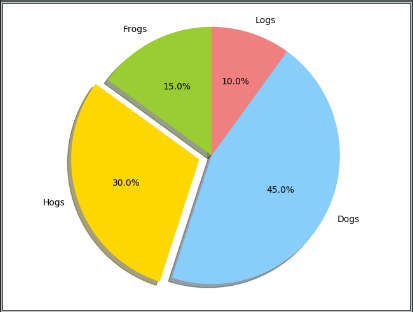 这个其实是官网的示例
这个其实是官网的示例
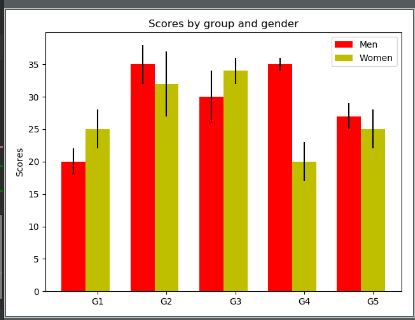
Bar Chart
This example is from: http://matplotlib.org/examples/api/barchart_demo.htmlAPI location: http://matplotlib.org/api/pyplot_api.html
matplotlib.pyplot.bar(left, height, width=0.8, bottom=None, hold=None, data=None, **kwargs)
N = 5 menMeans = (20, 35, 30, 35, 27) menStd = (2, 3, 4, 1, 2) ind = np.arange(N) # the x locations for the groups width = 0.35 # the width of the bars fig, ax = plt.subplots() rects1 = ax.bar(ind, menMeans, width, color='r', yerr=menStd) womenMeans = (25, 32, 34, 20, 25) womenStd = (3, 5, 2, 3, 3) rects2 = ax.bar(ind + width, womenMeans, width, color='y', yerr=womenStd) # add some text for labels, title and axes ticks ax.set_ylabel('Scores') ax.set_title('Scores by group and gender') ax.set_xticks(ind + width) ax.set_xticklabels(('G1', 'G2', 'G3', 'G4', 'G5')) ax.legend((rects1[0], rects2[0]), ('Men', 'Women')) plt.show()
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/27 19:32' # 深浅拷贝 import numpy as np tree_house = np.array([-45, -31, 2, 25, 51, 99]) farm_house = tree_house.view() farm_house.shape = (2, 3) print(farm_house) ''' [[-45 -31 2] [ 25 51 99]] ''' tree_house[0] = 0 print(tree_house, '---', farm_house) # views并不改变id,只是角度不同而已 ''' [ 0 -31 2 25 51 99] --- [[ 0 -31 2] [ 25 51 99]] '''
值的注意的是对于使用view()函数一样的是,都是属于浅拷贝,简单的可以理解为从不同的视角看一个人,虽然看上去可能会不一样但是本身还是一个人
深拷贝
dog_house = np.copy(tree_house) tree_house[0] = 9 print(tree_house, '*****', dog_house) ''' [ 9 -31 2 25 51 99] ***** [ 0 -31 2 25 51 99] '''
numpy的数据属性
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/27 20:16' import numpy as np a = np.arange(24).reshape((2,3,4)) print(a) print(a.ndim) # 看数组是几维 print(a.shape) # 具体维度 print(a.size) # 数组的总长 print(a.dtype) # 数组的类型 print(a.itemsize) # 数组中每一个元素的长度 print(type(a)) ''' [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] 3 (2, 3, 4) 24 int32 4 <class 'numpy.ndarray'> '''
append
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/27 20:23' import numpy as np # numpy 添加数据的方式 ''' append horizontal stacking vertical stacking insert ''' a = np.array([np.arange(24)]).reshape(2, 3, 4) print(a) ''' [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] ''' b = np.append(a, [5,6,7,8]) # 所有的数组全部变成了单维的 print(b, b.ndim, b.shape) ''' [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 5 6 7 8] 1 (28,) ''' c = np.array([np.arange(24)]).reshape(2, 3, 4)*10 + 3 print(c) ''' [[[ 3 13 23 33] [ 43 53 63 73] [ 83 93 103 113]] [[123 133 143 153] [163 173 183 193] [203 213 223 233]]] ''' np.append(a,c,axis=0) # 第一个参数是被添加的数组,第二个是准备添加的数组,第三个参数表示从第几个维度添加 print(np.append(a,c,axis=0)) ''' [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[ 12 13 14 15] [ 16 17 18 19] [ 20 21 22 23]] [[ 3 13 23 33] [ 43 53 63 73] [ 83 93 103 113]] [[123 133 143 153] [163 173 183 193] [203 213 223 233]]] ''' print(np.append(a,c,axis=1)) ''' [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [ 3 13 23 33] [ 43 53 63 73] [ 83 93 103 113]] [[ 12 13 14 15] [ 16 17 18 19] [ 20 21 22 23] [123 133 143 153] [163 173 183 193] [203 213 223 233]]] ''' print(np.append(a,c,axis=2)) ''' [[[ 0 1 2 3 3 13 23 33] [ 4 5 6 7 43 53 63 73] [ 8 9 10 11 83 93 103 113]] [[ 12 13 14 15 123 133 143 153] [ 16 17 18 19 163 173 183 193] [ 20 21 22 23 203 213 223 233]]] ''' # 总结 1维是追加, 2维是分别在维度增加,三维是每个增加
其实可以通过维度来确认的
print(np.append(a,c,axis=0).shape) (4, 3, 4)
加入第一个维度的话就是(2,3, 4) + (2,3,4) 在第一个维度相加就是2+2 = 4
第二个维度就是(2,3, 4) + (2,3,4) 在第一个维度相加就是3+3 = 6
第三个维度就是(2,3, 4) + (2,3,4) 在第一个维度相加就是3+3 = 6
数据删除
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/27 21:58' import numpy as np c = np.array([np.arange(24)]).reshape(2, 3, 4) * 10 + 3 print(c) ''' [[[ 3 13 23 33] [ 43 53 63 73] [ 83 93 103 113]] [[123 133 143 153] [163 173 183 193] [203 213 223 233]]] ''' d = np.empty(c.shape) # 生成空的数组 print(d) ''' [[[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]] ''' np.copyto(d, c) # 将ccopy到d里面 print(d) ''' [[[ 3. 13. 23. 33.] [ 43. 53. 63. 73.] [ 83. 93. 103. 113.]] [[123. 133. 143. 153.] [163. 173. 183. 193.] [203. 213. 223. 233.]]] ''' # 删除元素 np.delete(d, 1, axis=0) print(np.delete(d, 1, axis=0)) # 删除一维中的第2个元素,对d保持不变 print(np.delete(d, 1, axis=0).shape) ''' [[[ 3. 13. 23. 33.] [ 43. 53. 63. 73.] [ 83. 93. 103. 113.]]] (1, 3, 4) ''' print(np.delete(d, 1, axis=1)) print(np.delete(d, 1, axis=1).shape) ''' [[[ 3. 13. 23. 33.] [ 83. 93. 103. 113.]] [[123. 133. 143. 153.] [203. 213. 223. 233.]]] (2, 2, 4) ''' print(np.delete(d, 1, axis=2)) print(np.delete(d, 1, axis=2).shape) ''' [[[ 3. 23. 33.] [ 43. 63. 73.] [ 83. 103. 113.]] [[123. 143. 153.] [163. 183. 193.] [203. 223. 233.]]] (2, 3, 3) '''
数据的合并与分离
# -*- coding:UTF-8 -*- __autor__ = 'zhouli' __date__ = '2018/10/28 19:12' import numpy as np a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) together = np.concatenate((a, b), axis=0) # 从第一维进行拼接 print(a.shape, b.shape, together.shape) # 结果是(2, 2) (1, 2) (3, 2) print(together) ''' [[1 2] [3 4] [5 6]] ''' together[1, 1] = 555 # 注意的是这种属于深拷贝,对原数组无影响 print(together) ''' [[ 1 2] [ 3 555] [ 5 6]] ''' # stack方式 arrays = np.zeros((5, 3, 4)) for n in range(5): arrays[n] = np.random.rand(3, 4) # 更具所给维度生成随机(0-1)之间的数 print(arrays) stark0 = np.stack(arrays, axis=0) stark1 = np.stack(arrays, axis=1) stark2 = np.stack(arrays, axis=2) # split temp = np.arange(6) print(np.split(temp, 2)) # 将temp分为两组,注意一定要需要能够整除 print(np.split(temp, 3)) # 将temp分为三组,注意一定要需要能够整除 ''' [array([0, 1, 2]), array([3, 4, 5])] [array([0, 1]), array([2, 3]), array([4, 5])] ''' before_split = stark0 print('***', before_split, '****') print(before_split.shape) ''' [[[0.74089229 0.57562171 0.49771472 0.95476674] [0.69835637 0.96123423 0.13564096 0.13647637] [0.06188776 0.02990894 0.10576619 0.76679994]] [[0.59469834 0.60684601 0.06526331 0.60184017] [0.09829733 0.75589599 0.45508954 0.89260168] [0.91433361 0.38032825 0.67378012 0.42212192]] [[0.9679411 0.4151054 0.38370863 0.18417247] [0.09062706 0.91781885 0.83342553 0.63371066] [0.33065516 0.69382064 0.21145002 0.8403751 ]] [[0.66457937 0.28737569 0.20606387 0.90673566] [0.21208279 0.0349772 0.16535588 0.24558066] [0.71858388 0.40978055 0.75868467 0.23043895]] [[0.67202567 0.2178853 0.26290549 0.41040766] [0.42430938 0.01558304 0.68961009 0.16342541] [0.99158998 0.75487652 0.51044091 0.78979936]]] ''' s0 = np.split(before_split, 5, axis=0) # 从第一个维度分为5个 print(s0, s0[1], s0[1].shape) s1 = np.split(before_split, 3, axis=1) # 从第二个维度分为3个 print(s1) s2 = np.split(before_split, 4, axis=2) # 从第三个维度分为4个 print(s2) ''' [array([[[0.74089229], [0.69835637], [0.06188776]], [[0.59469834], [0.09829733], [0.91433361]], [[0.9679411 ], [0.09062706], [0.33065516]], [[0.66457937], [0.21208279], [0.71858388]], [[0.67202567], [0.42430938], [0.99158998]]]), array([[[0.57562171], [0.96123423], [0.02990894]], [[0.60684601], [0.75589599], [0.38032825]], [[0.4151054 ], [0.91781885], [0.69382064]], [[0.28737569], [0.0349772 ], [0.40978055]], [[0.2178853 ], [0.01558304], [0.75487652]]]), array([[[0.49771472], [0.13564096], [0.10576619]], [[0.06526331], [0.45508954], [0.67378012]], [[0.38370863], [0.83342553], [0.21145002]], [[0.20606387], [0.16535588], [0.75868467]], [[0.26290549], [0.68961009], [0.51044091]]]), array([[[0.95476674], [0.13647637], [0.76679994]], [[0.60184017], [0.89260168], [0.42212192]], [[0.18417247], [0.63371066], [0.8403751 ]], [[0.90673566], [0.24558066], [0.23043895]], [[0.41040766], [0.16342541], [0.78979936]]])] '''
今天在做数据分析的时候,忽然发现 std有问题,我擦这他妈的是什么鬼,赶紧在终端作了一个测试
a = [1, 2, 3, 4, 5, 6] data = pd.Series(a) print(data.std()) print(np.std(a)) >>>> 1.8708286933869707 1.707825127659933
我擦这都能算错了?
按照道理说应该是不会的
so看了一下官方文档
在numpy求标准差的时候,需要加上参数
np.std(a, ddof=1)
真的是神坑
