



版权声明:本文系博主原创,未经博主许可,禁止转载。保留所有权利。
引用网址:https://www.cnblogs.com/zhizaixingzou/p/9992847.html
目录

1. 泛型
1.1. 解决什么问题
先来看如下的一个类,它封装了一个String类型的值。
1 public class StringEntry { 2 private String value; 3 4 public void setValue(String value) { 5 this.value = value; 6 } 7 8 public String getValue() { 9 return value; 10 } 11 }
现在,我需要再封装一个Integer类型的值,一个很自然的想法是再定义一个IntegerEntry类。然而此法有不足之处,即如果我需要再封装一些其他类型的值,那么就需要再定义对应的这么多的类,哪怕它们的定义如此类似,即复用性不好。
考虑到Object类是所有类的超类,可以定义一个类,用它来封装Object类型的值,定义了这个类,就不用再定义上面的许多类了。
1 public class ObjectEntry { 2 private Object value; 3 4 public void setValue(Object value) { 5 this.value = value; 6 } 7 8 public Object getValue() { 9 return value; 10 } 11 }
这样的实现,也是早期Java实现集合框架采用的策略:继承多态。
然而,这个基于Object继承的多态实现有两个问题:一是get方法返回的是Object对象,使用该对象时需要显式地强制转换为我们需要的类型,二是使用set方法时,即使加入了我们不期望的类型的对象,编译器也不会产生任何的错误提示,我们取出该对象时,若仍按期望的类型转换就会抛异常,即类型不安全。
从C++的类型模板特性得到启发,Java在Java 5引入了泛型的概念以解决这个问题。就是在定义一个类时可以加入类型参数,使类成为泛型类。
1 public class Entry<T> { 2 private T value; 3 4 public void setValue(T value) { 5 this.value = value; 6 } 7 8 public T getValue() { 9 return value; 10 } 11 }
这样以后,在外部使用get方法时,如果用类型参数的实际类型的变量来接纳它,那么返回的就是我们需要的类型的实例,无须强制转换,因为编译器自动加入了类型转换指令(当然,如果没有变量接纳,而单纯调用get方法,则返回类型参数的边界类型的实例)。对应地,在外部使用set方法时,如果传入的不是我们期望的类的实例,则会编译报错,这是编译器在编译时自动进行类型检查的缘故。总之,在使用泛型类时,编译器会帮我们自动完成类型检查和强制转换的工作。
1.2. 泛型的用法
1.2.1. 声明泛型类的变量时可给出类型参数的实际类型
对于上面定义的Entry<T>,可以像下面这样使用。
1 public static void main(String[] args) { 2 Entry<String> entry = new Entry<String>(); 3 entry.setValue("hello world"); 4 }
可以看到,声明泛型类的变量时可给出类型参数的实际类型。当然,这里的“给出类型参数的实际类型”的“实际类型”可以是确定的,如这里的String,也可以不确定,而是一个范围,也就是后面要讲的通配符。
1.2.2. 可为类型参数指定边界类型
可为类型参数指定边界类型,如下。
1 <T extends Comparable<T>> 2 <K, V extends Vector & Runnable>
其中,extends后的类型为边界类型,可以是一个类或接口,或后面还可以使用“&”连接多个接口。
<E>实际等效于<E extends Object>。
指定边界类型的好处在于,可以确定类型参数具有边界类型的某些方法,以便编译期就可以使用这些方法,如上面的T类型的实际类型必然具有compareTo方法。
1.2.3. 泛型类可以有多个类型参数
所谓泛型类,是指具有一个或多个类型参数的类。
1 public class Pair<K, V> { 2 private K key; 3 private V value; 4 5 public void setKey(K key) { 6 this.key = key; 7 } 8 9 public K getKey() { 10 return key; 11 } 12 13 public void setValue(V value) { 14 this.value = value; 15 } 16 17 public V getValue() { 18 return value; 19 } 20 }
泛型类Pair<K, V>的类型参数为K、V。这里的K为Key的首字母,代表键的意思,V为Value的首字母,代表值的意思。常用的类型参数名还有E(Element)、T(Type)等,当然用其他字母也是可以的。
泛型类的使用如下。
1 Pair<String, Integer> pair = new Pair<String, Integer>()
1.2.4. 泛型方法的定义和使用
所谓泛型方法,是带有类型参数的方法,既可以定义在泛型类中,也可以定义在普通类中。
1 public class Util { 2 public static <K, V> boolean process(Pair<K, V> pair) { 3 return true; 4 } 5 }
类型参数定义于修饰符的后面和返回类型的前面,之所以不放在方法名后,是因为返回类型也可能是类型参数指定的类型。
泛型方法的使用如下。
1 Util.<String, Integer>process(new Pair<String, Integer>())
或者
1 Util.process(new Pair<String, Integer>())
后一个利用了Java 1.7引入的类型推导。
1.2.5. 类型参数的继承关系不会传递给泛型类
1.2.5.1. 不同类型参数的泛型类实例无关系
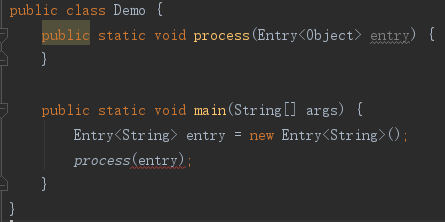
虽然String是Object的子类,但是Entry<String>却不是Entry<Object>的子类,它们甚至都不是类与类的关系,它们都属于Entry的一种使用方式。也就是说,类型参数的继承关系不会传递给泛型类实例。在这里,我们不妨创造一个概念,就是泛型类实例,它不是类的概念,也不是对象的概念,乃是对泛型类的一种使用方式,也可以叫泛型类的使用模式,不同的模式,对应着不同的类型参数,对应着不同的类型检查和类型转换。也就是说,类不能根据类型参数的多少和顺序来区分,类型参数仅只是使用方式的概念。
顺便看一个例子。
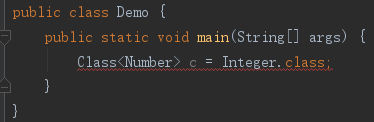
可以看出,Integer.class是一个对象,它的类型应该为Class<Integer>或其子类,这里有了一个新概念,对象可以属于某种使用方式。
1.2.5.2. 通配符的类型限定
上面说了,类型参数的继承关系并不会传递给泛型类实例,这有点不符我们的思维习惯。为解决这个问题,引入了通配符。
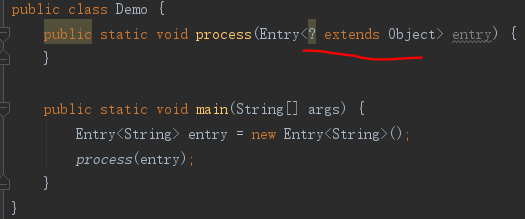
<? extends Object>的代码形式叫做通配符的子类型限定,通常用作协变。还有通配符的超类型限定,代码形式是<? super Integer>,通常用作逆变。无限定的通配符为<?>。
关于通配符的用法如下。
1 public Method getMethod(String name, Class<?>... parameterTypes) 2 public static Class<?> forName(String className) 3 public native Class<? super T> getSuperclass() 4 Class<? super T> c = getSuperclass() 5 public <U> Class<? extends U> asSubclass(Class<U> clazz) { 6 return (Class<? extends U>) this 7 public <A extends Annotation> A getAnnotation(Class<A> annotationClass) 8 return (A) annotationData().annotations.get(annotationClass)
可以看出,通配符?可用于方法参数、方法返回、变量类型声明、变量强制转换等处,即?用在泛型类或泛型方法的使用上,而不用在泛型类的定义上。
Entry<Integer>在使用上来讲,是一个Entry<?>。这不是“is-a”的关系,因为“is-a”是静态的类与类的概念。这也不是泛型类实例间的关系,而只能是一种泛型类实例属于某个泛型类实例范围的概念,通配符?的类型限定表达的正是范围的概念。
1.2.5.3. 协变与逆变
下面的语法有问题。对编译器而言,list的类型参数可以是任何Object的子类(编译期根据声明而非实例化来确定),是不确定的,是一个范围,现在给确定的String于它显然不合适,因为list的类型参数可以是Integer等。

下面的就没有问题了。对编译器而言,list的类型参数可以是任何String的超类,也是不确定的,现在给确定的String于它却是合适的,因为list的类型参数虽然不确定,但一旦确定下来,它总是String的超类,可以接受String类型的值。
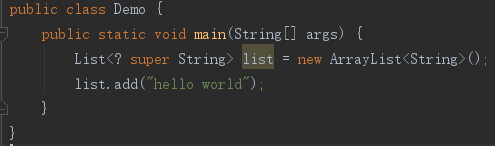
这里的list是用来添加元素的,对元素来说,它是消费者,因而有Consumer Super一说。完整的理解就是:对于被“吞进”的元素来说,list是消费者,为了完成“吞进”工作,它应该使用通配符的超类型限定。
然而,这样的使用了super的list就不能成为Producer了,即不能用来“吐出”元素。类似分析,即编译器认为list的类型参数可以是任何String的超类,是不确定的,现在用String来接纳它显然不合适,因为list的类型参数可以是Object。
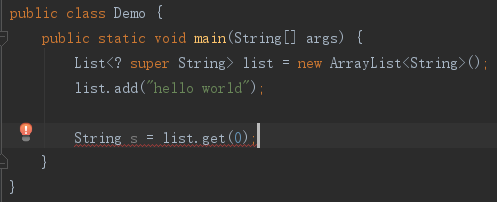
解决的方法是,list又定义回使用extends,这就是Producer Extends一说的由来。
可以看到Producer Extends和Consumer Super是不能兼容的,只能二居其一,这就是PECS原则。总结一下就是:对于集合类,如果是只读的,则为Producer,使用extends,为协变,如果是只写的,则为Consumer,使用Super,为逆变,进一步简记为“协读PE,逆写CS”。
下面看个例子,Collections类同时使用了两者。
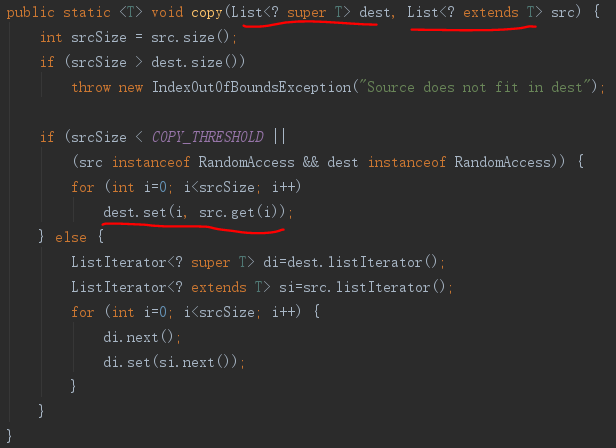
1.2.5.4. 空型泛型类实例
对Entry<T>来说,Entry有定义和使用两个方面的含义。作为定义泛型类的一面说,Entry被称为原始类型,作为使用泛型类的一面说,Entry等价于Entry<边界类型>,是确定的泛型类实例,不同于Entry<?>是一个泛型类实例范围,为了便于描述,不妨称它为空型泛型类实例,空型泛型类实例等价于边界类型的泛型类实例。比如下面的list1,乃是List<Object>,因而添加String是可以的。但list2是List<?>,可以是任何的类,现在给它赋值String,但它如果是List<Integer>就会出错。
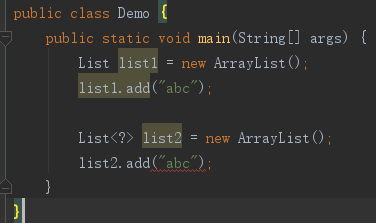
再来看空型泛型类实例的字节码,处理是使用边界类型来的:
1 public class Demo { 2 public static void main(String[] args) { 3 List list1 = new ArrayList(); 4 list1.add("abc"); 5 } 6 }
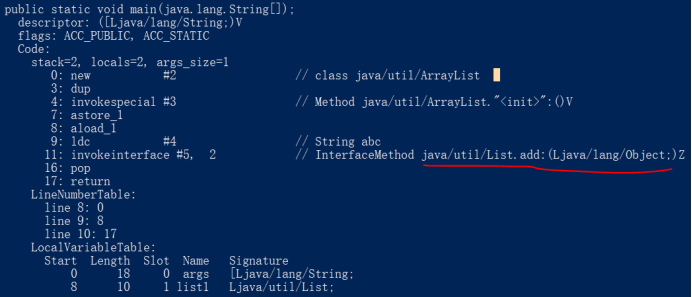
再看下面的例子:
1 public class Entry<T extends Number> { 2 private T value; 3 4 public void setValue(T value) { 5 this.value = value; 6 } 7 8 public T getValue() { 9 return value; 10 } 11 }
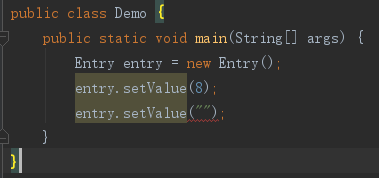
Entry实际上等价于Entry<Number>,不等价于Entry<Object>,所以赋值String时出错。
1.2.6. 泛型使用的注意事项
1.2.6.1. 不能用基本类型来实例化类型参数
用则必须用它们的包装类。

这是因为,编译后类型参数被擦除,原始类中的类型变量(T)替换为Object,但Object类型不能存储基本类型的值。
1.2.6.2. 泛型类不能继承Throwable
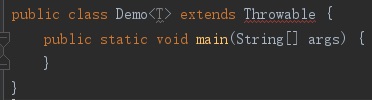
但异常声明中可以使用类型参数。

1.2.6.3. 不能创建组件类型为参数化类型的数组
Object[]可以是任何数组的父类。

不能创建组件类型为参数化类型的数组,但可以声明。
1 Pair<String, String>[] pairs = (Pair<String, String>[]) new Pair[10]
1.2.6.4. 泛型类静态成员不可使用泛型类的类型参数

1.2.6.5. 其他
下面是可以的:
1 public class Demo { 2 public static void main(String[] args) { 3 Entry<String> entry = new Entry<String>(); 4 System.out.println(entry instanceof Entry<?>); 5 System.out.println(entry instanceof Entry); 6 } 7 }
但下面就不行:
1 entry instanceof Entry<String>
总结来看,注意事项能根据原理解释几个就行,不必刻意去掌握全了。多提一嘴,因为这些规则终究是编译器或JVM的代码逻辑:有的是绝对不能怎样的,有的则是一种可与不可的选择,甚至是编码者的一个临时随意,他这样要求而已,而有些甚至是其功能实现的副作用,对于这样的原因,需要了解编译后的字节码或者JVM代码才能弄清。但这不总是有必要的,因为即便是编码者本人,也许都不清楚,而且近乎全部的使用都不会触及副作用。总之,只要能用其精髓,分析懂别人代码,遇到错能分析就已经足够,除非自己要搞一套编译器或JVM,做得更好,或者发生了某种平台性的bug,则才细究另论。
1.3. 泛型的实现原理
1.3.1. 类型擦除
1.3.1.1. 定义泛型类时对应类型参数的地方都用边界类型
先看下面的类。
1 public class Pair<K extends Number, V> { 2 private K key; 3 private V value; 4 5 public Pair(K key, V value) { 6 this.key = key; 7 this.value = value; 8 } 9 10 public void setKey(K key) { 11 this.key = key; 12 } 13 14 public K getKey() { 15 return key; 16 } 17 18 public void setValue(V value) { 19 this.value = value; 20 } 21 22 public V getValue() { 23 return value; 24 } 25 }
编译器会将泛型类所有的对应类型参数的地方替换为边界类型,而泛型类本身对应到原始类型,它是泛型类使用时的模板,以得到最终的字节码文件。
编译后,构造方法的字节码如下:

可以看到,参数key被保存为边界类型Number,而参数value被保存为默认的边界类型Object。set方法与之类似。
编译后,getKey方法的字节码如下:
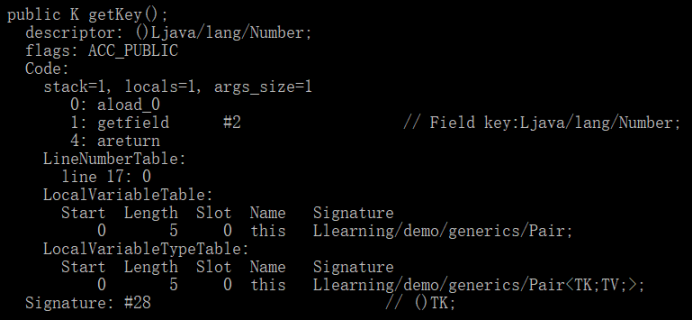
可以看到,字段存储使用的是Number类型,而方法描述符中返回类型也是Number。
1.3.1.2. 使用泛型类时使用类中会自动类型检查和强制转换
来看对泛型类的使用:
1 public class Demo { 2 public static void main(String[] args) { 3 Integer key = 5; 4 String value = "hello world"; 5 Pair<Integer, String> pair = new Pair<Integer, String>(key, value); 6 Integer i = pair.getKey(); 7 } 8 }
下面看main方法的字节码:
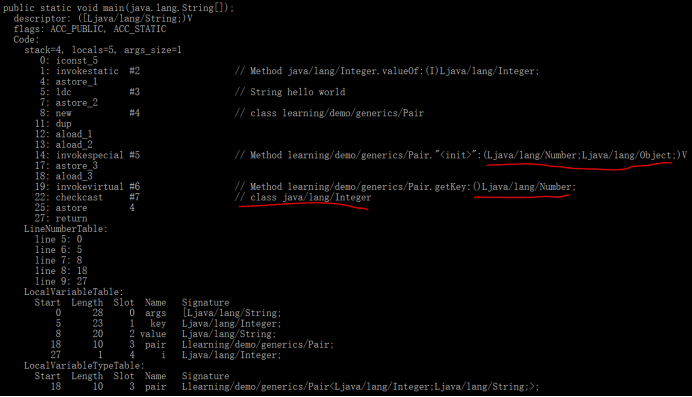
可以看到,在调用构造方法时,会把参数存为边界类型(set也类似)。在获取值时,自动加了一个类型转换指令,由Number转换为Integer。需要注意的是,如果编码时,构造方法参数或set方法参数类型不是实际类型的,则编译不过,因为编译器会作类型检查,如果编译通过,则还是通过边界类型存储,而不是实际类型。
总之,泛型类定义时,在字节码上只保留了原始类型和对边界类型的使用,当然也保留了它的类型参数标识。在泛型类使用时,编译器替我们完成了类型检查及强制转换的工作,不同目标类型的类型检查及强制转换,完成了不同动态类型的区别功能,因而动态类型就没有必要而被“擦除”了,因而这种泛型的实现机制被称为类型擦除。类型擦除也会发生于泛型方法中,如泛型方法public static <T extends Comparable> T min(T[] a)编译后会变成下面这样:public static Comparable min(Comparable[] a)。
因为Java泛型是通过类型擦除实现的,本质上是边界类型的继承多态实现的,而非每一个类型参数实例都对应一个类定义,因而是伪泛型。伪泛型的好处在于兼容了之前的继承多态版本(如早期Java的集合框架就是使用Object继承多态实现的,伪泛型便于保持向下兼容),也可以防止类型膨胀。泛型是继基类继承、接口实现后的有一种泛化机制。
1.3.1.3. 通过泛型的实现原理分析一个实例
下面的代码没有报错:
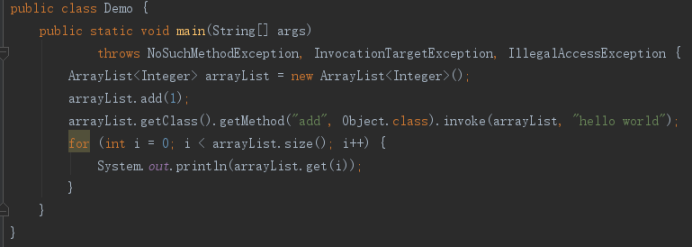
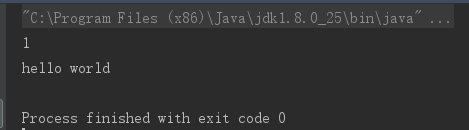
ArrayList的类型参数指定为Integer,加入1是自然的,而加入字符串未报错又是为何?这是因为ArrayList使用了反射语法,添加操作已经不在ArrayList类里发生,在编译期都识别不出这是add操作,因而编译期检查通过了。运行的时候,调用的是add(Object),所以也没有问题。接下来,println方法需要的参数是Object,所以编译的字节码结果是arrayList.get(i)返回的是Object,没有强制类型转换操作。而最终打印出这个字符串,则是因为println一个Object的时候,通过invokevirtual指令调用了子类,即String类的重写toString方法。
但下面的报错了:
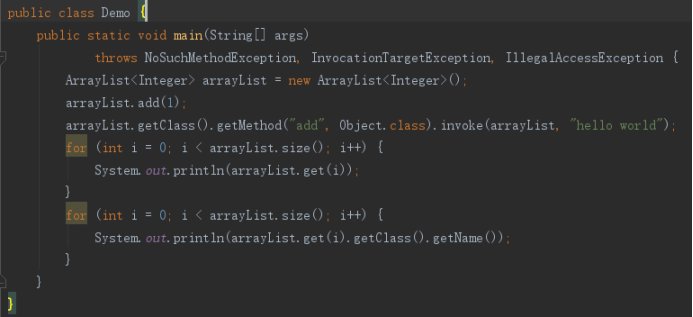
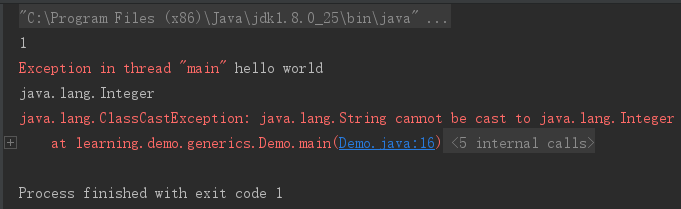
这是因为,虽然arrayList.get(i)获得的是Object,但马上的操作是getClass,编译器作了强制类型转换为实际的类型参数类型。原来通过Object类型保存的字符串,要转换为显式的Integer,就发生错误了。
1.3.2. 桥接方法
类型擦除会引入新问题。
看下面的类。
1 public class IntegerStringPair extends Pair<Integer, String> { 2 public IntegerStringPair(Integer key, String value) { 3 super(key, value); 4 } 5 6 @Override 7 public void setValue(String value) { 8 super.setValue(value); 9 } 10 }
子类会从Pair类继承setValue方法,Pair类的这个方法如下:
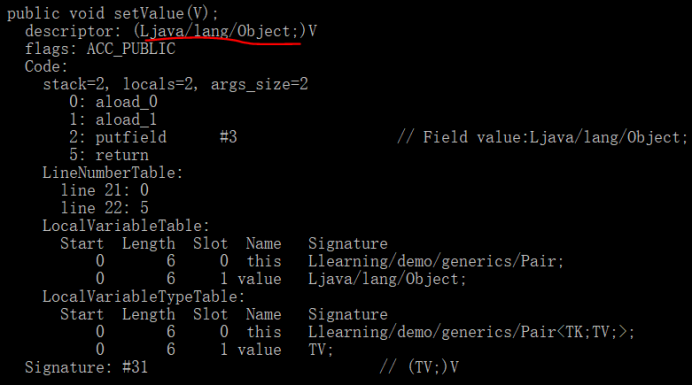
可以看到这个方法的签名是public void setValue(Object),而子类的签名是public void setValue(String),即子类的本意是要覆写父类的该方法,但实际上变为了方法重载。
1 public class Demo { 2 public static void main(String[] args) { 3 Pair<Integer, String> pair = new IntegerStringPair(5, "hello world"); 4 pair.setValue("oh"); 5 } 6 }
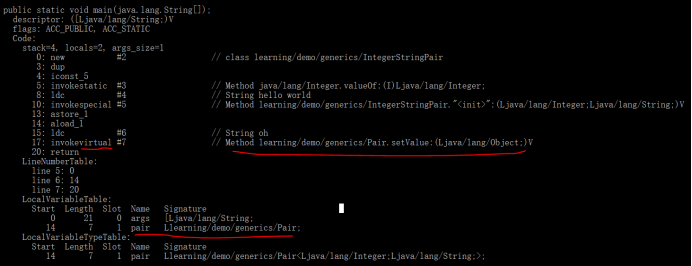
此时,pair.setValue(“oh”)调用的是父类的setValue(Object),因为发现子类没有覆写方法,所以调用到这里就结束了。这是违背动态调用指令invokevirtual和覆写语法的本意的。
为了弥补,编译器引入了桥接方法,即在子类中覆写从泛型继承来的方法(这是自动完成的,无需人工干预,下面的第二个setValue):
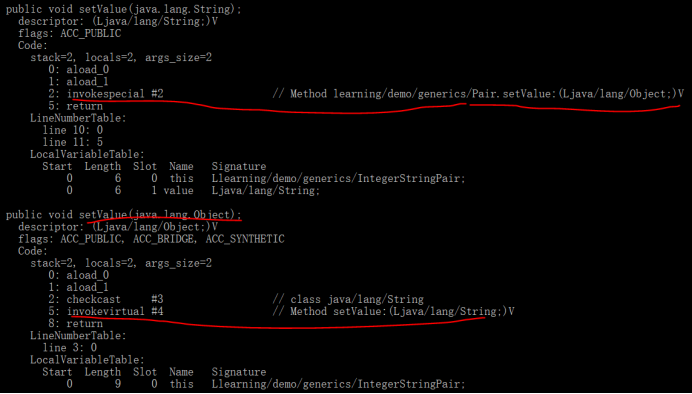
pair.setValue(“oh”)调用的就是子类的这个setValue(Object)了,可以看到这个桥接方法转换类型后,又调用子类的setValue(String),这样从外观效果上看pair.setValue(“oh”)调用了子类的setValue(String),这正是“桥接”的意义所在。顺便说一句,子类setValue(String)里面的super.setValue(value)调用父类的setValue(Object)则是与此无关的方法自身的逻辑了。
1.4. 参考资料
http://www.importnew.com/24029.html
http://www.importnew.com/19740.html
http://blog.csdn.net/sunxianghuang/article/details/51982979
http://www.importnew.com/21694.html

