



版权声明:本文系博主原创,未经博主许可,禁止转载。保留所有权利。
引用网址:https://www.cnblogs.com/zhizaixingzou/p/10066683.html
目录

1. 正则表达式
1.1. 编码实例
1.1.1. 数据的格式校验
package com.cjw.learning.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo01 {
private static final Pattern PATTERN = Pattern.compile("^0x[0-9A-Fa-f]{40}$");
private static boolean isIllegalAddress(String address) {
Matcher matcher = PATTERN.matcher(address);
return matcher.matches();
}
public static void main(String[] args) {
boolean illegal = isIllegalAddress("0x0123456789abcde0123456789abc8df6ee9ab7ab");
System.out.println(illegal);
}
}
输出如下:

这里假设我们有用到一种地址,是长度为40的16进制串,这样的场景还有很多,就是某种数据应该满足一定的格式,如邮箱地址。
对于这样一类问题,我们常常需要将正则表达式预先编译,然后对具体的数据,直接进行模式匹配,这可以提升校验的速度。
1.1.2. 正则表达式的语法错误捕获
package com.cjw.learning.regex;
import java.util.regex.Pattern;
import java.util.regex.PatternSyntaxException;
public class Demo02 {
public static void main(String[] args) throws InterruptedException {
try {
Pattern.compile("p1weds\\g\\u");
} catch (PatternSyntaxException e) {
System.out.println(e.getPattern());
System.out.println(e.getIndex());
System.out.println(e.getDescription());
System.out.println(e.getMessage());
Thread.sleep(1000);
e.printStackTrace();
}
}
}
输出如下:
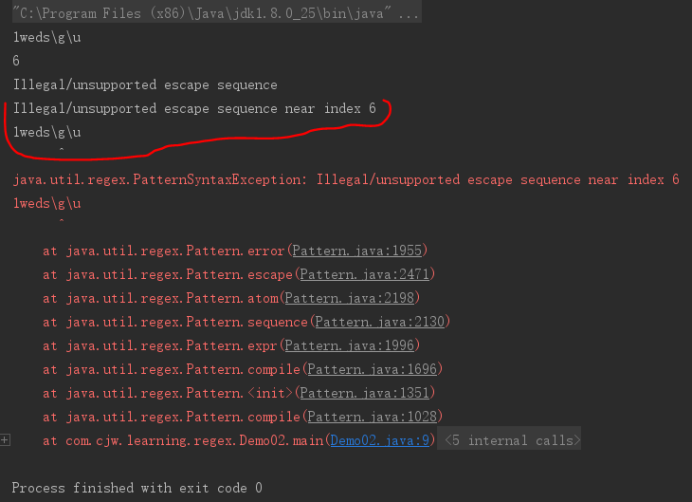
这里的正则表达式为“p1weds\\g\\u”,其中的“\g”及“\u”都是错误的语法。但程序不等全部检查完,而是在遇到第一个错误的语法时就抛PatternSyntaxException异常了。
下面是该异常的定义:

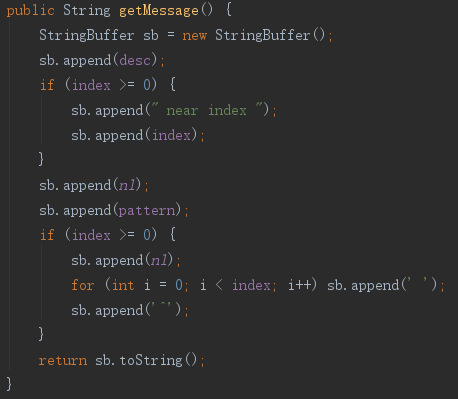
可以看到,该异常是一个非受检异常。
pattern,即正则表达式本身。
index,出现语法错误的位置,即第几个字符发现问题,从0开始计数。
desc,关于语法错误的描述信息,如这里显示非法或不支持的转义。
1.1.3. 捕获组
import java.util.regex.Pattern;
public class Demo03 {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("cd(efg).{3}(klm(.op))qr");
Matcher matcher = pattern.matcher("abcdefghijklmnopqrstuvwxyz");
System.out.println(matcher.groupCount());
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
}
}
}
输出如下:

程序输出了正则表达式小括号对应的所有捕获组。退一步解释下:捕获组是目标串的子串,它通过小括号内的子正则表达式匹配。捕获组的编号是以正则表达式左小括号的顺序来编号的。如“(efg).{3}(klm(.op))”,对应的捕获组编号为:
(efg)->1
(klm(.op))->2
(.op)->3
其中,索引为0的捕获组始终是整个正则表达式匹配到的子串,不计入groupCount。
1.1.4. 匹配操作的结果
package com.cjw.learning.regex;
import java.util.regex.MatchResult;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo04 {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("cd(efg).{3}(klm(.op))qr");
Matcher matcher = pattern.matcher("abcdefghijklmnopqrstuvwxyz");
if (matcher.find()) {
MatchResult matchResult = matcher.toMatchResult();
System.out.println(matchResult.groupCount());
System.out.println(matchResult.group());
System.out.println(matchResult.group(0));
System.out.println(matchResult.group(1));
System.out.println(matchResult.group(2));
System.out.println(matchResult.group(3));
System.out.println(matchResult.start());
System.out.println(matchResult.start(0));
System.out.println(matchResult.start(1));
System.out.println(matchResult.start(2));
System.out.println(matchResult.start(3));
System.out.println(matchResult.end());
System.out.println(matchResult.end(0));
System.out.println(matchResult.end(1));
System.out.println(matchResult.end(2));
System.out.println(matchResult.end(3));
}
}
}
输出如下:
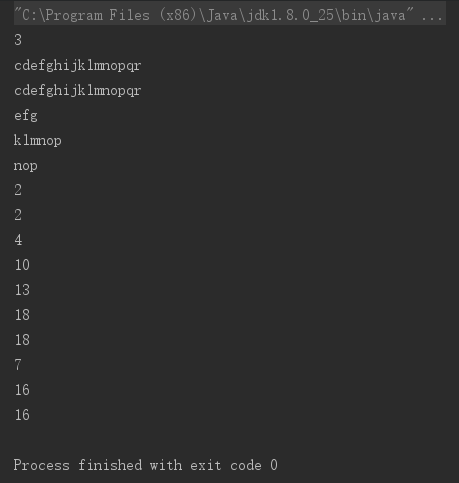
匹配操作的结果显示了每个捕获组相对于目标串的起始匹配位置、终止匹配位置,以及匹配到的子串。对应的方法中,没有参数的相当于参数为0,从源代码可以看到这点。
1.1.5. 目标串可有多个匹配
package com.cjw.learning.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo05 {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("a");
Matcher matcher = pattern.matcher("abcdefghijklmnopqrstuvwxyz,abcdefghijklmnopqrstuvwxyz");
if (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
}
if (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
}
if (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
}
}
}
输出如下:
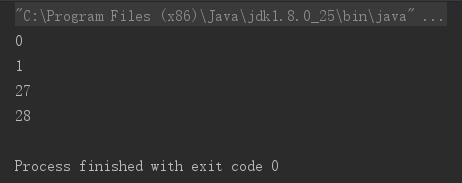
可以看成,matcher.find方法实际上是只要匹配过程中一旦匹配到,就立马结束,哪怕还没有匹配完整个目标串。当此方法返回为false,则表示整个目标串没有可再匹配的了。
1.1.6. 特殊字符匹配
package com.cjw.learning.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo06 {
public static void main(String[] args) {
Pattern pattern = Pattern.compile(Pattern.quote("\\") + "\\07");
Matcher matcher = pattern.matcher("abcdefghijklmnopqrstuvwxyz\\\07abcdefghijklmnopqrstuvwxyz");
if (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
}
if (matcher.find()) {
System.out.println(matcher.start());
System.out.println(matcher.end());
}
}
}
输出如下:
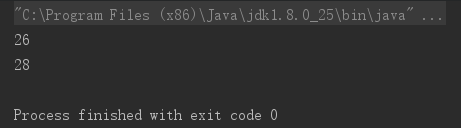
反斜杠的模式匹配在写正在表达式时有些特殊,如程序。
1.1.7. 范围匹配
package com.cjw.learning.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo07 {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("^([abc]{3}de[^xyz]g[a-z]ijk[lmn&&[lxy]]mn)\\d\\Dpq\\w\\p{Lower}");
Matcher matcher = pattern.matcher("abcdefghijklmn8opqrstuvwxyz,abcdefghijklmnopqrstuvwxyz");
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
}
}
}
输出如下:
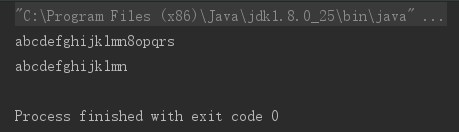
1.1.8. 量词匹配
package com.cjw.learning.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo08 {
private static void greediness() {
Pattern pattern = Pattern.compile("(a.+f)");
Matcher matcher = pattern.matcher("abcdefxyzflzy");
if (matcher.find()) {
System.out.println(matcher.group(1));
}
}
private static void reluctant() {
Pattern pattern = Pattern.compile("(a.+?f)");
Matcher matcher = pattern.matcher("abcdefxyzflzy");
if (matcher.find()) {
System.out.println(matcher.group(1));
}
}
private static void possessive1() {
Pattern pattern = Pattern.compile("(a\\w++@)");
Matcher matcher = pattern.matcher("abcdefxyzflz@y");
if (matcher.find()) {
System.out.println(matcher.group(1));
}
}
private static void possessive2() {
Pattern pattern = Pattern.compile("(a\\w++8)");
Matcher matcher = pattern.matcher("abcdefxyzflz@y");
if (matcher.find()) {
System.out.println(matcher.group(1));
}
}
public static void main(String[] args) {
greediness();
reluctant();
possessive1();
possessive2();
}
}
输出如下:
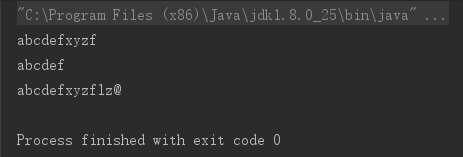
简单量词如下:
X?,匹配0或1次。
X*,匹配0或多次。
X+,匹配1或多次。
X{n},匹配n次。
X{n,},匹配至少n次。
X{n,m},匹配至少n次,至多m次。
量词匹配分3种类型:贪婪型、勉强型、所有型。简单量词就是贪婪型,简单量词后跟?就成为勉强型,跟+就成为所有型。
为了描述简便,我们不妨假设正则表达式为<prefix><quantifier><suffix>,其中quantifier是含X的量词,它是3种量词中的一种。
1)对于贪婪型,当<prefix>和第一个X匹配到后,就把目标串剩余的全部纳入<quantifier><suffix>匹配,如果匹配不上,就吐出最后一个字符再匹配,这样一直进行直到找到匹配或没有可再吞的字符为止。
2)对于勉强型,当<prefix>和第一个X匹配到后,就把后续的第一个字符纳入<quantifier><suffix>匹配,如果匹配不上,则新加入后续的第一个字符,这样一直进行直到找到匹配或没有更多可加的字符为止。
3)对于所有型,当<prefix>和第一个X匹配到后,就把后续的字符逐个匹配<quantifier>,每匹配完一次,就又往后,直到没有匹配为止,然后看目标串剩余字符是否匹配<suffix>,如果匹配则整个都匹配,否则不匹配。
1.1.9. 字符串替换
package com.cjw.learning.regex;
public class Demo09 {
private static void greediness() {
System.out.println("abcdefxyzflzy".replaceAll("a.+f", "*"));
}
private static void reluctant() {
System.out.println("abcdefxyzflzyabcdeff".replaceAll("a.+?f", "*"));
System.out.println("abcdefxyzflzyabcdeff".replaceFirst("a.+?f", "*"));
System.out.println("abcdefxyzflzyabcdeff".replace("xyzflzyab", "YYYYYY"));
System.out.println("abcdefxyzflzyabcdeff".replace('f', 'U'));
}
private static void possessive1() {
System.out.println("abcdefxyzflz@y".replaceAll("a\\w++@", "*"));
}
public static void main(String[] args) {
greediness();
reluctant();
possessive1();
}
}
输出如下:
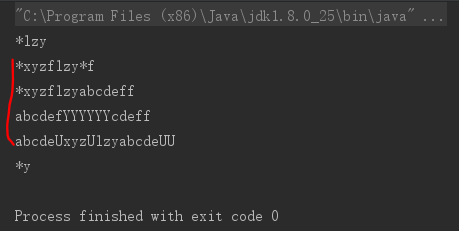
字符串的replaceAll,实际上是不停地调用Matcher.find,匹配到一次就替换一次。
replace如果是字符串,那么实际上是以旧字符串为正则表达式的replaceAll。
1.1.10. 字符串是否符合正则表达式
package com.cjw.learning.regex;
public class Demo10 {
public static void main(String[] args) {
System.out.println("abcdefxyzflzyabcdeff".matches("a.+?f"));
}
}
输出如下:
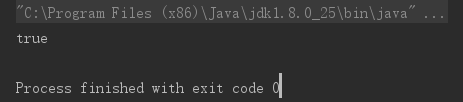
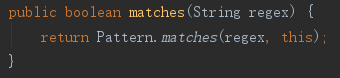
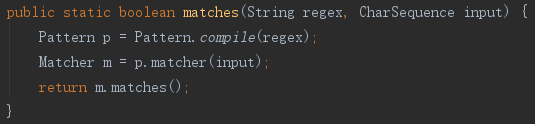
从下面看到,String的匹配实际上是转换为了Pattern,一切如常,但实际上只有整个字符串匹配才成功,也就是好像在正则表达式前后加了“^”和“$”,但源代码并没有显示这点,这个让人费解,是String模式匹配的一个坑?
java.lang.String#matches
1.2. 参考资料
https://docs.oracle.com/javase/9/docs/api/java/util/regex/Pattern.html
https://www.yiibai.com/javaregex/

