

1 import pandas as pd 2 3 time_sentences = ["Monday: The doctor's appointment is at 2:45pm.", 4 "Tuesday: The dentist's appointment is at 11:30 am.", 5 "Wednesday: At 7:00pm, there is a basketball game!", 6 "Thursday: Be back home by 11:15 pm at the latest.", 7 "Friday: Take the train at 08:10 am, arrive at 09:00am."] 8 9 df = pd.DataFrame(time_sentences, columns=['text']) 10 df

1 # find the number of characters for each string in df['text'] 2 df['text'].str.len()
0 46 1 50 2 49 3 49 4 54 Name: text, dtype: int64
1 # find the number of tokens for each string in df['text'] 2 df['text'].str.split().str.len()
0 7 1 8 2 8 3 10 4 10 Name: text, dtype: int64
1 # find which entries contain the word 'appointment' 2 df['text'].str.contains('appointment')
0 True 1 True 2 False 3 False 4 False Name: text, dtype: bool
1 # find how many times a digit occurs in each string 2 df['text'].str.count(r'\d')
0 3 1 4 2 3 3 4 4 8 Name: text, dtype: int64
1 # find all occurances of the digits 2 df['text'].str.findall(r'\d')
0 [2, 4, 5] 1 [1, 1, 3, 0] 2 [7, 0, 0] 3 [1, 1, 1, 5] 4 [0, 8, 1, 0, 0, 9, 0, 0] Name: text, dtype: object
1 # group and find the hours and minutes 2 df['text'].str.findall(r'(\d?\d):(\d\d)')
0 [(2, 45)] 1 [(11, 30)] 2 [(7, 00)] 3 [(11, 15)] 4 [(08, 10), (09, 00)] Name: text, dtype: object
1 # replace weekdays with '???' 2 df['text'].str.replace(r'\w+day\b', '???')
0 ???: The doctor's appointment is at 2:45pm. 1 ???: The dentist's appointment is at 11:30 am. 2 ???: At 7:00pm, there is a basketball game! 3 ???: Be back home by 11:15 pm at the latest. 4 ???: Take the train at 08:10 am, arrive at 09:... Name: text, dtype: object
1 # replace weekdays with 3 letter abbrevations 2 df['text'].str.replace(r'(\w+day\b)', lambda x: x.groups()[0][:3])
0 Mon: The doctor's appointment is at 2:45pm. 1 Tue: The dentist's appointment is at 11:30 am. 2 Wed: At 7:00pm, there is a basketball game! 3 Thu: Be back home by 11:15 pm at the latest. 4 Fri: Take the train at 08:10 am, arrive at 09:... Name: text, dtype: object
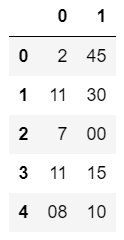
1 # create new columns from first match of extracted groups 2 df['text'].str.extract(r'(\d?\d):(\d\d)')
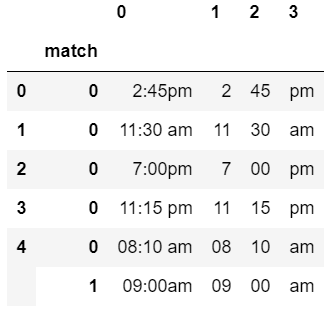
1 # extract the entire time, the hours, the minutes, and the period 2 df['text'].str.extractall(r'((\d?\d):(\d\d) ?([ap]m))')
1 # extract the entire time, the hours, the minutes, and the period with group names 2 df['text'].str.extractall(r'(?P<time>(?P<hour>\d?\d):(?P<minute>\d\d) ?(?P<period>[ap]m))')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号