#导入数据
1 %matplotlib notebook 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import pandas as pd 5 from sklearn.model_selection import train_test_split 6 7 fruits = pd.read_table('fruit_data_with_colors.txt')
1 fruits.head()
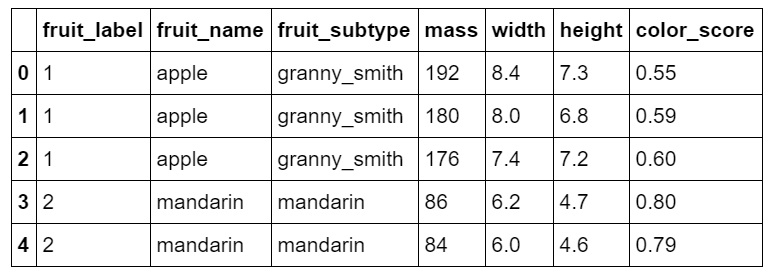
1 # 创建从fruit_label到fruit_name的映射 2 lookup_fruit_name = dict(zip(fruits.fruit_label.unique(), fruits.fruit_name.unique())) 3 lookup_fruit_name
{1: 'apple', 2: 'mandarin', 3: 'orange', 4: 'lemon'}
检验数据
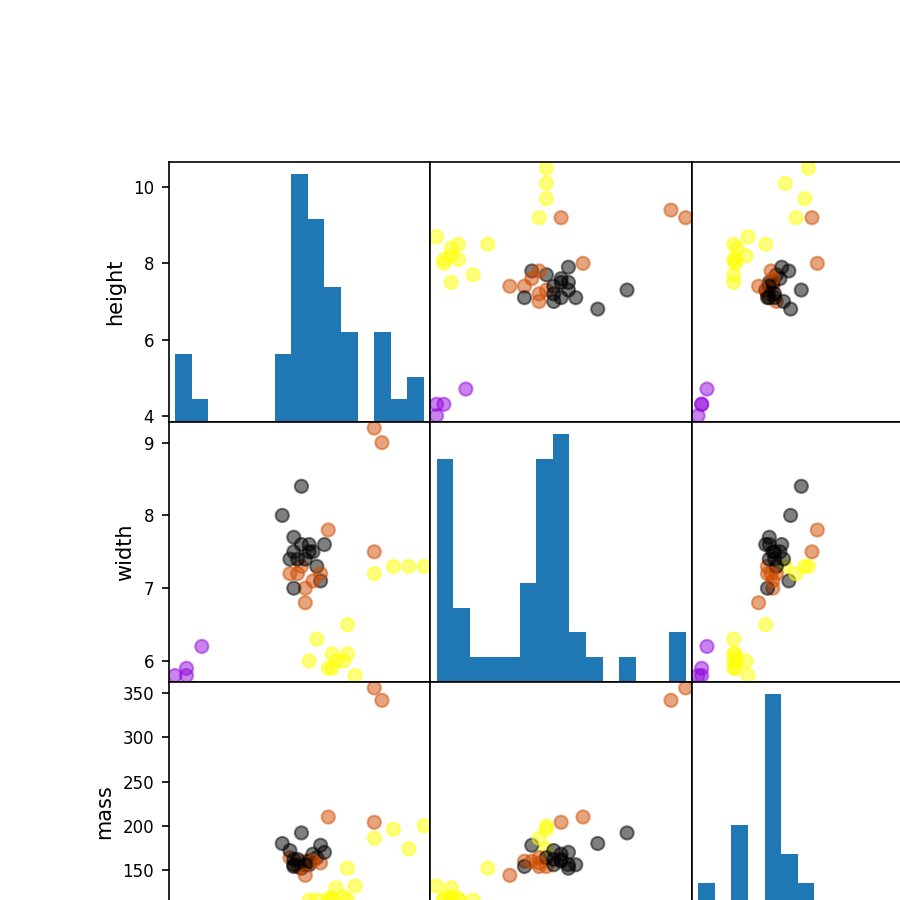
1 # 画点阵 2 from matplotlib import cm 3 4 X = fruits[['height', 'width', 'mass', 'color_score']] 5 y = fruits['fruit_label'] 6 #划分train和test数据集 7 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) 8 9 cmap = cm.get_cmap('gnuplot') 10 scatter = pd.scatter_matrix(X_train, c= y_train, marker = 'o', s=40, hist_kwds={'bins':15}, figsize=(9,9), cmap=cmap)
1 # 画3D点图 2 from mpl_toolkits.mplot3d import Axes3D 3 4 fig = plt.figure() 5 ax = fig.add_subplot(111, projection = '3d') 6 ax.scatter(X_train['width'], X_train['height'], X_train['color_score'], c = y_train, marker = 'o', s=100) 7 ax.set_xlabel('width') 8 ax.set_ylabel('height') 9 ax.set_zlabel('color_score') 10 plt.show()

1 # 把mass,width,height作为决定因素 2 X = fruits[['mass', 'width', 'height']] 3 y = fruits['fruit_label'] 4 5 # 默认 75% / 25% train-test split 6 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
#创建knn分类器
1 from sklearn.neighbors import KNeighborsClassifier 2 #n_neighbors分类数量 3 knn = KNeighborsClassifier(n_neighbors = 5)
1 #数据拟合 2 knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
使用test集来计算模型的准确性
1 knn.score(X_test, y_test)
0.53333333333333333
使用训练好的knn模型来预测新数据
1 # first example: a small fruit with mass 20g, width 4.3 cm, height 5.5 cm 2 fruit_prediction = knn.predict([[20, 4.3, 5.5]]) 3 lookup_fruit_name[fruit_prediction[0]]
'mandarin'
1 # second example: a larger, elongated fruit with mass 100g, width 6.3 cm, height 8.5 cm 2 fruit_prediction = knn.predict([[100, 6.3, 8.5]]) 3 lookup_fruit_name[fruit_prediction[0]]
'lemon'
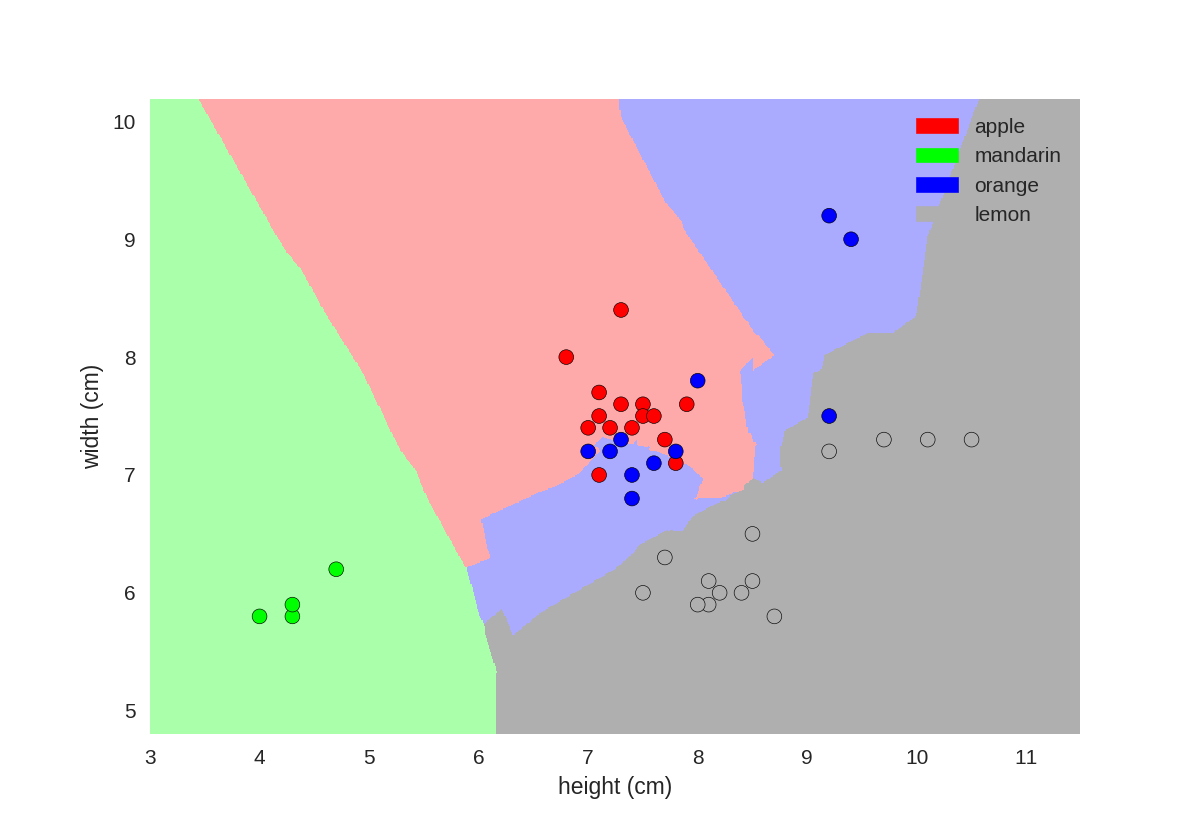
画knn的决策边界
1 from adspy_shared_utilities import plot_fruit_knn 2 3 plot_fruit_knn(X_train, y_train, 5, 'uniform') # we choose 5 nearest neighbors
knn中聚类个数k对最后准确率的影响
1 k_range = range(1,20) 2 scores = [] 3 4 for k in k_range: 5 knn = KNeighborsClassifier(n_neighbors = k) 6 knn.fit(X_train, y_train) 7 scores.append(knn.score(X_test, y_test)) 8 9 plt.figure() 10 plt.xlabel('k') 11 plt.ylabel('accuracy') 12 plt.scatter(k_range, scores) 13 plt.xticks([0,5,10,15,20]);
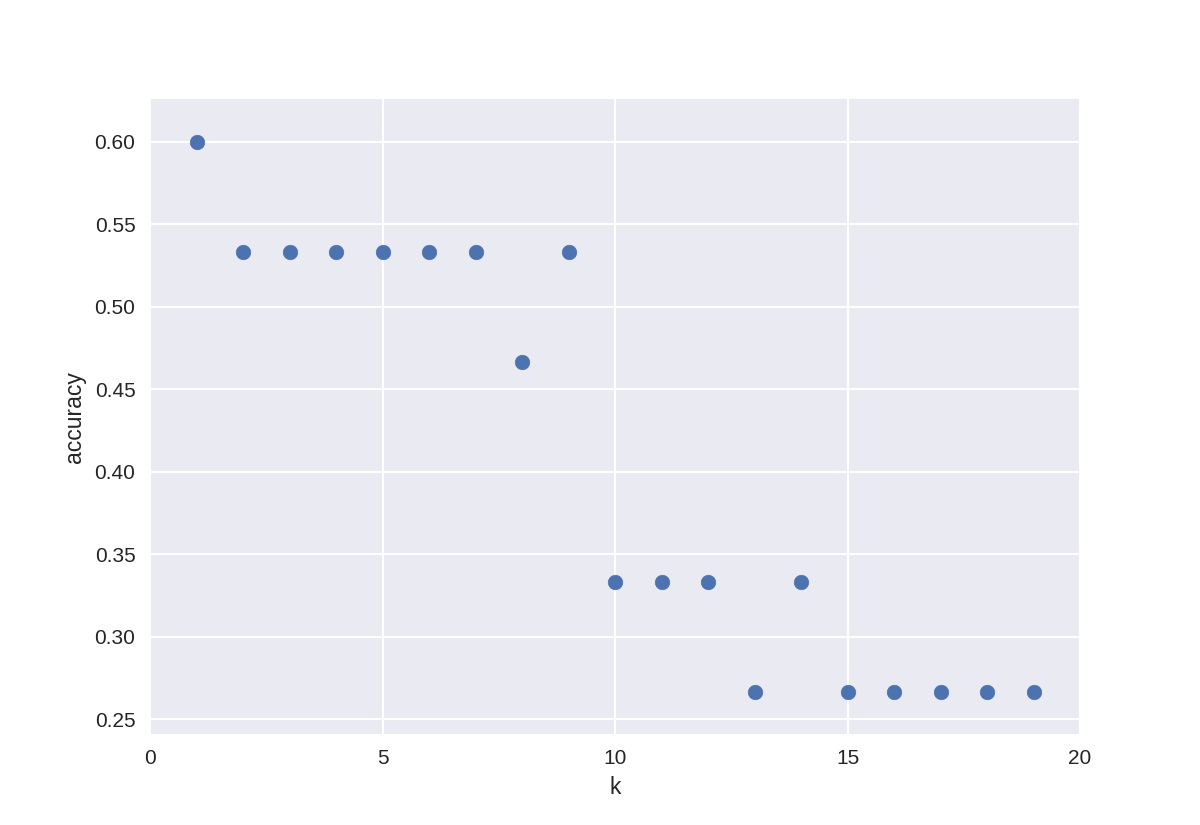
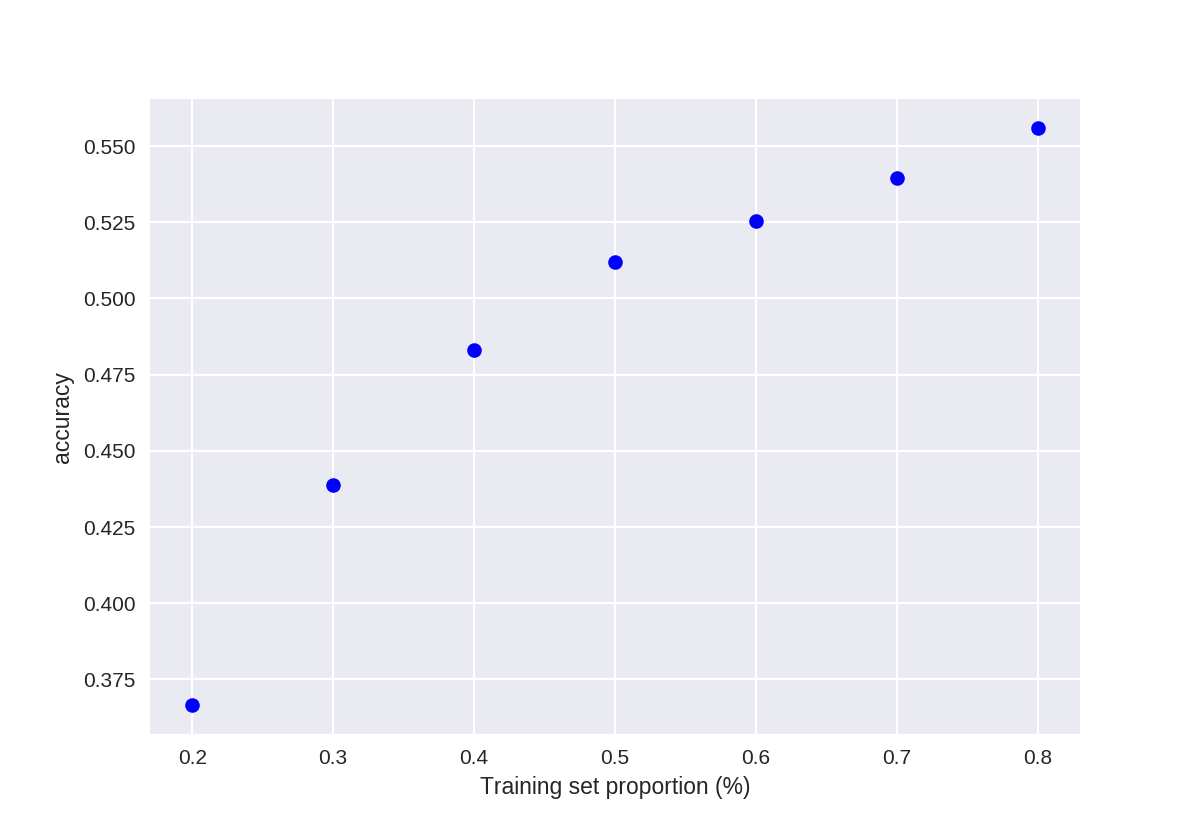
knn对数据集train/test划分比例的敏感性
1 t = [0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2] 2 3 knn = KNeighborsClassifier(n_neighbors = 5) 4 5 plt.figure() 6 7 for s in t: 8 9 scores = [] 10 for i in range(1,1000): 11 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1-s) 12 knn.fit(X_train, y_train) 13 scores.append(knn.score(X_test, y_test)) 14 plt.plot(s, np.mean(scores), 'bo') 15 16 plt.xlabel('Training set proportion (%)') 17 plt.ylabel('accuracy');