

无监督学习
聚类:对数据进行分类
1.K均值算法
先选两个中心
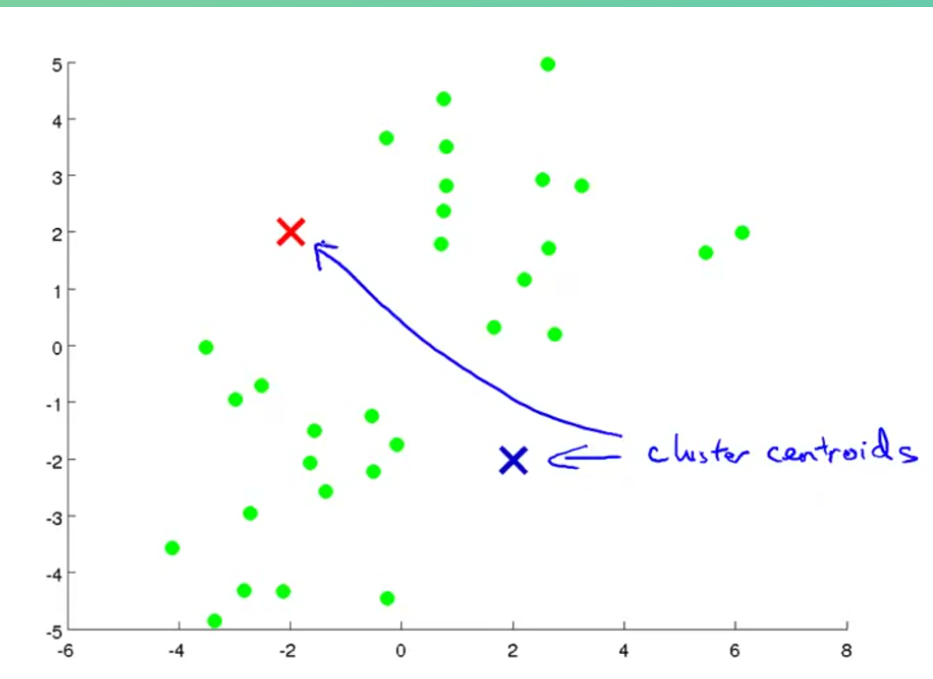
簇分类:
根据离两个点的距离远近,把数据分成两类
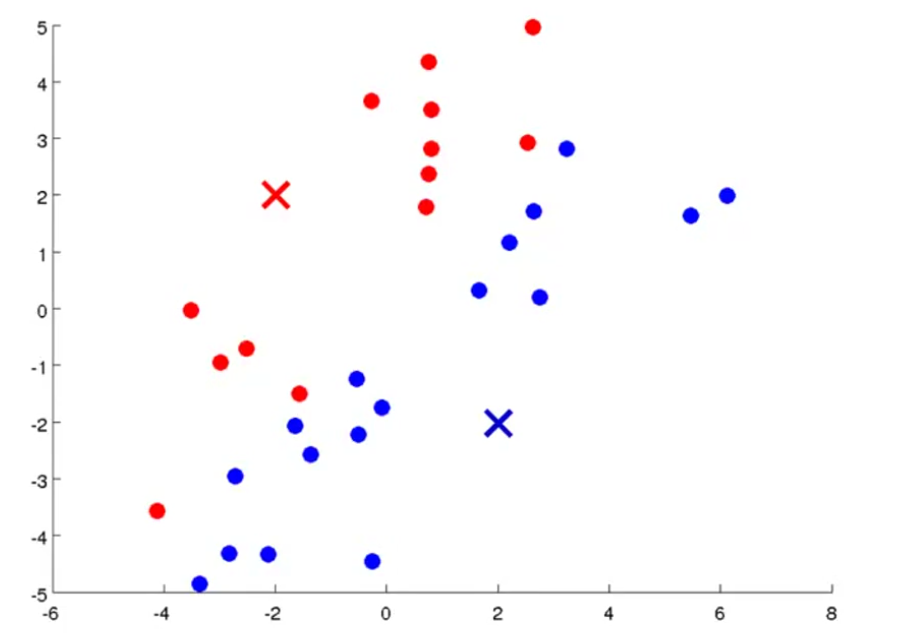
移动中心,移动到各类的中心:
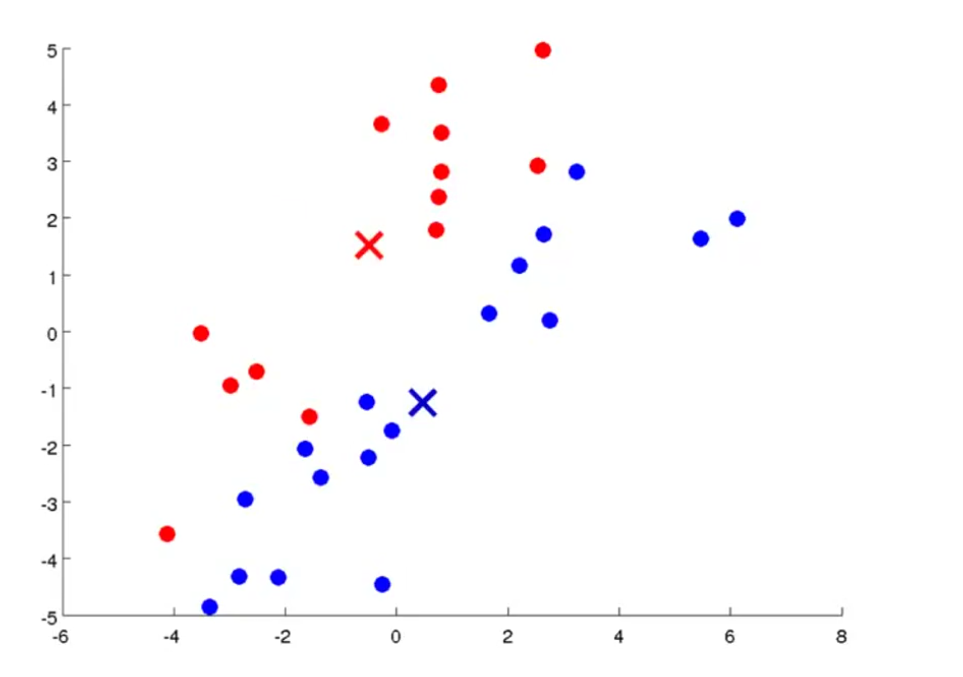
不断循环上面的步骤
输入:
1.K-分类的个数。
2.训练集
算法:

如果在循环过程中一个类没有和他最近的点,
1.移除这个类,也就是减少一个类
2.随机产生一个新的坐标
优化目标

c(i):离属于第i个中心的输入集
uk:第k个中心
uc(i) :相应的分类
相应的代价函数:

每次循环都在使代价函数的值减少。

初始化聚类中心:
1.随机产生聚类中心。
得到局部最优解,可能偏差很大
2.相比与随机产生有一种更好的方法,选择输入集中的点,但由于得到的是局部最优解
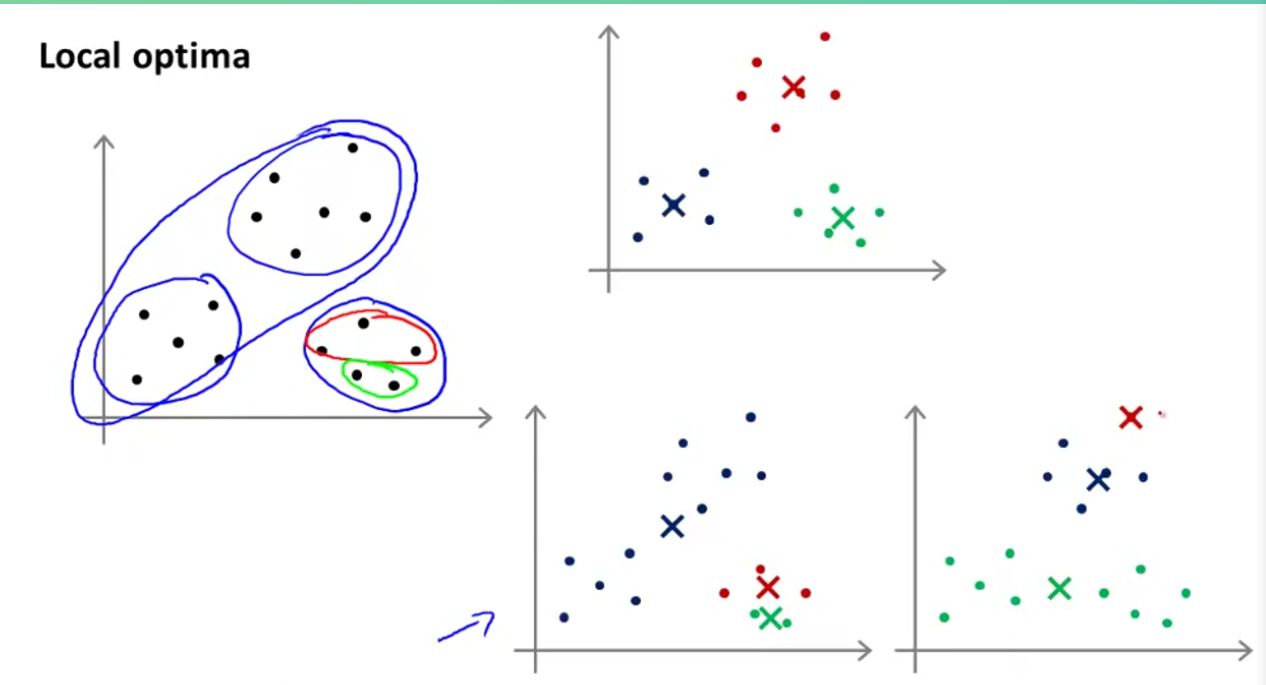
会出现以上结果。所以要进行多次初始化,尽可能得到全局最优解

循环迭代尽可能多的次数,最后选择代价函数值最小的一个
选择中心的数量:
1.通过可视化数据,手工进行选择。
可能会出现模棱两可的情况
2.肘部法则
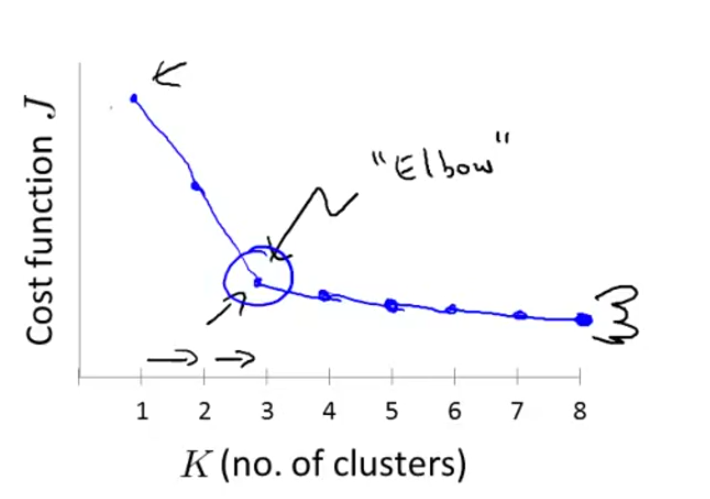
代价函数随聚类中心增加而下降,到某个值时,下降变得缓慢。
但不是那么理想。
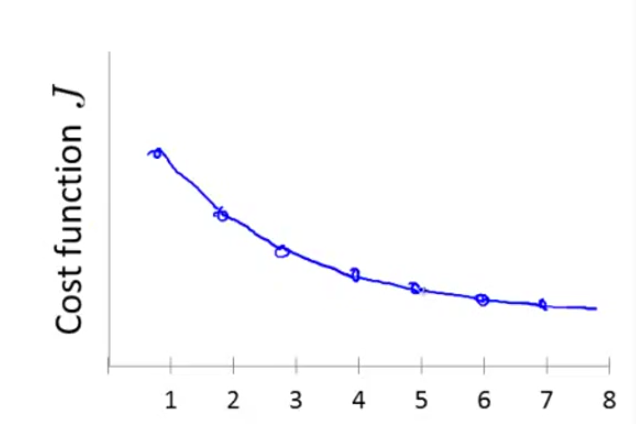
我们会在3和4之间犹豫。
这在某些情况下可能能帮助我们判断。

