


scrapy爬虫框架介绍
一为什么选择scrapy
通过这一篇博客,我致力于对scrapy进行简单的介绍和简单的网页WEB数据抓取能力.Scrapy是一个健壮的web框架,用于从各种数据源抓取数据。
作为一个普通的web用户,您经常会发现自己希望能够通过Excel之类的电子表格程序从正在浏览的网站上获取数据(参见第3章基本爬行),以便在脱机或执行计算时访问这些数据。
作为开发人员,您常常希望能够组合来自各种数据源的数据,但是您很清楚检索或提取这些数据源的复杂性。Scrapy可以帮助您完成简单和复杂的数据提取活动。
1.处理残缺的HTML
您可以直接从Scrapy使用Beautiful Soup或lxml,但是Scrapy提供了选择器——lxml之上的高级XPath(主要)接口。它能够有效地处理损坏的HTML代码和混乱的编码。
2.社区
拥有一个强大的社区,在stack overflow上面 http://stackoverflow.com/questions/tagged/scrapy,基本能够在几分钟内解决你提出的问题.更多的社区信息可以访问 http://scrapy.org/community/.
3.由社区维护的组织良好的代码
scrapy是一个标准化的大妈格式和框架,您可以编写名为spider和pipeline的Python小模块,并且可以自动地从将来对引擎本身的任何改进中获益。所以,不管有谁加入你的团队,都不必经历理解自定义爬行器特性的学习曲线。
二.scrapy需要注意的事项
在某些情况下,不负责任的web抓取可能是恼人的,甚至是非法的。需要避免的两件最重要的事情是拒绝服务攻击(DoS),比如行为和侵犯版权。
一个典型的web爬虫程序可能每秒下载几十个页面。这是普通用户产生流量的十倍多。这可能会让网站所有者感到不安。使用节流将生成的流量减少到可接受的类似用户的级别。监控响应时间,如果您看到响应时间在增加,请减少爬行的强度。
在版权方面,很明显,看看你浏览的每一个网站的版权公告,确保你明白什么是允许的,什么是不允许的。为网站管理员提供一种方法来表达他们希望被排除在您的爬虫之外,这是很好的。
三.理解HTML和XPATH
为了解析来自web页面的信息,你必须要理解更多关于它的框架.
1.HTML
让我们花一些时间来理解从用户在浏览器上键入URL:
1.在浏览器上键入URL。URL的第一部分(域名,如gumtree.com)用于在web上找到合适的服务器,URL和其他数据(如cookie)形成一个请求,该请求被发送到该服务器。
2.服务器通过向浏览器发送HTML页面进行响应。注意,服务器还可能返回其他格式,如XML或JSON,但目前我们主要关注HTML。
3.HTML被转换成浏览器中的一个内部树表示:文档对象模型(Document Object Model, DOM)。
4.根据一些布局规则,将内部表示呈现为您在屏幕上看到的可视表示。
2.XPath
使用XPath选择和过滤HTML元素.文档的层次结构以元素开始,您可以使用元素名称和斜杠来选择文档的元素。例如,以下是从http://example.com/页面返回的各种表达式:
$x('/html')
[ <html>...</html> ]
$x('/html/body')
[ <body>...</body> ]
$x('/html/body/div')
[ <div>...</div> ]
$x('/html/body/div/h1')
[ <h1>Example Domain</h1> ]
$x('/html/body/div/p')
[ <p>...</p>, <p>...</p> ]
$x('/html/body/div/p[1]')
[ <p>...</p> ]
$x('/html/body/div/p[2]')
[ <p>...</p> ]
您还可以选择属性。http://example.com/上唯一的属性是链接的href,您可以使用字符@访问该链接,如下所示:
$x('//a/@href') [ href="http://www.iana.org/domains/example" ]
你也能够永选择器text():
$x('//a/text()') [ "More information..." ]
实际上,您经常需要在XPath表达式中使用类。在这些情况下,您应该记住,由于一些称为CSS的样式元素,您经常会看到HTML元素在它们的class属性上声明多个类。
这意味着,例如,在导航系统中,您将看到一些div的类属性设置为“link”,而另一些div的类属性设置为“link active”。后者是当前处于活动状态的链接,因此可用特殊颜色(通过CSS)显示或突出显示。
在进行抓取时,您通常会对包含特定类的元素感兴趣,即前面示例中的“link”和“link active”。contains() XPath函数允许您选择包含某个类的所有元素。
//table[@class="infobox"]//img[1]/@src //div[starts-with(@class,"reflist")]//a/@href //*[text()="References"]/../following-sibling::div//a
如果它们的HTML以使XPath表达式无效的方式更改,我们将不得不返回爬行器并纠正它们。这通常不会花费很长时间,因为更改通常很小。然而,这肯定是我们宁愿避免的事情。一些简单的规则可以帮助我们降低您的表达式无效的几率:
//*[@id="myid"]/div/div/div[1]/div[2]/div/div[1]/div[1]/a/img //div[@class="thumbnail"]/a/img //*[@id="more_info"]//text() //[@id="order-F4982322"]
尽管id是惟一的,但是上面的XPath表达式非常糟糕。还要记住,即使id是惟一的,您也会发现许多HTML文档并不是惟一的。
四.基础爬虫
1.安装scrapy
scrapy是通过python语言作为基础的,所以在scrapy安装以前,是要先安装python的,这里我就不多说python的安装了,网上有很多教程。
这里我是通过Anaconda进行python包的版本控制,这样非常的方便管理python的各种包依赖版本问题。
当安装了Anaconda后,就可以安装scrapy,scrapy也是python的一个包,所以命令如下:pip install scrapy安装。
2.创建scrapy项目
scrapy startproject 项目名(demo)

3.简单爬取网页(http://jandan.net)为例
1.创建jiandanSpider,作为项目主要入口
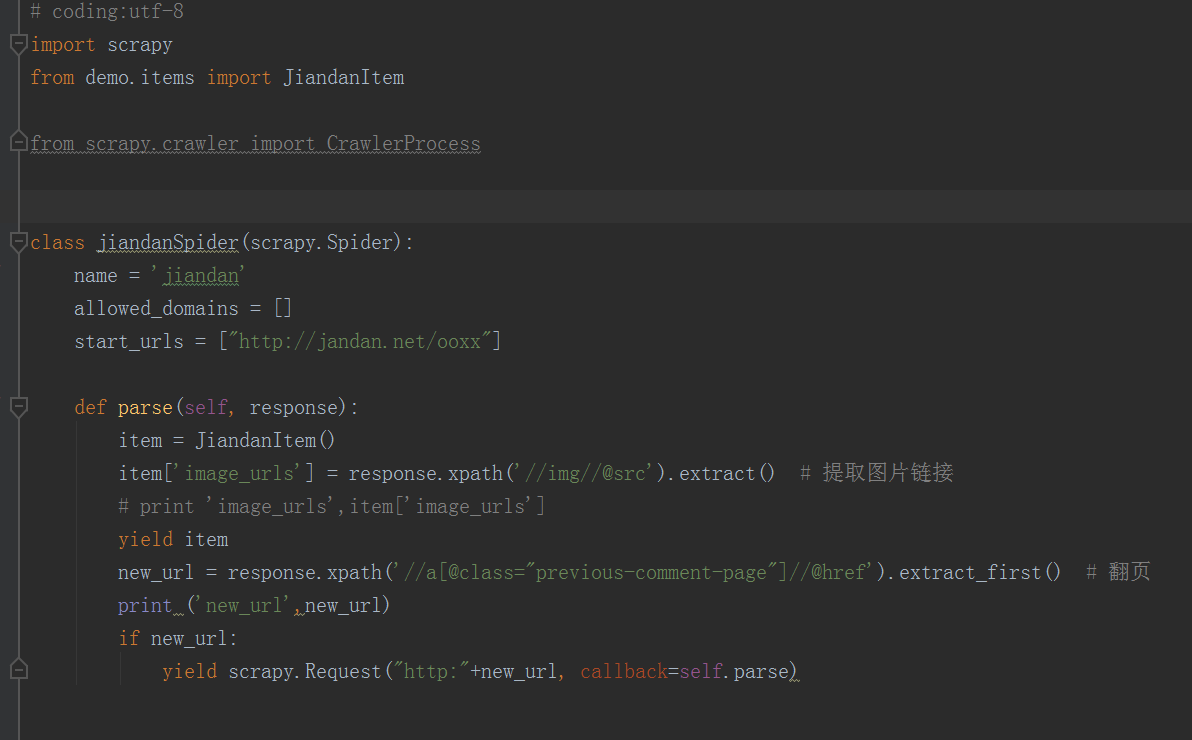
2.item

3.pipeline

4.setting
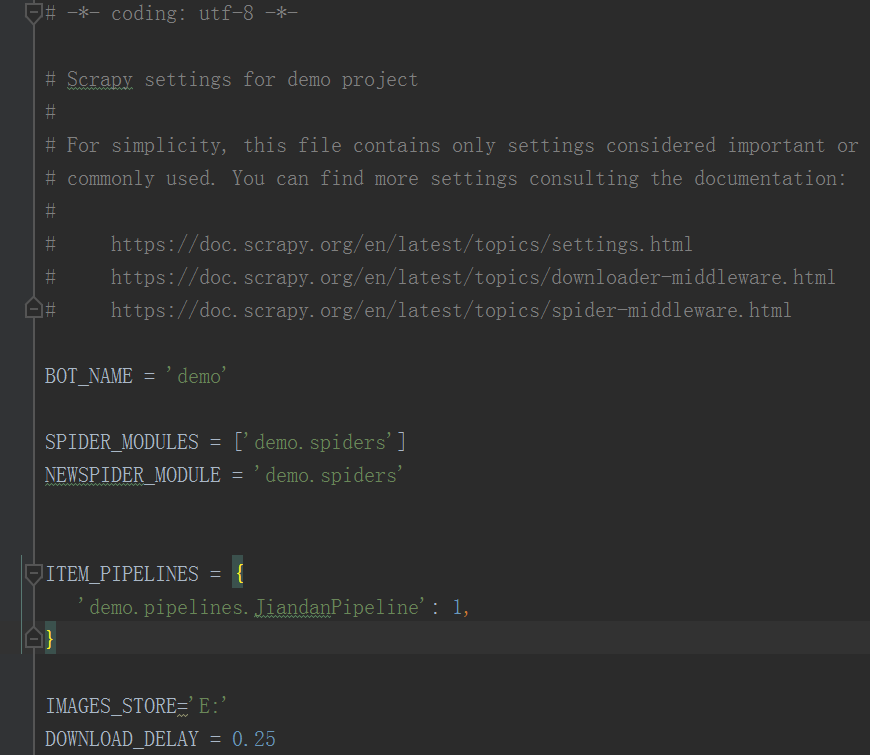
5.测试
进入项目目录cmd
使用命令:scrapy crawl jiandan,可以再E盘看到我们抓取下来的图片:

