

1、避免拆箱装箱:
我们知道C#中的值类型和引用类型,C#基础数据类型和Struct、Enum属于值类型,引用类型包括类、数组、接口、委托以及字符串(String),不错,字符串也属于引用类型;值类型会以栈(Stack)的形式存储在内存,引用类型会以堆(Heap)的形式存储。值类型转换为引用类型称为装箱,反之称为拆箱。如下:
![]()

装箱拆箱会影响程序性能,我们在程序中应该尽可能避免。因此程序这样写会提升那么一点点的性能:
注意:
1、首先,会为值类型在托管堆中分配内存。除了值类型本身分配的内存外,内存总量还要加上类型对象指针和同步块索引所占用的内存。
2、将值类型的值赋值到新分配的堆内存中。
3、返回已经成为引用类型的对象的地址。
装箱:
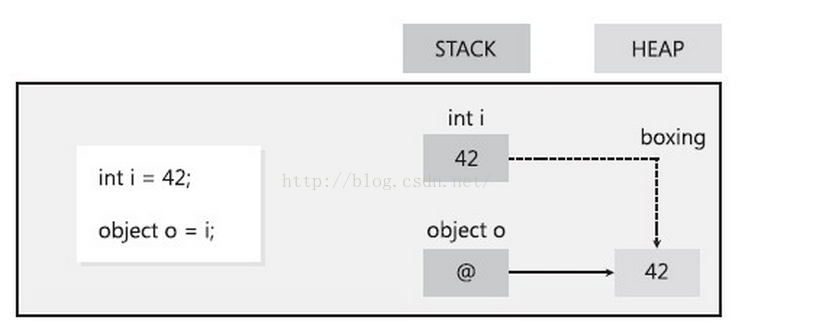
对值类型在堆中分配一个对象实例,并将该值复制到新的对象中。按三步进行。 1:首先从托管堆中为新生成的引用对象分配内存(大小为值类型实例大小加上一个方法表指针和一个SyncBlockIndex)。 2:然后将值类型的数据拷贝到刚刚分配的内存中。 3:返回托管堆中新分配对象的地址。这个地址就是一个指向对象的引用了。 可以看出,进行一次装箱要进行分配内存和拷贝数据这两项比较影响性能的操作。
拆箱:

1、首先获取托管堆中属于值类型那部分字段的地址,这一步是严格意义上的拆箱。 2、将引用对象中的值拷贝到位于线程堆栈上的值类型实例中。 经过这2步,可以认为是同boxing是互反操作。严格意义上的拆箱,并不影响性能,但伴随这之后的拷贝数据的操作就会同boxing操作中一样影响性能。
2、使用StringBuilder
如果字符串拼接过多,可能会影响程序性能,这样因为每次++都会创新一个新的字符串,也就是说会在内存中多开辟了一个空间给这个新的字符串。使用StringBuilder可以减少这种消耗。建议在连接字符串过多的情况下使用。
如果StringBuilder 没有先定义长度,则默认分配的长度为16. 当StringBuilder字符长度小于等于16时,StringBuilder 不会重新分配内存;当StringBuilder 字符长度大于16小于32时,StringBuilder 又会重新分配内存,使之16的倍数。
注意:StringBuilder 指定的长度要合适,太小了,需要频繁分配内存,太大了,浪费空间。
3、区别对待 == 和 Equals
== 和 Equals 的区别
1. == 是一个运算符。
2.Equals则是string对象的方法,可以.(点)出来。
我们比较无非就是这两种 1、基本数据类型比较 2、引用对象比较
1、基本数据类型比较
==和Equals都比较两个值是否相等。相等为true 否则为false;
2、引用对象比较
==和Equals都是比较栈内存中的地址是否相等 。相等为true 否则为false;
需注意几点:
1、string是一个特殊的引用类型。对于两个字符串的比较,不管是 == 和 Equals 这两者比较的都是字符串是否相同;
2、当你创建两个string对象时,内存中的地址是不相同的,你可以赋相同的值。所以字符串的内容相同。引用地址不一定相同,(相同内容的对象地址不一定相同),但反过来却是肯定的;
3、基本数据类型比较(string 除外) == 和 Equals 两者都是比较值;
4、在Linq 查询中避免不必要的迭代
迭代含义: 每一次对过程的重复称为一次“迭代”
/// <summary> /// 返回年龄等于20的第一个元素 /// </summary> public static void GetPerson() { MyList list = new MyList(); var temp = (from c in list where c.Age == 20 select c).ToList(); Console.WriteLine(list.IteratedNum.ToString()); list.IteratedNum = 0; var temp2 = (from c in list where c.Age >= 20 select c).First(); Console.WriteLine(list.IteratedNum.ToString()); } class MyList : IEnumerable<Person> { //为了演示需要,模拟了一个元素集合 List<Person> list = new List<Person>() { new Person(){ Name = "Mike", Age = 20 }, new Person(){ Name = "Mike", Age = 30 }, new Person(){ Name = "Rose", Age = 25 }, new Person(){ Name = "Steve", Age = 30 }, new Person(){ Name = "Jessica", Age = 20 } }; /// <summary> /// 迭代次数属性 /// </summary> public int IteratedNum { get; set; } public Person this[int i] { get { return list[i]; } set { this.list[i] = value; } } #region IEnumerable<Person> 成员 public IEnumerator<Person> GetEnumerator() { foreach (var item in list) { //每遍历一个元素就加1 IteratedNum++; yield return item; } } #endregion #region IEnumerable 成员 IEnumerator IEnumerable.GetEnumerator() { return GetEnumerator(); } #endregion } class Person { public string Name { get; set; } public int Age { get; set; } }

无论是SQL查询还是LINQ查询,搜索到结果立刻返回总比搜索完所有的结果再将结果返回的效率要高。
/// <summary> /// 获取耗时 /// </summary> /// <returns></returns> private static void GetLinqMilliseconds() { List<Customer> strList = new List<Customer>(); for (int i = 0; i < 100000; i++) { strList.Add(new Customer { CustomerName = "张三" + i, City = "suzhou" }); } Stopwatch watch = new Stopwatch(); watch.Start(); var straList = strList.Where(p => p.City == "suzhou").ToList(); watch.Stop(); var useTime = watch.Elapsed; Console.WriteLine($"Where 耗时:{useTime}"); watch.Restart(); var selList = strList.Select(p => p.City == "suzhou").ToList(); watch.Stop(); Console.WriteLine($"Select耗时:{watch.Elapsed}"); Console.ReadKey(); } /// <summary> /// 顾客实体 /// </summary> public class Customer { public Customer(string customerName, string city) { CustomerName = customerName; City = city; } public Customer() { } /// <summary> /// 顾客姓名 /// </summary> public string CustomerName { get; set; } /// <summary> /// 顾客所在城市 /// </summary> public string City { get; set; } }

Where 根据返回bool值的Func委托参数过滤元素。
Select 将序列的每个元素经过lambda表达式处理后投影到一个新类型元素上
6、并行 并不总是速度更快
private static void GetMilliseconds() { Stopwatch watch = new Stopwatch(); watch.Start(); DoinFor(); watch.Stop(); Console.WriteLine($"同步耗时{ watch.ElapsedMilliseconds}"); watch.Restart(); DoInParalleFor(); watch.Stop(); Console.WriteLine($"并行耗时{watch.ElapsedMilliseconds}"); Console.ReadKey(); } static void DoSomething() { for (int i = 0; i < 10; i++) { i++; } } static void DoinFor() { for (int i = 0; i < 2000; i++) { DoSomething(); } } static void DoInParalleFor() { Parallel.For(0, 2000, (i) => { DoSomething(); }); }

在数据量较大的情况 并行的速度 还是比串行的快的过

 浙公网安备 33010602011771号
浙公网安备 33010602011771号