
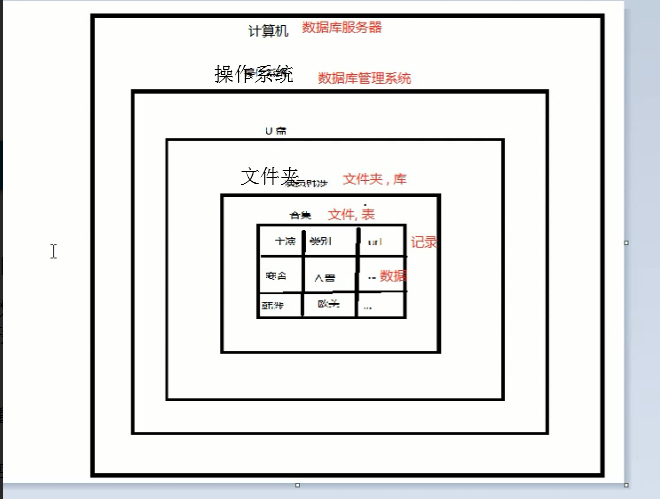
一.概述
数据库(Database,简称DB),类似于文件夹;
数据库表(table),类似于文件,用来存储数据的;每张表是由行和列组成;字段名也是就列名;
数据(data),存储在表中的信息就叫做数据;
数据库系统有3个主要的组成部分
1.数据库(Database System):用于存储数据的地方。
2.数据库管理系统(Database Management System,DBMS):用户管理数据库的软件。
3.数据库应用程序(Database Application):为了提高数据库系统的处理能力所使用的管理数据库的软件补充。
二.数据库的特点
三.数据库分类
最常用的数据库模型主要是两种,即 关系型数据库 和 非关系型数据库;
关系型数据库:是把复杂的数据结构归结为简单的二元关系,即二维表格形式;
主流的关系型数据库为MySQL,Oracle,DB2;
非关系型数据库:也被称为 NoSQL数据库, NoSQL 的含义为Not Only SQL , 是对传统关系型数据库的一个有效的补充;
传统的关系型数据库IO瓶颈、性能瓶颈都难以有效突破,于是出现了大批针对特定场景,以高性能和使用便利为目的功能特异化的数据库产品。
NOSQL 为了高性能,高并发而生,典型产品为redis等;
为什么选择MySQL数据库?
(1) MySQL性能卓越、服务稳定,很少出现异常宕机
(2) MySQL开放源代码且无版权制约,自主性及使用成本低
(3) MySQL历史悠久,社区及用户活跃,遇到问题可以解决
(4) MySQL软件体积小,安装使用简单,并且易于维护,安装及维护成本低
(5) MySQL品牌口碑效应,使得企业无需考虑就直接用
(6) MySQL支持多用操作系统,提供多种API接口,支持多用开发语言,特别对流行的语言有很好的支持
SQL语言:是关系型数据库的标准语言, 其主要用于存取数据,查询数据,更新数据和管理数据库系统 等操作。
create database 数据库的名字 CHARSET utf8; # 当前库的编码集为utf8
2.查看数据库:
#查询当前用户下所有数据库
show databases;
#查看创建数据库的信息
show create database db_name;
#查询当前操作所在的数据库名称
select database();
3.删除数据库
DROP DATABASE db5;
4.进入数据库
use databasename
5.查看数据库里面的表
show tables;
四.用户权限
1.用户管理
创建用户
create user '用户名'@'IP地址' identified by '密码';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';
2.授权管理
show grants for '用户'@'IP地址' -- 查看权限
grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权
revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限

MySQL之表的操作:

create database db5 CHARSET utf8;
DROP DATABASE db5;
-- CREATE table info(id int not null auto_increment PRIMARY key,
-- name VARCHAR(50) not null,
-- sex CHAR(2) null) 创建表
-- 查看表
-- select * from info
-- 修改表
-- ALTER table info add age int not null; # 添加一个字段,字段后面必须要添加 字段的属性;
-- ALTER table info CHANGE name names VARCHAR(50) not null;修改表里面的字段;
-- rename table info to user_info 修改表名;
-- INSERT user_info VALUES(30,'曾辉','男',23) #插入所有的字段。
-- INSERT user_info(id,NAMES) VALUES(2,'ZZZ'); 插入固定的字段。
-- insert into user_info(id,NAMES) values(3,'aa'), (4,'aaaa'),(5,'aaaaa');在表中添加多个数据;
-- 操作数据
-- update user_info set sex ='人妖',names = '小强' where id =12;修改
-- select names,sex as '性别' from user_info; as 是别名;便于理解;
-- delete from user_info where id in('1','3','5')
-- truncate user_info; #清空表中的数据,并且也把自增主键也同时删去了;
MySQL之数据的操作:



-- select name,salary+500 as salary from person ; #查询的时候数字可以进行四则运算;
-- select distinct age,name from person; 按照后面的多个数据相加后去重,而不是单看一个了。
-- select name,sex from person where age >=20 and age <=30;
-- select name,sex from person where age between 20 and 30; 区间
-- select name,sex from person where age <> 20; 不等于,相当于 !=
-- select * from person where dept_id is null; #这是数据为空值 (null)的用is ;
-- select * from person where name = ''; #这是数据为空,即为空字符( )的用 = ;
-- select name from person where not age>20; #非
-- select * from person where id in (1,3,5);#in 为集合,
-- select * from person where name like '%e'; #最后结尾是e的 ;模糊查询
-- select * from person where name like 'e%';#开头是e的
-- select * from person where name like '%e%';#只要是包含e的
-- select * from person where name like '___';#_表示一个站位符; 名字是3位的;
-- select * from person where name like '__' ORDER BY salary DESC;# ORDER BY 排序,默认asc正序;desc倒序;
# 条件加在排序的前面;
-- select * from person ORDER BY CONVERT(name USING gbk); #按照名字的ascil码
-- select max(age),min(age),avg(age) from person; #聚合函数
-- select avg(salary),dept_id,GROUP_CONCAT(name) from person GROUP BY dept_id;#查看每个部门平均工资,并且查看人员;
#GROUP_CONCAT(值)将聚合分开,取每个值组合成字段,然后用逗号分隔。
-- select avg(salary)as salary,dept_id,GROUP_CONCAT(name) from person GROUP BY dept_id HAVING salary >100000;#HAVING就跟where一样是条件。
-- select * from person LIMIT 0,4; #LIMIT 为分页,第一个参数为 起始的数,第二个参数为页数。
truncate 和delete 都是删除表中的数据,但是两者有区别:
1.truncate 在各种表上无论是大的还是小的 删除都是非常快的,但是 delete 会被表中的数据量的大小影响其执行的效率;
2.truncate 不能触发 触发器,而 delete 会触发 触发器;
3.truncate 清空表中的数据,并且也把自增主键也同时删去了;而 delete 不会把自增和主键同时删去;
SQL语句关键字的执行顺序:
select name, max(salary) #5
from person #1
where name is not null #2
group by name #3
having max(salary) > 5000 #4
order by max(salary) #6
limit 0,5 #7
以上是单表的查询方式;下面是多表的查询方式:
-- select * from person p,dept d where p.dept_id = d.did;#多表查询 -- SELECT * from person p LEFT JOIN dept d on p.dept_id = d.did;#左连接,即左边中的数据全部显示出来; -- SELECT * from person p RIGHT JOIN dept d on p.dept_id = d.did;#右连接,即右边中的数据全部显示出来; -- SELECT * from person p INNER JOIN dept d on p.dept_id = d.did;
#内连接和多表查询是一样的,只显示出两个表共同的条件数据; -- SELECT * FROM person LEFT JOIN dept ON person.dept_id = dept.did -- UNION ALL#全连接,只是 不去重, -- UNION #全连接,并且 去重, -- SELECT * FROM person RIGHT JOIN dept ON person.dept_id = dept.did; -- 查询出 教学部 年龄大于20岁,并且工资小于40000的员工,按工资倒序排列 #内连接把两个表结合在一起; -- select * from person p INNER JOIN dept d on p.dept_id = d.did -- and d.dname ='教学部' -- and age >20 -- and salary < 40000 -- ORDER BY salary DESC; -- select did from dept where dname = '教学部'; -- select * from person where person.dept_id = (select did from dept where dname = '教学部')
and age>20 -- and salary >40000 ORDER BY salary DESC; #()是代表优先级,优先执行; #查询每个部门中最高工资和最低工资是多少,显示部门名称 -- -- select * from person p INNER JOIN dept d on p.dept_id = d.did ; -- select max(salary),min(salary),dname from(select * from person p INNER JOIN dept d
on p.dept_id = d.did)as n -- GROUP BY dname; #person p INNER JOIN dept d on p.dept_id = d.did 结合的表。 -- select max(salary),min(salary),dname from person p INNER JOIN dept d on p.dept_id = d.did -- GROUP BY dname; #多表连接相当于一个组合的表; #1.查询平均年龄在20岁以上的部门名. select avg(age),dname from (select * from person p INNER JOIN dept d where p.dept_id = d.did)
as a GROUP BY dname HAVING avg(age)>20 ; #2.查询教学部 下的员工信息. -- select * from person p INNER JOIN dept d ON p.dept_id = d.did AND dname = '教学部'; -- select * from (select * from person p INNER JOIN dept d ON p.dept_id = d.did AND dname = '教学部')as n; #3.查询大于所有人平均工资的人员的姓名与年龄 -- SELECT avg(salary) from person; -- select name,age from person where salary > (SELECT avg(salary) from person) #子语句 # 子语句就相当于一个 元组; #1.查询平均年龄在20岁以上的部门名. -- select dname from dept where did in
(select dept_id from person GROUP BY dept_id HAVING avg(age) >20); #2.查询教学部 下的员工信息. -- select * from person where dept_id in (select did from dept where dname='教学部') #3.查询大于所有人平均工资的人员的姓名与年龄 -- select name,age from person where salary >(select avg(salary) from person) #查询高于本部门平均工资的本部门的人员; -- select avg(salary) from person GROUP BY dept_id; -- select * from person p1,(select dept_id,avg(salary)as 'avg_salary' from person GROUP BY dept_id)as p2 -- where p1.dept_id = p2.dept_id AND p1.salary > p2.avg_salary; #根据工资高低,将人员划分为两个级别,分别为 高端人群和低端人群。显示效果:姓名,年龄,性别,工资,级别 IF; -- SELECT p1.*, -- IF(p1.salary >10000,'高端人群','低端人群') as '级别' #自己创建一个字段; -- from person p1; #需求2: 根据工资高低,统计每个部门人员收入情况,划分为 富人,小资,平民,吊丝 四个级别, 要求统计四个级别分别有多少人 -- select * from person p LEFT JOIN dept d on p.dept_id = d.did -- select dname,SUM((CASE WHEN salary >50000 THEN 1 ELSE 0 END)) as '富人', -- SUM((CASE WHEN salary BETWEEN 29000 and 50000 THEN 1 ELSE 0 END)) as '小资', -- SUM((CASE WHEN salary BETWEEN 10000 and 29000 THEN 1 ELSE 0 END)) as '平民', -- SUM((CASE WHEN salary <10000 THEN 1 ELSE 0 END)) as '屌丝' -- from (select * from person p LEFT JOIN dept d on p.dept_id = d.did )as n GROUP BY dept_id #count(*)相当于没有分组前的行数 #查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列 -- SELECT course.c_name,avg(num)
FROM score,course where score.c_id = course.c_id GROUP BY score.c_id
ORDER BY avg(num) ASC , score.c_id DESC #按条件排序,可以按照多个条件,如果第一个条件不满足,则按照第二个条件;即 平均成绩相同时,按课程号降序排列.
在多表查询中的SQL语句的执行的顺序:
#mysql 语句关键字的执行顺序:
-- SELECT DISTINCT <select_list> #7
-- FROM <left_table> #1
-- <join_type> JOIN <right_table> #3
-- ON <join_condition> #2
-- WHERE <where_condition> #4
-- GROUP BY <group_by_list> #5
-- HAVING <having_condition> #6
-- ORDER BY <order_by_condition> #8
-- LIMIT <limit_number> #9
约束:
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性
1.外键约束:
CREATE TABLE IF NOT EXISTS person(
id int not null auto_increment PRIMARY KEY,
name VARCHAR(50) not null,
age TINYINT(4) null DEFAULT 0,
sex enum('男','女','人妖') NOT NULL DEFAULT '人妖',
salary decimal(10,2) NULL DEFAULT '250.00',
hire_date date NOT NULL,
dept_id int(11) DEFAULT NULL,
CONSTRAINT fk_did FOREIGN KEY(dept_id) REFERENCES dept(did) -- 添加外键约束
#外键的名字 约束创建表中的字段 与另外一个表中的字段 ;
#两者进行约束
)ENGINE = INNODB DEFAULT charset utf8;
#在已经创建表后,在追加外键约束;
ALTER TABLE pesron add constraint fk_did foreign key (dept_id) references dept(did)
#删除外键约束
ALTER TABLE person DROP foreign key fk_did;
定义外键的条件:
(1)外键对应的字段数据类型保持一致,且被关联的字段(即references指定的另外一个表的字段),必须保证唯一
(2)所有tables的存储引擎必须是InnoDB类型.
(3)外键的约束4种类型: 1.RESTRICT 2. NO ACTION 3.CASCADE 4.SET NULL
(4)建议:1.如果需要外键约束,最好创建表同时创建外键约束.
2.如果需要设置级联关系,删除时最好设置为 SET NULL.
references(参考) 后面是 主表的数据;
注意:插入数据时,先插入主表中的数据,再插入从表中的数据;
删除数据时,先删除从表的数据,再删除主表中的数据;
2.非空的约束
关键字:NOT NULL ,表示 不可空,用来约束表中的字段列;
3.主键约束
primary key
主键这一行的数据不能重复,并且不能为空;
复合主键,主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
create table t3(
id int(10) not null,
name varchar(100) ,
primary key(id,name)
);
4.唯一约束
关键字: UNIQUE, 比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
create table t4(
id int(10) not null,
name varchar(255) ,
unique id_name(id,name)
);
//添加唯一约束
alter table t4 add unique id_name(id,name); #id和name 一起不能有重复;
//删除唯一约束
alter table t4 drop index id_name;
5.默认值约束
关键字为:default
create table t5(
id int(10) not null primary key,
name varchar(255) default '张三'
);
#插入数据
INSERT into t5(id) VALUES(1),(2);
注意: INSERT语句执行时.,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充。
表与表之间的关系:
表的关系总体可以分为三类: 一对一;一对多;多对多;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号