按惯例首先贴出原博地址http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
网络组织
R-CNN使用神经网络来解决两个主要问题:
- 识别输入图像中可能包含前景对象的前景区域(感兴趣区域- ROI)
- 计算每个ROI的对象类概率分布,即,计算ROI包含某个类的对象的概率。然后用户可以选择概率最高的对象类作为分类结果。
R-CNNs包括三种主要类型的网络:
- Head
- 区域建议网络RPN
- 分类网络
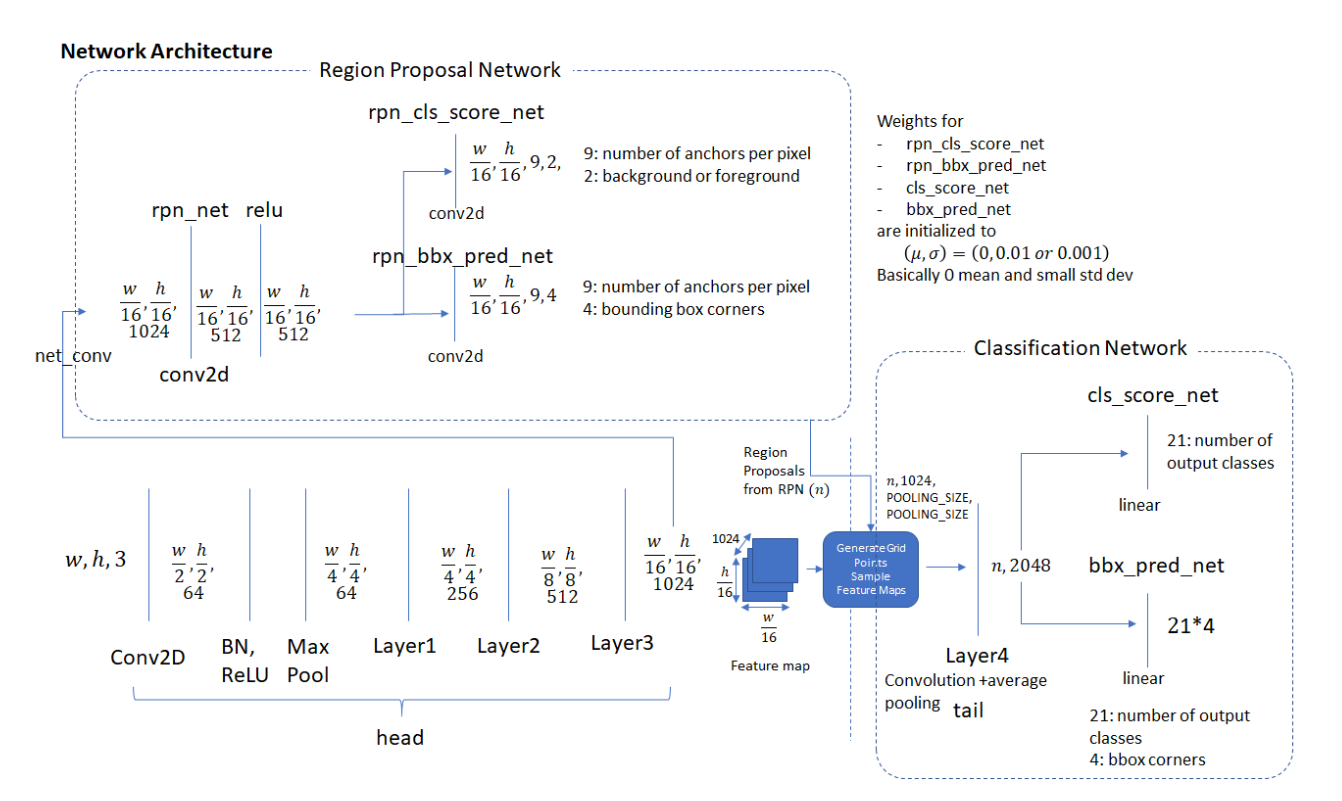
R-CNNs使用预训练网络(如ResNet 50)的前几层来从输入图像中识别有前途的特征。因为神经网络表现出“转移学习”(Yosinski et al. 2014),所以在不同的问题上使用一个训练在一个数据集上的网络是可能的。网络的前几层学习检测一般特征,如边缘和色块,它们是跨许多不同问题的良好鉴别特征。后一层获得的特征是更高级的、更具体的问题特征。在反向传播期间,可以删除这些层,或者对这些层的权值进行微调。由预先训练好的网络初始化的前几层构成“头”网络。head网络生成的convolutional feature map然后通过Region Proposal network (RPN), RPN使用一系列convolutional和fully connected layers来生成有前途的ROIs,这些ROIs很可能包含一个前景对象(上文第1题)。然后利用这些有前途的roi,从head网络生成的feature map中裁剪出相应的区域。这就是所谓的“作物汇集”。然后通过一个分类网络对作物池产生的区域进行分类,该分类网络学会对每个ROI中包含的对象进行分类。
网络结构
下图显示了上述三种网络类型的各个组件。我们展示了每个网络层的输入和输出的维度,这有助于理解数据是如何被网络的每一层转换的。w和h表示输入图像的宽度和高度(预处理后)。