

1.现实中的问题
我们知道数据库的数据,基本80%的业务是查询,20%的业务涵盖了增删改,经过长期的业务变更和积累数据库的数据到达了一定的数量之后,直接影响的是用户与系统的交互,查询时的速度,插入数据时的流畅度,系统的可用性,这些指标对用户体验都是会有影响的,不说用户,你自己用是什么感觉?我经历过且常见的无非以下几个解决方案,从用户,代码,数据库,不知道有没有人跟我有相似的经历
1.最简单粗暴的就是从用户下手,也就是通过业务的手段来约束,限定查询时间,限定查询条件,大批量需要申请后台工程师导出,不是说对这些方法嗤之以鼻,在某些场景下这样也是不错的方法.
2.检查代码,查询语句什么的能优化的做下优化,这一点确实也是比较关键的,再好的架构和服务器,也顶不住递归死循环查询这些.
3.结合一些数据库监控工具或者对常用查询的表,做一些数据库基本的属性设定,例如数据库加索引,分分区.
虽然确实可以使用这些技术手段来提升本身的查询速度,但是达到一定量级,这些手段得到的改善也不是很大,因为数据的量是实实在在的存在,假设此时加上并发量的增大,数据库引擎在查询或者计算时,使用的是服务器的CPU和内存,当资源消耗过高时,直接降低系统可用性,往往这个时候就需要通过整体业务上的变通或者技术架构的转换上来着手解决问题了。
然而现实中业务上的改变,可能在落实上会存在很大的问题,但是可以从技术架构上来尝试解决,主要在代码整体架构或者数据库存储架构解决了,我们主要介绍数据架构层面的方案。
1.分库
-
在水平分库中,就是将数据库中的表,存到不同的数据库,但是不同库的表数量和结构是一样的,只是每个库的数据都不一样,没有交集,库的并集是全量数据
-
在垂直分库中,以表为依据,按照业务归属不同,将不同的表拆分到不同的库中,不同的库存储的可能是不同的表,库的并集是全量数据
2.分表
-
水平分表就是将一张表分为多张表,表的结构都一样,每个表的数据都不一样,没有交集,所有表的并集是全量数据;
-
垂直分表将一张表字段拆分为不同的表,合并起来就是整个全量数据,但是这种可以归属于设计之初的设计缺陷
虽然使用分库分表可以一定程度解决上面所说的问题,但是分了之后也有可能再变大,总不能一直无脑拆分下去把,此时应该使用读写分离,也就是说读写分离应该是在分库分表的基础之上来实施的。
2.什么是ShardingSphere-Proxy?
在ShardingSphere中一共有3个核心组件 ShardingSphere-JDBC 定位是一个Java的框架 、ShardingSphere-Proxy、ShardingSphere-Sidecar 还在开发中,我们主要介绍ShardingSphere-Proxy和ShardingSphere-Proxy的实际应用。
ShardingSphere-Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持,主要目的对数据库实现分库分表和读写分离,应用场景不管是传统的单体项目,或者现有流行的微服务项目中都可以使用,但是目前只支持 MySQL 和 PostgreSQL , 它在整个系统架构中定位是一个数据库中间件。
在这里我们选择使用ShardingSphere-Proxy中间件,来作为我们实现分库分表的工具,写这个的目的主要是记录ShardingSphere-Proxy的使用和一些基本的概念,至于说具体分成什么样,如果您只想知道到底是分表,还是分库,又或者是分库分表,我可能帮不了什么,但是您可以按照现在所困扰的问题展开分析,然后使用ShardingSphere-Proxy落地。
3.分库分表方案
实现分库分表的方案根据不同的需求可能会延伸出很多,但是我们在逻辑上抽象出2种,一种是进程内和业务系统集成,一种是拆分出分库分表作为独立进程,
1.进程内方案
进程内的方案通常是将分库分表实现业务放到系统内部,通常存在以下缺陷
-
1.系统和分库分表会存在资源竞争
-
2.一个异常的话,另外一个也会异常,依赖性太强。
-
3.无法适应异构,对其他语言的支持
2.进程外方案
进程外方案将分库分表逻辑拆分,使用单独的工具实现客户端将请求发送到系统, 系统通过数据库中间件在内部进行分库分表逻辑,然后存储数据库,通常存在以下缺陷
-
1.维护量上升
-
2.相对进程内,性能会差一点,但是如果内网部署基本可以接受
4.ShardingSphere-Proxy基本概念
使用ShardingSphere-Proxy在进行实现分库分表或者查询时,主要有6个阶段,这整个阶段中的核心步骤是由中间件来实现的。
-
1.选择具体数据库
-
2.sql解析将中间件连接成为真实数据库连接
-
3.sql路由,选择一个真实数据库执行
-
4.sql重写优化
-
5.sql执行真实数据库获取结果
-
6.结果合并从多个表或者库中获取结果
用户主要是针对路由规则的配置,实现将数据分片到不同表以及不同的库,那我们应该思考如何对数据进行分片呢,需要哪些条件?
-
1.分片键:数据表中的字段,选择以哪个字段作为分片的条件。
-
2.分片算法:它的作用就是根据分片数据字段如何去实现数据的分片。
5.项目环境及搭建
ShardingSphere-Proxy是由java开发,所以首先我们需要准备java的基本环境。
1.环境准备
- 1.下载Mysql
- 2.下载jdk1.8 提取码:wgl2
- 3.下载mysql-connector-java-5.1.47.jar
- 4.下载ShardingSphere-Proxy
- 4.1 使用tar命令解压 tar zxvf apache-shardingsphere-5.0.0-shardingsphere-proxy-bin.tar.gz
- 4.2 将下载的mysql-connector-java-5.1.47.jar 拷贝到lib目录下
6.分库分表配置
1.ShardingSphere-Proxy 分表
1.以数据采集数据库的电源信息数据表为例,如果没有数据库就创建数据库
2.在ShardingSphere-Proxy中的conf下找到config-sharding.yaml配置文件进行配置
3.在config-sharding.yaml中配置数据库连接
dataSources:
dataacquisitionsources_0:
url: jdbc:mysql://localhost:3306/dataacquisition?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
4.配置表和数据的分片规则,我们这里选择取模分表
-
- actualDataNodes节点用来配置分成几张表{0..1}就是2张,如果配置10张那就
-
- 如果多张表分表就使用多个逻辑表名和节点,注意一定要注意配置格式
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: id #分表字段
shardingAlgorithmName: powerinformation_MOD
shardingAlgorithms: #取模分表算法
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
5.配置客户端连接虚拟数据库,一般和真实库名对应
schemaName: dataacquisition
6.打开配置目录的server.yaml配置文件,来设置虚拟服务器用户和密码
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
7.启动bin目录下的start.bat,如果出现以下画面,那么恭喜你中间件被成功配置

8.使用客户端连接虚拟服务器3307端口

9.执行脚本在虚拟服务器上创建表结构,那么中间件会默认按照预定的规则分表
create table powerinformation
(
id int not null AUTO_INCREMENT PRIMARY key,
connectionId int(11),
Station Text,
voltage DECIMAL,
resistance DECIMAL,
electricity DECIMAL,
createDate DATETIME
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=2
;
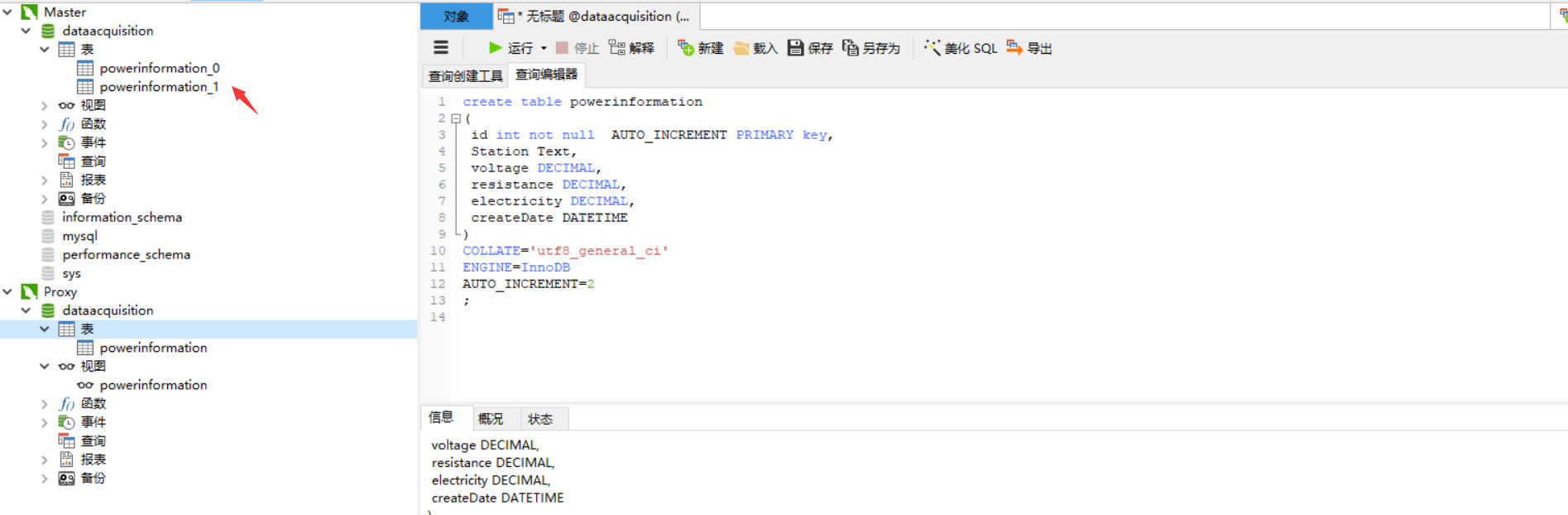
10.打开客户端查看真实库已经分表成功
2.ShardingSphere-Proxy 分库
1.创建2个数据库分别取名为dataacquisition_0和dataacquisition_1

2.打开配置文件,对代理配置不同数据库连接
dataSources:
dataacquisitionsources_0:
url: jdbc:mysql://127.0.0.1:3306/dataacquisition_0?serverTimezone=UTC&useSSL=false #连接库0
username: root
password: sa@123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
dataacquisitionsources_1:
url: jdbc:mysql://127.0.0.1:3306/dataacquisition_1?serverTimezone=UTC&useSSL=false #连接库1
username: root
password: sa@123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
3.配置分库规则,由于现在是2个不同的库,所以不需要配置数据分到表的规则
rules:
- !SHARDING
tables:
powerinformation:
actualDataNodes: dataacquisitionsources_${0..1}.powerinformation #库名表达式
databaseStrategy: #数据分库策略
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD #分库选择取模分库
shardingAlgorithms: #取模算法
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
4.在虚拟库中添加表和数据将会分配到2个不同的库

3.ShardingSphere-Proxy 分库分表
1.按照分库的操作执行,分库配置不变
2.配置文件配置分库分表的规则
rules:
- !SHARDING
tables:
powerinformation:
actualDataNodes: dataacquisitionsources_${0..1}.powerinformation_${0..1}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD
databaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: powerinformation_MOD
shardingAlgorithms:
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
7.分表算法分析实践
1.取模分表(雪花算法)
1.采集表powerinformation使用Id作为自增主键,如果通过ShardingSphere-Proxy代理添加采集数据,数据会添加到powerinformation_0和powerinformation_1中,这个时候真实的业务表中会出现主键重复的现象,我们可以使用GUID或者使用ShardingSphere-Proxy中间件自带的雪花算法来解决主键冲突问题。
2.在config-sharding.yaml配置文件的分片规则中配置雪花算法
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: connectionId #分表字段
shardingAlgorithmName: powerinformation_MOD
keyGenerateStrategy: #配置主键生成的策略
column: Id #主键名称
keyGeneratorName: snowflake #使用雪花算法
shardingAlgorithms:
powerinformation_MOD:
type: MOD
props:
sharding-count: 2
keyGenerators:
snowflake: #算法名
type: SNOWFLAKE
props:
worker-id: 123
3.修改创建表字段id为char类型,如果使用int因为雪花id太长,就会有问题
create table powerinformation
(
id CHAR(100) not null PRIMARY key,
connectionId int(11),
Station Text,
voltage DECIMAL,
resistance DECIMAL,
electricity DECIMAL,
createDate DATETIME
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=2
;
;
2.取模分表(分布式事务)
1.采集表powerinformation,如果通过ShardingSphere-Proxy代理添加采集数据,数据会添加到powerinformation_0和powerinformation_1中,这个时候单笔数据依次添加是没有问题的,但是如果批量添加数据到2个表中,如果powerinformation_0成功了,powerinformation_1失败了,会导致数据不一致。此时我们应该使用分布式事务
2.在server.yaml配置分布式事务
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
providerType: Atomikos
3.字符串分表
1.采集表使用Id作为自增主键,如果在虚拟代理中添加数据,数据会添加到powerinformation_0和powerinformation_1中,我们使用的是powerinformation_Id作为分片键进行数据分片,这个时候如果使用取模分表会出现一些相同采集点的数据添加到不同数据表,查询的时候,我想查看某一个采集点的数据,会涉及到多个表,导致性能下降,应对这种业务场景我们需要使用字符串分表
2.在config-sharding.yaml配置文件的分片规则中配置字符串分表,并且使用hash分表算法
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: Station #分表字段
shardingAlgorithmName: powerinformation_MOD
keyGenerateStrategy: #配置主键生成的策略
column: Id #主键名称
keyGeneratorName: snowflake #使用雪花算法
shardingAlgorithms:
powerinformation_MOD: #配置字符串hash 算法名
type: HASH_MOD #使用hash算法
props:
sharding-count: '2'
keyGenerators:
snowflake: #算法名
type: SNOWFLAKE
props:
worker-id: 123
4.范围分表
1.我们使用的是基于powerinformation_Id作为分片键进行数据分片,这个时候,会出现Id分散到的不同表中,如果进行分页查询就涉及连表,导致查询性能问题,我们可以将分表模式改为范围分表,将连续的数据存在一个表。
2.在config-sharding.yaml配置文件的分片规则中配置范围分表,并且使用范围分表算法
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: powerinformation_Id #分表字段
shardingAlgorithmName: powerinformation_BOUNDARY_RANGE
keyGenerateStrategy: #配置主键生成的策略
column: Id #主键名称
keyGeneratorName: snowflake #使用雪花算法
shardingAlgorithms:
powerinformation_MOD: #配置hash算法名
type: HASH_MOD #使用hash算法
props:
sharding-count: '2'
powerinformation_BOUNDARY_RANGE: #配置范围算法名
type: BOUNDARY_RANGE
props:
sharding-ranges: 100,200,300,400
keyGenerators:
snowflake: #算法名
type: SNOWFLAKE
props:
worker-id: 123
5.固定容量分表
1.使用范围分表会导致最后一张表数据是最多的,随着推移和数据量增大,依然会有查询性能问题,所以我们需要设定当达到指定容量后进行分表
2.在config-sharding.yaml配置文件的分片规则中配置范围分表,并且使用范围分表算法,下面举例为200万条数据以下存在表0,大于200万之后的是表2,最大是400万数据
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: powerinformation_Id #分表字段
shardingAlgorithmName: powerinformation_VOLUME_RANGE #使用固定容量
keyGenerateStrategy: #配置主键生成的策略
column: Id #主键名称
keyGeneratorName: snowflake #使用雪花算法
shardingAlgorithms:
powerinformation_MOD: #配置hash算法名
type: HASH_MOD #使用hash算法
props:
sharding-count: '2'
powerinformation_BOUNDARY_RANGE: #配置范围算法名
type: BOUNDARY_RANGE
props:
sharding-ranges: 2
powerinformation_VOLUME_RANGE: #配置容量算法名
type: VOLUME_RANGE @使用容量
props:
range-lower: '2000000'
range-upper: '4000000'
# 分片的区间的数据的间隔
sharding-volume: '2000000'
keyGenerators:
snowflake: #算法名
type: SNOWFLAKE
props:
worker-id: 123
6.时间分表
1.在现实中如果我想按照一年或者一个月一个表存储采集数据,ShardingSphere-Proxy也提供了相应的算法配置方式。
2.配置文件config-sharding.yaml中
2.在config-sharding.yaml配置文件的分片规则中配置范围分表,并且使用范围分表算法
rules:
- !SHARDING
tables:
powerinformation:# 逻辑表名
actualDataNodes: dataacquisitionsources_0.powerinformation_${0..1} #分表
tableStrategy: #数据分表策略
standard:
shardingColumn: createDate #分表字段
shardingAlgorithmName: powerinformation_AUTO_INTERVAL #使用时间范围定容量
keyGenerateStrategy: #配置主键生成的策略
column: Id #主键名称
keyGeneratorName: snowflake #使用雪花算法
shardingAlgorithms:
powerinformation_MOD: #配置hash算法名
type: HASH_MOD #使用hash算法
props:
sharding-count: '2'
powerinformation_BOUNDARY_RANGE: #配置范围算法名
type: BOUNDARY_RANGE
props:
sharding-ranges: 2
powerinformation_VOLUME_RANGE: #配置容量算法名
type: VOLUME_RANGE @使用容量
props:
range-lower: '5'
range-upper: '10'
# 分片的区间的数据的间隔
sharding-volume: '5'
powerinformation_AUTO_INTERVAL:
type: AUTO_INTERVAL
props:
datetime-lower: '2022-01-01 23:59:59'
datetime-upper: '2023-01-01 23:59:59'
# 以1年度为单位进行划分
sharding-seconds: '31536000'
# 以1个月为单位进行划分
#sharding-seconds: '2678400'
# 以1天为单位进行划分
#sharding-seconds: '86400'
keyGenerators:
snowflake: #算法名
type: SNOWFLAKE
props:
worker-id: 123
8.搭建以及常见问题
1.由于是yaml文件,一定要注意对应节点的格式对齐
2.建议使用大于等于5.0.0+版本 折腾4.0.0版本被恶心吐了
3.如果出现 near 0这种错误就是在配置中使用了特殊符号 建议使用 下划线的"_"
4.ShardingSphere-Proxy 默认使用 3307 端口,可以通过启动脚本追加参数作为启动端口号。如: bin/start.sh 3308
4.分表后插入数据出现错误,说明分表字段错误,但是插入前就需要分片,这个时候没有数据,因为id为主键,应该不用id分片



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话