HWC和CHW数据格式以及C++相互转换
| N | C | H | W |
| batch批量大小 | channels,特征图通道数 | 特征图的高 | 特征图的宽 |
NCHW中,“N”batch批量大小,“C”channels特征图通道数,“H”特征图的高,和“W”特征图的宽。
在深度学习中,为了提升数据传输带宽和计算性能,image 或 feature map在内存中的存放通常会使用NCHW、NHWC 和CHWN 等数据格式。
例如常用的深度学习框架中默认使用NCHW的有caffe、NCNN、pytorch、mxnet等,默认使用NHWC的有tensorflow、openCV等,设置非默认排布格式只需要修改一些参数即可。
虽然我们人可以的将数据按照任意维度进行划分,然而对于计算机而言,数据的存储只能是线性的。NCHW和NHWC格式数据的存储形式如下图所示:
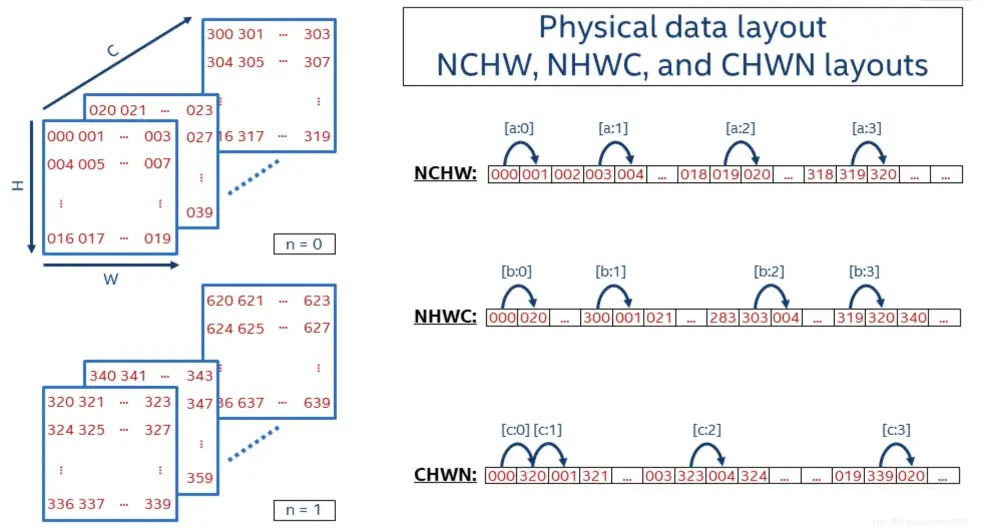
3.1 NCHW
NCHW是先取W方向数据;然后H方向;再C方向;最后N方向。
所以,序列化出1D数据:
000 (W方向) 001 002 003,(H方向) 004 005 ... 019,(C方向) 020 ... 318 319,(N方向) 320 321 ...
3.2 NHWC
NHWC是先取C方向数据;然后W方向;再H方向;最后N方向。
所以,序列化出1D数据:
000 (C方向) 020 ... 300,(W方向) 001 021 ... 303,(H方向) 004 ... 319,(N方向) 320 340 ...
1.CHW
NCHW是先取W方向数据;然后H方向;再C方向;最后N方向。
所以,序列化出1D数据是这个样子的:
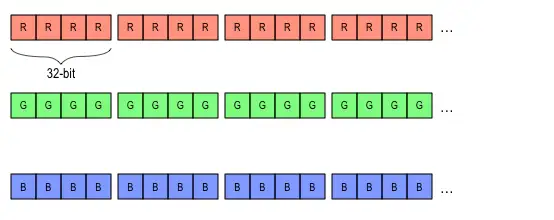
2.HWC
NHWC则是先取C方向数据;然后W方向;再H方向;最后N方向。
所以,序列化出1D数据为:

尽管数据的排列方式不一样,但存储的数据是一样的,因此不同框架下数据的计算结果也是相同的。值得注意的是,数据的不同排布方式会导致数据访问特性不一致,因此即使输入输出相同,但过程的性能会存在区别。
通常,由于神经网络的计算特性,使用HWC格式不需要参数太多的数据移动,且每次内存读取可以将数据并行传输到多个处理器内。因此HWC 更快。
但是,内存通常是分块的,不同处理器组管理不同的数据块,即多处理器需共享一个数据存储器,这降低了输入的最大允许尺寸。而使用 CHW 数据格式时,一般使用单个处理器处理一个内存数据块,下一个通道需要使用连接到不同数据存储器的处理器,以便机器可以在每个时钟周期将一个字节传送到每个启用的处理器中。
因此,"NHWC"更适合多核CPU运算,CPU的内存带宽相对较小,每个像素计算的时延较低,临时空间也很小,有时计算机采取异步的方式边读边算来减小访存时间,计算控制灵活且复杂。"NCHW"的计算时需要的存储更多,适合GPU运算,正好利用了GPU内存带宽较大并且并行性强的特点,其访存与计算的控制逻辑相对简单。
总的来说,不同排列方式并无优劣之分,它们也有相应的底层优化算法,对上层用户来说这些差异是看不见的。深度学习引擎特别会在推理的时候,根据实际硬件结构和计算资源,对数据排布进行转换,有些中间过程的数据的排布和访存甚至会有多种优化方式。这也是很多kernel优化所要做的。
3.c++ 图片HWC格式转CHW格式
vector<uint8_t> fileData(channels * height * width);
float* hostInputBuffer = static_cast<float*>(channels * height * width);
// Convert HWC to CHW and Normalize
for (int c = 0; c < channels; ++c)
{
for (int h = 0; h < height; ++h)
{
for (int w = 0; w < width; ++w)
{
int dstIdx = c * height * width + h * width + w;
int srcIdx = h * width * channels + w * channels + c;
hostInputBuffer[dstIdx] = static_cast<const float>(fileData[srcIdx]);
}
}
}4.c++ 图片CHW格式转HWC格式
vector<uint8_t> fileData(channels * height * width);
float* hostInputBuffer = static_cast<float*>(channels * height * width);
// Convert CHW to HWC and Normalize
for (int h = 0; h < height; ++h)
{
for (int w = 0; w < width; ++w)
{
for (int c = 0; c < channels; ++c)
{
int dstIdx = h * width * channels + w * channels + c;
int srcIdx = c * height * width + h * width + w;
hostInputBuffer[dstIdx] = static_cast<const float>(fileData[srcIdx]);
}
}
}
