项目开发
其他
1.项目开发经历了哪几个阶段? 45

2.白盒测试和黑盒测试 45


3.面向对象设计原则有哪些 45

4.写出简单工厂模式的示例代码 46

5.写出单例模式的示例代码 46


6.请对你所熟悉的一个设计模式进行介绍 47

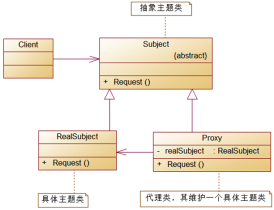
包括静态代理模式和动态代理模式,在实际开发中应用广泛的是动态代理模式,关键代码如下。



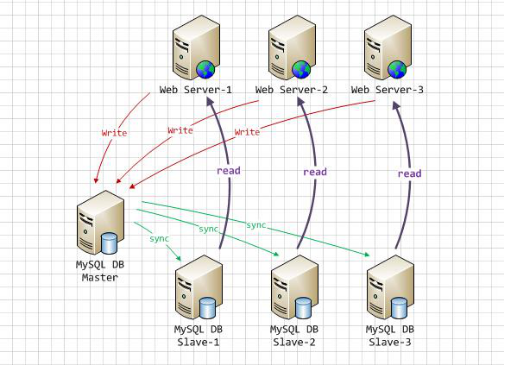
7. Mysql主从复制,读写分离
[简历描述]
Mysql主从复制结构使用1个master+2个slaver结构,实现读写分离,使用spring的动态数据源,解决DAO层访问不同数据库的问题
[项目描述]
当时,考虑到性能问题,当时在数据库方面,采用了mysql主从复制的结构,使用了1个master+2个slaver,
碰到写数据库操作,都访问master, 碰到写操作中有读的操作,也访问master,如果只有读的操作,访问slaver。
因为有了多个数据库,不同的操作访问不同的数据库,在代码实现上,需要在spring中配置动态数据源, 具体实现是,
编写一个动态数据源DynamicDataSource 继承AbstractDataSource,拥有属性master的数据源,slaver的数据源集合,
在spring配置文件中配置1个master的数据源,2个slaver的数据源,然后将他们都注入到DynamicDataSource的数据源中,在定义事务管理器TransactionManager时就使用DynamicDataSource。
编写一个DataSourceProcessor实现BeanPostProcessor,用它来实现master和slaver的数据源选择,在调用service层代理类之前,获得当前执行的方法名称,如果是写操作,就设置当前线程使用的数据源是master,如果是读操作,就设置当前线程使用的数据源是slaver,这里使用了ThreadLocal技术在线程间共享数据源类型。
之后执行service层的代理类,在DynamicDataSource 获取连接之前,会根据ThreadLocal中的数据源类型进行判断,如果是master,就使用master的数据源获取连接,如果是slaver,就会使用slaver的数据源获取连接,这里DynamicDataSource重写了获取连接的方法。
对于多个slaver,采用轮询的方式进行选取,就是定义一个计数器,每次获取slaver的时候,都将计数器加1,然后使用计数器对 slaver的个数 求余数,根据余数选取具体的slaver的数据源。
[说明]
1.
这里mysql的主从复制,采用了异步复制,这样master上的写操作会比较快。
2.
Mysql 主从复制,需要打开bin-log, 就是在mysql配置文件my.cnf(linux)中配置
Master, Slaver1, Slaver2的配置
|
master |
Slaver 1 |
Slaver2 |
|
server-id=1 binlog-do-db=demo log-bin=mysql-bin
|
server-id=2 master-host=master的地址 master-user=root master-password=root master-port=master的IP replicate-do-db=复制的数据库名称 |
server-id=3 master-host=master的地址 master-user=root master-password=root master-port=master的IP replicate-do-db=复制的数据库名 |
3.
Mysql主从复制原理,master将所有的写操作的sql语句都记录到bin-log, slaver 连接master获取新增加的bin-log,将新的sql语句在slaver自己的数据库上执行。
如果界定新增加的bin-log, master会为bin-log文件编号,而slaver每次连接master获取bin-log记录,都会记录获取的最大位置position。下次获取的时候,会获取这个位置position之后的日志
MySQL使用3个线程来执行复制功能(其中1个在主服务器上,另两个在从服务器上。
当发出START SLAVE时,从服务器创建一个I/O线程,以连接主服务器并让主服务器发送二进制日志。
主服务器创建一个I/O线程将二进制日志中的内容发送到从服务器。
从服务器I/O线程读取主服务器Binlog Dump线程发送的内容并将该数据拷贝到从服务器数据目录中的本地文件中,即中继日志。
第3个线程是从服务器SQL线程,从服务器使用此线程读取中继日志并执行日志中包含的更新。SHOW PROCESSLIST语句可以查询在主服务器上和从服务器上发生的关于复制的信息。
4.
Master, slaver相关操作
|
|
master |
slaver |
|
查看状态 |
show master status \G; |
show slave status \G; |
|
启动 |
start master; |
start slave; |
|
停止 |
stop master; |
stop slave; |
|
|
Bin-log file :mysql-bin.000003 Master最大位置:2351 Slaver最大位置:2351 |
|

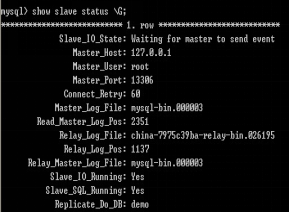
Slaver手动修正复制信息
先在master上使用show master status \G;查看master的信息,然后在slaver上执行
mysql> change master to
master_host=’master的ip’,
master_user=’访问master的用户名’,
master_password=’访问master的密码,
master_log_file=’master的bin-log文件’,
master_log_pos=261; (设置slaver当前同步的位置)

Spring配置文件:
<bean id="masterDataSource" class="org.logicalcobwebs.proxool.ProxoolDataSource">
<!--省略-->
</bean>
<bean id="slaverDataSource1" class="org.logicalcobwebs.proxool.ProxoolDataSource">
<!--省略-->
</bean>
<bean id="slaverDataSource2" class="org.logicalcobwebs.proxool.ProxoolDataSource">
<!--省略-->
</bean>
<bean id="dynamicDataSource" class="demo.j2ee.mysql.replication.DynamicDataSource">
<property name="master" ref="masterDataSource"/>
<property name="slavers">
<map>
<entry key="slaver1" value-ref="slaverDataSource1"/>
<entry key="slaver2" value-ref="slaverDataSource2"/>
</map>
</property>
</bean>
<bean id="dataSourceProcessor"
class="demo.j2ee.mysql.replication.DataSourceProcessor">
<property name="forceChoiceReadWhenWrite" value="false"/>
</bean>
<aop:config expose-proxy="true">
<!-- 只对业务逻辑层实施事务 -->
<aop:pointcut id="txPointcut"
expression="execution(* demo.j2ee.mysql.replication..service..*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="txPointcut"/>
<!-- 通过AOP切面实现读/写库选择 -->
<aop:aspect order="-2147483648" ref="dataSourceProcessor">
<aop:around pointcut-ref="txPointcut" method="determineReadOrWriteDB"/>
</aop:aspect>
</aop:config>
8. 全文检索
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法
全文检索是将存储于 数据库中整本书、整篇文章中的任意内容信息查找出来的检索。它可以根据需要获得全文中有关章、节、段、句、词等信息,也就是说类似于给整本书的每个字词添 加一个标签,也可以进行各种统计和分析。
例如,它可以很快的回答“《红楼梦》一书中“林黛玉”一共出现多少次?”的问题
各种中文分词器比较
开源框架
Apache lucene,
http://archive.apache.org/dist/lucene/java/
Apache Solr,lucene的企业级应用框架
http://lucene.apache.org/solr/
http://archive.apache.org/dist/lucene/solr/
Luke,Lucene索引管理工具
https://code.google.com/p/luke/
中文分词,分词器,词库,停词库
|
名称 |
网址 |
速度 |
词典 |
歧义排除 |
Lucene3 |
Lucene4 |
|
IKAnalyzer |
https://code.google.com/p/ik-analyzer/ |
IK2012具有160万字/秒(3000KB/S) |
支持多词典文件 |
支持 |
支持 |
支持 |
|
ansj |
https://github.com/ansjsun/ansj_seg
|
Ansj内存中分词:具有160万字/秒, 文件读写分词:每秒钟30万字
|
支持单词典文件 |
支持
|
支持 |
待验证 |
|
mmseg4j |
https://code.google.com/p/mmseg4j/ |
目前 complex 1200kb/s左右, simple 1900kb/s左右
|
支持
|
不支持
|
支持
|
支持 |
全文检索理解
例如,
发布一篇新闻A,新闻内容如下:
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版本开始,IKAnalyzer已经推出了3个大版本。
对内容进行分词,分词结果:
ikanalyzer | 是 | 一个 | 一 | 个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级| 量级 | 的 | 中文 | 分词 | 工具包 | 工具 | 包 | 从 | 2006 | 年 | 12 | 月 | 推出 | 1.0 | 版 | 开始 | ikanalyzer | 已经 | 推出 | 出了 | 3 | 个 | 大 | 版本
对每个分词,创建索引,比如,ikanalyzer这个分词,它关联了这篇新闻(即这篇新闻含有这个分词),只要查找ikanalyzer这个关键词,就能通过索引快速查找 ikanalyzer它关联的文档集里所有的新闻(这些新闻必然都包含这个关键词)
如果在发布一篇新闻B,内容如下:
IKAnalyzer已经升级了,可以兼容lucene4.x版本
同样,这个时候,也在ikanalyzer这个分词关联的文档集里加入这篇新闻
这个时候,搜索关键词ikanalyzer,就能搜索到两篇新闻,新闻A,新闻B,这两篇新闻都含有ikanalyzer这个关键词
再回到新闻A发布的时候, 这个时候其实对所有的分词都创建了索引,每个分词关联的文档集都添加了新闻A
这样,全文检索,可以理解为查找 分词 关联的 文档集 的文档(这里是新闻)
全文检索一般用于做站内检索,和百度,google,搜狗这些搜索网站不一样, 它们是去互联网上爬网页内容,然后把网页进行分词,创建索引,存储在自己的服务器,
站内检索,
一般用于CMS系统,对网站发布的新闻做搜索,
也可以用于对企业系统内部,上传的文件,做全文搜索,搜索哪些文件的文件名或文件内容含有某关键词
为什么用全文检索,
在数据库中,使用like 查询,也能查询,但是记录多了的时候,非常慢,
Lucene全文检索,为每个分词都创建了索引,所以查询的时候相当于只是查询分词关联的文档集,效率非常高
全文检索开发lucene+IKAnalyzer
引入jar包
Ikanalyzer:
IKAnalyzer2012_u6.jar
Lucene:
lucene-analyzers-3.6.2.jar
lucene-core-3.6.2.jar
lucene-highlighter-3.6.2.jar
文件解析,
用于解析各种文件,支持office文件word,excel等,pdf,text,html等,非常方便,tika是lucene的子项目
tika-app-1.2.jar
IKAnalyzer配置
源代码根路径,放置IKAnalyzer核心配置IKAnalyzer.cfg.xml,
配置用户扩展词典,配置用户扩展 停词库
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_dict">ikanalyzer/ext.dic</entry>
<entry key="ext_stopwords">ikanalyzer/stopword.dic</entry>
</properties>
在响应的目录下面,放置ext.dic(词库),stopword.dic(停词库)
Lucene的核心对象
IndexWriter(建索引添加文档),IndexSearcher(搜索)
Document(文档), Field(字段)
Field的构造参数
(String name,String content,Field.Store store,Field.Index index)
name: 字段名称
content: 内容
store: 是否存储
Field.Store.YES:存储字段值(未分词前的字段值)
Field.Store.NO:不存储,存储与索引没有关系
Field.Store.COMPRESS:压缩存储,用于长文本或二进制,但性能受损
Index: 是否索引
Field.Index.ANALYZED:分词建索引
Field.Index.NOT_ANALYZED:不分词且索引
Field.Index.ANALYZED_NO_NORMS:分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间
Field.Index.NOT_ANALYZED_NO_NORMS:不分词建索引,Field的值去一个byte保存
TermVector表示文档的条目(由一个Document和Field定位)和它们在当前文档中所出现的次数
Field.TermVector.YES:为每个文档(Document)存储该字段的TermVector
Field.TermVector.NO:不存储TermVector
Field.TermVector.WITH_POSITIONS:存储位置
Field.TermVector.WITH_OFFSETS:存储偏移量
Field.TermVector.WITH_POSITIONS_OFFSETS:存储位置和偏移量
新闻发布
当发布一篇新闻的时候,数据库表要保存一条记录,同时lucene的索引添加这篇文档
当修改这篇新闻的时候,数据库表要修改一条记录,同时lucene的索引更新这篇文档
当删除这篇新闻的时候,数据库表要删除一条记录,同时lucene的索引删除这篇文档
文件上传
上传文件之后, 使用tika解析文件内容,得到文件内容的字符串,对字符串做分词且索引
商品发布
这个时候,lucene的Document对象添加的Field包括文件id,文件名称,文件路径,文件内容
Mongodb存储商品数据,使用lucene+IKAnalyzer做站内商品搜索
Mongodb存储商品的数据,
1.商品的参数不统一,使用数据库表存储,字段固定之后,不容易扩展,
使用mongodb可以方便的存储不同的参数
2.mongodb是非关系型数据库,在大数据量下,查询效率比数据库表高,(比mysql快10倍)
使用mongodb同时,使用lucene+IKAnalyzer做站内商品的搜索,
可以对商品品牌,商品名称,重要参数以及商品描述内容等做分词索引,提高搜索效率,
使用jquery的autocomplete插件,实现搜索框自动补全的功能
Lucene新闻发布代码片段
//由新闻对象得到Lucene的Document对象
public Document getDocument(News news) {
Document doc = new Document();
// Field.Index.NO 表示不索引
// Field.Index.ANALYZED 表示分词且索引
// Field.Index.NOT_ANALYZED 表示不分词且索引
doc.add(new Field("id", String.valueOf(news.getId()), Field.Store.YES,
Field.Index.NOT_ANALYZED));
doc.add(new Field("title", news.getTitle(), Field.Store.YES,
Field.Index.ANALYZED));
doc.add(new Field("content", news.getContent(), Field.Store.YES,
Field.Index.ANALYZED));
return doc;
}
//在lucene索引中添加文档
public void add(News news) {
try {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(
Version.LUCENE_36, lip.getAnalyzer());
IndexWriter indexWriter = new IndexWriter(lip.getDirectory(),
indexWriterConfig);
Document document = getDocument(news);
indexWriter.addDocument(document);
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public void update(News news) {
try {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(
Version.LUCENE_36, lip.getAnalyzer());
IndexWriter indexWriter = new IndexWriter(lip.getDirectory(),
indexWriterConfig);
Document document = getDocument(news);
Term term = new Term("id", String.valueOf(news.getId()));
indexWriter.updateDocument(term, document);
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public void delete(Long id) {
try {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(
Version.LUCENE_36, lip.getAnalyzer());
IndexWriter indexWriter = new IndexWriter(lip.getDirectory(),
indexWriterConfig);
Term term = new Term("id", String.valueOf(id));
indexWriter.deleteDocuments(term);
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public List<News> search(String keyword) {
IndexSearcher indexSearcher = null;
List<News> result = new ArrayList<News>();
try {
// 创建索引搜索器,且只读
IndexReader indexReader = IndexReader.open(lip.getDirectory(), true);
indexSearcher = new IndexSearcher(indexReader);
String[] fields = new String[] { "title", "content" };
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(
Version.LUCENE_36, fields, lip.getAnalyzer());
Query query = queryParser.parse(keyword);
// 返回前number条记录
TopDocs topDocs = indexSearcher.search(query, 10);
// 信息展示
int totalCount = topDocs.totalHits;
System.out.println("共检索出 " + totalCount + " 条记录");
// 高亮显示,创建高亮器,使搜索的结果高亮显示 SimpleHTMLFormatter:
//用来控制你要加亮的关键字的高亮方式 此类有2个构造方法
//1:SimpleHTMLFormatter()默认的构造方法.加亮方式:<B>关键字</B>
//2:SimpleHTMLFormatter(String preTag, String postTag).
//加亮方式:preTag关键字postTag
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>",
"</font>");
//QueryScorer QueryScorer是内置的计分器。计分器的工作首先是将片段排序。
//QueryScorer使用的项是从用户输入的查询中得到的;
// 它会从原始输入的单词、词组和布尔查询中提取项,
Scorer fragmentScorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
Fragmenter fragmenter = new SimpleFragmenter(100);
// Highlighter利用Fragmenter将原始文本分割成多个片段。
// 内置的SimpleFragmenter将原始文本分割成相同大小的片段,片段默认的大小为100个字符。 //这个大小是可控制的。
highlighter.setTextFragmenter(fragmenter);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scDoc : scoreDocs) {
Document document = indexSearcher.doc(scDoc.doc);
Long id = Long.parseLong(document.get("id"));
String title = document.get("title");
String content = document.get("content");
// float score = scDoc.score; //相似度
String lighterTitle = highlighter.getBestFragment(
lip.getAnalyzer(), "title", title);
if (null == lighterTitle) {lighterTitle = title;}
String lighterContent = highlighter.getBestFragment(
lip.getAnalyzer(), "content", content);
if (null == lighterContent) {lighterContent = content;}
News news = new News();
news.setId(id);
news.setTitle(lighterTitle);
news.setContent(lighterContent);
result.add(news);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
indexSearcher.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
9. PV,UV,IP

10. 单点登录
[简历描述]
使用CAS实现本系统和其他业务系统的单点登录。
[项目描述]
在项目中,客户要求我们的系统和其他的系统,能够在一个系统上登录,其他的系统不再登录就可以使用。
当时我们使用了CAS集成多个系统,实现单点登录。
当用户访问系统A,如果没有登录,A系统先重定向到CAS服务器,
当用户在CAS服务器上登录后,向用户的客户端浏览器写一个cookie,这个是加密的cookie,然后,重定向到系统A,此时会携带一个ticket进行授权, 系统A通过ticket判断是否登录成功
当用户再访问其他系统B的时候,系统B也重定向到CAS服务器,这个时候,CAS服务器根据用户的客户端浏览器发送的cookie,判断该用户已经登录,然后CAS服务器重定向到系统B,同时会携带一个ticket进行授权,系统B根据ticket判断是否登录成功。
[说明]
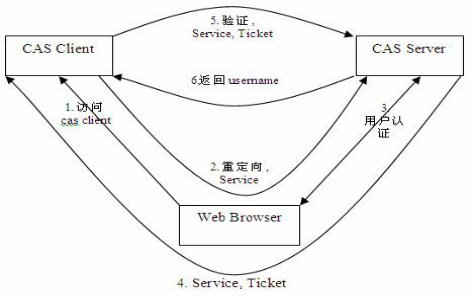
CAS原理说明, 下面的图中,
CAS Client就是系统A,CAS Server就是CAS服务器, Web Browser就是用户的客户端浏览器
下图中没有画出系统B的登录过程,需要经过步骤1,2,4,5,6
11. 测试


12.逻辑题目
村子里有50个人,每人有一条狗。在这50条狗中有病狗(这种病不会传染)。于是人们就要找出病狗。每个人可以观察其他的49条狗,以判断它们是否生病,只有自己的狗不能看。观察后得到的结果不得交流,也不能通知病狗的主人。主人一旦推算出自己家的是病狗就要枪毙自己的狗,而且每个人只有权利枪毙自己的狗,没有权利打死其他人的狗。第一天,第二天都没有枪响。到了第三天传来一阵枪声,问有几条病狗,如何推算得出?
第一种推论:
1.假设有1条病狗,病狗的主人会看到其他狗都没有病,那么就知道自己的狗有病,所以第一天晚上就会有枪响。因为没有枪响,说明病狗数大于1。
2.假设有2条病狗,病狗的主人会看到有1条病狗,因为第一天没有听到枪响,说明病狗数大于1,所以病狗的主人会知道自己的狗是病狗,因而第二天会有枪响。既然第二天也没有枪响,说明病狗数大于2。由此推理,如果第三天枪响,则有3条病狗。
第二种推论:
1.如果为1条病狗,第一天那条狗必死,因为狗主人没看到病狗,但病狗存在。
2.若为2条病狗,狗主人为a、b。a看到一条病狗,b也看到一条病狗,但a看到b的病狗没死故知狗数不为1,而其他人没病狗,所以自己的狗必为病狗,故开枪;而b的想法与a一样,故也开枪。由此,为2时,第一天后2条狗必死。
3.若为3条病狗,狗主人为a、b、c。a第一天看到2条病狗,若a设自己的不是病狗,由推理2,第二天看时,那2条狗没死,故狗数肯定不是2,而其他人没病狗,所以自己的狗必为病狗,故开枪;而b和c的想法与a一样,故也开枪。由此,为3时,第二天后3条狗必死。
4.余下即为递推了,由n-1推出n。
答案:n为4。第四天看时,狗已死了,但是在第三天死的,故答案是3条。




