初识MySql
数据库介绍
我们之前使用的数据都是存储在内存中的!比如说我们写一个注册功能。
我们首先需要在内存中创建一个对象,之后输入注册需要的用户名和密码等数据!
然后登陆时,输入注册的数据即可完成登陆!
注册成功之后 比如用户名是admin 密码是123456
出现的问题:
请问
01.用户的数据放在哪里了?
02.如果放在内存中,下次登陆还使用之前注册的用户名和密码,能登陆吗?
显然是不能的! 因为程序一旦运行完毕,内存中的数据也随之消失!
怎么办?
01使用序列化保存对象到文件中
02.使用xml保存数据到文件中
但是把大量的数据放在文件中,我们对文件数据的读写效率是相对较慢的!
而且也不便于我们管理文件中的数据!这时候就需要有新的存储方式来代替!
就是我们所谓的数据库(存储数据的仓库)!
什么是数据库
定义 按照数据结构来组织 储存和管理数据的仓库,我们称之为数据库Database(DB)
这些存储的数据可以是多种形式 如文字 符号 图片 视频 音频等
从广义上来说 我们的txt文件 word文档 excel文件 都可以理解成一个数据库
在it的世界里数据库指的是有专业技术团队开发的用于存储数据的软件系统
使用 数据库的必要性
1、可以结构化的存储大量的数据信息 方便用户进行访问和操作数据库可以对数据进行分类保存 提高我们的访问效率
2、可以保证数据信息的一致性 完整性 降低数据的冗余
数据库中有事务(ACID特性)来保证数据信息的一致性 完整性
数据库自身也有有数来降低数据的冗余
ps 数据冗余 (redundance)数据重复的现象
3、可以满足应用的安全和共享方面的要求
如果我们把员工的所有信息 都保存在一个txt文件中 那么员工的薪水就会暴露出来 很显然这是不允许的
如果把数据放在数据库中 我们可以限制只有财务人员才能查询薪水 而其他员工只能查询自己的信息
常见的关系型数据库
1、sql server
是microsoft公司的关系型数据库管理系统
2、Mysql
是一种开放源代码的关系型数据库管理系统
3、Oracle
是Oracle公司的关系型数据库管理系统
ps 虽然数据不一样 但是对数据库的操作都大同小异 有的操作命令都是一致的
关系型数据库:是指建立在关系模型基础上的数据库 借助于集合代数等数学概念和方法来处理数据库的数据
关系型数据库与菲关系型数据库
常见的非关系型数据库 Mongo DB Redis HBase
在关系模型中 数据结构表示为一个二维表 一个关系就是一个二维表(但不是任意一个二维表都能表示一个关系),二维表就是关系名表中的第一行通常称为属性名,表中的每一个元组和属性都是不可再分的 且元组的次序是无关紧要的
常用的关系术语如:
记录 二维表中每一行称为一个记录 即元组
字段 二维表中每一列称为一个字段 即属性
域 属性的取值范围
两者的优缺点
关系型数据库
1、容易理解 存放在数据库中的数据就是以二维表的形式存储的
ps 二维表就是有行和列组成的 知道行号和列号就能定位到表中的数据 excel就是二维表
2、使用方便 基于通用的sql语言使用操作关系型数据库方便
3、支持sql 所以可以进行复杂的查询
4、易于维护 丰富的完整性(域完整性 实体完整性 擦找完整性和自定义完整性)
大大降低了数据冗余 事务的ACID特性保证了数据的一致性
5、读写性能低
6、对海量数据的处理不如菲关系型数据库
7、分布式不够完善
非关系型数据库
1、不支持sql 省去了解析sql的步骤 读写性能高
2、基于键值对的形式 数据没有耦合性 扩张性强
3、可以实现数据的分布式处理
4、适用于海量数据的处理
5、持久化性能低
6、因为没有事务 所以数据安全性不高
7、出道时间短 功能没有关系型数据库完善
关系型数据库的不足
不擅长处理:
1、大量数据的写入处理
2、为有数据更新的表做索引或表结构(schema)变更
3、字段不固定时应用
4、对简单查询需要快速返回结果的处理
-----大量数据的写入处理
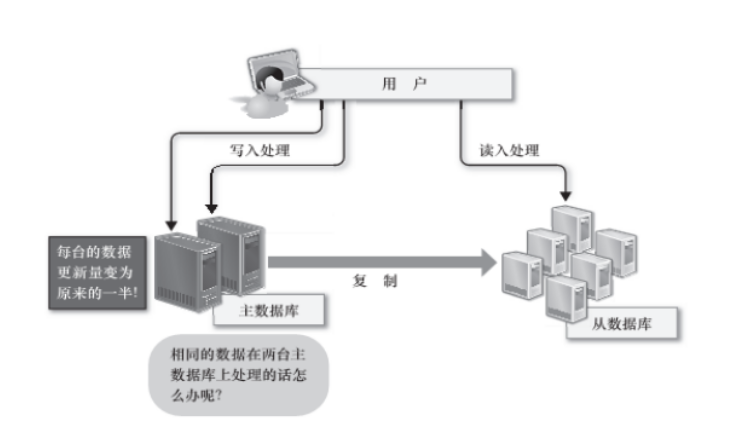
读写集中在一个数据库上让数据库不堪重负 大部分网站已使用主从复制技术实现读写分离 以提高读写性能和毒库的可扩展性
所以在进行大量数据操作时 会使用数据库主从模式 数据的写入有主数据库负责 数据的读入由从数据库负责 可以比较简单的通过增加从数据来实现规模化 但是数据的写入却完全没有简单的方法来解决规模化问题
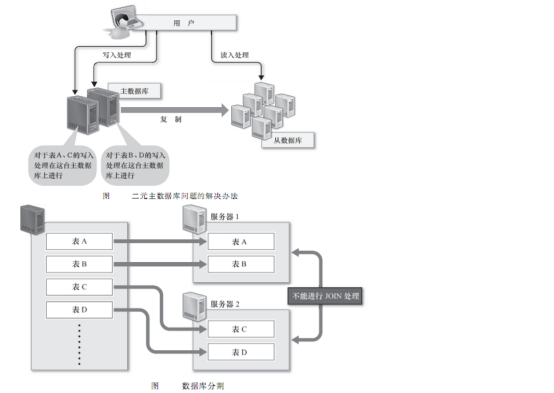
第一 要想将数据的写入规模化 可以考虑把主数据库从一台增加到2台 作为互相关联复制的二元主数据库使用 却是这样可以把每台主数据库的复合减少一半 但是更新处理会发生冲突 可能会造成数据的不一致 为了避免这样的问题 需要把对每个表的请求分别分配给合适的主数据库来处理
第二 可以考虑把数据库分割开来 分别放在不同的数据库服务器上 比如讲不同的表放在不同的数据库服务器上 数据库分割可以减少每台数据库服务器上的数据量 一边减少影片io的输入 输出处理 实现内存上的高速处理 但是由于分别储存不同服务器上的表之间无法进行join处理 数据库分割的时候就需要预先考虑这些问题 数据库分割之后 如果一定要进行Join处理 就必须要在程序中进行关联 这是非常困难的
为有数据更新的表做索引或表结构变更
在使用关系型数据库时 为了加快查询速度需要创建索引 为了增加必要的字段就一定要改变表结构为了进行这项处理 需要对表进行共享锁定 这期间数据变更 更新 插入 删除等都是无法进行的
如果需要进行一些耗时操作 例如为数据量比较大的表创建索引或是变更其表结构 就需要特别注意 长时间内数据可能无法进行更新
字段不固定的应用
如果字段不固定 利用关系型数据库也是比较困难的 有人会说 需要的时候价格字段就可以了 这种方法不是不可以 但是实际运用中每次都进行反复的表结构变更是非常痛苦的 你也可以预先设定大量的预备字段 但是这样的话 时间一长很容易弄不清楚字段和数据的对应状态 即哪个字段保存有哪些数据
对简单查询需要快速返回结果的处理 (没有复杂的查询条件)
这一点称不上是缺点 但不管怎样 关系型数据库并不擅长对简单的查询快速返回结果 因为关系型数据库是使用专门的sql语言进行数据读取的 他需要对sql语言进行解析 同时还要对表的锁定和解锁等这样的额外开销 这里并不是说关系型数据库的速度太慢 而只是想告诉大家若希望对简单查询进行告诉处理 则没有必要非食用关系型数据库不可
Mysql数据库的特点
版本分:社区(自由免费下载)和企业(不能自由下载 收费 官方提供了完整的技术支持 适合对数据库要求比较高的企业用户)
优点
1、运行速度快 mysql体积小 命令执行速度快
2、食用成本低 mysql免费开源(大多数人)
3、易学易用 相对来说(设置 管理)
4、可移植性强 能够运行在windows linux unix 等多系统中
数据库管理系统和数据库系统
数据库管理系统DataBase Management System (DBMS)
数据库系统DataBase System (DBS)数据库和数据库管理员
数据库管理员DataBase Administrator(DBA)创建 监控 维护数据库的专业管理人员
数据库DataBase
ps 关系型数据库管理系统(Relational DataBase Management System)
数据库以表格形式出现
每行为各种记录名称
没列为各种记录所对应的数据域
许多的行和列组成一张表单
若干的表单组成database
数据库中相关的名词
数据库 数据表的集合
数据表 数据的集合
行 一行数据(元组或记录)横向
列 一列数据(字段)纵向
主键(Primary key):唯一标示数据的字段
外键(Foreign key):关联两个表之间关系的字段
标识列是自增列
主键是唯一
复合主键
所谓的复合主键 就是指你表的主键含有一个以上的字段组成 不适用无业务含义的自增id作为主键
如
create table test(
id number
value varchar(10),
primary key(name,id))
上面的name和id字段组合起来就是你test表的复合主键 他的出现是因为你的name字段可能会出现重名 所以要加上ID字段这样就可以保住你记录的唯一性 一般情况下 主键的字段长度和字段数目越少越好
其实“主键是唯一的所有”这句话是有歧义的 在表中创建了一个ID字段 自动增长 并设为主键 这个是没有问题的 因为主键是唯一的索引 ID自动增长保住了唯一性 可以
但是我们再创建一个字段name 类型为varchar 也设置为主键 你会发现 在表的多行中 你是可以填写相同的name值的 这岂不是有违 主键是唯一的索引 !
当表中只有一个主键时!他是唯一的索引 当表中有多个主键时 称为复合主键 复合主键联合保证唯一索引
为什么自增长ID已经可以作为唯一标识的主键 为啥还需要复合主键呢 因为 并不是所有的表都要有ID这个字段 比如 我们建一个学生表 没有唯一能标识学生的ID 怎么办呢 学生的名字 年龄 班级 都可能重复 无法使用单个字段来唯一标识 这时 我们可以将多个字段设置为主键 形成复合主键 这多个字段联合标识唯一性 其中 某几个主键字段值出现重复是没有问题的 只要不是有多条记录的所有主键值完全一样 就不算重复
数据完整性
存储在数据库中的所有数据值均正确的状态 如果数据库中存储有不正确的数据值 则该数据库称为已丧失数据完整性
组成部分
1、实体完整性(Entity Integrity)
2、域完整性(Domain Integrity)
3、参照完整性(Referential Integrity)
4、用户自定义完整性(User Defined Integrity)

