
1. f 格式化操作,相当于format()函数
1 name = 'wy' 2 s = f'{{"name": "{name}"}}' 3 print(s)
{"name": "wy"}
f-string,亦称为格式化字符串常量(formatted string literals),是Python3.6新引入的一种字符串格式化方法,该方法源于PEP 498 – Literal String Interpolation,主要目的是使格式化字符串的操作更加简便。f-string在形式上是以 f 或 F 修饰符引领的字符串(f'xxx'或 F'xxx'),以大括号 {} 标明被替换的字段;f-string在本质上并不是字符串常量,而是一个在运行时运算求值的表达式:
While other string literals always have a constant value, formatted strings are really expressions evaluated at run time. (与具有恒定值的其它字符串常量不同,格式化字符串实际上是运行时运算求值的表达式。) —— Python Documentation
f-string大括号内根本就不允许出现 \。如果确实需要 \,则应首先将包含 \ 的内容用一个变量表示,再在f-string大括号内填入变量名
>>> f"newline: {ord('\n')}" File "<stdin>", line 1 SyntaxError: f-string expression part cannot include a backslash >>> newline = ord('\n') >>> f'newline: {newline}' 'newline: 10'
多行f-string
f-string还可用于多行字符串:
>>> name = 'Eric' >>> age = 27 >>> f"Hello!" \ ... f"I'm {name}." \ ... f"I'm {age}." Hello!I'm Eric.I'm 27.
>>> f"""Hello! I'm {name}. I'm {age}."""
Hello!
I am Eric.
I am 27.
自定义格式:对齐、宽度、符号、补零、精度、进制等
f-string采用 {content:format} 设置字符串格式,其中 content 是替换并填入字符串的内容,可以是变量、表达式或函数等,format是格式描述符。采用默认格式时不必指定 {:format},如上面例子所示只写 {content} 即可。
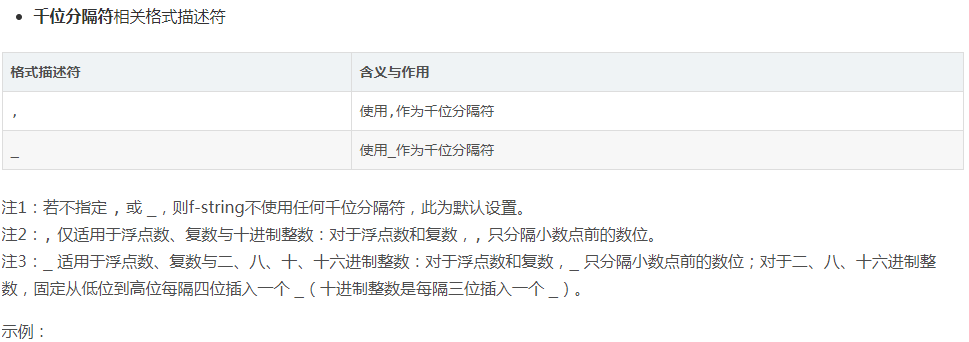
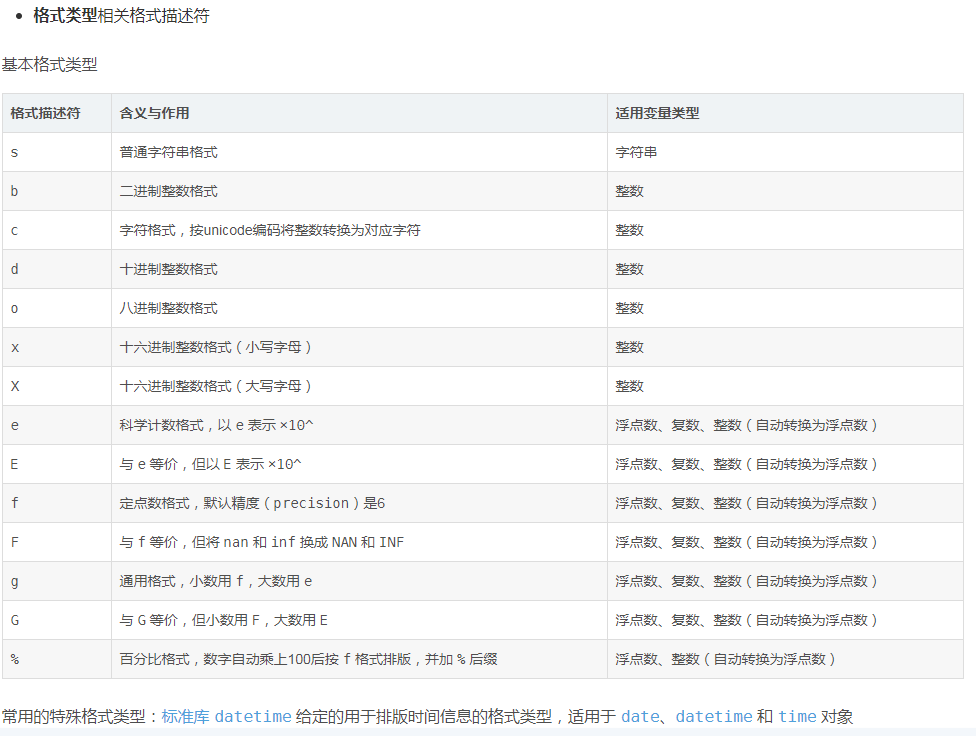
关于格式描述符的详细语法及含义可查阅Python官方文档,这里按使用时的先后顺序简要介绍常用格式描述符的含义与作用:
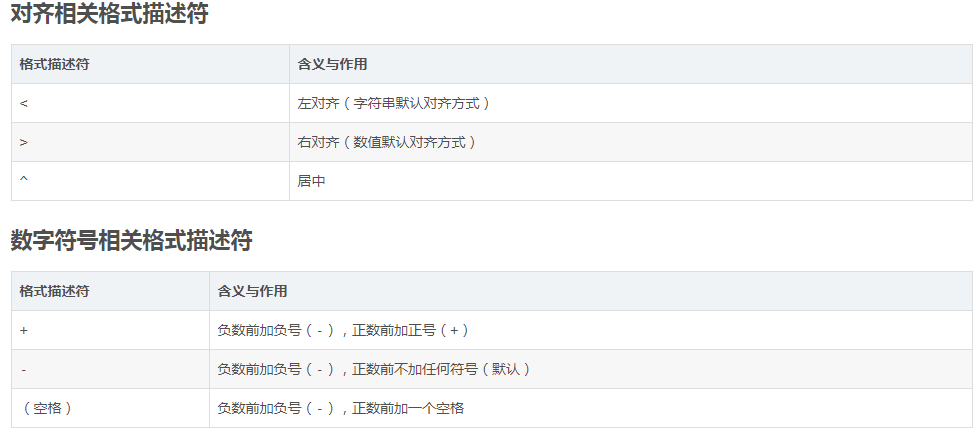
#右对齐
1 for line in [[1, 128, 1298039], [123388, 0, 2]]: 2 print('{:>8} {:>8} {:>8}'.format(*line)) 3 4 for line in [[1, 128, 1298039], [123388, 0, 2]]: 5 print(f'{line[0]:>8} {line[1]:>8} {line[2]:>8}')

1 # 左右对齐 2 print(f"{'Trades:':<15}{2034:>10}", 3 f"\n{'Wins:':<15}{1232:>10}", 4 f"\n{'Losses:':<15}{1035:>10}", 5 f"\n{'Breakeven:':<15}{37:>10}", 6 f"\n{'Win/Loss Ratio:':<15}{1.19:>10}", 7 f"\n{'Mean Win:':<15}{0.381:>10}", 8 )
#用指定的字符填充 >>> name = "Huang Wei" >>> f"{name:_>20}" '___________Huang Wei'
python-tabulate 支持多种格式,详细请参考github
pip install tabulate
>>> from tabulate import tabulate >>> table = [["Sun",696000,1989100000],["Earth",6371,5973.6], ... ["Moon",1737,73.5],["Mars",3390,641.85]] >>> print(tabulate(table)) ----- ------ ------------- Sun 696000 1.9891e+09 Earth 6371 5973.6 Moon 1737 73.5 Mars 3390 641.85 ----- ------ -------------
print(f'{3:0b}') print(f'{3:#0b}')
11
0b11
>>> a = 123.456 # 只指定width >>> f"{a:10}" ' 123.456' # 只指定0width >>> f"{a:010}" '000123.456' # 使用width.precision >>> f"{a:8.1f}" ' 123.5' >>> f"{a:8.2f}" ' 123.46' >>> f"{a:.2f}" '123.46' # 在width后面,直接加f,表示补足小数点后的位数至默认精度6 >>> f"{a:2f}" '123.456000'
#截断与填充的结合使用 >>> a = "Hello" # 当发生截断的时候,如果不指定填充符,默认使用空格填充 >>> f"{a:10.3}" 'Hel ' # 在发生截断的时候,使用指定的填充符 >>> f"{a:_>10.3}" '_______Hel' >>> f"{a:_<10.3}" 'Hel_______'
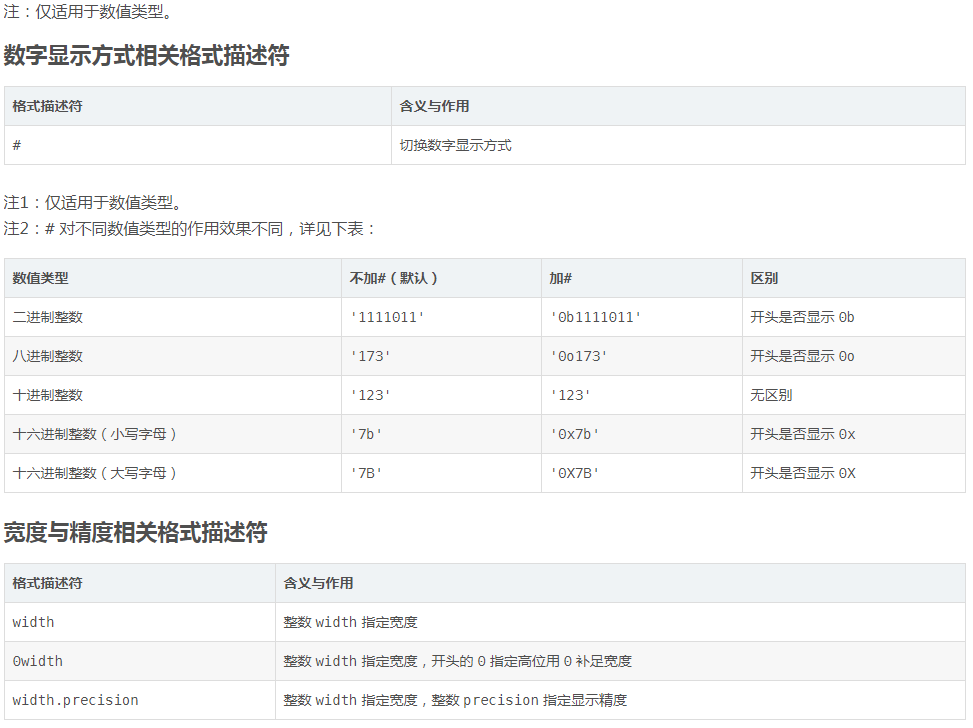
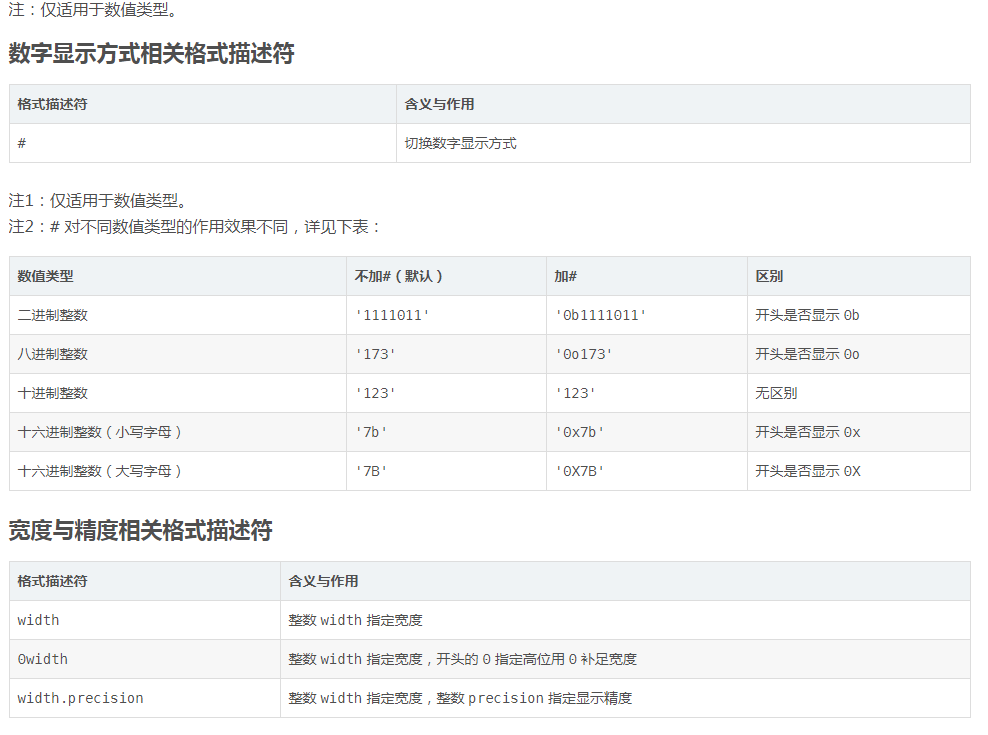
注1:0width 不可用于复数类型和非数值类型,width.precision 不可用于整数类型。
注2:width.precision 用于不同格式类型的浮点数、复数时的含义也不同:用于 f、F、e、E 和 % 时 precision 指定的是小数点后的位数,用于 g 和 G 时 precision 指定的是有效数字位数(小数点前位数+小数点后位数)。
注3:width.precision 除浮点数、复数外还可用于字符串,此时 precision 含义是只使用字符串中前 precision 位字符。
示例:

>>> a = 123.456
>>> f'a is {a:8.2f}'
'a is 123.46'
>>> f'a is {a:08.2f}'
'a is 00123.46'
>>> f'a is {a:8.2e}'
'a is 1.23e+02'
>>> f'a is {a:8.2%}'
'a is 12345.60%'
>>> f'a is {a:8.2g}'
'a is 1.2e+02'
>>> s = 'hello'
>>> f's is {s:8s}'
's is hello '
>>> f's is {s:8.3s}'
's is hel '
>>> a = 1234567890.098765
>>> f'a is {a:f}'
'a is 1234567890.098765'
>>> f'a is {a:,f}'
'a is 1,234,567,890.098765'
>>> f'a is {a:_f}'
'a is 1_234_567_890.098765'
>>> b = 1234567890
>>> f'b is {b:_b}'
'b is 100_1001_1001_0110_0000_0010_1101_0010'
>>> f'b is {b:_o}'
'b is 111_4540_1322'
>>> f'b is {b:_d}'
'b is 1_234_567_890'
>>> f'b is {b:_x}'
'b is 4996_02d2'

>>> a = 1234
>>> f'a is {a:^#10X}' # 居中,宽度10位,十六进制整数(大写字母),显示0X前缀
'a is 0X4D2 '
>>> b = 1234.5678
>>> f'b is {b:<+10.2f}' # 左对齐,宽度10位,显示正号(+),定点数格式,2位小数
'b is +1234.57 '
>>> c = 12345678
>>> f'c is {c:015,d}' # 高位补零,宽度15位,十进制整数,使用,作为千分分割位
'c is 000,012,345,678'
>>> d = 0.5 + 2.5j
>>> f'd is {d:30.3e}' # 宽度30位,科学计数法,3位小数
'd is 5.000e-01+2.500e+00j'
>>> import datetime
>>> e = datetime.datetime.today()
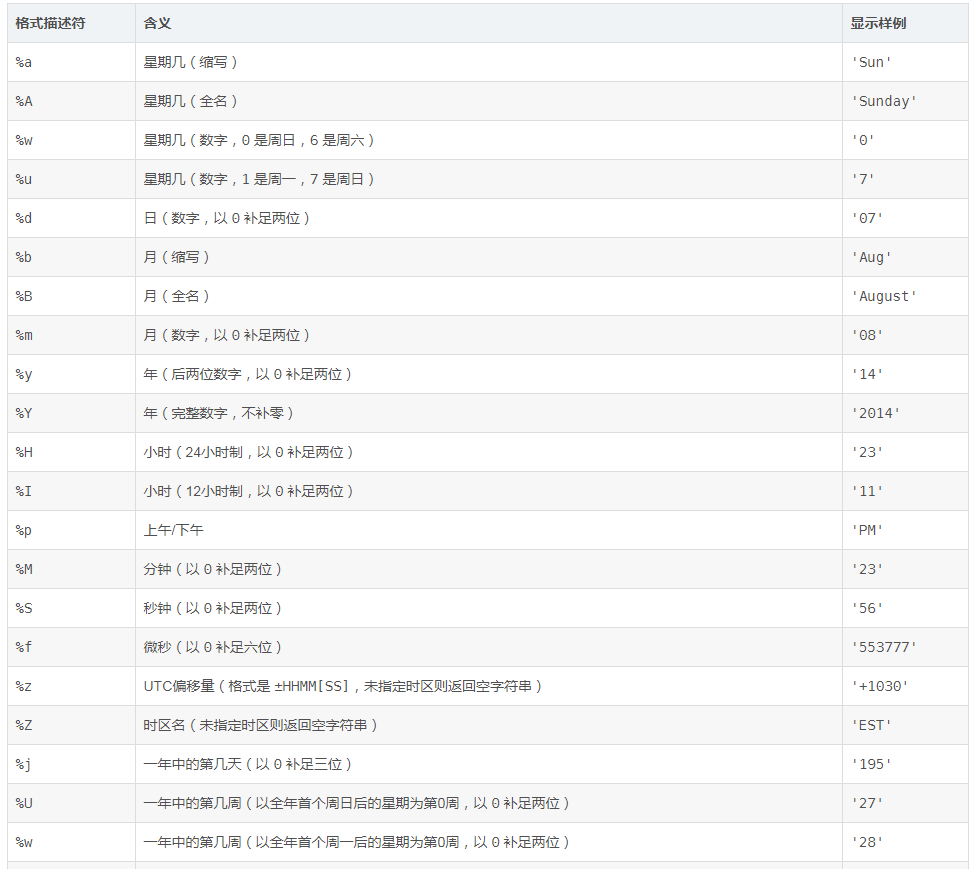
>>> f'the time is {e:%Y-%m-%d (%a) %H:%M:%S}' # datetime时间格式
'the time is 2018-07-14 (Sat) 20:46:02'
- lambda表达式
f-string大括号内也可填入lambda表达式,但lambda表达式的 : 会被f-string误认为是表达式与格式描述符之间的分隔符,为避免歧义,需要将lambda表达式置于括号 () 内:
>>> f'result is {lambda x: x ** 2 + 1 (2)}'
File "<fstring>", line 1
(lambda x)
^
SyntaxError: unexpected EOF while parsing
>>> f'result is {(lambda x: x ** 2 + 1) (2)}'
'result is 5'
>>> f'result is {(lambda x: x ** 2 + 1) (2):<+7.2f}'
综合示例
>>> a = 1234
>>> f'a is {a:^#10X}' # 居中,宽度10位,十六进制整数(大写字母),显示0X前缀
'a is 0X4D2 '
>>> b = 1234.5678
>>> f'b is {b:<+10.2f}' # 左对齐,宽度10位,显示正号(+),定点数格式,2位小数
'b is +1234.57 '
>>> c = 12345678
>>> f'c is {c:015,d}' # 高位补零,宽度15位,十进制整数,使用,作为千分分割位
'c is 000,012,345,678'
>>> d = 0.5 + 2.5j
>>> f'd is {d:30.3e}' # 宽度30位,科学计数法,3位小数
'd is 5.000e-01+2.500e+00j'
>>> import datetime
>>> e = datetime.datetime.today()
>>> f'the time is {e:%Y-%m-%d (%a) %H:%M:%S}' # datetime时间格式
'the time is 2018-07-14 (Sat) 20:46:02'
lambda表达式
f-string大括号内也可填入lambda表达式,但lambda表达式的 : 会被f-string误认为是表达式与格式描述符之间的分隔符,为避免歧义,需要将lambda表达式置于括号 () 内:
>>> f'result is {lambda x: x ** 2 + 1 (2)}'
File "<fstring>", line 1
(lambda x)
^
SyntaxError: unexpected EOF while parsing
>>> f'result is {(lambda x: x ** 2 + 1) (2)}'
'result is 5'
>>> f'result is {(lambda x: x ** 2 + 1) (2):<+7.2f}'
# 使用%、format、f-string打印九九乘法表 for i in range(1,10): for j in range(1,i+1): print("%s*%s=%s" % (j,i,j*i),end=" ") print("\n") for i in range(1,10): for j in range(1,i+1): print("{0}*{1}={2}".format(j,i,j*i),end=" ") print("\n") for i in range(1,10): for j in range(1,i+1): print(f"{j}*{i}={j*i}",end=" ") print("\n")
注:若要输出{则需双写{{,输出}需要双写}}
2. b二进制,相当于bytes
1 s = 'wy' 2 print(s, type(s)) 3 b = b'wy' 4 print(b, type(b))
wy <class 'str'>
b'wy' <class 'bytes'>
注:encode和decode也可以在二进制和字符串之间转换
1 name1 = 'wy'.encode('utf8') 2 print(name1, type(name1)) 3 name2 = name1.decode('utf8') 4 print(name2, type(name2))
b'wy' <class 'bytes'>
wy <class 'str'>
3. u/U 表示unicode字符串
不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。
一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
建议所有编码方式采用utf8
4. r/R 非转义的原始字符串,原义输出
相对特殊的字符,其中可能包含转义字符,反斜杠加上对应字母,表示对应的特殊含义的,
比如最常见的”\n”表示换行,”\t”表示Tab等
以r开头的字符,常用于正则表达式,对应着re模块。
1 name1 = 'w\ny' 2 print(name1) 3 name1 = r'w\ny' 4 print(name1)
w
y
w\ny

 浙公网安备 33010602011771号
浙公网安备 33010602011771号