

在学习读取csv文件读取时,发现一个问题:网上学习的代码比比皆是,可是举例中csv文件都不存在中文(好多说不支持中文),所以在尝试含有中文读取时(就是不死心,哈哈),发现了几个报错,在度娘的帮助下已顺利解决。下面就总结下解决过程。
1、csv文件:
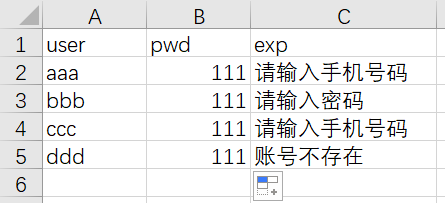
2、在红黑联盟中看到了读取csv文件的介绍,于是写了第一次代码:
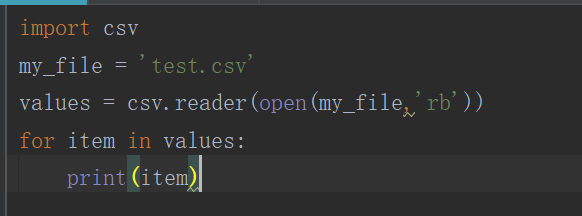
运行结果:
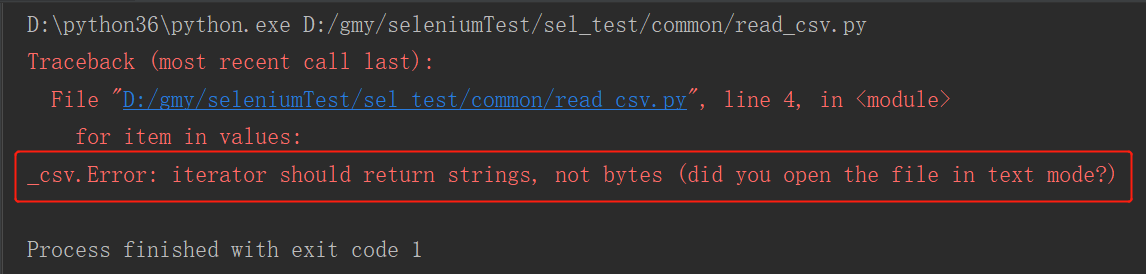
从报错中可以看出csv文件并非二进制文件, 只是一个文本文件
3、于是,修改成以下代码

运行结果:
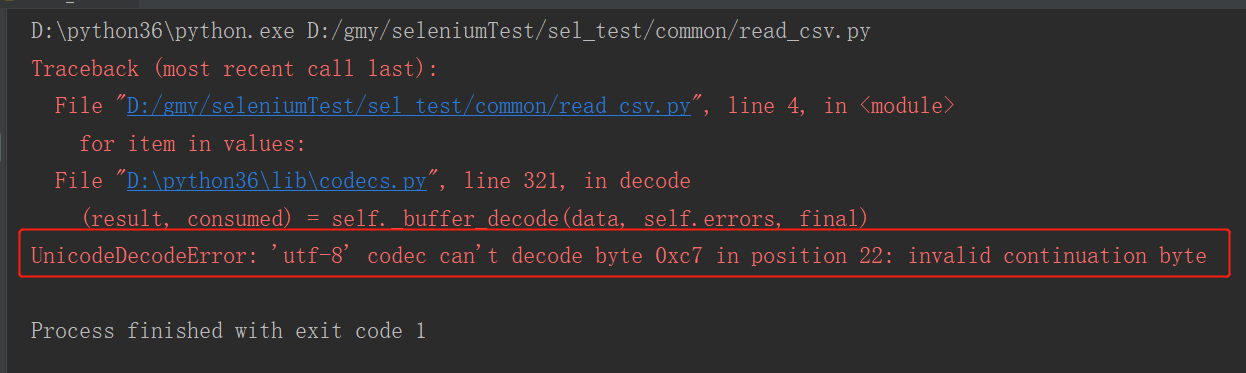
报错提示“utf-8”编解码器无法解码位置22中的字节0xc7,说明该csv文件未使用utf-8编码,因此无法使用utf-8编码器打开它。
4、于是,将文件另存,选择保存类型为:CSV UTF-8(逗号分隔)
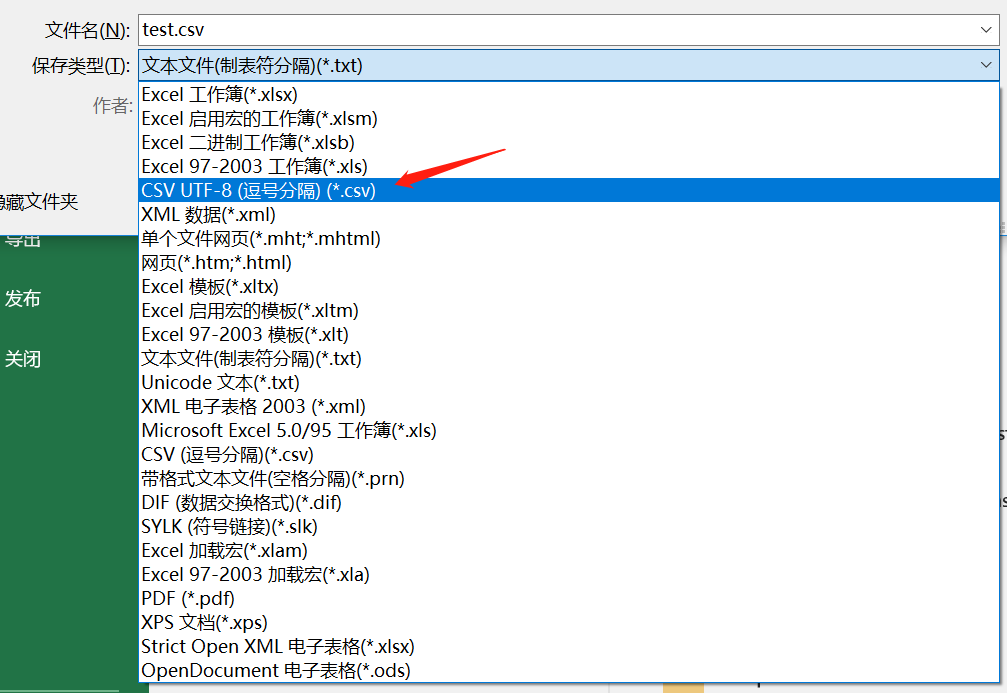
再运行代码,结果如下:
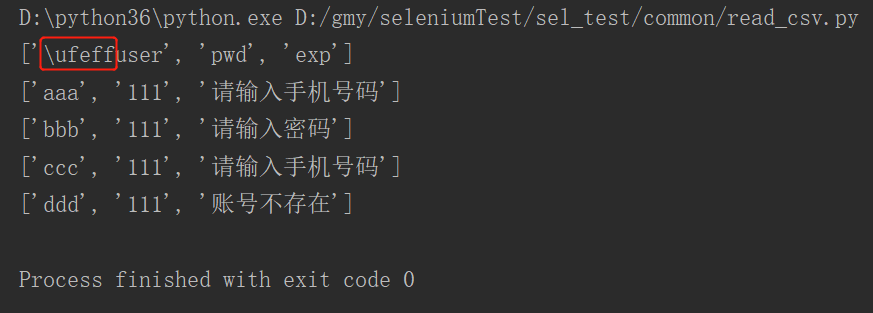
从结果可以看出,中文已正常显示,但是第1行第1列中多显示了‘\ufeff’这个东东。
然后就了解了utf-8与utf-8-sig两种编码格式的区别:
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE.
UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序的问题,也因此它实际上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
紧接着,将代码改成如下样子:
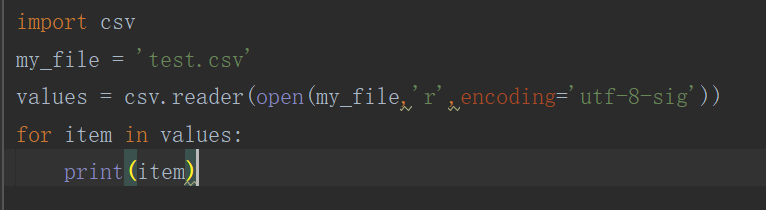
运行结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号