
一、定义
一个.py文件就称之为一个模块(module)
格式:
1.import 模块名
2.from 模块名 import 函数名
from 模块名 import * (引入模块中的一切函数)#最好不用
python 种类:
1.python标准库模块/内置模块
2.第三方模块
3.应用程序自定义模块
文件夹和包的区别:包比文件夹内部会多一个__init__.py文件
import:
1.执行调用的文件
2.引入变量名
__name__在执行文件中运行print→__main__
__name__在调用文件中运行print→调用文件的地址
if __name__ == '__main__'的作用
1.用于被调用文件的测试
2.用于执行文件是为了不让别人直接调用该执行文件
BASE_DIR介绍
import os, sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))#找文件的上一层目录
sys.path.append(BASE_DIR)
from my_module import main
main.add(3, 5)
二、random模块
import random
print(random.random())#输出是(0, 1)之间的浮点型
print(random.randint(1, 3))#输出范围是[1, 3]
print(random.randrange(1, 3))#输出范围是[1, 3)
print(random.choice([11, 22, 33, 44]))
print(random.sample([11, 22, 33, 44], 2))
print(random.uniform(1, 6))#输出是任意范围之间的浮点型
item = [1, 2, 3, 4, 5]
random.shuffle(item)#打乱次序
print(item)
需求:做一个验证码函数
def v_code():
ret = ''
for i in range(0, 5):
num = random.randint(0, 9)
alf = chr(random.randint(65, 122))
s = str(random.choice([num, alf]))
ret += s
return ret
print(v_code())
二、time时间模块
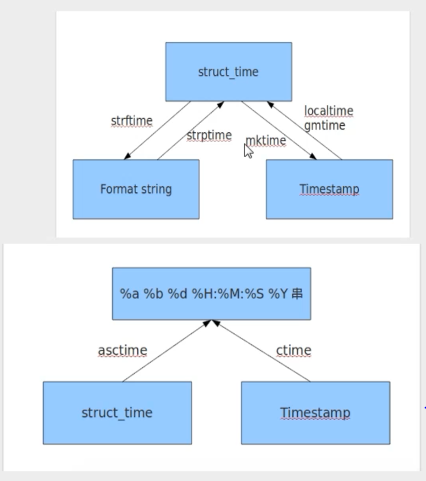
import time
#时间戳:做计算用
print(time.time())#1970年凌晨算起,过去了多少秒
#结构化时间---当地时间
print(time.localtime())#参数默认是当前的时间戳time.time(),也可以传入其他时间戳
print(time.localtime(1234566778))
t = time.localtime()
print(t.tm_year)
print(t.tm_wday)
#结构化时间格---林尼治标准时间
print(time.gmtime())
import time
#将结构化时间转换为时间戳
print(time.mktime(time.localtime()))
#将结构化时间转换为字符串时间
print(time.strftime('%Y-%m-%d %X', time.localtime()))
#将字符串时间转换为结构化时间
print(time.strptime('2018:05:06:14:59:23', '%Y:%m:%d:%X'))
#将结构化时间转化为固定的字符串表达形式,没有参数,默认传入time.localtime()作为参数
print(time.asctime())
#将时间戳转化为字符串
print(time.ctime())
import datetime
print(datetime.datetime.now())
三、os 模块
import os
print(os.getcwd())#获取当前目录
os.chdir('test_a')#从当前目录切换到另一目录
print(os.getcwd())
import os
print(os.getcwd())#获取当前目录
os.chdir('..')#返回上一层目录
print(os.getcwd())
import os
print(os.getcwd())#获取当前目录
os.chdir('..')#返回上一层目录
print(os.getcwd())
# os.makedirs('dirname1/dirname2')#生成多层递归目录
os.removedirs('dirname1/dirname2')#若目录为空则删除,若不为空,则不删除
os.makedir('dirname')#生成单级目录
os.rmdir('dirname')#删除单级空目录,若目录不为空,则无法删除,报错
os.listdir('dirname')#列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove()#删除一个文件
os.rename('oldname', 'newname')#重命名文件
import os
print(os.stat('ssss.py'))#获取文件/目录信息
import os
print(os.sep)#输出操作系统的分隔符,win为\,linux为/
print(os.pathsep)#输出用于分隔路径的字符串,win为;,linux为:
print(os.linesep)#输出当前平台使用的行终止符,win为\r\n,linux为\n
print(os.name)#输出字符串指示当前使用平台,win为'nt',linux为'posix'
print(os.environ)#获取系统环境变量
print(os.path.abspath('test_a'))#获取绝对路径
print(os.path.split(r'C:\Users\Administrator\PycharmProjects\python\day57\os_test.py'))#将路径分成目录和文件名,组成元组
print(os.path.dirname(r'C:\Users\Administrator\PycharmProjects\python\day57\os_test.py'))#取上面split的第一个值
print(os.path.basename(r'C:\Users\Administrator\PycharmProjects\python\day57\os_test.py'))#取上面split的第二个值
import os
print(os.path.exists('dirname1'))#判断path是否存在
print(os.path.isabs('test_a'))#判断是否是绝对路径
print(os.path.isdir('test_a'))#判断是否是目录
print(os.path.isfile('test_a'))#判断是否是文件
a = r'C:\Users\Administrator\PycharmProjects'
b = r'python\day57\os_test.py'
print(os.path.join(a, b))#路径拼接
import os
print(os.path.getatime('test_a'))#获取最后访问时间
print(os.path.getmtime('test_a'))#获取最后修改时间
四、sys模块
进度条
import sys
import time
for i in range(100):
sys.stdout.write('#')
time.sleep(3)
sys.stdout.flush()
五、Json模块
dic = {'name': 'cyx'}#json.dumps将单引号转为双引号,再在外面加字符串引号
i = 8#json.dumps直接在外面加字符串引号
s = 'hello'#json.dumps将单引号转为双引号,再在外面加字符串引号
l = [11, 22]#json.dumps直接在外面加字符串引号
dic_str = json.dumps(dic)#将数据转换为字符串类型
print(dic_str)
print(type(dic_str))
f = open('new_hello', 'w')
f.write(dic_str)
f_read = open('new_hello', 'r')
data = json.loads(f_read.read())
print(data)
print(type(data))
import json
f_read = open('new_hello', 'r')
data = json.load(f_read)#只能用于文件操作,局限性比较大
print(data)
print(type(data))
import json
dic = {'name': 'cyx'}
f = open('hello', 'w')
json.dump(dic, f)#
注意:json.loads不是一定要和json.dumps捆绑使用,只要字符串格式符合json字符串要求,json.loads即可对该字符串进行操作
六、pickle模块
import pickle
dic = {"name": "cyx", "gender": "male", "hobby": "reading"}
print(type(dic))
j = pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f = open("xuliehua", 'wb')#w写入的是字符串,wb写入的是字节,j是字节
f.write(j)#等价于pickle.dump(dic, f)
import pickle
f_read = open('xuliehua', 'rb')
data = pickle.loads(f_read.read()) #等价于data = pickle.load(f)
print(data["name"])
dumps叫做序列化
loads叫做反序列化
pickle和json的区别:
pickle支持的数据类型更多,支持函数、类,json不支持,但更常用的是json
七、shelve模块
import shelve
f = shelve.open(r'shelve')#f={}
# f['stu1_info'] = {"name": "cyx", "age": "21"}
# f['stu2_info'] = {"name": "ypp", "age": "19"}
# f['sch_info'] = {"name": "ob", "city": "sz"}
#
# f.close()
print(f.get('stu1_info')["age"])
八、xml模块
import xml.etree.ElementTree as ET
tree = ET.parse("xml_lesson")#parse解析后获得一个对象,赋值给tree
root = tree.getroot()#获取根节点
print(root.tag)#打印根节点标签名
#遍历
for i in root:
print(i.tag)
print(i.attrib)
for j in i:
print(j.tag)
print(j.attrib)
print(j.text)
#遍历year节点
for node in root.iter('year'):
print(node.tag, node.text)
#修改
for node in root.iter("year"):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated", "yes")
tree.write("abc.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write("bnm.xml")
#创建xml
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"})
age = ET.SubElement(name, "age", attrib={"checked": "no"})
sex = ET.SubElement(name, "sex")
sex.text = "33"
name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"})
age = ET.SubElement(name2, "age")
age.text = "19"
et = ET.ElementTree(new_xml)#生成文档对象
et.write("test.xml", encoding="utf-8", xml_declaration=True)
ET.dump(new_xml)#打印生成的格式
九、re模块:模糊匹配,面向字符串
元字符.:通配符,除了\n以外的所有字符都可以匹配上,一个.代表一个字符
import re
ret = re.findall('a..x', 'hjklsanmxljye')
print(ret)
import re
ret = re.findall('a..x', 'adsxhjklsanmxljye')
print(ret)
元字符^:以……开头
import re
ret = re.findall('^a..x', 'hjklsanmxljye')
print(ret)
元字符$:以……结尾
import re
ret = re.findall('a..x$', 'adsxhjklsanmxlayex')
print(ret)
import re
ret = re.findall('a..x$', 'adsxhjklsanmxlayex$')#$不能当做普通字符
print(ret)#输出为空
元字符*:按照紧挨着的字符重复,重复次数为0-无穷次,贪婪匹配,按多的来匹配
元字符+:按照紧挨着的字符重复,重复次数为1-无穷次,贪婪匹配 ,按多的来匹配
元字符?: 按照紧挨着的字符重复,重复次数为0-1,贪婪匹配 ,按多的来匹配
元字符{}: 按照紧挨着的字符重复,重复次数为自定义:{0, } == * {1, } == + {0, 1} == ?
import re
ret = re.findall('alex*', 'qwdrtalexxxx')
print(ret)
ret = re.findall('alex+', 'qwdrtalexxxx')
print(ret)
ret = re.findall('alex*', 'qwdrtale')
print(ret)
ret = re.findall('alex+', 'qwdrtale')
print(ret)
ret = re.findall('alex?', 'qwdrtalexxxx')
print(ret)
ret = re.findall('alex?', 'qwdrtale')
print(ret)
ret = re.findall('alex{6}', 'qwdrtalexxxxxx')
print(ret)
ret = re.findall('alex{0,6}', 'qwdrtalexx')
print(ret)
贪婪匹配变惰性匹配:加?
ret = re.findall('alex*?', 'qwdrtalexxxx')
print(ret)
元字符[]:字符集
功能1:起或的作用
ret = re.findall('x[yz]', 'xyuuuxzu')
print(ret)
ret = re.findall('x[yz]p', 'xypuuuxzpu')
print(ret)
ret = re.findall('x[y,z]p', 'xypux,puuxzpu')
print(ret)
ret = re.findall('www[oldboy baidu]', 'wwwbaidu')
print(ret)
ret = re.findall('x[yz]', 'xyuuuxzu')
print(ret)
ret = re.findall('x[yz]p', 'xypuuuxzpu')
print(ret)
ret = re.findall('x[y,z]p', 'xypux,puuxzpu')
print(ret)
ret = re.findall('www[oldboy baidu]', 'wwwbaidu')
print(ret)
ret = re.findall('q[a*z]', 'xypuxpuuxzpuq')#[]内无特殊符号,*就是普通符号*
print(ret)
ret = re.findall('q[a*z]', 'xypuxpuuxzpuqaa')#[]内无特殊符号,*就是普通符号*
print(ret)
ret = re.findall('q[a*z]', 'xypuxpuuxzpuq*')#[]内无特殊符号,*就是普通符号*
print(ret)
ret = re.findall('q[a-z]', 'quo')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[a-z]*', 'quo')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[a-z]*', 'quoghjk')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[a-z]*', 'quoghjk9')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[0-9]*', 'quoghjk9')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[0-9]*', 'q567uoghjk9')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[0-9]*', 'q567uoghjkq9')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[A-Z]*', 'q567uoghjkq9')#[]内无特殊符号,例外1:-代表范围
print(ret)
ret = re.findall('q[^a-z]', 'q214')#[]内无特殊符号,例外2:^代表非
print(ret)
ret = re.findall('q[^a-z]', 'qz')#[]内无特殊符号,例外2:^代表非
print(ret)
ret = re.findall('\([^()]*\)', '12+(34*6+2-5*(2-1))')#[]内无特殊符号,例外2:^代表非
print(ret)
ret = re.findall('\([^()]*\)', '12+(34*6+2-5*(2-1))')#[]内无特殊符号,例外2&#:^代表非 \代表转译
print(ret)
元字符:转义符\

ret = re.findall('\d', '12+(34*6+2-5*(2-1))')#[]内无特殊符号,例外2&#:^代表非 \代表转译
print(ret)
ret = re.findall('\d+', '12+(34*6+2-5*(2-1))')#[]内无特殊符号,例外2&#:^代表非 \代表转译
print(ret)
ret = re.findall('[0-9]+', '12+(34*6+2-5*(2-1))')#[]内无特殊符号,例外2&#:^代表非 \代表转译
print(ret)
ret = re.findall('\s+', 'hello world')
print(ret)
ret = re.findall('\w', 'hello world_')
print(ret)
ret = re.findall('www.baidu', 'www.baidu')
print(ret)
ret = re.findall('www.baidu', 'www/baidu')
print(ret)
ret = re.findall('www.baidu', 'wwwobaidu')
print(ret)
ret = re.findall('www.baidu', 'www\nbaidu')
print(ret)
ret = re.findall('www\.baidu', 'www/baidu')
print(ret)
ret = re.findall('www\.baidu', 'www.baidu')
print(ret)
ret = re.findall('www*baidu', 'www*baidu')
print(ret)
ret = re.findall('www\*baidu', 'www*baidu')
print(ret)
import re
ret = re.findall('I\b', 'hello I am LIST')#pyhton解释器调用re模块,拿到re.findall('I\b', 'hello I am LIST'),
读到\b时,因为\b在python中本身就有意义,所以直接将\b翻译成python中代表的转译内容,python翻译的\b传给re模块时,对re已经没有意义
实际需求是将\b给re,让re执行操作,解决方法有两种
方法一:r代表raw string原生字符串,只要加上r,字符串里的内容不做任何转义
print(ret)
ret = re.findall(r'I\b', 'hello I am LIST')
方法二:加\,python解释器先走\\,\本身有特殊意义,再加\会将其特殊意义去掉,两个\在一起代表一个普通的\,普通的\加b传入re,re可以认识
print(ret)
ret = re.findall('I\\b', 'hello I am LIST')
print(ret)
ret = re.findall('c\\\\l', 'abc\lerwt')#re中需要\\使\变成普通意义的\,才能找到c\l,python要想传到re里的是c\\l,必须接收c\\\\l
print(ret)
ret = re.findall(r'c\\l', 'abc\lerwt')
print(ret)
元字符:|或
ret = re.findall('ka|b', 'ckabsf')
print(ret)
ret = re.findall('ka|bc', 'sdjka|bsf')
print(ret)
元字符:()分组
ret = re.findall('(abc)+', 'abccccc')
print(ret)
import re
ret = re.findall('(abc)+', 'abcabcabcabc')#findall 优先取组里的内容,所以只输出'abc'
print(ret)
ret = re.findall('(?:abc)+', 'abcabcabcabc')#findall 优先取组里的内容,所以只输出'abc',?:可以取消优先级
print(ret)
ret = re.findall('abc+', 'abcabcabcabc')#findall
print(ret)
ret = re.findall('(?P<name>\w+)', 'abccccc')#有名分组
print(ret)
ret = re.search('(?P<name>\w+)', 'abccccc')#search 只要找到一个满足的,就不再往后找
print(ret)
ret = re.search('\d+', 'abc34ccc36c')#search 只要找到一个满足的,就不再往后找,返回值是一个对象
print(ret)
ret = re.search('\d{5}', 'abc34ccc36c')#search 只要找到一个满足的,就不再往后找,返回值也可能是None
print(ret)
ret = re.search('\d+', 'abc34ccc36c').group()#group取出结果
print(ret)
ret = re.search('(?P<name>[a-z]+)', 'cyx21ypp12yjj11').group()#group取出结果
print(ret)
ret = re.search('(?P<name>[a-z]+)\d+', 'cyx21ypp12yjj11').group("name")#group取出结果
print(ret)
ret = re.search('(?P<name>[a-z]+)(?P<age>\d+)', 'cyx21ypp12yjj11').group("age")#可以根据组名提取需要的内容
print(ret)
re模块下的方法
match
ret = re.match('\d+', 'cyx21ypp12yjj11')#match只会从开始匹配,返回值也是一个对象
print(ret)
ret = re.match('\d+', '56cyx21ypp12yjj11')#match只会从开始匹配,返回值也是一个对象
print(ret)
ret = re.match('\d+', '56cyx21ypp12yjj11').group()#match也可以用group取出结果
print(ret)
split
ret = re.split(" ", "hello abc|def")
print(ret)
ret = re.split("[ , |]", "hello abc|def")
print(ret)
ret = re.split(" |\|", "hello abc|def")
print(ret)
ret = re.split("[ab]", "asdabcd")#结果['', 'sd', '', 'cd']:a或者b左边或右边无内容时显示''
print(ret)
ret = re.split("[ab]", "abc")#结果['', '', 'c']:a或者b左边或右边无内容时显示''
print(ret)
sub & subn替换
ret = re.sub("\d+", "A", "abc122wer56")
print(ret)
ret = re.sub("\d", "A", "abc122wer56")
print(ret)
ret = re.sub("\d", "A", "abc122wer56", 4)
print(ret)
ret = re.subn("\d", "A", "abc122wer56")#显示匹配的结果和次数
print(ret)
compile编译
com = re.compile("\d+")#规则已经编译OK,和re.findall相比,compile只要编译一次即可,re.findall可能要编译多次
ret = com.findall("asdhj78nkld456")
print(ret)
finditer:把结果封装到迭代器内,返回的是一个迭代器对象
ret = re.finditer("\d", "abc122wer56")#处理大数据时可以省内存,因为结果存放在迭代器内,需要时再调到内存里
print(next(ret).group())
print(next(ret).group())
print(next(ret).group())
print(next(ret).group())
print(next(ret).group())
ret = re.findall('www\.(baidu|163)\.com', 'www.baidu.com')#优先匹配分组内的内容
print(ret)
ret = re.findall('www\.(?:baidu|163)\.com', 'www.baidu.com')#取消优先级
print(ret)
十、logging模块
logging.basicConfig
import logging
logging.basicConfig(
level=logging.DEBUG,
filename='logger.log',#只能在文件中显示,不能在屏幕上显示
filemode="w",
format='%(asctime)s %(filename)s [%(lineno)d] %(message)s'
)
#日志级别
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')

logger对象
def logger():#把logger封装在函数里
import logging
logger = logging.getLogger()#创建logger对象
fh = logging.FileHandler("test_log")#可以向文件发送日志内容
ch = logging.StreamHandler()#可以向屏幕发送日志内容
fm = logging.Formatter("%(asctime)s %(message)s")
fh.setFormatter(fm)
ch.setFormatter(fm)
logger.addHandler(fh)
logger.addHandler(ch)
logger.setLevel("DEBUG")
return logger
#调用logger
logger = logger()
logger.debug("debug")
logger.info("info")
logger.warning("warning")
logger.error("error")
logger.critical("critical")
注意点1:子对象的命名是惟一的,起名重复会对应同一个对象
import logging
logger1 = logging.getLogger('mylogger')#创建子用户,logger1和logger2对应的是同一个对象
logger1.setLevel(logging.DEBUG)
logger2 = logging.getLogger('mylogger')#logger1和logger2对应的是同一个对象
logger2.setLevel(logging.WARNING)#对象第二次级别被改为WARNING,是其最终级别
fh=logging.FileHandler("test_log-new")
ch=logging.StreamHandler()
logger1.addHandler(fh)
logger1.addHandler(ch)
logger2.addHandler(fh)
logger2.addHandler(ch)
logger1.debug('logger1 debug message')
logger1.info('logger1 info message')
logger1.warning('logger1 warning message')
logger1.error('logger1 error message')
logger1.critical('logger1 critical message')
logger2.debug('logger2 debug message')
logger2.info('logger2 info message')
logger2.warning('logger2 warning message')
logger2.error('logger2 error message')
logger2.critical('logger2 critical message')
注意点2:子对象打印时,上面有几个父对象在工作,就多打印几次
import logging
logger = logging.getLogger()#创建根用户,logger和logger1是父子关系,名字默认是root,没设定等级默认是warning
logger1 = logging.getLogger('mylogger')
logger1.setLevel(logging.DEBUG)
fh=logging.FileHandler("test_log-new")
ch=logging.StreamHandler()
logger.addHandler(fh)
logger.addHandler(ch)
logger1.addHandler(fh)
logger1.addHandler(ch)
logger1.debug('logger1 debug message')
logger1.info('logger1 info message')
logger1.warning('logger1 warning message')
logger1.error('logger1 error message')
logger1.critical('logger1 critical message')
logger1.debug('logger1 debug message')#子打印时,上面有几个父级在工作,就多打印几次
logger1.info('logger1 info message')
logger1.warning('logger1 warning message')
logger1.error('logger1 error message')
logger1.critical('logger1 critical message')
如何解决子对象多打印的问题:让父对象停止工作
import logging
logger = logging.getLogger()#创建根用户,logger和logger1是父子关系,名字默认是root,没设定等级默认是warning
logger1 = logging.getLogger('mylogger')
logger1.setLevel(logging.DEBUG)
fh=logging.FileHandler("test_log-new")
ch=logging.StreamHandler()
# logger.addHandler(fh)
# logger.addHandler(ch)
logger1.addHandler(fh)
logger1.addHandler(ch)
# logger1.debug('logger1 debug message')
# logger1.info('logger1 info message')
# logger1.warning('logger1 warning message')
# logger1.error('logger1 error message')
# logger1.critical('logger1 critical message')
logger1.debug('logger1 debug message')#子打印时,上面有几个父级,就多打印几次
logger1.info('logger1 info message')
logger1.warning('logger1 warning message')
logger1.error('logger1 error message')
logger1.critical('logger1 critical message')
十一、configparser模块:配置文件的解析模块
#创建配置文件
import configparser
#类字典操作,增加内容方法一
config = configparser.ConfigParser() #得到一个空字典config= {}
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
#类字典操作,增加内容方法二
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
#类字典操作,增加内容方法三
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022'
topsecret['ForwardX11'] = 'no'
with open('example.ini', 'w') as f:
config.write(f)#正常是f.write,这里是不同之处
查看内容:
import configparser
config = configparser.ConfigParser()
print(config.sections())#结果为空
config.read("example.ini")
print(config.sections())#[DEFAULT]不打印
print('bytebong.com' in config)
print(config['bitbucket.org']['User'])#取值时键不区分大小写
for key in config['topsecret.server.com']:#当遍历任何其他信息时,DEFAULT下的内容会同时出现,不想DEFAULT的内容出现,就要改DEFAULT的命名
print(key)
print(config.options('topsecret.server.com'))#取出所有的键放入列表中
print(config.items('topsecret.server.com'))#键值组成元组放入列表,将config理解成一个字典
print(config.get('topsecret.server.com', 'compressionlevel'))#连续取值,和字典的get不太一样
删、改 、增
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('cyx')#增加一个section
config.set('cyx', 'age', '18')#给section加键值对
config.remove_section('topsecret.server.com')#整体删除块
config.remove_option('bitbucket.org', 'user')#删除键值对
config.write(open('i.cfg', 'w'))#不需要进行f.close
十二、hashlib模块:摘要算法 将不定长的字符串转换成定长的密文
应用场景:京东、淘宝等服务器储存用户名密码是会用到,相对安全,黑客盗取后也无法使用
用户 登录验证前会对用户输入的密码进行加密后验证
只能把明文变成密文,密文回不到明文,不同于加密(明文变成密文,密文也可以变为明文)
import hashlib
obj = hashlib.md5()
obj.update('hello'.encode('utf8'))#5d41402abc4b2a76b9719d911017c592 将不定长的字符串转换成定长的密文
print(obj.hexdigest())
因原生的md5算法所有人都知道明文密文的对应关系 ,容易被破解,需要加严
import hashlib
obj = hashlib.md5('ypp'.encode('utf8'))#加严加密,加上自定义的字符串
obj.update('hello'.encode('utf8'))#6924fd2e3e7fd50e717eca1420cb03bd 将不定长的字符串转换成定长的密文
print(obj.hexdigest())
算法越复杂花费的时间越长(消耗效率),所以不是说越复杂的算法越好
更常用的方法是sha256算法,用法同md算法
import hashlib
obj = hashlib.md5()
obj.update('admin'.encode('utf8'))
obj.update('root'.encode('utf8'))#结果4b3626865dc6d5cfe1c60b855e68634a→此两步等同于obj.update('adminroot'.encode('utf8'))
print(obj.hexdigest())
