


一、实验要求
按要求完成题目,在实验报告中应有代码和运行截图以及心得体会
二、实验题目
构造机器学习模型,预测泰坦尼克号上乘客是否可以存活
数据字段说https://www.kaggle.com/competitions/titanic/data?select=train.csv
具体要求:
1 读取titanic.csv数据集
2对数据进行预处理,主要对缺失值进行处理
3对数据进行探索,使用数据可视化的方式查看不同特征对最后是否存活的影响
4对数据进行转换,主要对离散值进行编码
5将数据集分为训练集和测试集两部分,测试集比例30%
6使用上课讲过的至少两种分类算法训练机器学习模型,并用测试集对训练的模型性能进行评估
三、实验代码与运行结果:
1 import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df=open(r'D:\数据分析\titanic.csv')
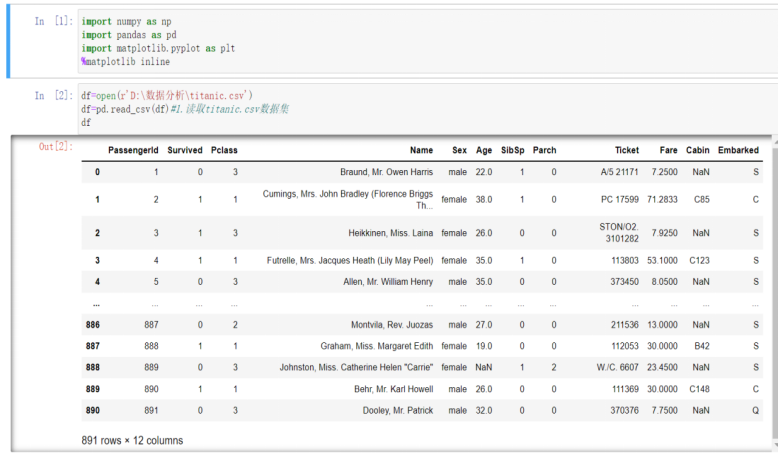
df=pd.read_csv(df)
df #读取titanic.csv数据集
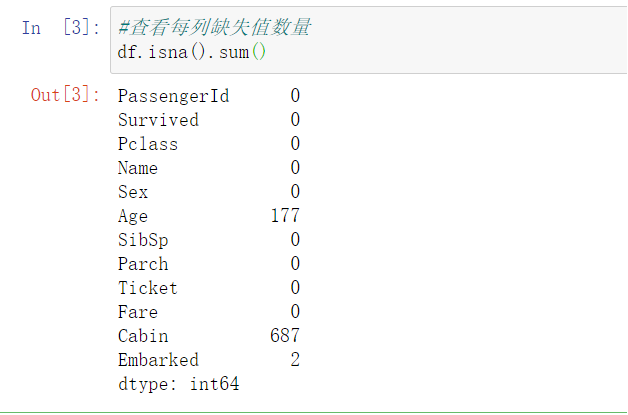
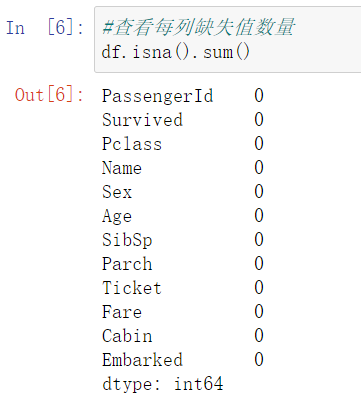
#查看每列缺失值
df.isna().sum()
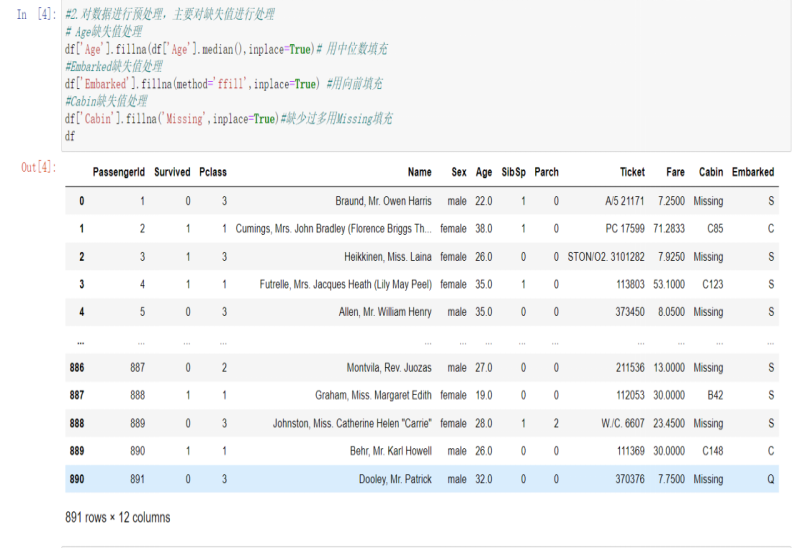
2#对数据进行预处理,主要对缺失值进行处理
# Age缺失值处理
df['Age'].fillna(df['Age'].median(),inplace=True)# 用中位数填充
#Embarked缺失值处理
df['Embarked'].fillna(method='ffill',inplace=True) #用向前填充
#Cabin缺失值处理
df['Cabin'].fillna('Missing',inplace=True)#缺少过多用Missing填充
df
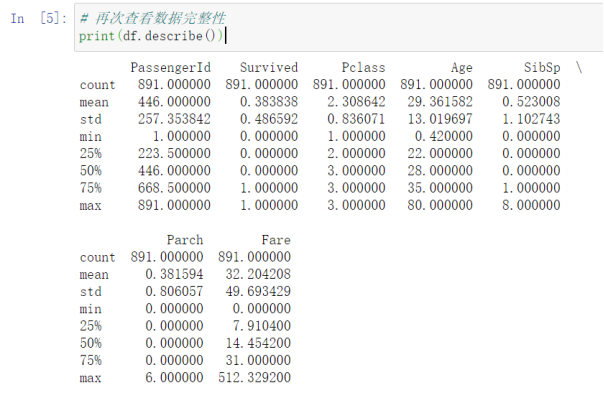
# 再次查看数据完整性
print(df.describe())
#再次查看每列缺失值数量
df.isnull().sum()
3 #对数据进行探索,使用数据可视化的方式查看不同特征对最后是否存活的影响
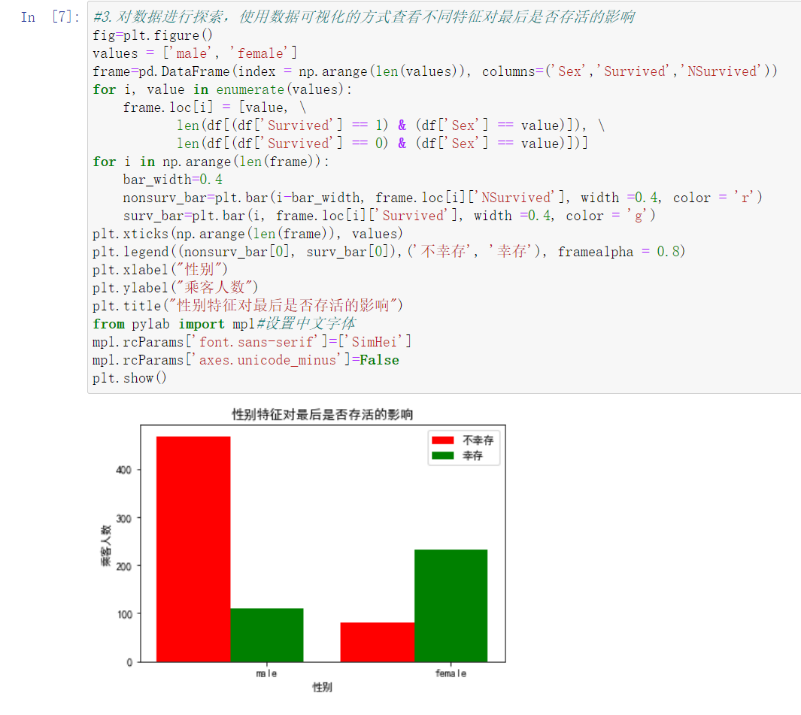
3.1性别特征对最后是否存活的影响
fig=plt.figure()
values = ['male', 'female']
frame=pd.DataFrame(index=np.arange(len(values)),
columns=('Sex','Survived','NSurvived'))
for i, value in enumerate(values):
frame.loc[i] = [value, \
len(df[(df['Survived'] == 1) & (df['Sex'] == value)]), \
len(df[(df['Survived'] == 0) & (df['Sex'] == value)])]
for i in np.arange(len(frame)):
bar_width=0.4
nonsurv_bar=plt.bar(i-bar_width, frame.loc[i]['NSurvived'], width =0.4, color = 'r')
surv_bar=plt.bar(i, frame.loc[i]['Survived'], width =0.4, color = 'g')
plt.xticks(np.arange(len(frame)), values)
plt.legend((nonsurv_bar[0], surv_bar[0]),('不幸存', '幸存'), framealpha = 0.8)
plt.xlabel("性别")
plt.ylabel("乘客人数")
plt.title("性别特征对最后是否存活的影响")
from pylab import mpl#设置中文字体
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
plt.show()
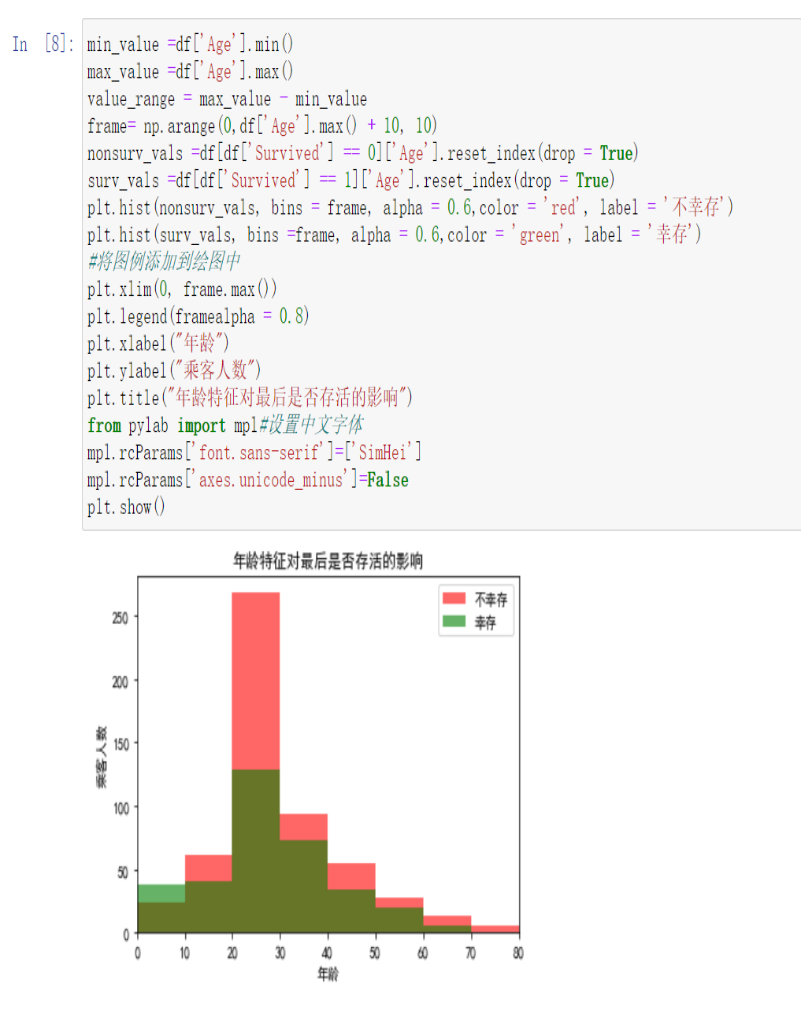
3.2年龄特征对最后是否存活的影响
min_value =df['Age'].min()
max_value =df['Age'].max()
value_range = max_value - min_value
frame= np.arange(0,df['Age'].max() + 10, 10)
nonsurv_vals =df[df['Survived'] == 0]['Age'].reset_index(drop = True)
surv_vals =df[df['Survived'] == 1]['Age'].reset_index(drop = True)
plt.hist(nonsurv_vals, bins = frame, alpha = 0.6,color = 'red', label = '不幸存')
plt.hist(surv_vals, bins =frame, alpha = 0.6,color = 'green', label = '幸存')
#将图例添加到绘图中
plt.xlim(0, frame.max())
plt.legend(framealpha = 0.8)
plt.xlabel("年龄")
plt.ylabel("乘客人数")
plt.title("年龄特征对最后是否存活的影响")
from pylab import mpl#设置中文字体
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
plt.show()
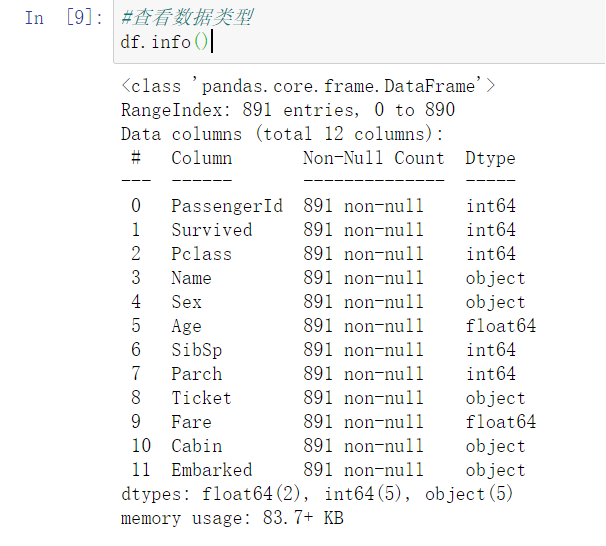
#查看数据类型
df.info()
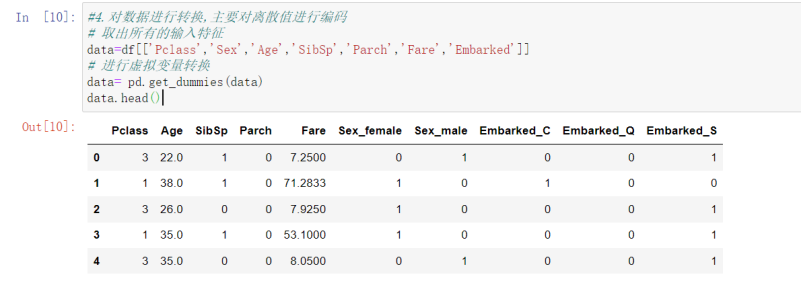
4 #对数据进行转换,主要对离散值进行编码
# 取出所有的输入特征
data=df[['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']]
# 进行虚拟变量转换
data= pd.get_dummies(data)
data.head()
5.#将数据集分为训练集和测试集两部分,测试集比例30%
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import pandas as pd
X=data
Y=df['Survived']
X_train,X_test,Y_train,Y_test=
train_test_split(X,Y,test_size=0.3,random_state=0) #构造训练集和测试集
X_train
X_test
6 使用上课讲过的至少两种分类算法训练机器学习模型,并用测试集对训练的模型性能进行评估
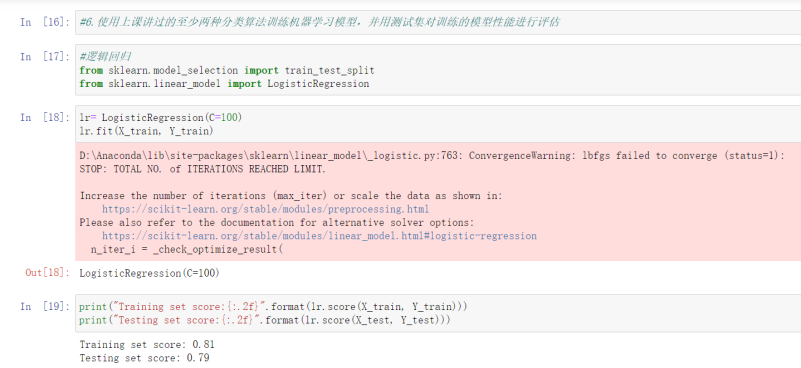
6.1 #逻辑回归
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
lr= LogisticRegression(C=100)
lr.fit(X_train, Y_train)
print("Training set score:{:.2f}".format(lr.score(X_train, Y_train)))
print("Testing set score:{:.2f}".format(lr.score(X_test, Y_test)))
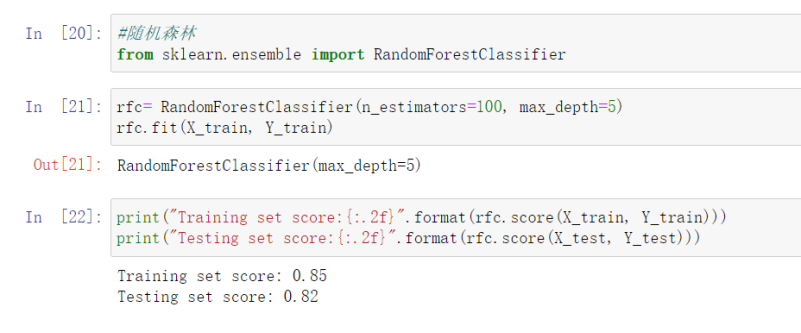
6.2 #随机森林
from sklearn.ensemble import RandomForestClassifier
rfc= RandomForestClassifier(n_estimators=100, max_depth=5)
rfc.fit(X_train, Y_train)
print("Training set score:{:.2f}".format(rfc.score(X_train, Y_train)))
print("Testing set score:{:.2f}".format(rfc.score(X_test, Y_test)))
本文来自博客园,作者:一路向北~~,转载请注明原文链接:https://www.cnblogs.com/ylxb2539989915/p/16339020.html

