


一、实验要求
按要求完成题目,在实验报告中应有代码和运行截图以及心得体会
二、实验题目
- 读取群文件“数据分析实验一”中的”us-state.csv”,加载为dataframe,要求读取state列作为行索引
- 选择出所有面积大于100000的州的数据
- 获取Arkansas,Texas,California三个州的数据
- 获取[5,10]行数据
- 将DataFrame中数据按照行索引升序排序
- 将DataFrame中数据按照州面积降序排序
- 计算最大面积州与最小面积州的差值
- 计算平均面积
- 删除DataFrame中的州简写(abbreviation)那一列
- 将Florida州的面积修改为你的学号
- 将修改后的DataFrame写入excel文件中,文件名为“你的名字.xlsx”,如“张三.xlsx”,excel文件中保留行索引,不保留列索引
三、实验代码与运行结果:
1 import pandas as pd
df=open(r'D:\数据分析\us-state.csv')
df=pd.read_csv(df,index_col='state',names=None)
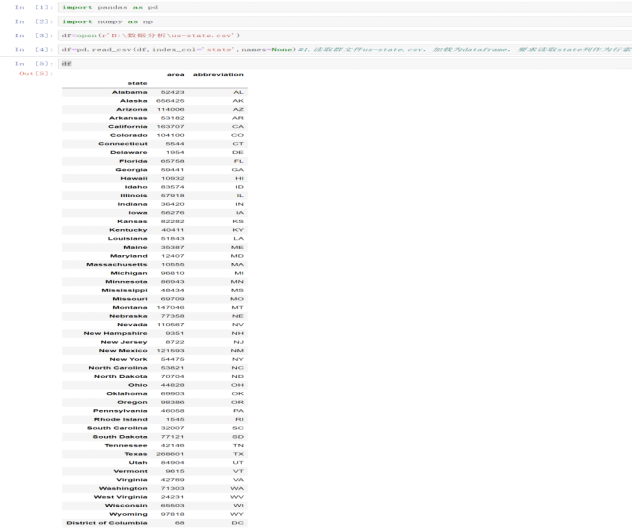
df #读取群文件“数据分析实验一”中的”us-state.csv”,加载为dataframe,要求读取state列作为行索引
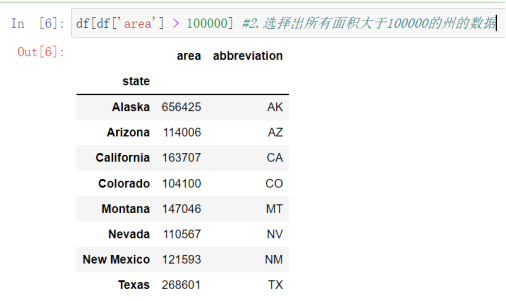
2 df[df['area'] > 100000]#选择出所有面积大于100000的州的数据
3 df.loc[['Alaska','Texas','California'],:] #获取Arkansas,Texas,California三个州的数据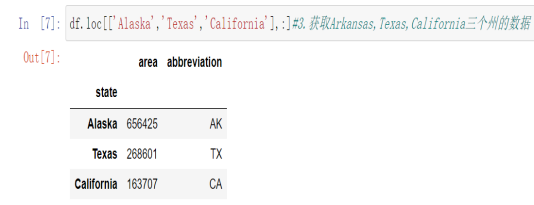
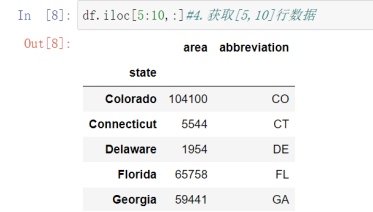
4 df.iloc[5:10,:] #获取[5,10]行数据
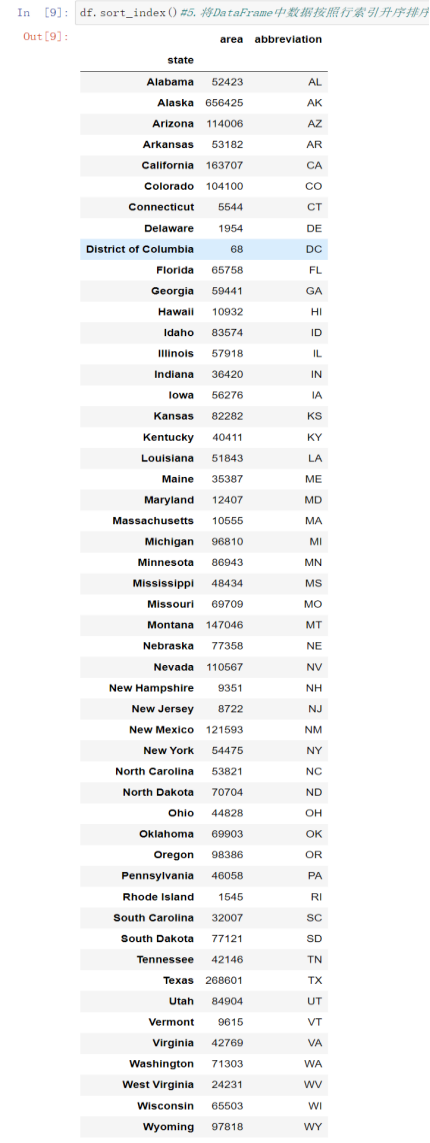
5 df.sort_index() #将DataFrame中数据按照行索引升序排序
6 df.sort_values('area',ascending=False)#将DataFrame中数据按照州面积降序排序

7 df_obj=(df['area'].max()-df['area'].min())
df_obj #计算最大面积州与最小面积州的差值
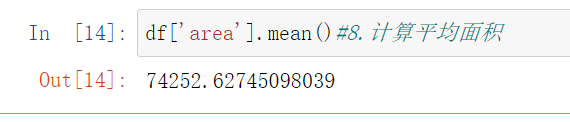
8 df['area'].mean() #计算平均面积
9 df.drop('abbreviation',axis=1,inplace=True)
df #删除DataFrame中的州简写(abbreviation)那一列

10 df.iloc[8]='xxxxxxxx'
df #将Florida州的面积修改为你的学号
(截图请自己实现)
11 df.to_excel(r'D:\数据分析\你的名字.xlsx',index=True,columns=None)
#将修改后的DataFrame写入excel文件中,文件名为“你的名字.xlsx”,如“张三.xlsx”,excel文件中保留行索引,不保留列索引
(截图请自己实现)
本文来自博客园,作者:一路向北~~,转载请注明原文链接:https://www.cnblogs.com/ylxb2539989915/p/16338667.html

