本期内容 :
- ReceivedBlockTracker容错安全性
- DStreamGraph和JobGenerator容错安全性
Driver的安全性主要从Spark Streaming自己运行机制的角度考虑的,如对源数据保存方面使用了WAL方式,驱动层面的容错安全主要使用的是CheckPoint ,
但是仅仅是WAL和CheckPoint在生成环境下不是完全足够的。
Spark Streaming 的Driver容错为什么是这两个方面 :
1、 ReceiverBlockTracker主要管理整个Spark Streaming的运行数据的源数据的,从容错的角度讲,源数据是否很重要,否则出错的话数据都不正常何谈其它呢
2、 DStream和JobGenerator 这个是框架的核心层面,具体调度到什么层面了,这是从业务与运行的角度考虑的
Driver哪些需要维持状态的:
1、 ReceiverBlockTracker跟踪数据毫无疑问是需要维持状态,所以就需要容错
2、 DStreams表达了依赖关系,在其恢复的时候需要恢复计算逻辑级别的依赖关系
3、 JobGenerator 表明你正在基于ReceiverBlockTracker的数据及DStreams构成的依赖关系产生Job的过程,消费了哪些数据、进行到什么程度等状态部分
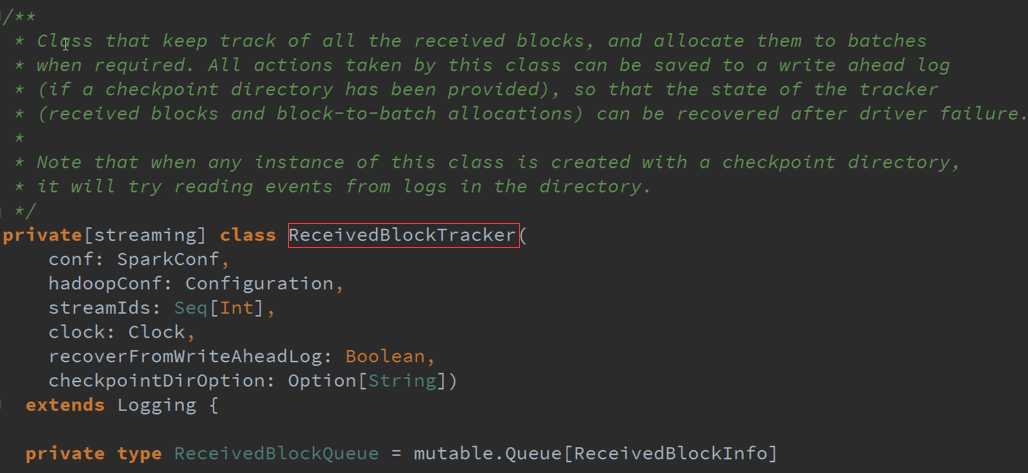
ReceiverBlockTracker :管理SparkStreaming的运行过程中指针指向的数据,一般都是在Executor上面的,并且把数据分配给每个Batches
Receiver接收到数据后是怎么处理的 :
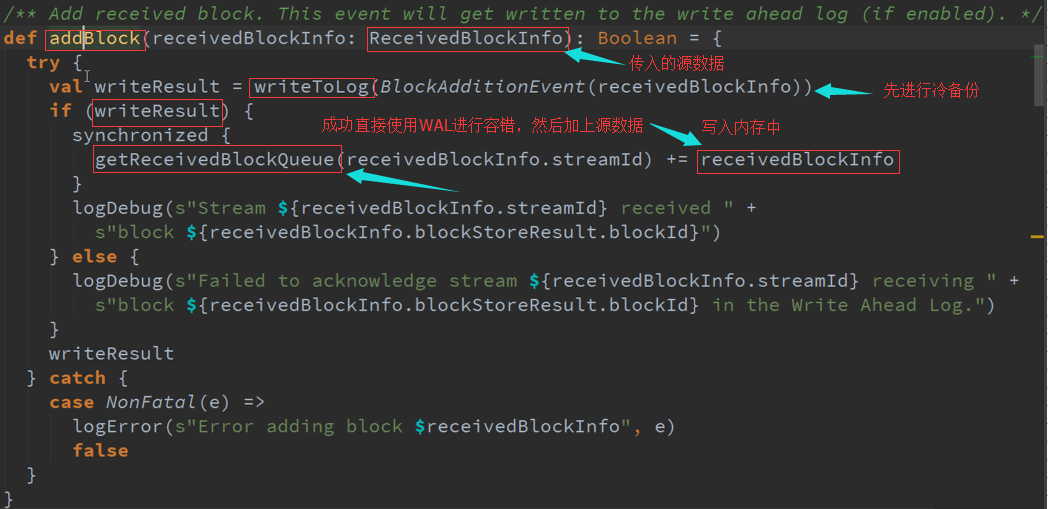
1、先进行WAL(冷备份),然才会写入内存中,整个Spark Streaming作业中的调度或者Generator是基于GetReceivedBlockQueue中的数据,来观察每个Streaming接收到的数据
2、 放入内存中是被当前运行的Spark Streaming的调度器JobGenerator去使用的,JobGenerator不可能直接使用WAL,WAL是一个磁盘的存储架结构,而是使用内存的缓存数据结构。
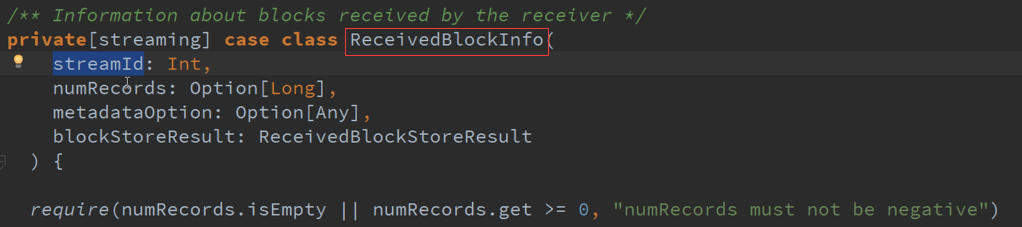


Spark Streaming是以窗口为作业划分标志,如频率以10S,在10S时间段接收到的所有数据保存在StreamIdToUnallocatedBlockQueues数据结构中,当计算时需要把,
所有的数据提取出来 ,最后就变成StreamIDToBlocks ,Spark Streaming处理中可以有不同的数据来源同时进行处理 。
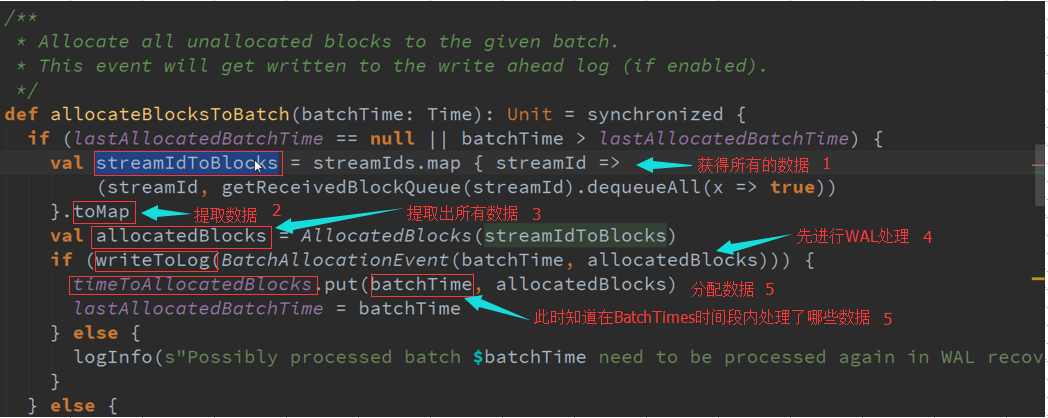
最终可以在AllocatedBlock 中获取数据,他有很多时间窗口的Blocks,Window操作或者状态操作都需要依赖这些信息,如果需要10分钟期间数据,根据数据结构把这些Bachelor集合起来就行了 。
随着时间的推移,会不断的产生数据,同时也不可能一直保持数据不变,需要对旧有的数据进行清理:
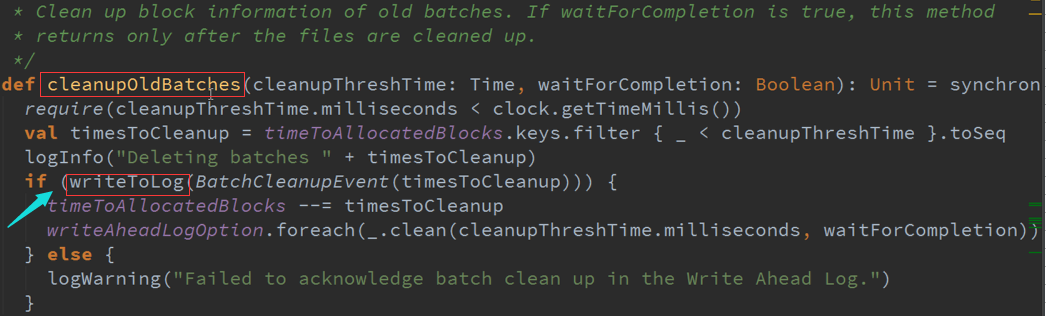
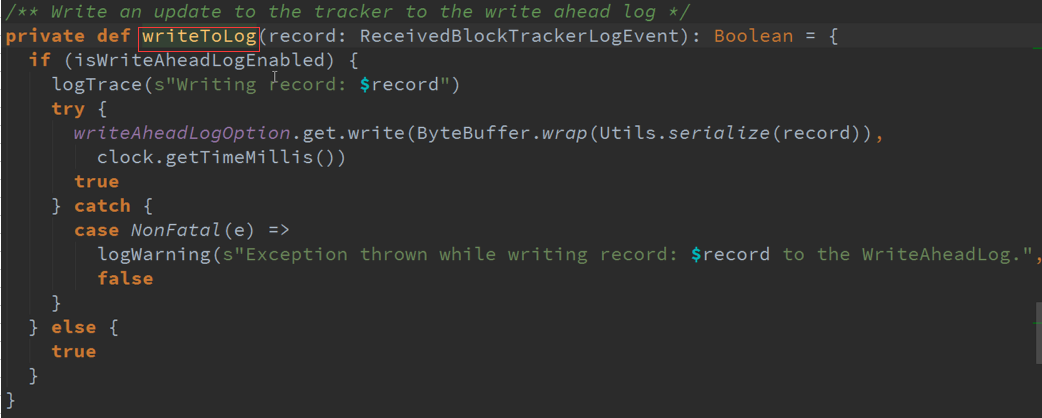
CheckPoint : Job开始进行一次CheckPoint,Job结束后也来一次CheckPoint

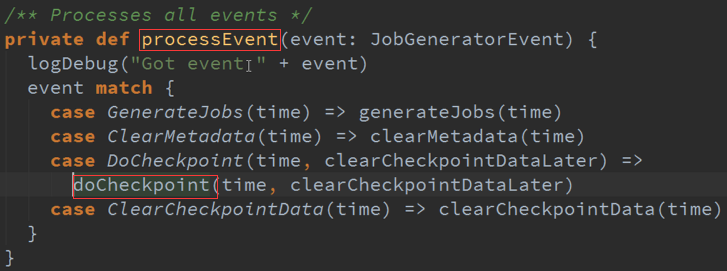

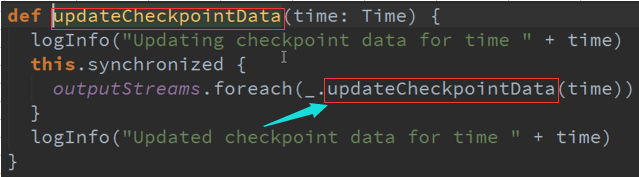
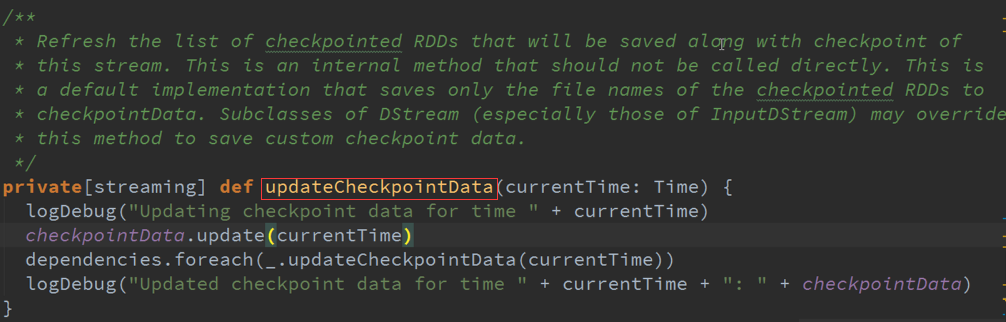
UpdateCheckPoint :
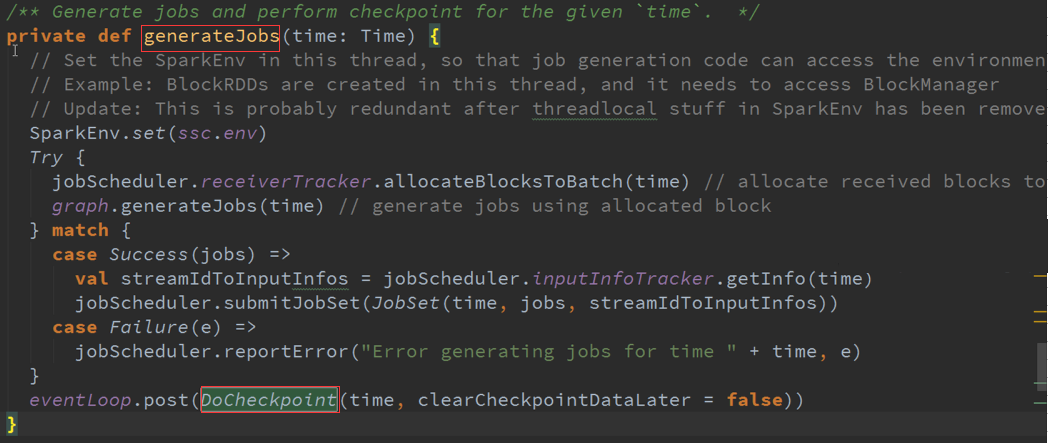
GenerateJobs :
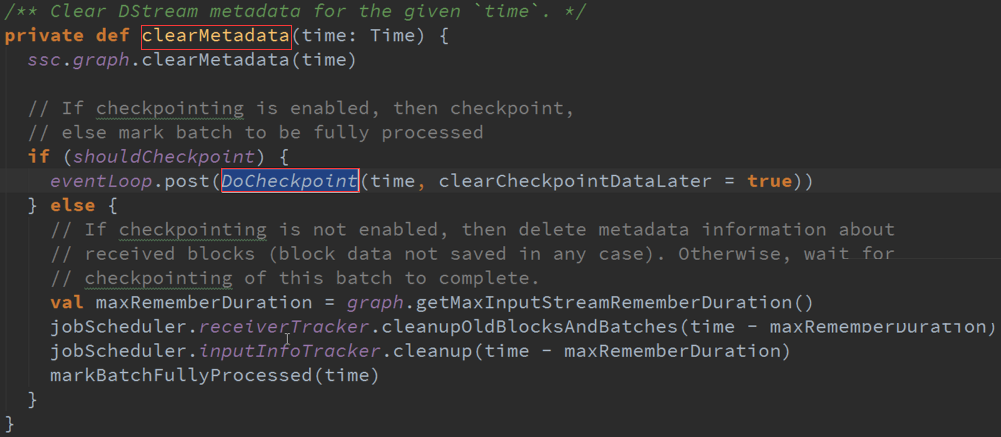
ClearMetadata :