本期内容 :
- Spark Streaming Job生成深度思考
- Spark Streaming Job生成源码解析
Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JOB由于它是基于Spark Core所以Spark Streaming对其进行了封装。
大数据开发应用中少不了定时任务,是否相当于流式处理,只是期间的时间间隔的不同而已,所以数据都可以认为是流式处理。
一、 JobGenerator 作业动态生成的一个类 :
JobGenerator是个普通的类,作业调度的核心是提交作业、作业生成的方方面面、生成后的Job提交到集群都是由JobSchedule决定的,
这个类JobGenerator是基于 DStreams生成Jobs ,基于Spark Streaming编程时都会产生一系列的DStreams 。
DStreams有三种类型 :
1、 输入的DStreams,可以有各种不同的数据来源来构建
2、 输出的DStreams是一种逻辑级别的 ,它是Spark Streaming框架级别的,它的底层会翻译成为物理级别的Action,即RDD的Action;
3、 中间是业务逻辑的转换过程,及状态转换;
JobGenerator类源码 :

二、 Spark Streams是基于时间为触发器的 :
大数据开发应用中少不了定时任务,是否相当于流式处理,只是期间的时间间隔的不同,所有的数据都会成为流式处理,都基于Times为基准。
无论是时间还是事件都统一为一种抽象的统一标准;
DStreams 的Action也是逻辑级别的操作,Spark Streams会产生一个逻辑级别的Job ,但是它不会运行,而是由底层物理级别的RDD Action去触发的。
Job的这种特性让你有机会对其进行各种调度与优化。
基于时间窗口, 每5秒钟都会产生一个Job :

当把DStreams Action逻辑级别翻译成物理级别的最后一个的RDD的Action时,就会立即触发Job执行,如果直接就执行了Job,那就不存在队列 ,源数据也就不受管理了。既要完成翻译也要进行管理,所以把DStreams的依赖关系变成RDD间的依赖关系,最后一个RDD Action的操作翻译成最后一个Action级别的操作,这个翻译后的内容它是放在方法体内。因只是定义还没有执行,所以它里面的Action不会执行触发Job。当我们的JobGenerator 看见要调度的这个Job时再转过来在线程池中拿出一条线程执行刚才的封装的方法。
1、 JobGenerator基于时间运行源码 :

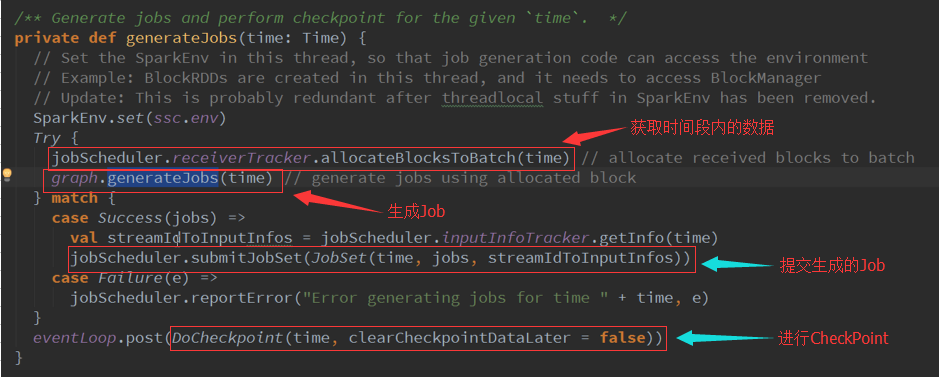
2、 使用方法进行封装,内部的方法不应该直接去调用,这个方法会基于我们的DStreams(逻辑级别)的操作物化成RDD(物理级别),GenerateJob源码:

3、 基于时间生成后会缓存起来 :

4、 GenerateJob : 生成RDD的实例,RDD的DAG依赖关系: