1.常规索引优化方式
1.1.单表优化
# 查询category_id为1且comments大于1的情况下,views最多的article id SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1; EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1; # 单表优化--建立对应索引 优化方案:cv建立索引 create index idx_article_cv on article(category_id,views);
总结:mysql索引是遵从B树索引原则,当建立ccv索引时,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments则再排序
views。而如果处于联合索引中间位置的字段comments > 1是一个范围值(range),则无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的
索引会失效。
这种情况建立cv索引最好。
1.2.两表优化
EXPLAIN SELECT b.bookid,c.card FROM book b LEFT JOIN class c ON b.card = c.card; # 优化方案:两表连接,左连接索引建立在右表,右连接索引建立在左表;或者查询对调位置 create index idx_class_card on class(card);
总结:两表连接,左连接索引建立在右表,右连接索引建立在左表;或者查询对调位置。
且注意小表驱动大表。
1.3.三表优化
# 针对连接的第三张表phone再在右表phone上建立一个索引 create index idx_class_card on class(card); create index idx_phone_card on phone(card); EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;
总结:三表连接,左连接索引建立在右表连接字段上,右连接建立在左表连接字段上;且注意小表驱动大表;如上,LEFT JOIN都建立在右表连接字段上。
三表连接,建立了两个表的索引。
2.索引失效
2.1.索引失效七字诀
模:模糊查询,like 如果以%开头,索引会失效;
型:数据类型,如果数据类型错误了,索引会失效;
数:函数,对索引字段使用内部函数,索引会失效,应该建立基于函数的索引;
空:null,索引不存储空值,如果不限制索引列是not null,数据库会认为索引列可能存在空值,也不会按照索引进行计算;
运:运算,对索引列进行加减乘除等运算会导致索引失效;
最:最左原则的意思,在复合索引中,索引列的顺序非常重要,如果不是按照索引列最左列开始进行查找,则无法使用索引;
快:全表扫描更快的意思,如果数据库预计使用全表扫描比使用索引更快,那就不会使用索引
2.2.硅谷十句诀
硅谷十句诀:
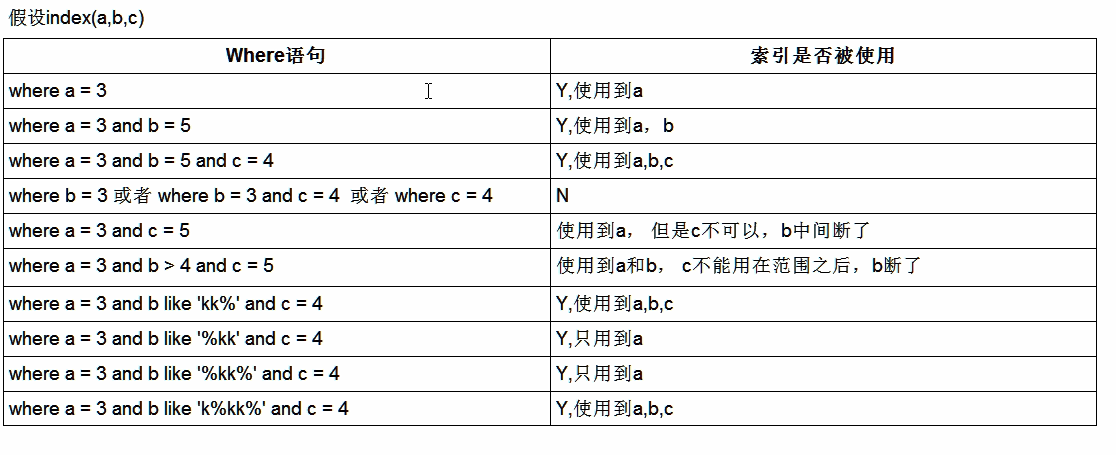
1.全值匹配我最爱:建立的索引个数和顺序与查询的字段个数和顺序完全一致。
2.最佳左前缀法则:如果索引包含多列(复合索引),需要遵守最左前缀法则,指的是查询从索引最左前列开始并且不跳过索引中的列。
所谓:“带头大哥不能死,中间兄弟不能断”

3.不要在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4.存储引擎不能使用索引中范围条件右边的列,即范围之后全失效

5.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*

6.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
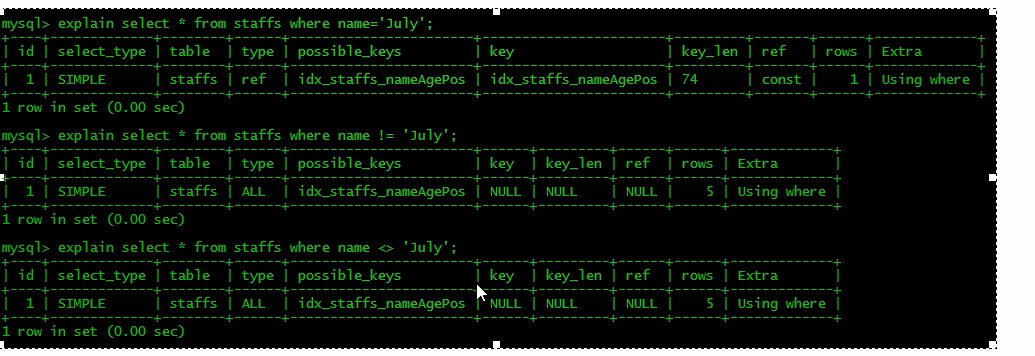
7.is null ,is not null 也无法使用索引
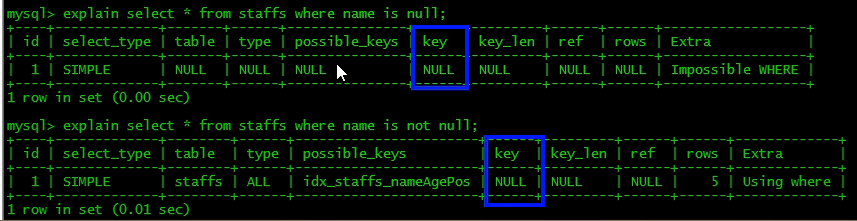
8.like以通配符开头('%ab...)mysq|索引失效会变成全表扫描的操作
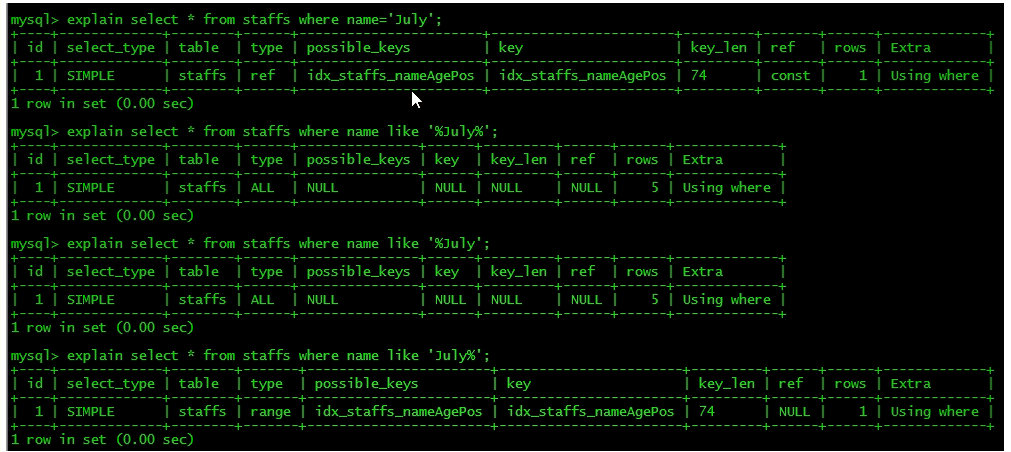
可以使用覆盖索引解决like %char% 不走索引的问题
9.字符串不加单引号会导致索引失效

10.少用or.用它来连接时令索引失效
小总结(判断索引是否被使用):