
本文主要记录了C/C++预处理指令,常见的预处理指令如下:
- #空指令,无任何效果
- #include包含一个源代码文件
- #define定义宏
- #undef取消已定义的宏
- #if如果给定条件为真,则编译下面代码
- #ifdef如果宏已经定义,则编译下面代码
- #ifndef如果宏没有定义,则编译下面代码
- #elif如果前面的#if给定条件不为真,当前条件为真,则编译下面代码
- #endif结束一个#if……#else条件编译块
- #error停止编译并显示错误信息
本来只是想了解一下#ifdef,#ifndef,#endif的,没想到查出来这么多的预处理指令,上面的多数都是常见的,但是平时没有怎么注意预处理这方面的内容,所以这里梳理一下知识吧。同时有什么不妥的地方,或者遗漏了什么内容,还请留言指出。
什么是预处理指令?
预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。
以前没有在意的学者注意了,预处理指令是在编译器进行编译之前进行的操作.预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。在很多编程语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码(防止重复包含某些文件)。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。
#include包含一个源代码文件
这个预处理指令,我想是见得最多的一个,简单说一下,第一种方法是用尖括号把头文件括起来。这种格式告诉预处理程序在编译器自带的或外部库的头文件中搜索被包含的头文件。第二种方法是用双引号把头文件括起来。这种格式告诉预处理程序在当前被编译的应用程序的源代码文件中搜索被包含的头文件,如果找不到,再搜索编译器自带的头文件。采用两种不同包含格式的理由在于,编译器是安装在公共子目录下的,而被编译的应用程序是在它们自己的私有子目录下的。一个应用程序既包含编译器提供的公共头文件,也包含自定义的私有头文件。采用两种不同的包含格式使得编译器能够在很多头文件中区别出一组公共的头文件。
#define定义宏
有关#define这个宏定义,在C语言中使用的很多,因为#define存在一些不足,C++强调使用const来定义常量。宏定义了一个代表特定内容的标识符。预处理过程会把源代码中出现的宏标识符替换成宏定义时的值。记住仅仅是进行标识符的替换。下面列举一些#define的使用:
用#define实现求最大值和最小值的宏
1 #include <stdio.h>
2 #define MAX(x,y) (((x)>(y))?(x):(y))
3 #define MIN(x,y) (((x)<(y))?(x):(y))
4 int main(void)
5 {
6 #ifdef MAX //判断这个宏是否被定义
7 printf("3 and 5 the max is:%d\n",MAX(3,5));
8 #endif
9 #ifdef MIN
10 printf("3 and 5 the min is:%d\n",MIN(3,5));
11 #endif
12 return 0;
13 }
14
15 /*
16 * (1)三元运算符要比if,else效率高
17 * (2)宏的使用一定要细心,需要把参数小心的用括号括起来,
18 * 因为宏只是简单的文本替换,不注意,容易引起歧义错误。
19 */
宏定义的错误使用
1 #include <stdio.h>
2 #define SQR(x) (x*x)
3 int main(void)
4 {
5 int b=3;
6 #ifdef SQR//只需要宏名就可以了,不需要参数,有参数的话会警告
7 printf("a = %d\n",SQR(b+2));
8 #endif
9 return 0;
10 }
11
12 /*
13 *首先说明,这个宏的定义是错误的。并没有实现程序中的B+2的平方
14 * 预处理的时候,替换成如下的结果:b+2*b+2
15 * 正确的宏定义应该是:#define SQR(x) ((x)*(x))
16 * 所以,尽量使用小括号,将参数括起来。
17 */
宏参数的连接
1 #include <stdio.h>
2 #define STR(s) #s
3 #define CONS(a,b) (int)(a##e##b)
4 int main(void)
5 {
6 #ifdef STR
7 printf(STR(VCK));
8 #endif
9 #ifdef CONS
10 printf("\n%d\n",CONS(2,3));
11 #endif
12 return 0;
13 }
14
15 /* (绝大多数是使用不到这些的,使用到的话,查看手册就可以了)
16 * 第一个宏,用#把参数转化为一个字符串
17 * 第二个宏,用##把2个宏参数粘合在一起,及aeb,2e3也就是2000
18 */
用宏得到一个字的高位或低位的字节
1 #include <stdio.h>
2 #define WORD_LO(xxx) ((byte)((word)(xxx) & 255))
3 #define WORD_HI(xxx) ((byte)((word)(xxx) >> 8))
4 int main(void)
5 {
6 return 0;
7 }
8
9 /*
10 * 一个字2个字节,获得低字节(低8位),与255(0000,0000,1111,1111)按位相与
11 * 获得高字节(高8位),右移8位即可。
12 */
用宏定义得到一个数组所含元素的个数
1 #include <stdio.h>
2 #define ARR_SIZE(a) (sizeof((a))/sizeof((a[0])))
3 int main(void)
4 {
5 int array[100];
6 #ifdef ARR_SIZE
7 printf("array has %d items.\n",ARR_SIZE(array));
8 #endif
9 return 0;
10 }
11 /*
12 *总的大小除以每个类型的大小
13 */
关于#define宏的使用,应该特别小心,尤其是含有参数计算的时候如小2示例,最保险的做法将参数用括号括起来。
#ifdef,#ifndef,#endif...的使用
以上这些预编译指令,都是条件编译指令,也就是说,将决定那些代码被编译,而哪些不被编译。
示例1:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #define DEBUG
4 int main(void)
5 {
6 int i = 0;
7 char c;
8 while(1)
9 {
10 i++;
11 c = getchar();
12 if('\n' != c)
13 {
14 getchar();
15 }
16 if('q' == c || 'Q' == c)
17 {
18 #ifdef DEBUG//判断DEBUG是否被定义了
19 printf("We get:%c,about to exit.\n",c);
20 #endif
21 break;
22 }
23 else
24 {
25 printf("i = %d",i);
26 #ifdef DEBUG
27 printf(",we get:%c",c);
28 #endif
29 printf("\n");
30 }
31 }
32 printf("Hello World!\n");
33 return 0;
34 }
35
36 /*#endif用于终止#if预处理指令。*/
#ifdef 和 #ifndef
1 #include <stdio.h>
2 #define DEBUG
3 main()
4 {
5 #ifdef DEBUG
6 printf("yes ");
7 #endif
8 #ifndef DEBUG
9 printf("no ");
10 #endif
11 }
12 //#ifdefined等价于#ifdef;
13 //#if!defined等价于#ifndef
#else指令
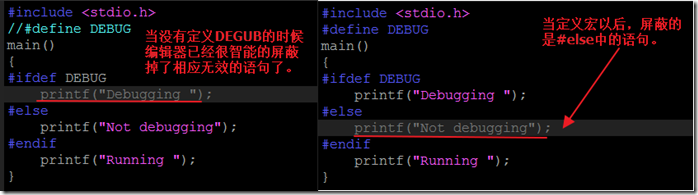
#elif指令

其他一些指令
#error指令将使编译器显示一条错误信息,然后停止编译。
#line指令可以改变编译器用来指出警告和错误信息的文件号和行号。
#pragma指令没有正式的定义。编译器可以自定义其用途。典型的用法是禁止或允许某些烦人的警告信息。
小结:
预处理就是在进行编译的第一遍词法扫描和语法分析之前所作的工作。说白了,就是对源文件进行编译前,先对预处理部分进行处理,然后对处理后的代码进行编译。这样做的好处是,经过处理后的代码,将会变的很精短。
写这篇博文的时候, 还没有参加工作. 现在回过头来, 感觉这篇内容写的还是很晦涩难懂. 因为当时的我处于学生时代, 对于技术的理解只有输入, 没有过多的工程化的输出, 导致一些东西理解的还是不够透彻. 过于这些宏的理解, 目前, 可以简单的做一下的总结(宏的基础知识,往下看即可);
工作中经常这样使用宏:
1. 常常使用宏来调试代码:
1 #if 0
2 ///< 旧的代码(或函数) (旧的代码, 将会被预处理的时候,屏蔽掉, 不进行编译)
3 #else
4 ///< 新的代码(或函数)
5 #endif
6
7 #ifndef JOE_DEBUG
8 ///< 新的代码(或函数)
9 #else
10 ///< 旧的代码(或函数) (旧的代码, 将会被预处理的时候,屏蔽掉, 不进行编译)
11 #endif
12
13 #ifdef Q_DEBUG
14 ///< 新的代码(或函数)
15 #else
16 ///< 旧的代码(或函数) (旧的代码, 将会被预处理的时候,屏蔽掉, 不进行编译)
17 #endif<br data-filtered="filtered"><br data-filtered="filtered">
通过以上类似的方法, 可以防止由于过多的修改代码, 而把代码修改的一塌糊涂. 建议修改代码的时候, 做到保护好以前的代码, 尽量不进行代码的删除操作. 切记, 能不删除, 就不删除...不要养成随手就删除的习惯. 要养成使用宏和注释代码的习惯.
2. 使用宏来根据不同的平台包含不同的文件. 很多时候, 我们的代码是需要跨系统平台编译和运行的. 比如: 一个小功能代码, 需要既可以在Win下面运行, 还要可以在Max, linux上面运行. 可是, 因为系统的不一样, 有些时候, 头文件的包含的名字是不一样的. 所以,这时候, 就是用到了宏. 因为我们使用编程工具分不同的系统平台, 编程工具自身的环境就会包含不同平台的系统宏, 假设OS_Win, OS_Mac, OS_Linux 分别代码三种系统不同的宏. 而且,Win版本的编程工具中已经定义了OS_Win, 类似的Mac下, 编程工具定义的是OS_Mac, Linux...
1 #ifdef OS_Win
2 #include <windows.h>
3 #endif
4
5 #ifdef OS_Mac
6 #include <mac.h>
7 #endif
8
9 #ifdef OS_Linux
10 #include <linux.h>
11 #endif
12
13 /** 不仅使用在头文件的包含. 而且,对于不同的系统平台. 你也可以使用不同的代码结构. */
今天查看以前文件的时候, 突然发现了#error 这个预处理指令.然后回想一下工作, 发现这个指令使用场景还是很多的.比如: 一个项目的模块儿之多,源文件之大,代码之多,那么其中的宏, 也会很多. 免不了冲突定义.这时候, 我们就需要编译器能及早的告诉我们.那就是在编译的时候.#error就可以这么实现:
/** 如果JOE宏没有定义,那么编译就此结束, 编译器就会显示红色的错误 */
#ifndef JOE
#error "JOE is not exits"
#endif
