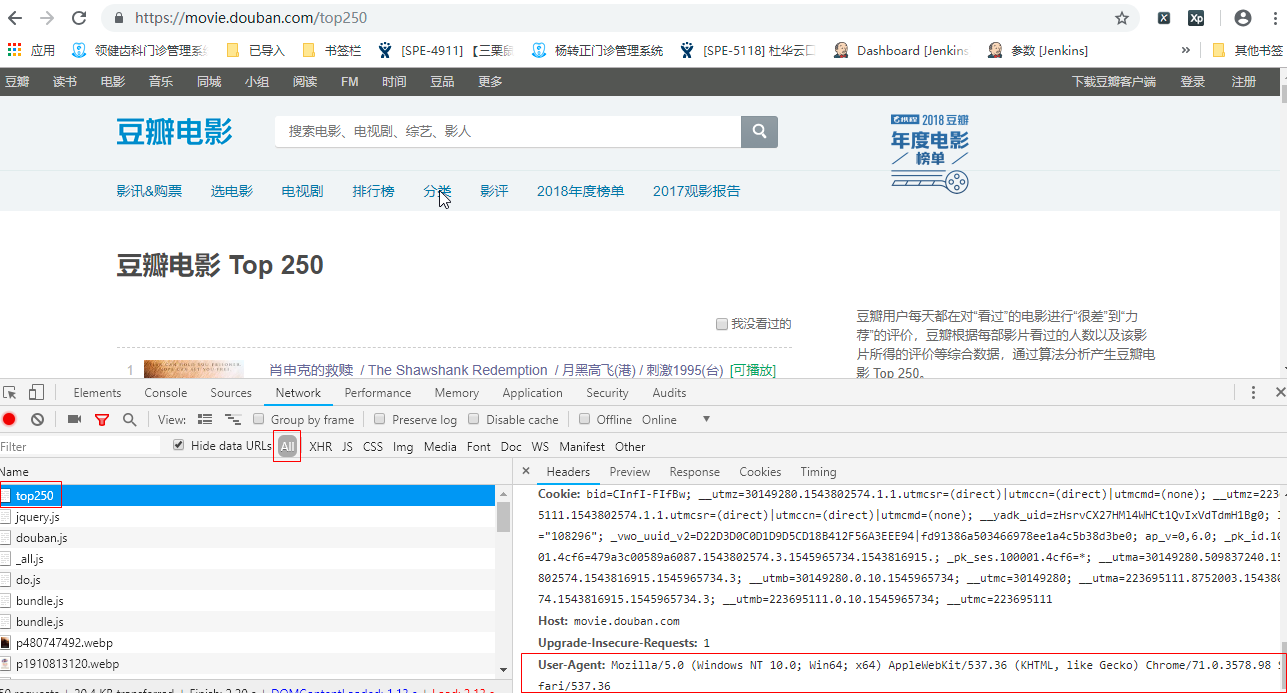
***scrapy框架入门,爬取豆瓣top250的电影信息,保存为csv、json格式***
***不急不怠,平稳心态***
1.创建scrapy项目
①.对应的目录下shell创建:

②.以创建的Mapp爬虫项目为例讲解,下图为创建后的scrapy爬虫框架结构

--1.红框内的文件先不搭理,是爬虫执行后抓取的数据
--2.在spider文件下创建一个新的爬虫文件:scrapy genspider 爬虫名字 域名
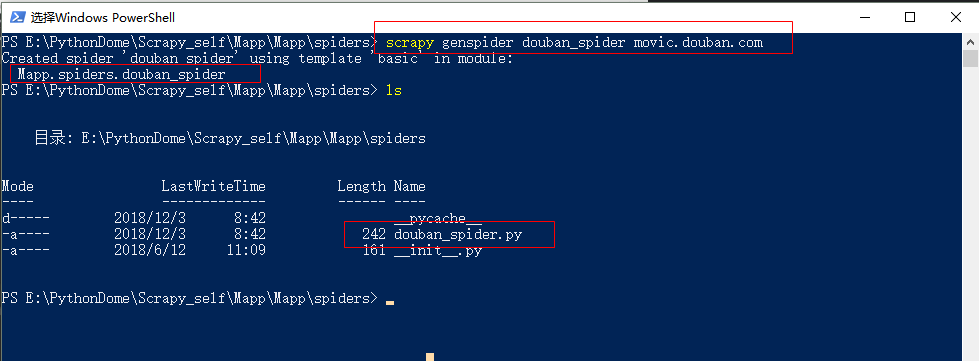
--3.在Mapp下创建main.py文件,用来后面执行爬虫脚本,如上红框内的
2.爬虫创建好之后,编写对应的代码
①.items.py:定义字段结构
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MappItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #序号 serial_number = scrapy.Field() #电影名称 movie_name = scrapy.Field() #电影介绍 interodoce = scrapy.Field() #星级 star = scrapy.Field() #电影评论数 evaluate = scrapy.Field() #电影的描述 describe = scrapy.Field()
②douban_spider.py:编写爬虫脚本
***URL建议复制浏览器地址栏的***
# -*- coding: utf-8 -*- import scrapy #引入定义好的items from Mapp.items import MappItem class DoubanSpiderSpider(scrapy.Spider): #爬虫名字,不能跟项目名字一致 name = 'douban_spider' #允许的域名,不在此域名下的数据不会抓取 allowed_domains = ['movie.douban.com'] #入口URL,扔到调度器里面 start_urls = ['https://movie.douban.com/top250'] def parse(self, response): #print(response.text) movie_list=response.xpath("//div[@class='article']//ol[@class='grid_view']/li") for i_item in movie_list: douban_item = MappItem() #. 是继续对上面movie_list的xpath进行追加 # 序号 douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em//text()").extract_first() # 电影名称 douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first() # 电影介绍,多行处理,拼接字符,进行循环 content=i_item.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()").extract() for i_content in content: #去掉空格,使用join将字符串连接起来 content_s = "".join(i_content.split()) douban_item['interodoce'] = content_s # 星级 douban_item['star'] = i_item.xpath(".//div[@class='info']/div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract_first() # 电影评论数 douban_item['evaluate'] = i_item.xpath(".//div[@class='info']/div[@class='bd']/div[@class='star']/span[4]/text()").extract_first() # 电影的描述 douban_item['describe'] = i_item.xpath(".//div[@class='info']/div[@class='bd']/p[@class='quote']/span[@class='inq']/text()").extract_first() #数据传回管道pipelines中处理 yield douban_item #实现自动翻页,解析下一页规则取的后页的xpath next_link = response.xpath("//span[@class='next']/link/@href").extract() if next_link: #判断是否返回连接,有连接就取 next_link = next_link[0] #提交到调度器,callback回调函数 yield scrapy.Request("https://movie.douban.com/top250" + next_link,callback=self.parse)
③pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class MappPipeline(object): def __init__(self): # 保存为json文件 self.file = open('douban.json','wb') def process_item(self, item, spider): # 当item文件中有中文时,ensure默认是用ascii编码中文 content = json.dumps(dict(item),ensure_ascii=False)+", \n" self.file.write(content.encode("utf-8")) return item def close_spider(self, spider): self.file.close()
④setting.py
***配置的内容:USER_AGENT、DOWNLOAD_DELAY、ITEM_PIPELINES***
# -*- coding: utf-8 -*- # Scrapy settings for Mapp project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'Mapp' SPIDER_MODULES = ['Mapp.spiders'] NEWSPIDER_MODULE = 'Mapp.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #对应要抓取的USER_AGENT 配置,获取方式看结尾 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' # Obey robots.txt rules # robots 协议,True的话是遵守协议,所以要False关掉 ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 0.5 #下载延迟 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html # SPIDER_MIDDLEWARES = { # 'Mapp.middlewares.MappSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'Mapp.middlewares.MappDownloaderMiddleware': 543, # 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html # ITEM_PIPELINES = {
#'Mapp.pipelines.MappPipeline': 300,
'Mapp.pipelines.MappPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
⑤mian.py
from scrapy import cmdline # 保存为csv文件 cmdline.execute('scrapy crawl douban_spider -o douban.csv -t csv'.split()) # 保存为json文件,在piplines.py中已经编写保存json的方法,此处附带第二种方法 # cmdline.execute('scrapy crawl douban_spider -o douban.json -t json'.split())
3.运行科看到以下结果
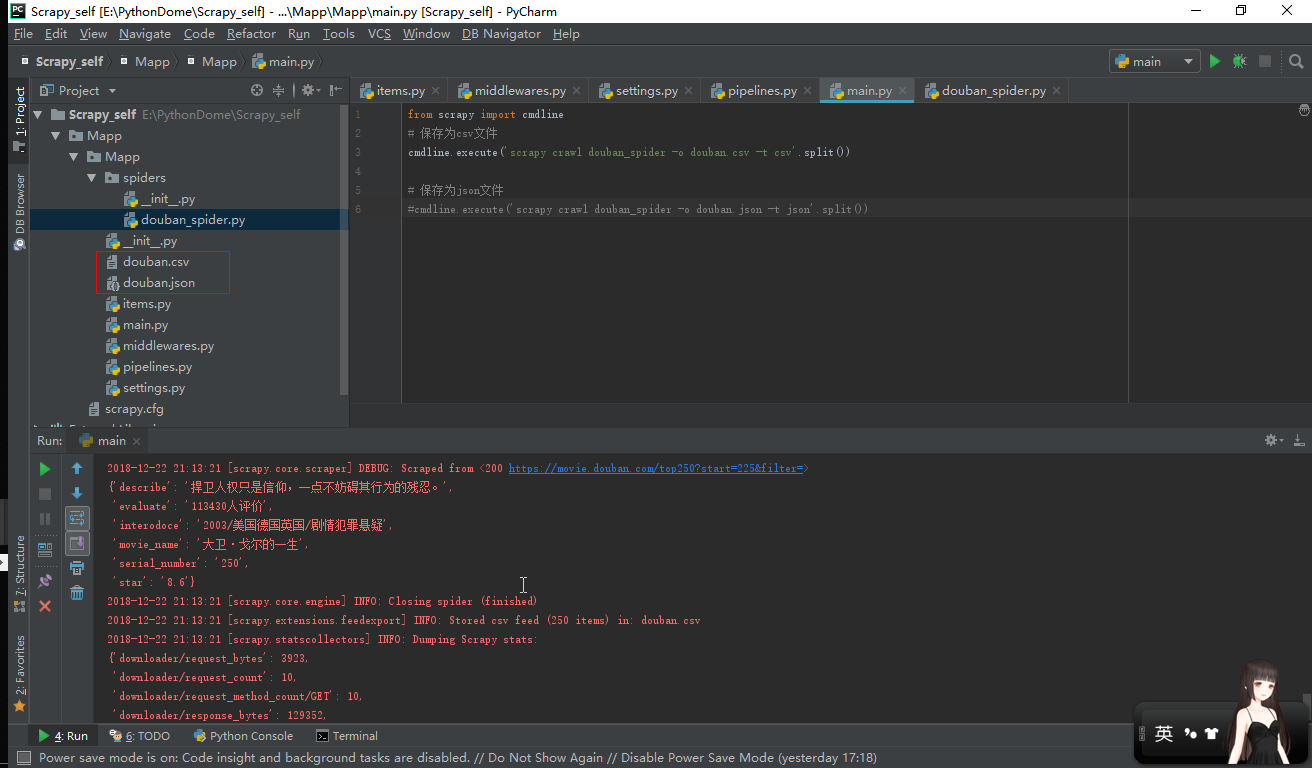
***需要深入的是xpath的选择器的使用***
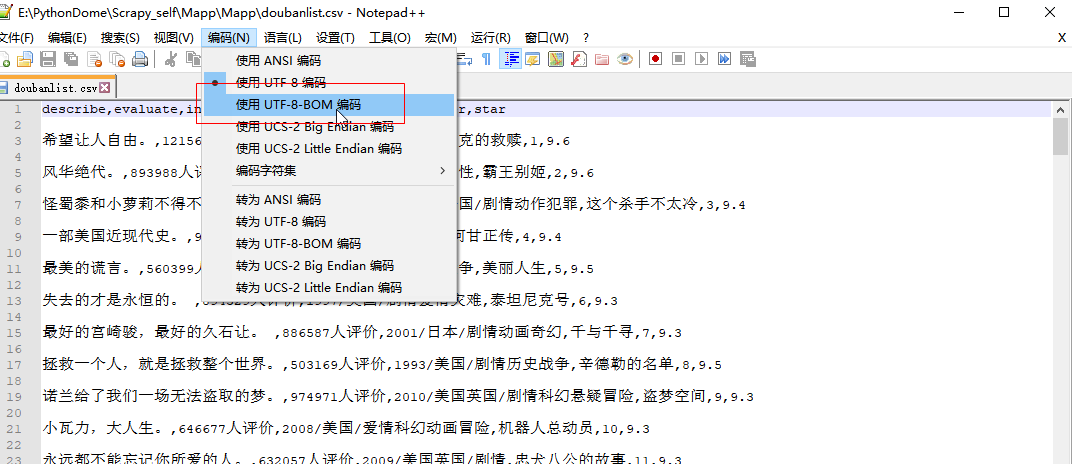
4.CSV打开乱码问题解决:使用notepad++修改csv文件编码即可
5.USER_AGENT 配置获取说明:打开对应的网站,建议使用谷歌,打开开发者工具如图: