

一、全链路监控概述
1.1 什么是全链路监控
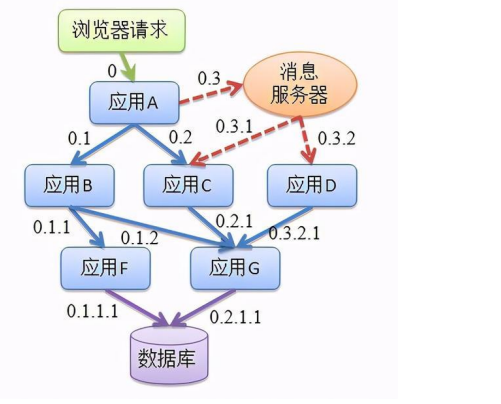
在分布式微服务架构中,系统为了接收并处理一个前端用户请求,需要让多个微服务应用协同工作,其中 的每一个微服务应用都可以用不同的编程语言构建,由不同的团队开发,并可以通过多个对等的应用实例实现水平扩展,甚至分布在横跨多个数据中心的数千台服务器上。单个用户请求会引发不同应用之间产生 一串顺序性的调用关系,如果要对这些调用关系进行监控,了解每个应用如何调用,这就产生了全链路监控
全链路监控说的是对代码的监控,对代码调用的监控
1.2 为什么要进行全链路监控?
在微服务架构中,服务会被拆分成多个模块,这些模块可能由不同的开发团队开发、维护,也可能使用不同的编程语言来实现、也有可能分布在多台服务器上,由于服务的拆分,单个用户的请求会经过多个微服务,相互之间形成复杂的调用关系,传统的监控手段已经不能实现如此复杂的链路之间的监控了,因此, 就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。
1.传统监控工具无法对代码调用监控
2.方便出现问题开发能够快速定位到代码之间哪个调用环节有问题:对代码级别的调用关系进行监控
Prometheus + Alertmanager + grafana 监控容器、物理节点、业务组件、自定义一些监控项
全链路监控工具:zipkin、skywalking、pinpoint 监控代码、代码之间的调用、应用程序之间的调用
1.3 全链路监控能解决哪些问题?
1. 请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
2. 可视化: 各个阶段耗时,进行性能分析。
3. 依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化。
4. 数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
1.4 常见的全链路工具
1.4.1 zipkin
github: https://github.com/openzipkin/zipkin
zipkin 是一个分布式的追踪系统,它能够帮助你收集服务架构中解决问题需要的时间数据,功能包括收集和查找这些数据。如果日志文件中有跟踪 ID,可以直接跳转到它。否则,可以根据服务、操作名称、标记和持续时间等属性进行查询。例如在服务中花费的时间百分比,以及哪些环节操作失败。特点是轻量, 使用部署简单。
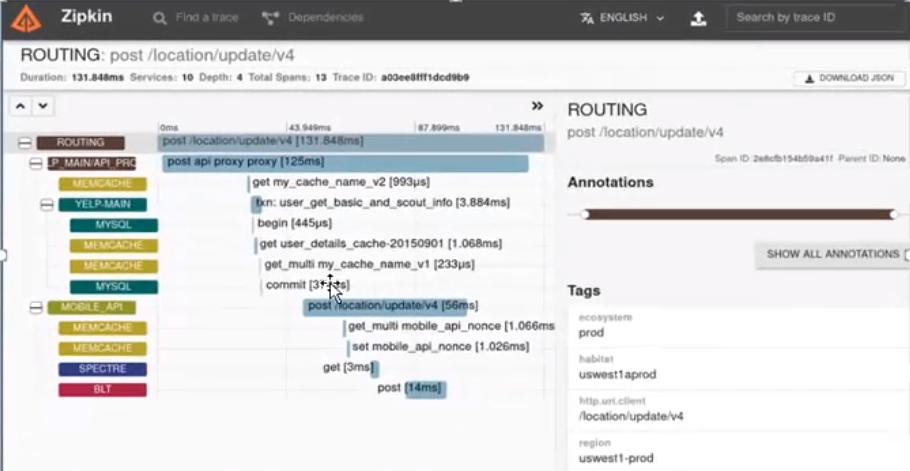
zipkin 还提供了一个 UI 界面,它能够显示通过每个应用程序的跟踪请求数。这有助于识别聚合行为,包括错误路径或对不推荐使用的服务的调
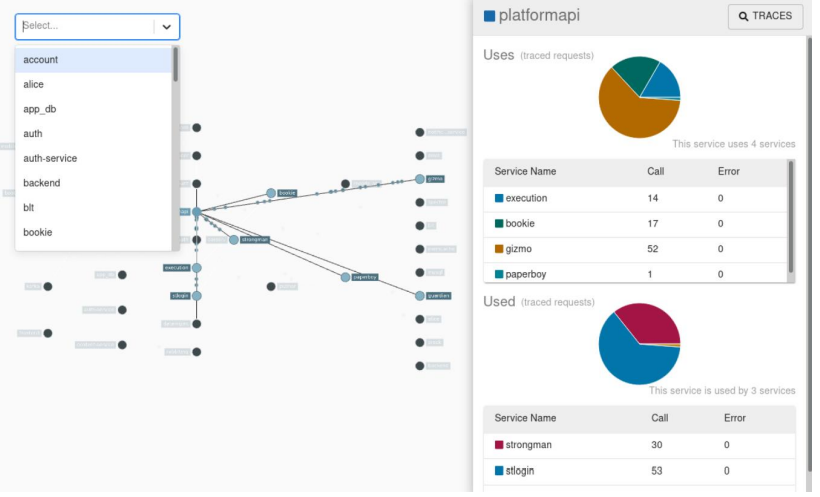
应用程序需要“检测”才能向 Zipkin 报告跟踪数据。这通常意味着需要配置一个用于追踪和检测的库。 最流行的向 Zipkin 报告数据的方法是通过 http 或 Kafka,尽管还有许多其他选项,如 apache, activemq、gRPC 和 RabbitMQ。提供给 UI 存储数据的方法很多,如存储在内存中,或者使用受支持的后端(如 apachecassandra 或 Elasticsearch)持久存储。
1.4.2 Skywalking
github: https://github.com/apache/incubator-skywalking
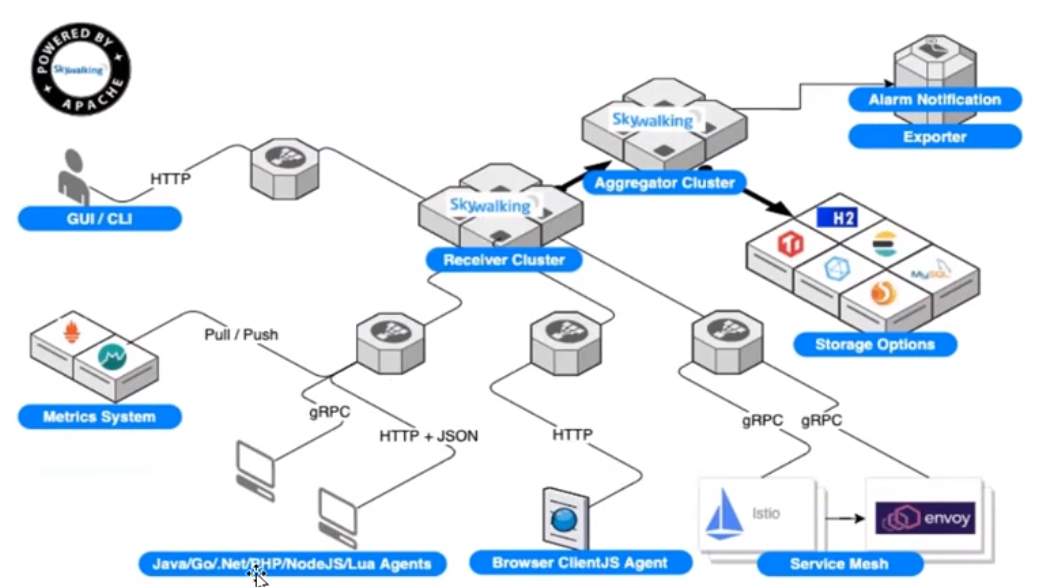
skywalking 是本土开源的调用链追踪系统,包括监控、跟踪、诊断功能,目前已加入 Apache 孵化器, 专门为微服务、云本地和基于容器(Docker、Kubernetes、Mesos)架构设计。
主要功能如下:
1)服务、服务实例、端点指标数据分析
2)根本原因分析,在运行时评测代码
3)服务拓扑图分析
4)服务、服务实例和端点依赖性分析
5)检测到慢速服务和终结点
6)性能优化
7)分布式跟踪和上下文传播
8)数据库访问度量。检测慢速数据库访问语句(包括 SQL 语句)。
9)报警
10)浏览器性能监视
1.4.3 Pinpoint
github: https://github.com/naver/pinpoint
pinpoint 是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。Pinpoint 提供了一个 解决方案,可以帮助分析系统的整体结构,以及通过跟踪分布式应用程序中的事务来分析其中的组件是如何相互连接的。
功能如下:
1)一目了然地了解应用程序拓扑
2)实时监视应用程序
3)获得每个事务的代码级可见性
4)安装 APM 代理程序,无需更改一行代码
5)对性能的影响最小(资源使用量增加约 3%)
Pinpoint 的可视化 UI 界面:
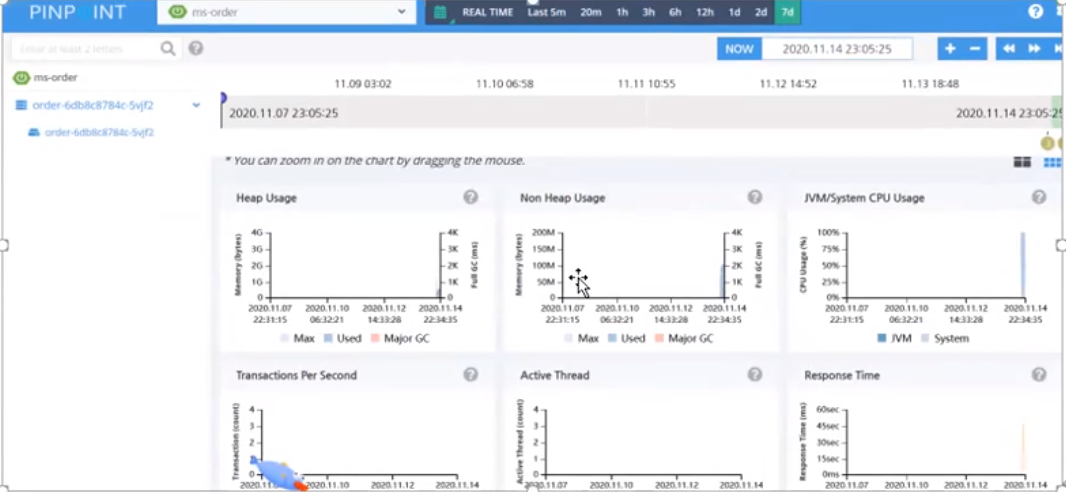
1.5 全链路监控工具对比分析
市面上的全链路监控理论模型大多都是借鉴 Google Dapper 论文,本文重点关注以下三种 APM 组件:
APM = ApplicationPerformance Management,中文即应用性能管理
1)Zipkin:由 Twitter 公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。
2)Pinpoint:一款对 Java 编写的大规模分布式系统的 APM 工具,由韩国人开源的分布式跟踪组件。
3)Skywalking:国产的优秀 APM 组件,是一个对 JAVA 分布式应用程序集群的业务运行情况进行追 踪、告警和分析的系统。
1.5.1 全面的调用链路数据分析
全面的调用链路数据分析,提供代码级别的可见性以便轻松定位失败点和瓶颈。
zipkin:
zipkin 的链路监控粒度相对没有那么细,调用链中具体到接口级别,再进一步的调用信息并未涉及。
skywalking:
skywalking 支持 20+的中间件、框架、类库,比如:主流的 dubbo、Okhttp,还有 DB 和消息中间 件。skywalking 链路调用分析截取的比较简单,网关调用 user 服务,由于支持众多的中间件,所以 skywalking 链路调用分析比 zipkin 完备些。
.pinpoint
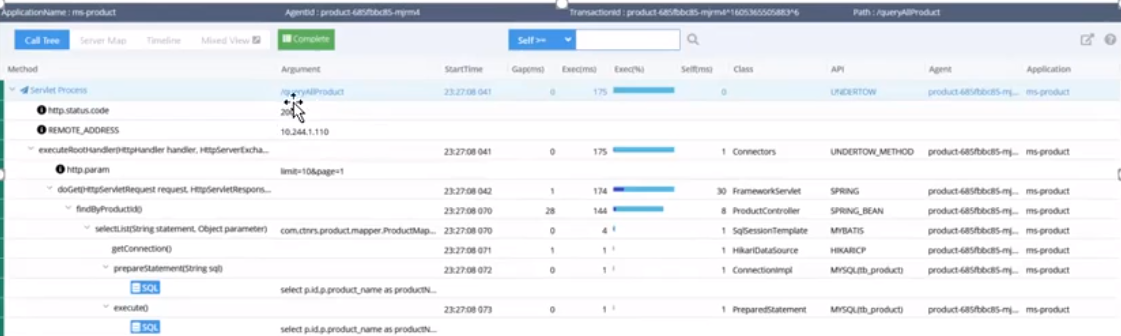
pinpoint 应该是这三种 APM 组件中,数据分析最为完备的组件。提供代码级别的可见性以便轻松定位失败点和瓶颈,上图可以看到对于执行的 sql 语句,都进行了记录。还可以配置报警规则等,设置每个应用对应的负责人,根据配置的规则报警,支持的中间件和框架也比较完备。
1.5.2 Pinpoint 与 Zipkin 细化比较
pinpoint和zipkin的差异性
1. Pinpoint 是一个完整的性能监控解决方案,有从探针、收集器、存储到 Web 界面等全套体系,而 Zipkin 只侧重收集器和存储服务,虽然也有用户界面,但其功能与 Pinpoint 不可同日而语。反而 Zipkin 提供有 Query 接口,更强大的用户界面和系统集成能力,可以基于该接口二次开发实现。
2. Zipkin 官方提供有基于 Finagle 框架(Scala 语言)的接口,而其他框架的接口由社区贡献,目前 可以支持 Java、Scala、Node、Go、Python、Ruby 和 C# 等主流开发语言和框架;但是 Pinpoint 目前只有官方提供的 Java Agent 探针,其他的都在请求社区支援中。
3. Pinpoint 提供有 Java Agent 探针,通过字节码注入的方式实现调用拦截和数据收集,可以做到真正的代码无侵入,只需要在启动服务器的时候添加一些参数,就可以完成探针的部署,而 Zipkin 的 Java 接口实现 Brave,只提供了基本的操作 API,如果需要与框架或者项目集成的话,就需要手动添加配置 文件或增加代码。
4. Pinpoint 的后端存储基于 Hbase,而 Zipkin 基于 Cassandra。
pinpoint与zipkin相似性
pinpoint 与 zipkin 都是基于 Google Dapper 的那篇论文,因此理论基础大致相同。两者都是将服务调 用拆分成若干有级联关系的 Span,通过 SpanId 和 ParentSpanId 来进行调用关系的级联,最后再将整 个调用链流经的所有的 Span 汇聚成一个 Trace,报告给服务端的 collector 进行收集和存储。
即便在这一点上,Pinpoint 所采用的概念也不完全与那篇论文一致。比如他采用 TransactionId 来取代 TraceId,而真正的 TraceId 是一个结构,里面包含了 TransactionId, SpanId 和 ParentSpanId。而且 Pinpoint 在 Span 下面又增加了一个 SpanEvent 结构,用来记录一个 Span 内部的调用细节(比如 具体的方法调用等等),因此 Pinpoint 默认会比 Zipkin 记录更多的跟踪数据。但是理论上并没有限定 Span 的粒度大小,所以一个服务调用可以是一个 Span,那么每个服务中的方法调用也可以是个 Span,这样的话,其实 Brave 也可以跟踪到方法调用级别,只是具体实现并没有这样做而已。
(1)span是什么?
基本工作单元,一次链路调用(可以是 RPC,DB 等没有特定的限制)创建一个 span,通过一个 64 位 ID 标识它,uuid 较为方便,span 中还有其他的数据,例如描述信息,时间戳,key-value 对的 (Annotation)tag 信息,parent_id 等,其中 parent-id 可以表示 span 调用链路来源。
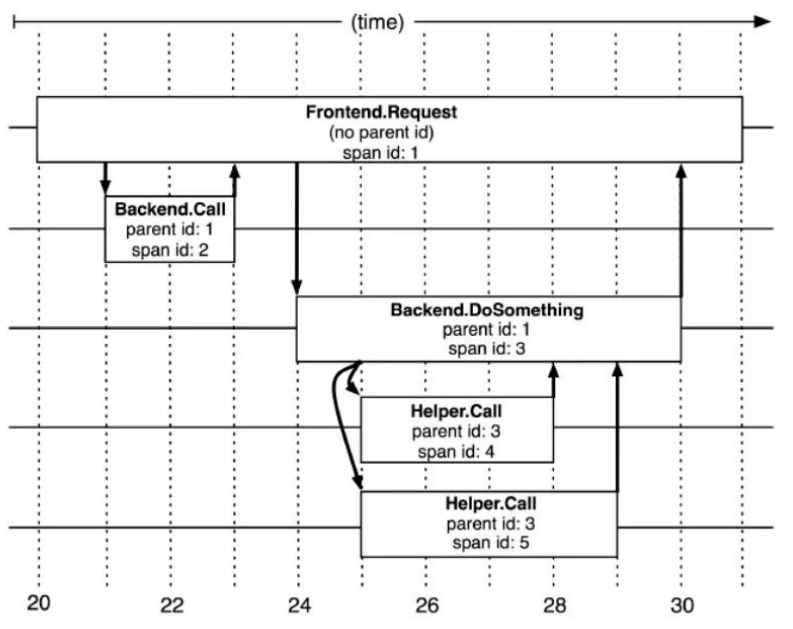
上图说明了 span 在一次大的跟踪过程中是什么样的。Dapper 记录了 span 名称,以及每个 span 的 ID 和父 ID,以重建在一次追踪过程中不同 span 之间的关系。如果一个 span 没有父 ID 被称为 root span。所有 span 都挂在一个特定的跟踪上,也共用一个跟踪 id。
Span 数据结构: type Span struct { TraceID int64 #用于标示一次完整的请求 id Name string ID int64 #当前这次调用 span_id ParentID int64 #上层服务的调用 span_id 最上层服务 parent_id 为 null Annotation []Annotation #用于标记的时间戳 Debug bool }
(2)Trace是什么?
类似于树结构的 Span 集合,表示一次完整的跟踪,从请求到服务器开始,服务器返回 response 结 束,跟踪每次 rpc 调用的耗时,存在唯一标识 trace_id。比如:你运行的分布式大数据存储一次 Trace 就 由你的一次请求组成。
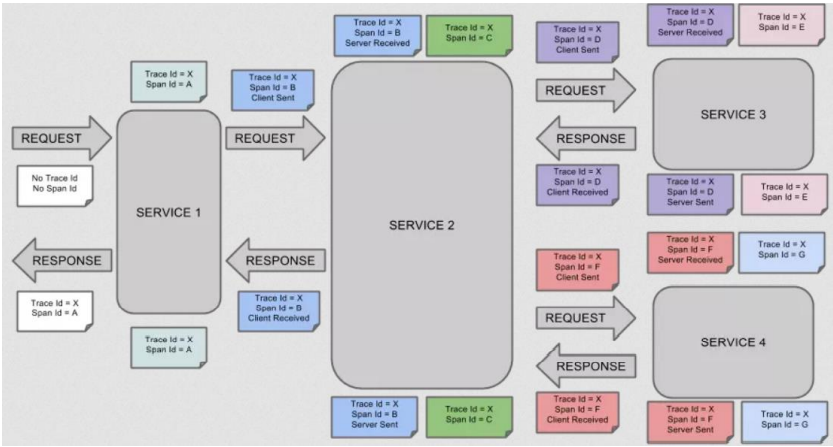
每种颜色的 note 标注了一个 span,一条链路通过 TraceId 唯一标识,Span 标识发起的请求信息。树节点是整个架构的基本单元,而每一个节点又是对 span 的引用。节点之间的连线表示的 span 和它的父 span 直接的关系。虽然 span 在日志文件中只是简单的代表 span 的开始和结束时间,他们在整个树形结 构中却是相对独立的。
二、Pinpoint部署
部署 pinpoint 的服务器建议 4 核 8G,比较消耗内存
新机器初始化的步骤按照上面讲的步骤操作即可,只需要执行如下七个步骤:
虚拟机harbor:192.168.10.12 可以参考k8s的环境初始化 1.1 配置静态 ip 1.2 修改 yum 源 1.3 配置防火墙 1.4 时间同步 1.5 关闭 selinux 1.6 修改内核参数 1.7 修改主机名 1.8 安装docker并配置镜像加速
2.1 pinpoint部署
本次部署版本为:2.0.1
下载路径:https://github.com/pinpoint-apm/pinpoint/releases/tag/v2.0.1
unzip pinpoint-docker-2.0.1.zip cd pinpoint-docker-2.0.1 # 修改 docker-compose.yml 文件的 version 版本,如 2.2,变成自己支持的版本 version: "3.6" 变成 version: "2.2" # 安装docker-compose yum install docker-compose -y # 拉取镜像 cd /data/install/pinpoint-docker-2.0.1 docker pull
pinpointdocker/pinpoint-web 2.0.1 f01611ce6ac6 2 years ago 563MB
pinpointdocker/pinpoint-agent 2.0.1 26d1e3a7161c 2 years ago 29.9MB
pinpointdocker/pinpoint-hbase 2.0.1 ae47793b0078 2 years ago 993MB
pinpointdocker/pinpoint-collector 2.0.1 adc22dda0207 2 years ago 529MB
pinpointdocker/pinpoint-mysql 2.0.1 f0ccfeaf1a3a 2 years ago 475MB
# 启动服务 docker-compose up -d # 查看对应服务是否启动 docker ps | grep pinpoint #找到 pinpoint-web,可看到在宿主机绑定的端口是 8079, 在浏览器访问 ip:8079 即可访问 pinpoint 的 web ui 界面 http://192.168.10.12:8079
2.2 部署pinpoint agent
http://192.168.10.12:8079
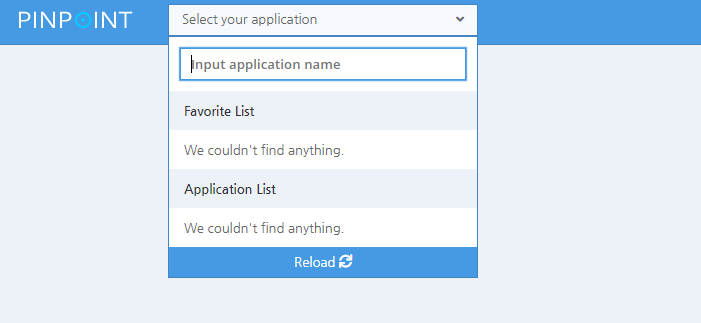
主页---》右上角"设置"---》"Installation"
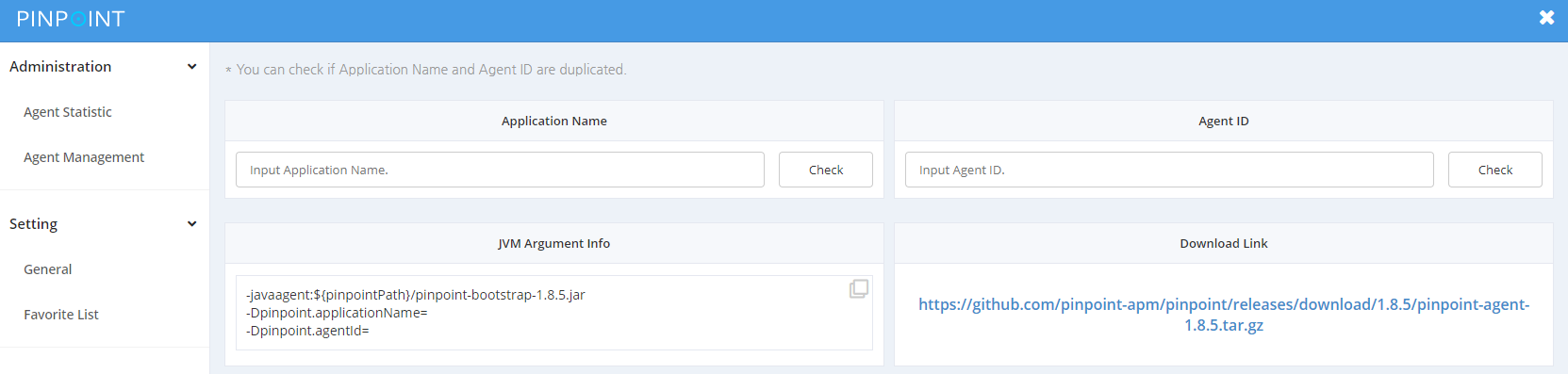
pinpoint监控springcloud
# 1.修改springcloud中stock、product、order订单数据库地址 # 2.修改pinpoint配置文件地址:stock、product、order、eureka-service、gateway-service、portal-service,更新对应目录下的pinpoint.config cd /data/microservic-test-dev1/product-service/product-service-biz/pinpoint vim pinpoint.config profiler.collector.ip=192.168.10.12 # pinpoint服务端地址 # 3.重新编译打包 mvn clean package -D maven.test.skip=true
2.2 部署带有pinpoint agent 的product服务
cd /data/microservic-test-dev1/product-service/product-service-biz [root@master product-service-biz]# cat Dockerfile FROM java:8-jdk-alpine RUN apk add -U tzdata && \ ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime COPY ./target/product-service-biz.jar ./ COPY pinpoint /pinpoint EXPOSE 8010 CMD java -jar -javaagent:/pinpoint/pinpoint-bootstrap-1.8.5.jar -Dpinpoint.agentId=${HOSTNAME} -Dpinpoint.applicationName=ms-product /product-service-biz.jar # 制作镜像 [root@master product-service-biz]# docker build -t 192.168.10.12/microservice/product:v2 . [root@master product-service-biz]# docker push 192.168.10.12/microservice/product:v2 #部署服务:现在有2个product,一个v1版本,一个v2版本,等v2版本起来后,会自动删除v1版本的 cd /data/microservic-test-dev1/k8s [root@master k8s]# kubectl apply -f product.yaml deployment.apps/product configured
以同样的步骤将order服务、stock服务、portal服务、gateway服务都重新部署一次,然后查看pinpoint 的 web 界面
2.3 pinpoint的web界面介绍
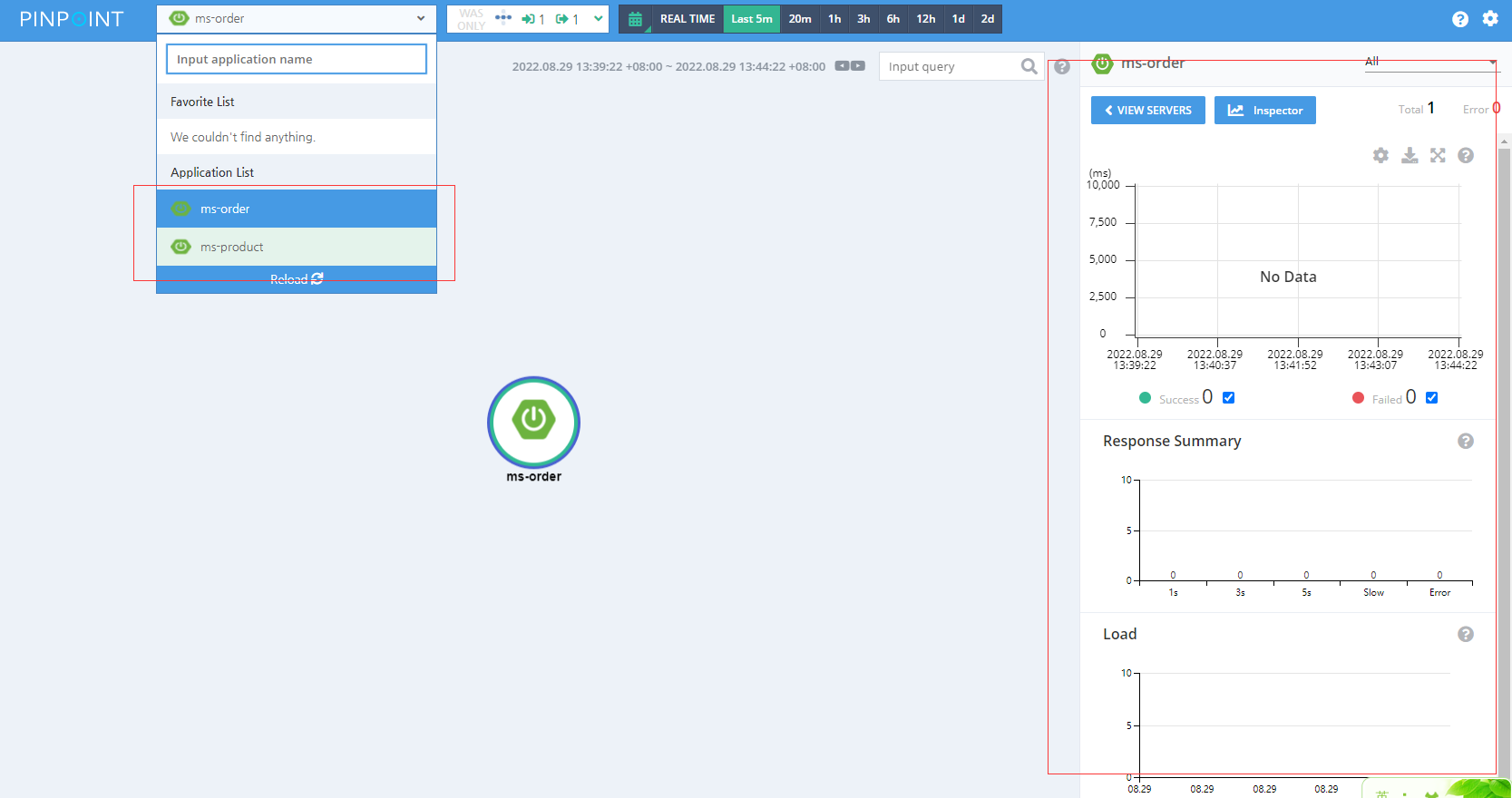
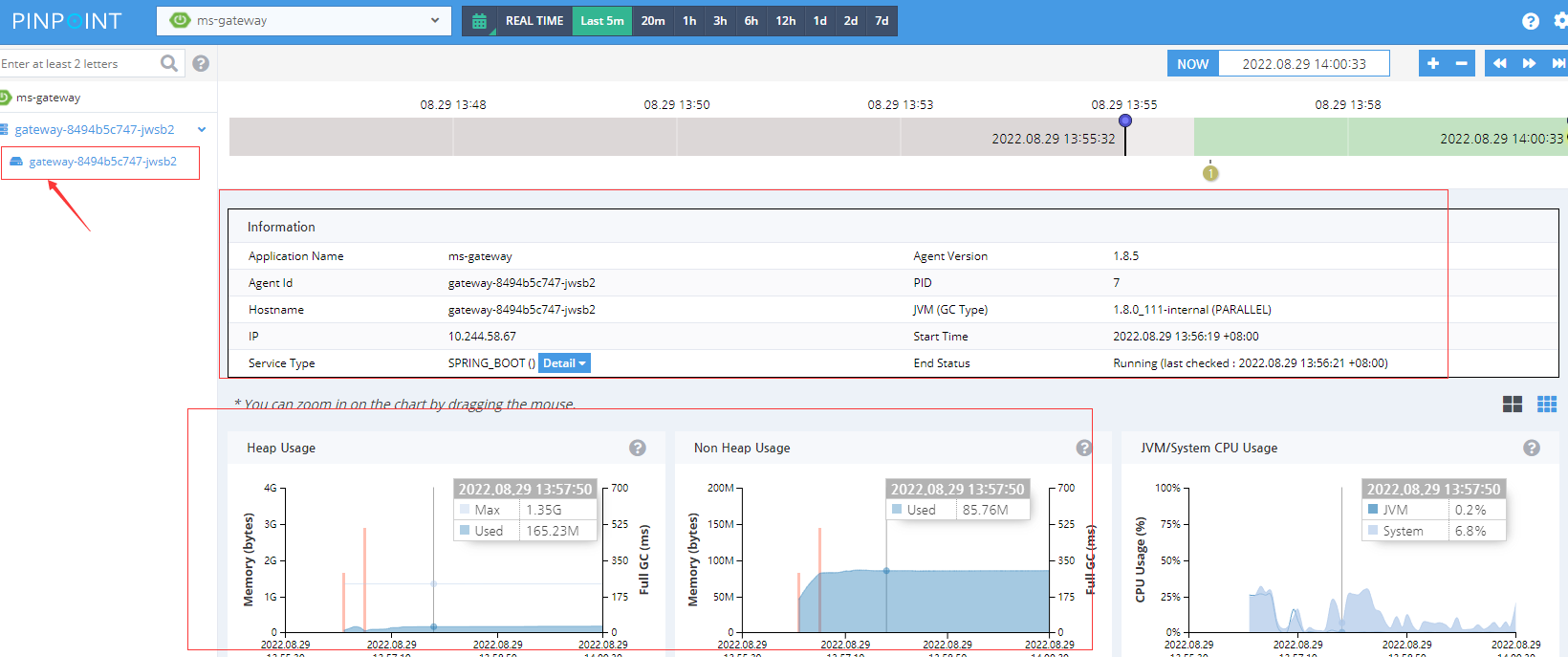

 浙公网安备 33010602011771号
浙公网安备 33010602011771号