
0.展示PTA总分
0.1 一维数组

0.2 二维数组

0.3 字符数组

1.本章学习总结
1.1 学习内容总结
1.数组是最基本的构造类型,是一组相同类型数据的有序集合。
2.在程序中使用数组,可以让一批相同类型的变量使用同一个数组变量名,用下标相互区分。
3.数组的优点是表达简洁,可读性好便于使用循环结构。
4.定义一个数组,需要明确数组变量名,数组元素的类型和数组的大小(即数组中元素的数量)。
5.一维数组定义的一般形式为:

类型名指定数组中每个元素的类型;
数组名是数组变量(以下简称数组)的名称,是一个合法的标识符;
数组长度是一个整型常量表达式,设定数组的大小。
6.数组是一些具有相同类型的数据的集合,数组中的数据按照一定的顺序排列存放。同一数组中的每个元素都具有相同的数据类型,有统一的标识符即数组名,用不同的序号即下标来区分数组中的各元素。
7.在定义数组之后,系统根据数组中元素的类型及个数在内存中分配了一段连续的存储单元用于存放数组中的各个元素,并对这些单元进行连续编号,即下标,以区分不同的单元。每个单元所需的字节数由数组定义时给定的类型来确定。只要知道了数组第一个元素的地址以及每个元素所需的字节数,其余各个元素的存储地址均可计算得到。
8.C语言规定,数组名表示该数组所分配连续内存空间中第一个单元的地址,即首地址。由于数组空间一经分配之后在运行过程中不会改变,因此数组名是一个地址常量,不允许修改。数组名是一个地址常量,存放数组内存空间的首地址。
9.定义数组后,C语言规定,只能引用单个的数组元素,而不能一次引用整个数组。
10.数组元素的引用要指定下标,形式为:
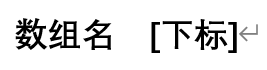
11.下标可以是整型表达式,它的合理取值范围是[0,数组长度-1],下标不能越界,这些数组元素在内存中按下标递增的顺序连续储存。
12.区分数组的定义和数组元素的引用:
两者都要用到“数组名[整型表达式]“,定义数组时,方括号内是常量表达式,代表数组长度,它可以包括常量和符号常量,但不能包含变量。也就是说,数组的长度在定义时必须指定,在程序的运行过程中是不能改变的。而引用数组元素时,方括号内是表达式,代表下标,可以是变量,下标的合理取值范围是[0,数组长度-1]。
13.对一维数组赋初值时,其一般形式为:

14.虽然C适言规定,只有静态存储的数组才能初始化,但一般的C编译系统都允许对动态储存的数组赋初值。
15.静态存的数组如果没有初始化,系统自动给所有的数组元素赋0。数组的初始化也可以只针对部分元素。

16.数组的应用离不开循环。
17.数组的长度在定义时必须确定,如果无法确定需要处理的数据数量,至少也要估计其上限,并将该上限值作为数组长度。
18.C语言支持多维数组,最常见的多维数组就是二维数组,主要用于表示二维表和矩阵。
19.二维数组定义的一般形式为:

20.引用二维数组的形式为:
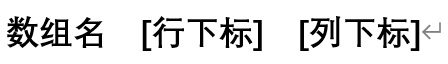
21.由于二维数组的行(列)下标从0开始,而矩阵或二维表的行(列)从1开始,用二维数组表示二维表和矩阵时,就存在行(列)计数的不一致。为了解决这个问题,可以把矩阵或二维表的行(列)也看成从0开始,即如果二维数组的行(列)下标为k,就表示矩阵或二维表的第k行(列);或者定义二维数组时,将行长度(列长度)加1,不再使用数组的第0行(列),数组的下标就从1开始。一般都采取第一种方法。
22.二维数组的初始化方法有两种:
①分行赋初值

②顺序赋初值

23.将二维数组的行下标和列下标分别作为循环变量,通过二重循环,就可以遍历二维数组,即访问二堆数组的所有元素。由于二维数组的元素在内存中按行优先方式存放,当行下标作为外循环的循环变量,列下标作为内循环的循环变量,可以提高程序的执行效率。
24.在C语言中,字符串的存储和运算可以用一维字符数组来实现、数组长度取上限80,以回车符'\n'作为输入结束符。
25.字符串常量是用一对双引号括起来的字符序列,它有一个结束标志'\0',整数0也代表字符'\0'。
26.初始一个字符串数组,如:
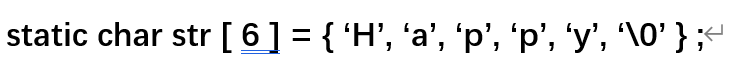
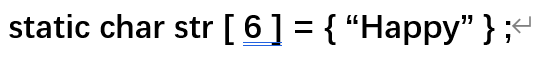
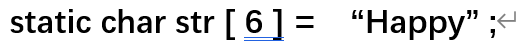
ps:三者等价
27.将字符串存入字符数组时,由于它有一个结束符”\0,数组长度至少是字符串的有效长度+1。
28.如果数组长度大于字符串的有效长度+1,则数组中除了存入的字符串,还有其他内容,即字符串只占用了数组的一部分。
29.字符串遇'\0'结束,所以第一个'\0'之后的其他数组元素与该字符串无关。
30.字符串由有效字符和字符串结束符'\0'组成。
31.区分”a”和’a’:前者是字符串常量,包括’a’和’\0’两个字符,用一维字符数组存放;后者是字符常量,只有一个字符,可以给字符变量。
32.输入的情况有些特殊,由于字符串结束符’\0’代表空操作,无法输人,因此,输入字符串时,需要事先设定一个输入结束符。一旦输入它,就表示字符串输入结束,并将输入结束符转换为字符串结束符’\0’。
33.sizeof() 是计算所占用的空间字节大小。
34.strlen() 是计算字符串数组的长度,遇 0 则止。
35.数组中目前学到排序方法:
1>.冒泡排序
void bubbleSort(int a[], int n)
{
int i;
int j;
int n;
int temp;
for (i = 0; i < n; i++)
{
for (j = 0; j < n - 1; j++)
{
if (a[j] > a[j + 1])
{
temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
}
2>.选择排序
void selectionSort(int a[], int n)
{
int i;
int j;
int temp;
for (i = 1; i < n; i++)
{
for (j = i + 1; j < n; j++)
{
if (a[j] > a[i])
{
temp = a[j];
a[j] = a[i];
a[i] = temp;
}
}
}
}
36.数组中如何插入数据?
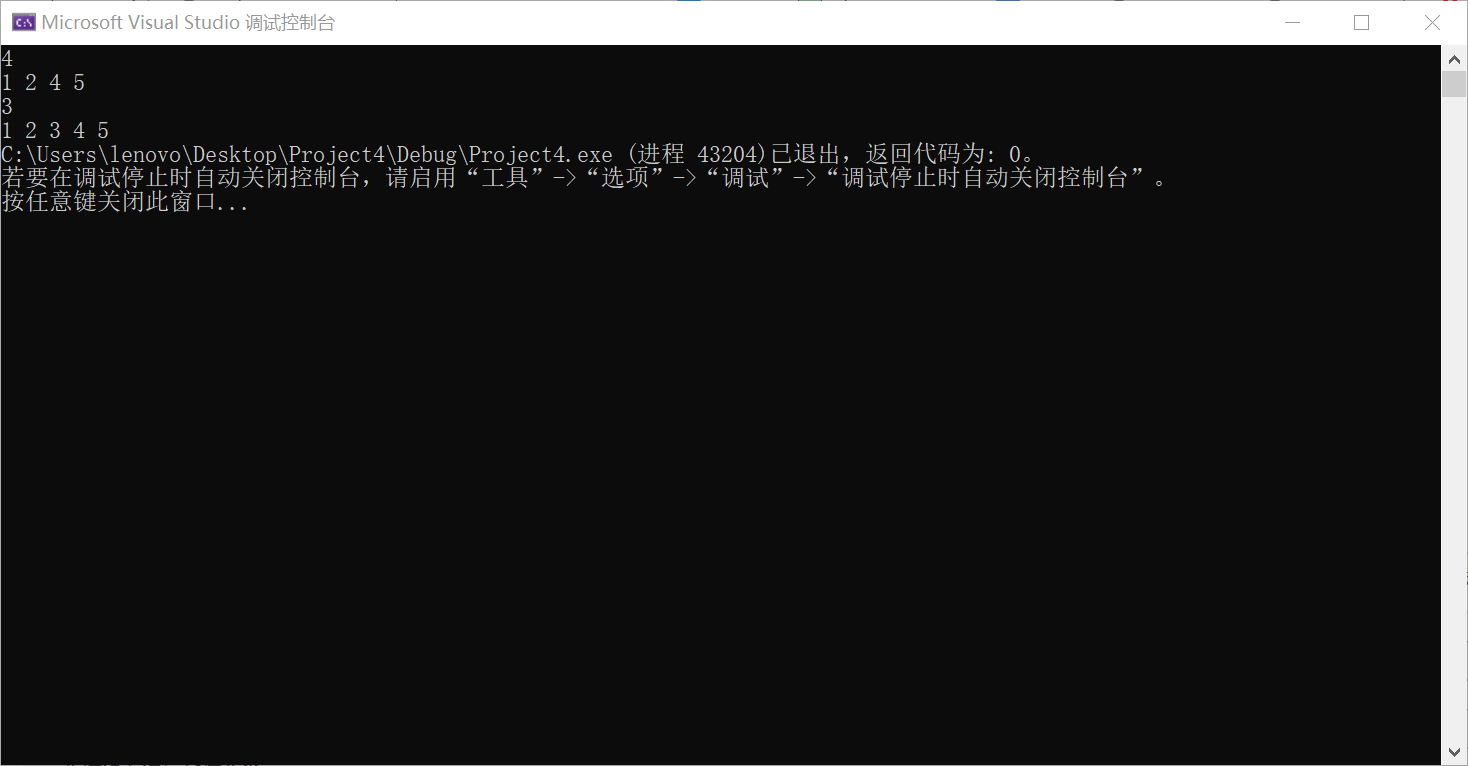
1>.输入一个数据k,将数组中的数据与k逐一比较,如果大于k,记录下数据的下标,然后此数据下标和其后的数据的下标都加一,相当于都向后挪一位,然后将k赋值给数组的那个下标
我的代码
#include<stdio.h>
#include <string.h>
#define N 100
int main()
{
int n;//数组元素的个数
int a[N];
int i;
int j;
int k;//插入的数
scanf("%d\n", &n);
for (i = 0; i < n; i++)
{
scanf("%d", &a[i]);
}
scanf("%d", &k);
for (i = 0; i < n; i++)
{
if (a[i] > k)
{
break;
}
}
for (j = n - 1; j >= i; j--)
{
a[j + 1] = a[j];
}
a[i] = k;
for (i = 0; i < n + 1; i++)
{
printf("%d ", a[i]);
}
return 0;
}
运行示例
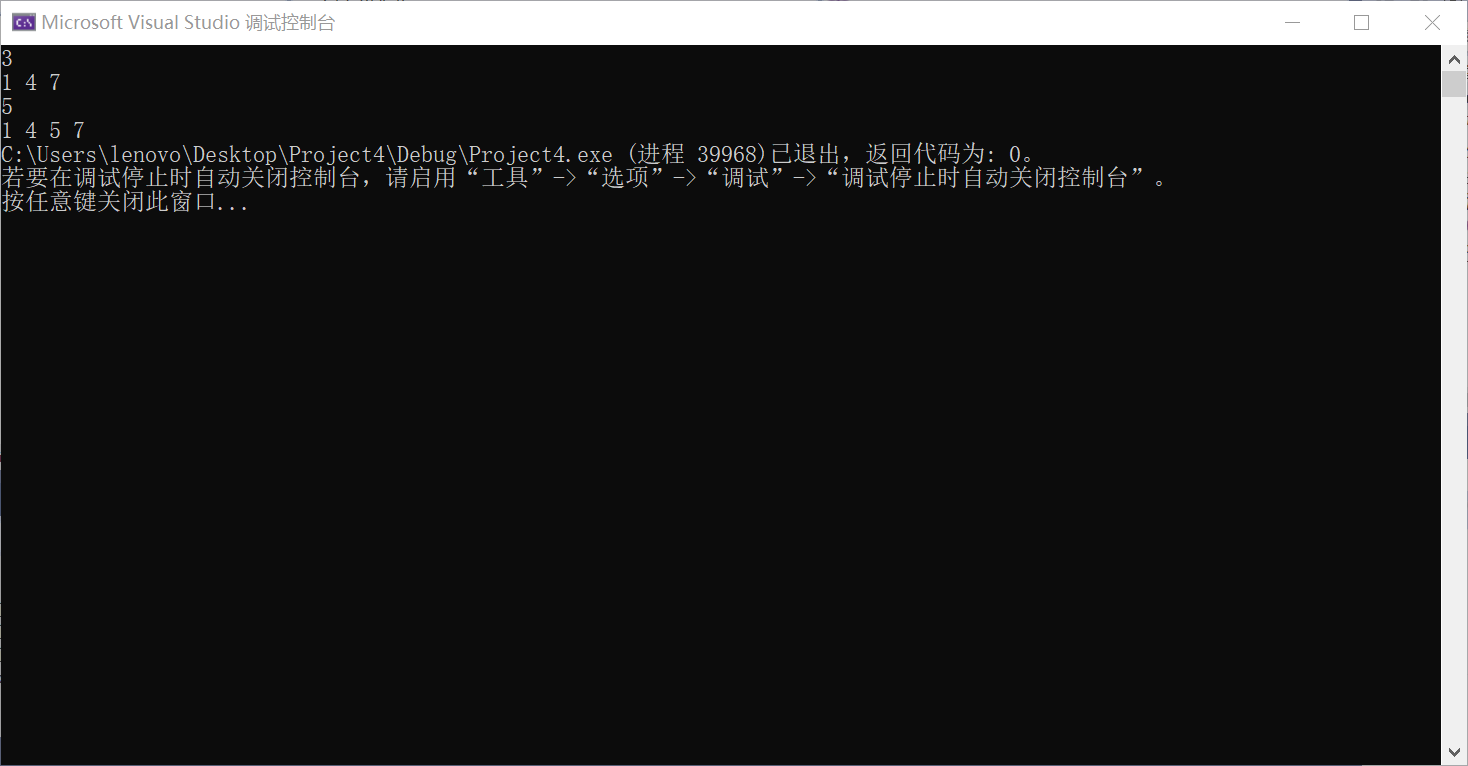
2>.将要插入的数据放在数组最后,然后和前面的数据逐一比较,如果k小于某元素a[i],则将a[i]后移一个位置,否则将k至于a[i+1]的位置
我的代码
#include<stdio.h>
#include <string.h>
#define N 100
int main()
{
int n;//数组元素的个数
int a[N];
int i;
int j;
int k;//插入的数
scanf("%d\n", &n);
for (i = 0; i < n; i++)
{
scanf("%d", &a[i]);
}
scanf("%d", &k);
a[n] = k;
for (i = n - 1; i >= 0; i--)
{
if (a[i] > k)
{
a[i + 1] = a[i];
}
else
{
a[i + 1] = k;
break;
}
}
for (i = 0; i < n + 1; i++)
{
printf("%d ", a[i]);
}
return 0;
}
运行示例
37.数组中如何删除数据?
#include<stdio.h>
#include <string.h>
#define N 100
int main()
{
int n;//数组元素的个数
int a[N];
int i;
int j;
int k;//进行k次删除
int x;//每行要删除第x个元素
int temp;
scanf("%d\n", &n);
for (i = 0; i < n; i++)
{
scanf("%d", &a[i]);
}
scanf("%d", &k);
for (i = 0; i < k; i++)
{
scanf("%d", &x);
for (j = x; j < n; j++)
{
a[j - 1] = a[j];
}
}
for (i = 0; i < n - k; i++)
{
if (i == n - k - 1)
{
printf("%d", a[i]);
}
else
{
printf("%d ", a[i]);
}
}
return 0;
}
38.数组中如何查找数据?
1>.二分查找法
我的代码
int dichotomySearch(int* a, int n, int x)
{
int left;
int right;
int mid;
left = 0;
right = n - 1;
while (left <= right)
{
mid = (left + right) / 2;//从中间开始
if (x == a[mid])
{
break;
}
else if (x < a[mid])
{
right = mid - 1;
}
else
{
left = mid + 1;
}
}
if (left <= right)
{
return mid; // 找到返回下标
}
else
{
return -1;//找不到返回 - 1
}
}
运行示例
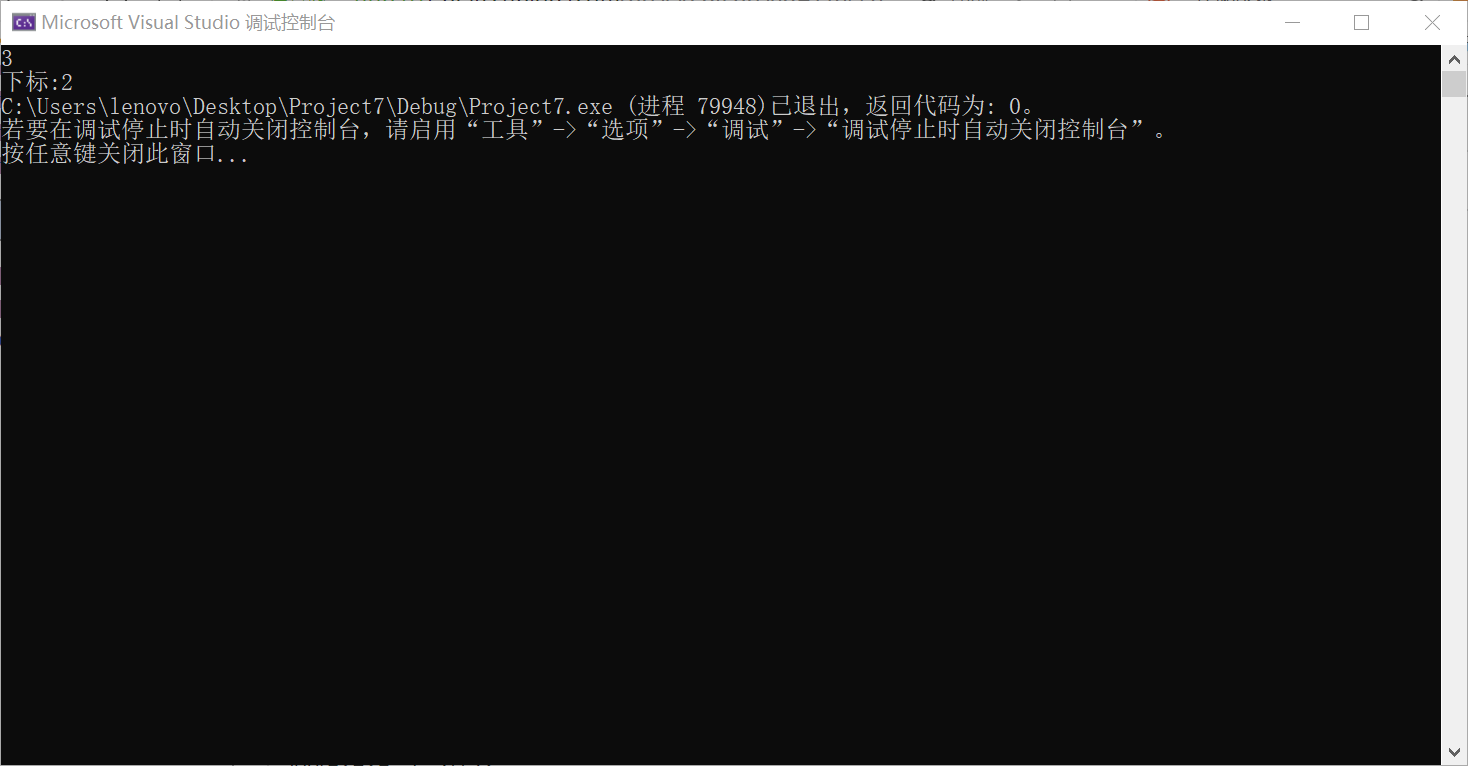
2>.遍历数组
我的代码
#include<stdio.h>
#define N 10
int main()
{
int a[N] = { 1,2,3,4,5,6,7,8,9,10 };
int x;
int i;
int flag;
flag = 0;
scanf("%d", &x);//输入要找的数
for (i = 0; i < N; i++)//遍历数组
{
if (a[i] == x)
{
flag = 1;//找到则flag=1,退出循环
break;
}
}
if (flag == 1)
{
printf("下标:%d", i);
}
else
{
printf("NOT FOUND!");
}
return 0;
}
运行示例
39.数组做枚举用法的案例:
题目
求整数序列中出现次数最多的数 (15 分)
本题要求统计一个整型序列中出现次数最多的整数及其出现次数。
代码
#include<stdio.h>
#define N 1000
int main()
{
int n;
int a[N];
static int count[N];
int i;
int j;
int max;
int maxIndex;
scanf("%d", &n);
for (i = 0; i < n; i++)
{
scanf("%d", &a[i]);
}
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
if (a[i] == a[j])
{
count[i]++;
}
}
}
max = count[0];
for (i = 1; i < n; i++)
{
if (max <= count[i])
{
max = count[i];
maxIndex = i;
}
}
printf("%d %d\n", a[maxIndex],max);
return 0;
}
40.哈希数组用法及目前学过的案例
用法
hash就是为了把一个复杂的字串,通过一定的转换,得到一个简单的数字,作为一个数组的下标来用。这样的话,如果要去查询一个字串是否存在,就不需要对一个数组使用字符串循环对比这样的慢操作,而直接先得到某个字串的hash值,再用这个hash值,在数组下标里直接找,这样速度要快上很多,特别是数据比较多的时候。
题目
有重复的数据I (10 分)
在一大堆数据中找出重复的是一件经常要做的事情。现在,我们要处理许多整数,在这些整数中,可能存在重复的数据。
你要写一个程序来做这件事情,读入数据,检查是否有重复的数据。如果有,输出“YES”这三个字母;如果没有,则输出“NO”。
代码
#include<stdio.h>
#define Max 100001
int IsSame(int n);
int main()
{
int n;
scanf("%d", &n);
if (IsSame(n))
{
printf("YES");
}
else
{
printf("NO");
}
return 0;
}
int IsSame(int n)
{
int i;
int data;
static int hash[Max];
for (i = 1; i <= n; i++)
{
scanf("%d", &data);
if (hash[data] == 1)
{
return 1;
}
else
{
hash[data] = 1;
}
}
return 0;
}
1.2 本章学习体会
1.2.1 学习体会
- 在这一章的学习中,我学会了数组的使用方法,学会了将数据存入到数组中,但是数组这一章中的方法有很多,比如说冒泡排序,选择排序等等,有时候写代码时还是比较混乱。
- 数组在写的时候常常会因为for语句的条件而越界,或者是没有用
static初始化导致程序错误,输出一堆乱码。 - 这一章的PTA题目集比较多,难度也比较大,经常是一道题卡好几天,提交列表里一片绿╮(╯▽╰)╭,需要思考思考再思考,整理整理框架,有时候只是一个
\n或者数组的范围再大一些的小细节方面的错误,有时候却压根儿找不出错误点在哪里╭(°A°`)╮。 - VS里有很多语法,在数组中经常会出现错误,不知道应该怎么去调整,但是在Dev-C++里可以,希望老师可以告诉一下怎么弄?_?。
1.2.2 代码累计
我的代码量(不包括重复)
| 周 | 代码量(行) |
|---|---|
| 4 | 241 |
| 5 | 506 |
| 6 | 771 |
| 7 | 842 |
| 8 | 793 |
| 9 | 724 |
| 10 | 1980 |
| 11 | 983 |
| 12 | 879 |
| 累计 | 8702 |
2.PTA实验作业
2.1 题目名1
判断E-mail地址是否合法 (20 分)
输入一个字符串,判断是否是合法邮箱(格式正确即可,不管是否真的存在)输入的只能是字母、数字、下划线、@以及.五种, @前后只能是字母或者数字,而且.后只能是com, 是则输出YES ,否则输出NO。
2.1.1 伪代码
定义i,j
定义k来储存@的下标,m来储存.的下标
定义flag1,flag2,flag3,flag4来储存不同判断的结果
定义num来储存字符数量
定义字符数组str[]
定义len储存真实的数组长度
给flag1,flag2,flag3,flag4,num赋初值
用gets(str)来输入数组
用strlen函数来求出输入的数组的长度
for i = 0 to i < N,i++
{
for j = 0 to j < N,j++
{
if ((str[i] == '@') && (str[j] == '.'))
{
k来储存@的下标,m来储存.的下标
for k = i to k < m,k++
{
if ((str[k] >= '0') && (str[k] <= '9') || (str[k] >= 'a') && (str[k] <= 'z') || (str[k] >= 'A') && (str[k] <= 'Z'))
{
flag1为1,即@前后只能是字母或者数字
}
}
}
}
}
if (str[len - 3] == 'c' && str[len - 2] == 'o' && str[len - 1] == 'm' && m == len - 4)
{
数组的长度的最后三位是com,倒数第四位是.,m是先前判断出来的.的下标,所以flag2为1,即.后只能是com
}
for i = 0 to i < N,i++
{
if ((str[i] >= '0') && (str[i] <= '9') || (str[i] >= 'a') && (str[i] <= 'z') || str[i] == '_' || str[i] == '@' || str[i] == '.')
{
如果str数组中输入的是字母或者数字或者下划线或者@或者.五种中的,则flag3=1
}
}
for i = 0 to i < len,i++
{
if (str[i] == ' ')
{
当检测到有空格时,flag4 = 0
break;
}
else
{
没有空格,则flag4 = 1;
}
}
if (flag1 == 1 && flag2 == 1 && flag3 == 1 && flag4 == 1)//前面四个条件都满足
{
输出YES
}
else
{
输出NO
}
2.1.2 代码截图



2.1.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| adf12@qw213.com | YES | 正常数据,样例 |
| 123qw 1@q.com | NO | 字符串中有空格 |
| 12q@w.com2 | NO | .com后有多余字符 |
| 12qwas.@com | NO | .@ |
| 142qht@.com | NO | @. |
| 654@@kjh.com | YES | @@ |
| 234jhs@uy..com | YES | .. |
| hgjh hg com | 引发异常 | 空格无@. |
| qw12 jhs.a.com | 引发异常 | 有空格多余的. |
| f12@qw213.com&*# | NO | 合法地址后有非法字符 |
2.1.4 PTA提交列表及说明
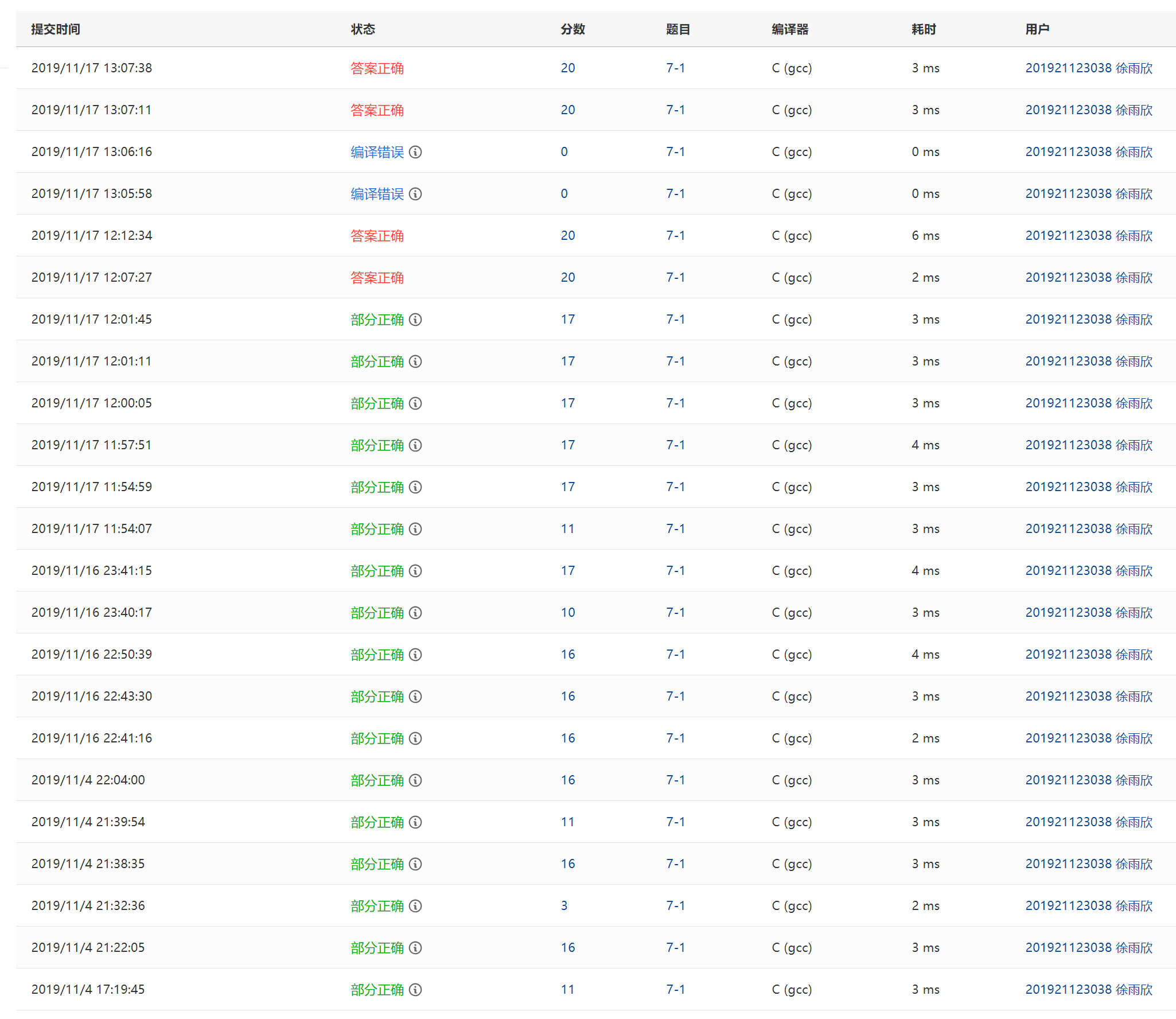
提交列表说明:
1. 部分正确:字母数字下划线.@和样例的测试点没有过
2. 部分正确:有关空格的测试点没有过,修改前用for循环输入数组,而当修改后用fgets语句,前面没有过的测试点过了,但是新出现了空格问题
3. 部分正确:判断@前后只能是字母或者数字时增加了flag4语句,使循环嵌套过多,运行超时
4. 部分正确:通过strlen的函数确认输入字符串的长度,然后再来判断数组的最后4位是不是.com,所以又一个测试点过了
5. 部分正确:测试点9,11,12,即有关空格的测试点一直过不了,我用for循环来判断是否有空格
6. 答案正确:当检测到有空格时就需要退出循环,所以要加break语句,否则flag4的值会一直变,刚开始写了这个for循环时没有想到这一点
7. 编译错误:写注释时发现n没有用,然后删除n的时候不小心把num也删了
8. 答案正确:完善注释,补回num
2.2 题目名2
阅览室 (20 分)
天梯图书阅览室请你编写一个简单的图书借阅统计程序。当读者借书时,管理员输入书号并按下S键,程序开始计时;当读者还书时,管理员输入书号并按下E键,程序结束计时。书号为不超过1000的正整数。当管理员将0作为书号输入时,表示一天工作结束,你的程序应输出当天的读者借书次数和平均阅读时间。
注意:由于线路偶尔会有故障,可能出现不完整的纪录,即只有S没有E,或者只有E没有S的纪录,系统应能自动忽略这种无效纪录。另外,题目保证书号是书的唯一标识,同一本书在任何时间区间内只可能被一位读者借阅。
2.2.1 数据处理
定义void函数AverageTime来统计借阅平均时间
定义n为天数
定义数组record[MAX][3],分为3列
定义number来存书号
定义hour存小时数
定义minute存分钟数
定义字符op储存E或S
定义i,j
定义k为数组行数
输入正整数n(n ≤ 10),代表给出n天的纪录
for i = 1 to i <= n,i++
{
给k赋初值
while(1)
{
输入数据按照number op hour:minute
if (number为0时)
{
break;
}
record数组第一列存number书号
record数组第二列存op是E还是S
通过hour * 60 + minute公式把时间转变为分钟的格式,record数组第三列来存时间
k++,行数增加
}
调用函数AverageTime
}
}
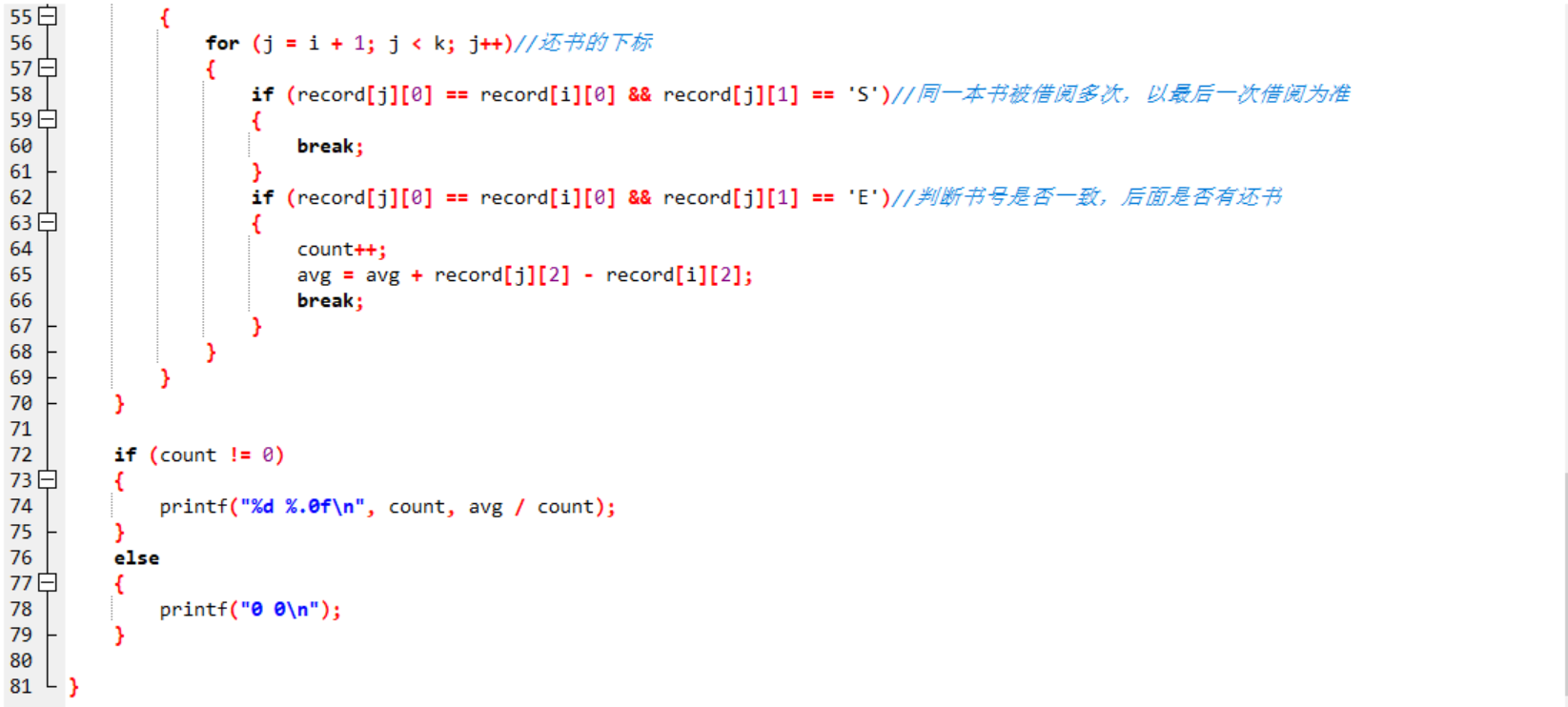
void AverageTime(int record[][3], int k)//统计借阅平均时间的函数
{
定义i,j
定义count统计借书次数
定义float型avg统计平均时间
给count赋初值
给avg赋初值
for i = 0 to i < k,i++
{
if (record[i][1] == 'S')//找到第i行中为S的
{
for j = i + 1 to j < k,j++
{
if (书号一致且是有借书记录)//同一本书被借阅多次,以最后一次借阅为准
{
break;
}
if (书号一致且有还书记录)//判断书号是否一致,后面是否有还书
{
借书次数count增加
算出总的时间avg
break;
}
}
}
}
if (count不为0,即这一天有借书)//防止除数为0
{
输出读者借书次数和平均阅读时间
}
else
{
否则这一天没有借书,输出0 0
}
}
2.2.2 代码截图


2.2.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
 |
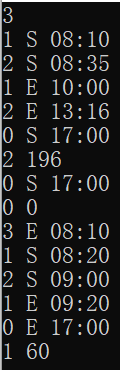 |
题目样例,有连续S和连续E |
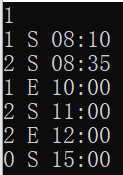 |
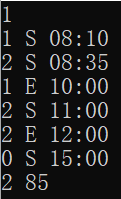 |
同一本书被借多次 |
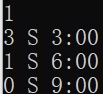 |
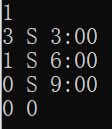 |
有不匹配 |
 |
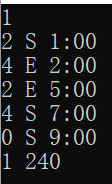 |
有S和E全反 |
2.2.4 PTA提交列表及说明
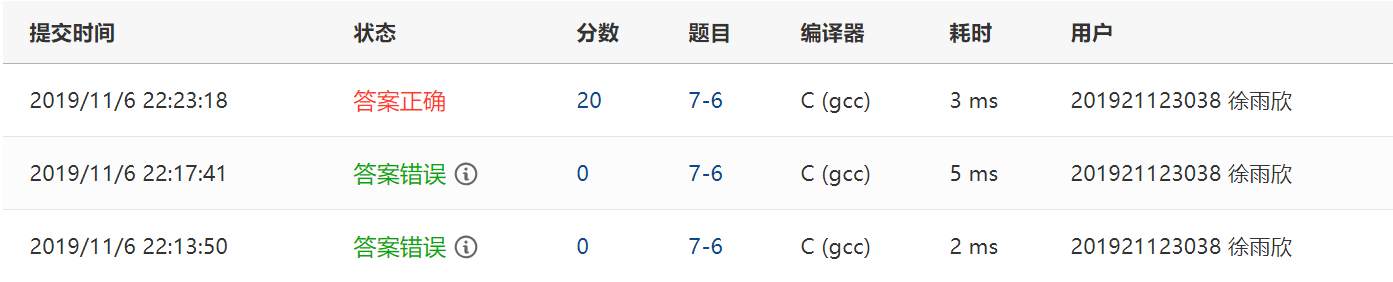
提交列表说明:
1. 答案错误:if语句中书号一致和借书还书这两个条件的关系由于粗心写成了或的关系
2. 答案正确:把代码细细读了一遍,改正了if语句中书号一致和借书还书这两个条件的关系为且的关系,这道题在课堂上老师让我们在课堂派的互动里写过想法,当时我是在想字符,但是时间不知道如何输入数组中,后来看了老师在超星平台上的视频,顿时觉得,emmm,明白了
2.3 题目名3
大数加法 (20 分)
输入2个大数,每个数的最高位数可达1000位,求2数的和。
2.3.1 数据处理
定义i,j
定义两个字符数组str1,str2来储存两个大数
定义len1,len2用来储存两个大数的长度
定义两个数组num1,num2来倒序存放两个大数
定义bit来储存大数之和的数组的最后一个下标
给i赋初值
给j赋初值
给bit赋初值
输入第一个大数str1
输入第二个大数str2
用strlen求第一个加数的位数,并且储存到len1中
用strlen求第二个加数的位数,并且储存到len2中
用strlen-1求两个大数之和的数组的最后一个下标,并且储存到bit中
if (bit < len2 - 1)//如果第二个大数的位数更多
{
bit变为更大的位数的下标
}
for i = len1 - 1 to i >= 0,i--
{
将第一个加数的字符数组转化为数字数组,并倒数存放
j++
}
j重新赋为0
for i = len2 - 1 to i >= 0,i--
{
将第二个加数的字符数组转化为数字数组,并倒数存放
j++;
}
for i = 0 to i <= 1000,i++
{
num1[i] = num1[i] + num2[i];
if (num1[i] > 9)//如果计算这一位的结果大于9,则需要进位
{
num1[i]减去10
且num1[i + 1]加1
}
}
if (num1[bit + 1] != 0)//根据同学告诉我的设置一个bit,记录位数,然后就可以了
{
输出num1[bit + 1]
}
for ; to bit >= 0,bit--
{
输出 num1[bit]
}
2.3.2 代码截图
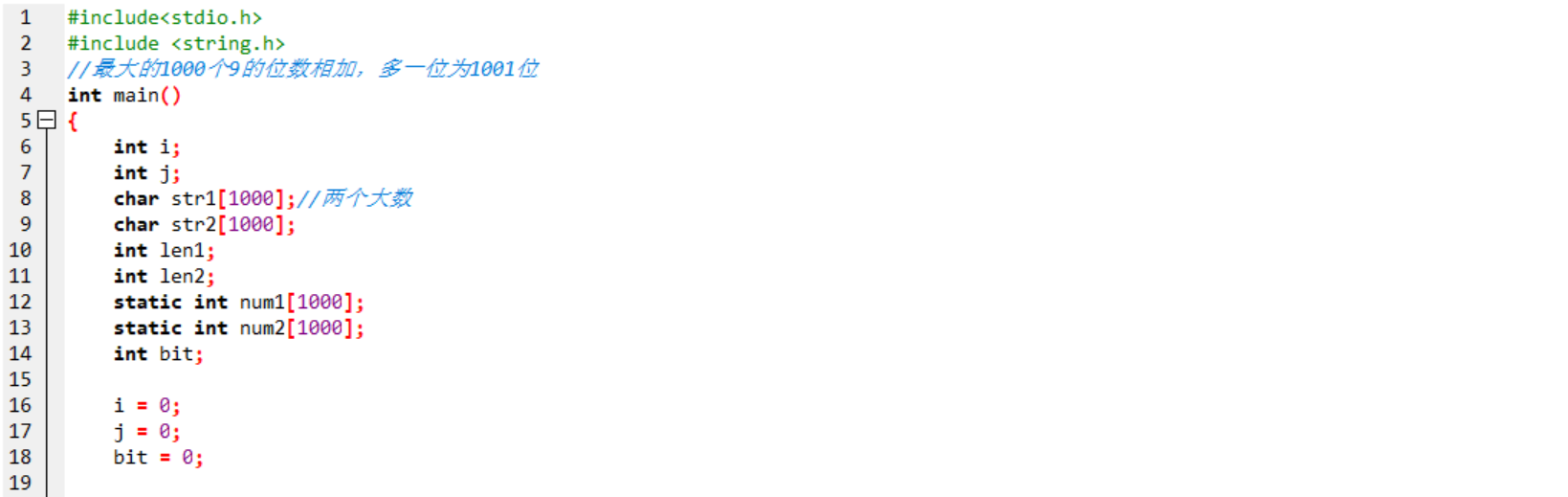



2.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 92345434336786876823540234787293542423 | ||
| 13343434323979878542919487294910345782 | 105688868660766755366459722082203888205 | 题目样例 |
| 123456 | ||
| 11111111 | 11234567 | 位数比较少 |
| 111111111111111111111111 | ||
| 111111111111111111 | 111111222222222222222222 | 最高位没进位 |
| 987654321 | ||
| 982345675 | 1969999996 | 最高位进位 |
| 4674892374353728743754765893921834783570754608 | ||
| 82172756576748748291948957658548784898384728357438 | 82177431469123102020692712424442706733168299112046 | 位数比较多 |
| 9999 | ||
| 99999 | 109998 | 最高位进位 |
2.3.4 PTA提交列表及说明
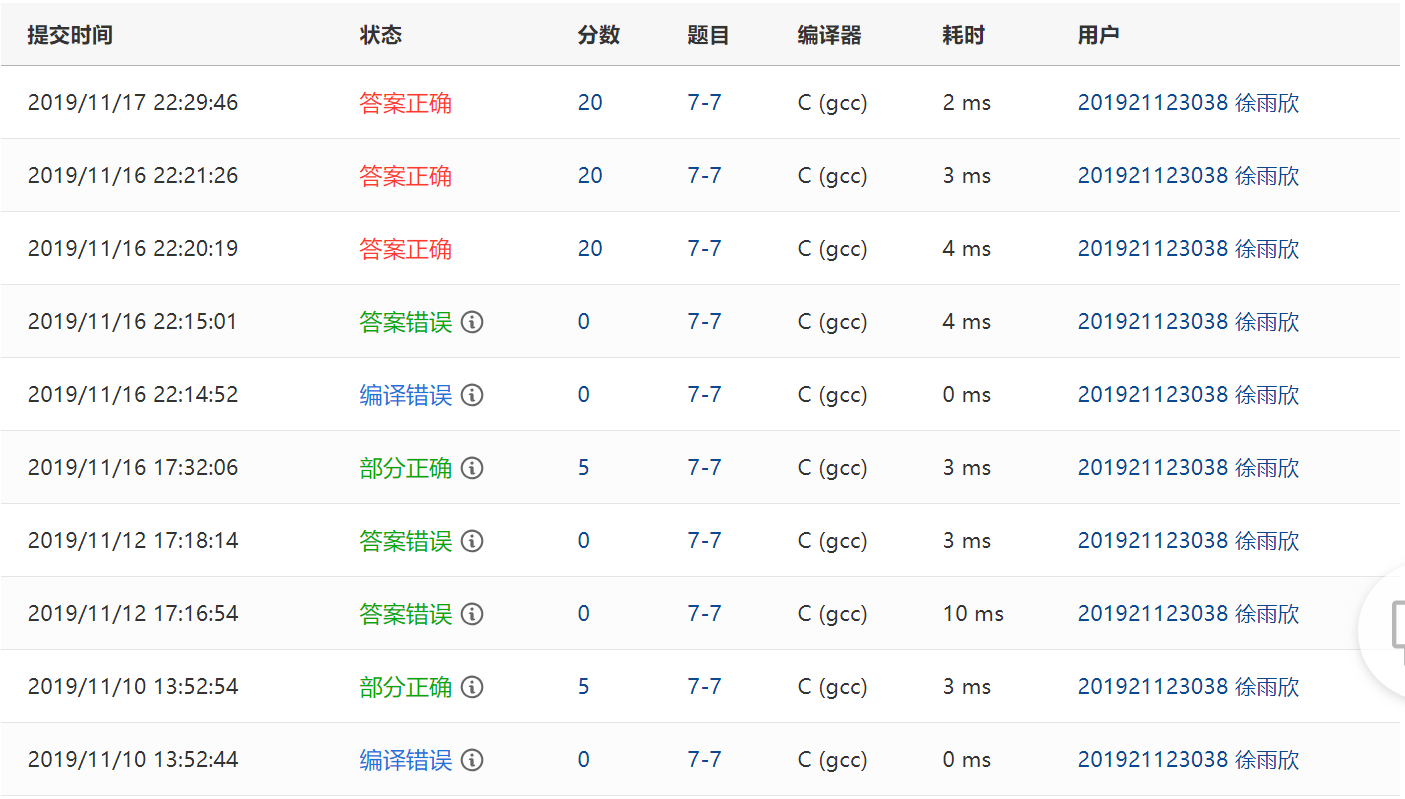
提交列表说明:
1. 编译错误:gets在VS上应该用gets_s,在复制到PTA上时没有改成gets
2. 部分正确:最高位没进位正确
3. 答案错误:总是前面会少一位或者后面少
4. 答案错误:修正后算出的结果正确了,但是前面会有一堆0
5. 答案正确:根据同学告诉我的设置一个bit,记录位数,然后就可以了
3.阅读代码
题目:ACM 题库题解大全> poj 2635 The Embarrassed Cryptographer
题目截图
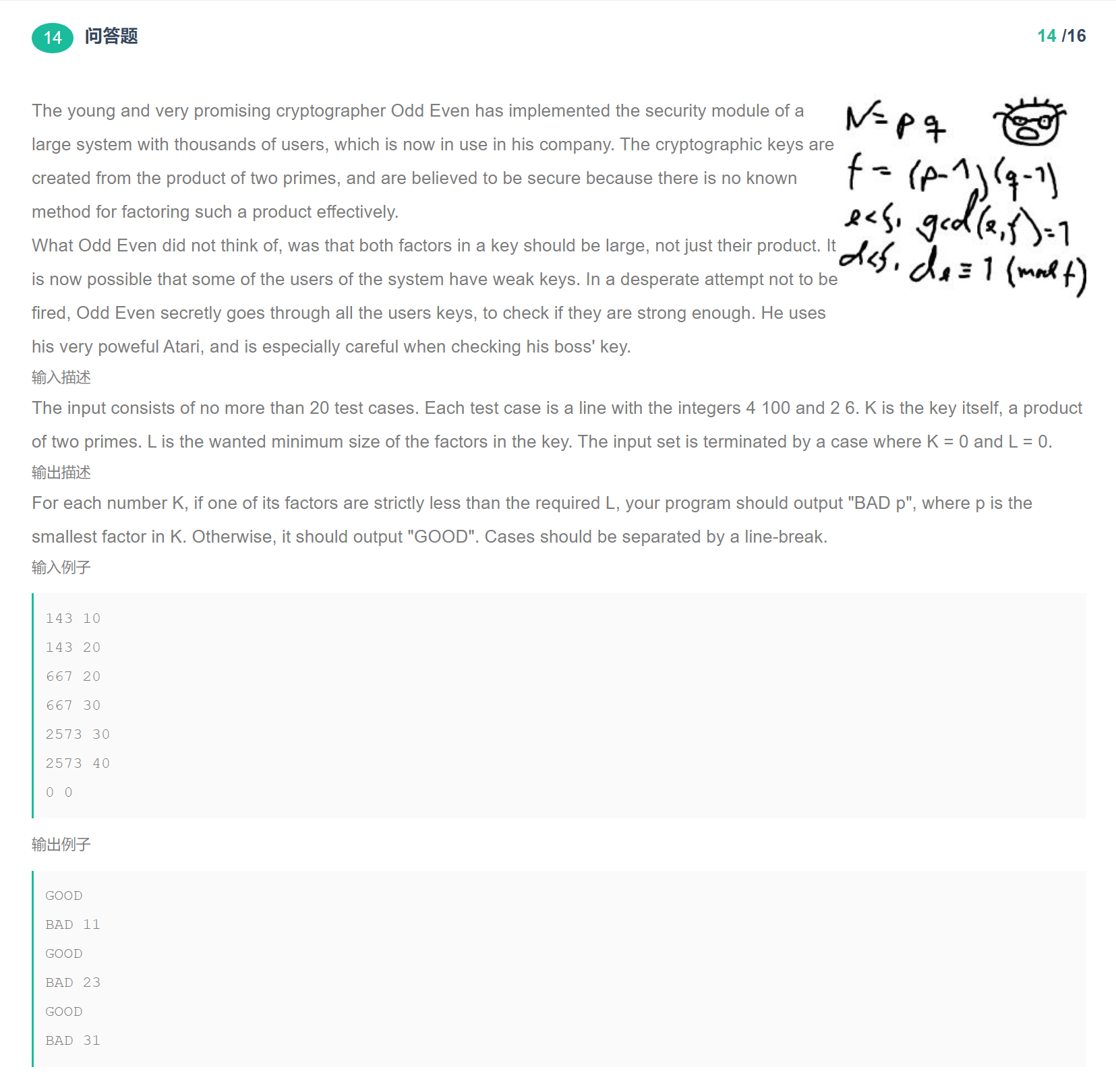
题目翻译

答案示例

代码功能
输入str数组和L,先判断出数组中的数是哪两个素数的乘积,然后再判断其中一个因子严格小于所需的L,则程序应输出“BAD p”,p是其中的最小因子,否则,程序应输出“GOOD”。
代码优点
1. 分装函数的数量多,每个函数都有不同的作用
2. Check函数在不同的结果下返回了两个值
3. 条件语句和循环语句运用熟练
4. 运用strlen()函数求数组长度,sizeof()函数求字节数
5. 逻辑思维很强,值得学习
缺月挂疏桐,漏断人初静。时见幽人独往来,缥缈孤鸿影。
惊起却回头,有恨无人省。拣尽寒枝不肯栖,寂寞沙洲冷。
