



linux查看文件的编码格式的方法 set fileencoding
乱码原因:
因为你的文件声明为utf-8,并且也应该是用utf-8的编码保存的源文件。但是windows的本地默认编码是cp936,也就是gbk编码,所以在控制台
直接打印utf-8的字符串当然是乱码了。
解决方法:
在控制台打印的地方用一个转码就ok了,打印的时候这么写:
print myname.decode('UTF-8').encode('GBK')
比较通用的方法应该是:
import sys
type = sys.getfilesystemencoding()
print myname.decode('UTF-8').encode(type)
最近利用python抓取一些网上的数据,遇到了编码的问题。非常头痛,总结一下用到的解决方案。
- linux中vim下查看文件编码的命令 set fileencoding
- python中一个强力的编码检测包 chardet ,使用方法非常简单。linux下利用pip install chardet实现简单安装
|
1
2
3
4
|
import chardetf = open ( 'file' , 'r' )fencoding = chardet.detect(f.read())print fencoding |
fencoding输出格式 {'confidence': 0.96630842899499614, 'encoding': 'GB2312'} ,只能判断是否为某种编码的概率。比较准确的结果了。输入参数为str类型。
- 了解python中str的编码后可以利用decode和encode来实现编码的转换。
一般流程是str利用decode方法根据str的编码将其解码为unicode字符串类型,然后利用encode根据特定的编码将unicode字符串类型转换为特定的编码。python中str和unicode属于两种不同的类型,如下。
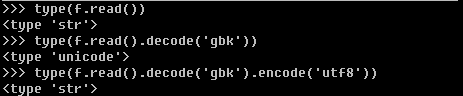
- 一般情况下window默认编码gbk,linux默认编码utf8
- python编程中 系统编码,python编码,文件编码 的概念。
系统编码:默认写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流。存入到磁盘中的。linux下通过locale命令查看。
python编码:指python内设置的解码方式。如果不设定的话,python默认的是ascii解码方式。如果python源代码文件中不出现中文的话,这个地方怎么设定应该不会问题。
设定方法:在源码文件开头(一定是第一行):#-*-coding:UTF-8-*-,源码文件的设置解码方式是UTF-8 或者
|
1
2
3
|
import sysreload (sys)sys.setdefaultencoding( 'UTF-8' ) |
文件编码:文本的编码方式,linux下vim利用set fileencoding查看。
- 一般情况下输出乱码的原因就是 没有按照系统解码的方式进行编码。
比如print s, s类型为str,linux系统下系统默认编码为utf8编码,s在输出前就应该编码为utf8。如果s为gbk编码就应该这样输出。print s.decode('gbk').encode('utf8')才能输出中文。
window下面情况相同,window默认编码为gbk编码,所以s输出前必须编码为gbk。
- python处理中一般处理unicode类型。这样输出前直接编码即可。
原文:https://www.cnblogs.com/klb561/p/11241664.html
linux查看文件的编码格式的方法 set fileencoding
查看文件编码
在Linux中查看文件编码可以通过以下几种方式:
1.在Vim中 可以直接查看文件编码
:set fileencoding
即可显示文件编码格式。
如果你只是想查看其它编码格式的文件或者想解决 用Vim查看文件乱码的问题,那么你可以在
~/.vimrc 文件中添加以下内容:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
这样,就可以让vim自动识别文件编码(可以自动识别UTF-8或 者GBK编码的文件),其实就是依照fileencodings提供的编码列表尝试,如果没有找到合适 的编码,就用latin-1(ASCII)编码打开。
2. enca (如果你的系统中没有安装这个命令,可以用sudo yum install -y enca 安装 )查看文件编码
$ enca filename
filename: Universal transformation format 8 bits; UTF-8
CRLF line terminators
需要说明一点的是,enca对某些GBK编码的文件识别的不是很好,识别时会出现:
Unrecognized encoding
文件编码转换
1.在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式
:set fileencoding=utf-8
2. enconv 转换文件编码,比如要将一个GBK编码的文件转换成UTF-8编码,操作如下
enconv -L zh_CN -x UTF-8 filename
3. iconv 转换,iconv的命令格式如下:
iconv -f encoding -t encoding inputfile
比如将一个UTF-8 编码的文件转换成GBK编码
iconv -f GBK -t UTF-8 file1 -o file2
本文地址:http://www.yaronspace.cn/blog/index.php/archives/523
乱码原因:
因为你的文件声明为utf-8,并且也应该是用utf-8的编码保存的源文件。但是windows的本地默认编码是cp936,也就是gbk编码,所以在控制台
直接打印utf-8的字符串当然是乱码了。
解决方法:
在控制台打印的地方用一个转码就ok了,打印的时候这么写:
print myname.decode('UTF-8').encode('GBK')
比较通用的方法应该是:
import sys
type = sys.getfilesystemencoding()
print myname.decode('UTF-8').encode(type)
最近利用python抓取一些网上的数据,遇到了编码的问题。非常头痛,总结一下用到的解决方案。
- linux中vim下查看文件编码的命令 set fileencoding
- python中一个强力的编码检测包 chardet ,使用方法非常简单。linux下利用pip install chardet实现简单安装
|
1
2
3
4
|
import chardetf = open ( 'file' , 'r' )fencoding = chardet.detect(f.read())print fencoding |
fencoding输出格式 {'confidence': 0.96630842899499614, 'encoding': 'GB2312'} ,只能判断是否为某种编码的概率。比较准确的结果了。输入参数为str类型。
- 了解python中str的编码后可以利用decode和encode来实现编码的转换。
一般流程是str利用decode方法根据str的编码将其解码为unicode字符串类型,然后利用encode根据特定的编码将unicode字符串类型转换为特定的编码。python中str和unicode属于两种不同的类型,如下。
- 一般情况下window默认编码gbk,linux默认编码utf8
- python编程中 系统编码,python编码,文件编码 的概念。
系统编码:默认写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流。存入到磁盘中的。linux下通过locale命令查看。
python编码:指python内设置的解码方式。如果不设定的话,python默认的是ascii解码方式。如果python源代码文件中不出现中文的话,这个地方怎么设定应该不会问题。
设定方法:在源码文件开头(一定是第一行):#-*-coding:UTF-8-*-,源码文件的设置解码方式是UTF-8 或者
|
1
2
3
|
import sysreload (sys)sys.setdefaultencoding( 'UTF-8' ) |
文件编码:文本的编码方式,linux下vim利用set fileencoding查看。
- 一般情况下输出乱码的原因就是 没有按照系统解码的方式进行编码。
比如print s, s类型为str,linux系统下系统默认编码为utf8编码,s在输出前就应该编码为utf8。如果s为gbk编码就应该这样输出。print s.decode('gbk').encode('utf8')才能输出中文。
window下面情况相同,window默认编码为gbk编码,所以s输出前必须编码为gbk。
- python处理中一般处理unicode类型。这样输出前直接编码即可。
转1. http://blog.sina.com.cn/s/blog_40e1ba640102wm26.html
2.http://www.cnblogs.com/joeyupdo/archive/2013/03/03/2941737.html
以下为copy链接2中的介绍
(1)encoding: Vim 内部使用的字符编码方式,包括 Vim 的 buffer (缓冲区)、菜单文本、消息文本等。用户手册上建议只在 .vimrc 中改变它的值,事实上似乎也只有在 .vimrc 中改变它的值才有意义
(2)fileencoding: Vim 中当前编辑的文件的字符编码方式,Vim 保存文件时也会将文件保存为这种字符编码方式 (不管是否新文件都如此),网上是这样介绍的,但是我这样做在.vimrc中定义为utf-8似乎没有作用,只能在打开vim文件时手动设置才会起效,不知道什么原因。
(3)fileencodings: Vim 启动时会按照它所列出的字符编码方式逐一探测即将打开的文件的字符编码方式,并且将 fileencoding 设置为最终探测到的字符编码方式。因此最好将 Unicode 编码方式放到这个列表的最前面,将拉丁语系编码方式 latin1 放到最后面。
(4)termencoding: Vim 所工作的终端 (或者 Windows 的 Console 窗口) 的字符编码方式。这个选项在 Windows 下对我们常用的 GUI 模式的 gVim 无效,而对 Console 模式的 Vim 而言就是 Windows 控制台的代码页,并且通常我们不需要改变它。
系统locale是utf-8(很多linux系统默认的locale形式),编辑的文档是GB2312或GBK形式的(Windows记事本
默认保存形式,大部分编辑器也默认保存为这个形式,所以最常见),终端类型utf-8(也就是假定客户端是putty类的unicode软件)
则vim打开文档后,encoding=utf-8(locale决定的),fileencoding=latin1(自动编码判断机制不准导致的),termencoding=空(默认无需转换term编码),显示文件为乱码。
解决方案1:首先要修正fileencoding为cp936或者euc-cn(二者一样的,只不过叫法不同),注意修正的方法不是:set
fileencoding=cp936,这只是将文件保存为cp936,正确的方法是重新以cp936的编码方式加载文件为:edit
++enc=cp936,可以简写为:e ++enc=cp936。
但是这样做,文件关闭后重新打开又要重新设置一遍。出现乱码归根结底的原因是vim不能识别该文件的编码方式,导致不能正常解码(不知道是不是叫解码,我的理解)。所以,我在.vimrc中设置了fileencodings,相当于告诉vim当以utf-8解码文件不成功时以这么几种方式尝试,set fileencoding=utf-8 set fileencodings=ucs-bom,utf-8,cp936,latin1. 这样打开正常了
原文:https://www.cnblogs.com/klb561/p/11241664.html

