
声明:本文版权归作者和博客园共有,欢迎转载。但必须保留此段声明,且在文章页面明显位置给出原文连接
正则表达式(Regular Expression,通常简写为Regex或RE),又称规则表达式。
正则表达式是对字符串进行过滤的一种公式,主要由具有特定意义的字符组成。我们一般把这种特定意义的字符称为元字符。正则表达式通常被用来检索或替换符合某个规则的文本。
那么常见的元字符有哪些呢?在我这里把常见的元字符归为以下几组:
第一组:格式组(匹配换行、回车等格式类符号)
| 元字符 | 解释说明 |
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \t | 匹配制表符 |
| \f | 匹配换页符 |
比如替换掉下面中的换行符:
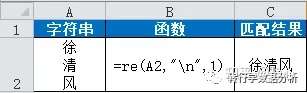
第二组:叫板组(你说A,我就偏不说A)
| 元字符 | 解释说明 |
| \n | 匹配换行符 |
| . | 匹配除换行符外的任意字符 |
| \s | 匹配任何空白字符 |
| \S | 匹配任何非空白字符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配除字母、数字、下划线以外的任意字符 |
| \d | 匹配数字 |
| \D | 匹配除数字以外的任意字符 |
| [] | 匹配括号内的任意字符 |
| [0-9] | 匹配数字,等价于\d |
| [A-Za-z] | 匹配英文字母 |
| [\u4e00-\u9fa5] | 匹配汉字 |
| [^] | 匹配除^号后字符以外的任意字符 |
| [^abc] | 匹配除了abc以外的任意字符 |
当然他们之间也可以组合起来,比如其中的\s和\S组合起来:[\s\S],就是匹配所有字符,其他组类似。

第三组:限定组(限定匹配的次数)
| 元字符 | 解释说明 |
| * | 匹配前面元字符0次或多次 |
| + | 匹配前面元字符1次或多次 |
| ? | 匹配前面元字符0次或1次 |
| {m} | 匹配前面元字符m次 |
| {m,} | 匹配前面元字符至少m次 |
| {m,n} | 匹配前面元字符m到n次,包含m和n |
比如匹配4个数字:

第四组:位置组(表示符号的位置)
| 元字符 | 解释说明 |
| \b | 表示单词的开始或结尾位置(注意只表示位置,不代表任何字符) |
| \B | 表示非单词的开始或结尾位置(同上) |
| ^ | 表示字符串的开始位置(同上) |
| $ | 表示字符串的结尾位置(同上) |
比如匹配以0结尾的数据:

第五组:断言组(假设满足一定的条件)
| 元字符 | 解释说明 |
| (?=abc) | 匹配abc前面的字符 |
| (?<=abc) | 匹配abc后面的字符 |
| (?<!abc) | 匹配前面不是abc的字符 |
| (?!abc) | 匹配后面不是abc的字符 |
比如匹配abc的所有字符:

第六组:子表达式及其他组(和子表达式相关的,以及其他常用的元字符)
| 元字符 | 解释说明 |
| () | 通常表示一个完整的表达式(也叫做子表达式),可将匹配的内容保存下来,以供后续使用 |
| \1 | 引用前面第1个子表达式保存的文本,\2\3\4...同理 |
| | | 表示或的关系,比如a|b表示a或者b |
| \ | 转义字符,比如\\n表示匹配\n这个符号 |
比如删除下面字符中的重复项:

小测验
在EXCEL中使用正则表达式对字符串:“单芯片,双芯片,单芯片,双芯片,四芯片,单芯片”进行删除重复项:“双芯片,四芯片,单芯片”。(还不知道怎么在Excel里使用正则表达式请移步下方公众号)
欢迎大家在下方留言您的答案,当然,如果您对我的答案感兴趣,请在公众号后台回复:正则小测验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号