


1.日pv、日人均pv和日uv
import numpy as np
from pyecharts import Line, Overlap
pv_day = df[df.行为类型 == 'pv'].groupby('日期')['行为类型'].count()
uv_day = df[df.行为类型 == 'pv'].drop_duplicates(['用户ID','日期']).groupby('日期')['用户ID'].count()
attr = pv_day.index
v1 = pv_day.values
v2 = uv_day.values
line1 = Line('日pv、日人均pv和日uv对比图')
line1.add('日pv(单位:万次)', attr, np.around(v1/10000,decimals=2), mark_point=["max", "min"],
mark_line=['average'], legend_pos='right')
line1.add('日人均pv(单位:次)', attr, np.around(v1/v2, decimals=2), mark_point=['max','min'],
mark_line=['average'], yaxis_max=100, yaxis_name='pv', yaxis_name_pos='end',
yaxis_name_gap=15, legend_pos='right', legend_top='3%')
line2 = Line()
line2.add('日uv(单位:万人)', attr, np.around(v2/10000, decimals=2), mark_point=["max",'min'],
mark_line=['average'], yaxis_name='uv', yaxis_name_pos='end', yaxis_name_gap=15)
overlap = Overlap()
overlap.add(line1)
overlap.add(line2, is_add_yaxis=True, yaxis_index=1)
overlap.render()
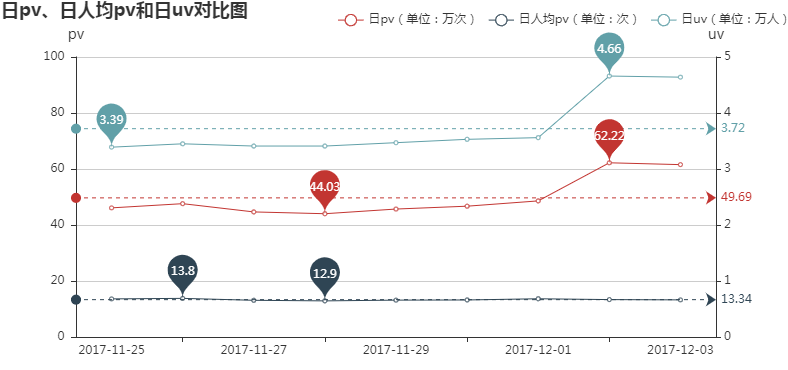
--日pv和日uv两者走势相类似,也进一步说明日人均pv波动较平缓,其平均水平为13.34;
--日pv和日uv均呈现上升趋势,且均在12月2日突然升高至九日内最高水平,而12月2日是周六,但11月25日也是周六,因此可能不是周末的原因,又由于12月2日距离双十一较近且多数人会在双十一购买近期所需物品,因此初步推测12月2日~3日的突然升高是因为商家进行促销、宣传推广等活动。
2.日新增uv和日新增uv的pv
from pyecharts import Bar, Line, Overlap
from copy import deepcopy
import datetime
df_pv = df[df.行为类型 == 'pv']
s = set()
days = []
nums = []
add_pv = []
for date in df_pv['日期'].unique():
num1 = len(s)
s1 = deepcopy(s)
ids = df_pv[df_pv.日期 == date]['用户ID'].values.tolist()
for i in ids:
s.add(i)
add_users = s - s1
add_users_pvs = df[(df.用户ID.isin(add_users)) & (df.行为类型 == 'pv')].groupby('日期', as_index=False)['行为类型'].count()
add_users_pv = int(add_users_pvs[add_users_pvs.日期 == date]['行为类型'].values)
num2 = len(s)
add_pv.append(add_users_pv)
days.append(date)
nums.append(num2-num1)
df_new_uv = pd.DataFrame({'日期': days, '新增访客数': nums, '新增访客的浏览量': add_pv})
attr = df_new_uv.日期
v = df_new_uv.新增访客数
w = df_new_uv.新增访客的浏览量
bar = Bar('日新增uv和日新增uv的pv对比图')
bar.add('日新增uv', attr, v, is_label_show=True, yaxis_formatter=" 人", legend_pos='right', legend_top='3%', label_pos='outside')
line = Line()
line.add('日新增uv的pv', attr, w, yaxis_formatter=" 次",is_label_show=True, yaxis_max=700000, label_pos='inside')
overlap = Overlap()
overlap.add(bar)
overlap.add(line, is_add_yaxis=True, yaxis_index=1)
overlap.render()
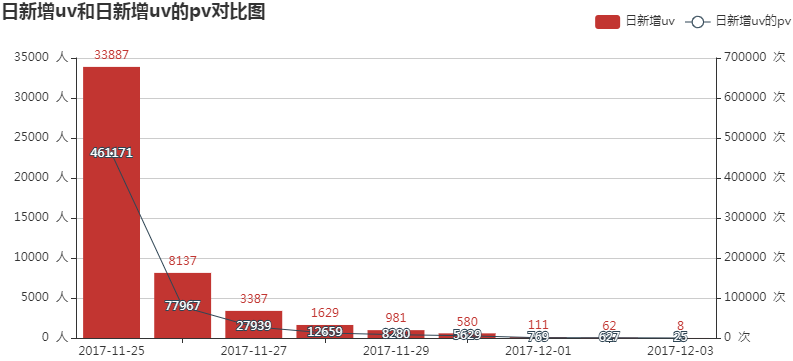
日新增uv和日新增uv的pv均呈现明显下降趋势,且在12月2日新增uv的人均pv为627/62=10.11(低于日人均pv的平均水平),说明日pv的突然升高不是由12月2日当日新增的uv带来的,而是由老uv带来的,另外,12月2日新增uv为62人,环比增长-0.44,从侧面反映了此次活动的目的可能不是拉新。
5.2 提高活跃度
1.时活跃用户数
hour_active = df.drop_duplicates(['用户ID', '小时']).groupby('小时')['用户ID'].count()
line = Line('时活跃用户折线图')
line.add('', hour_active.index, hour_active.values, mark_point=['max', 'min'],
mark_line=['average'], yaxis_formatter=' 人')
line.render()
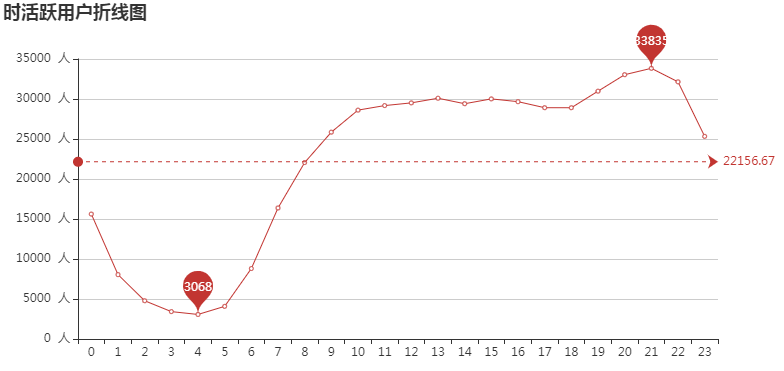
19时~22时为用户活跃高峰期, 而2时~5时则为用户活跃低峰期,可在用户活跃高峰期加大活动宣传力度。
2.日活跃用户数
day_active = df.drop_duplicates(['用户ID', '日期']).groupby('日期')['用户ID'].count()
day_active
line = Line('日活跃用户折线图')
line.add('', day_active.index, day_active.values, is_label_show=True, yaxis_formatter=' 人')
line.render()
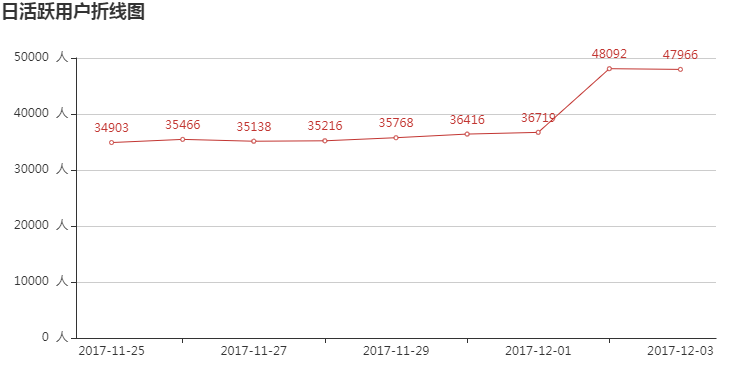
日活跃用户数呈现明显的增长趋势,且在12月2日取得最大值,说明此次活动的目的可能是促活。
5.3 提高留存率
from datetime import timedelta
def get_nday_retention_rate(df, n):
users2 = set()
days = []
nday_retentions = []
dates = df.日期.unique()[:-n]
for date in dates:
users1 = deepcopy(users2)
ids = df[df.日期 == date].用户ID.values.tolist()
for i in ids:
users2.add(i)
users = users2 - users1
nday_users = df[df.日期 == date + timedelta(days=n)].用户ID.unique()
counts = 0
for nday_user in nday_users:
if nday_user in users:
counts += 1
nday_retention_rate = counts / len(users)
nday_retentions.append(nday_retention_rate)
days.append(date)
df_retention_rate = pd.DataFrame({'日期': days, 'n日留存率': nday_retentions})
return df_retention_rate
retention_rate1 = get_nday_retention_rate(df, 1)
retention_rate2 = get_nday_retention_rate(df, 2)
retention_rate3 = get_nday_retention_rate(df, 3)
retention_rate4 = get_nday_retention_rate(df, 4)
retention_rate5 = get_nday_retention_rate(df, 5)
retention_rate6 = get_nday_retention_rate(df, 6)
retention_rate7 = get_nday_retention_rate(df, 7)
line = Line('留存率对比分析图')
line.add('7日留存', retention_rate7.日期, retention_rate7.n日留存率)
line.add('6日留存', retention_rate6.日期, retention_rate6.n日留存率)
line.add('5日留存', retention_rate5.日期, retention_rate5.n日留存率)
line.add('4日留存', retention_rate4.日期, retention_rate4.n日留存率)
line.add('3日留存', retention_rate3.日期, retention_rate3.n日留存率)
line.add('2日留存', retention_rate2.日期, retention_rate2.n日留存率)
line.add('次日留存', retention_rate1.日期, retention_rate1.n日留存率, legend_pos='right')
line.render()
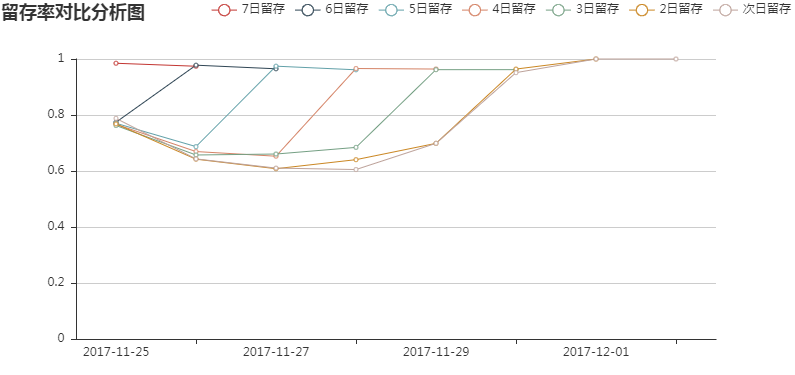
--就时间窗口来说,次日留存和3日留存均表现出先减后增的趋势,而7日留存则相比之前略有减少;
--就某一天来说,11月25日新增的活跃用户3日留存<次日留存<7日留存,11月26日新增的活跃用户次日留存<3日留存<7日留存,且其他日期3日留存均大于次日留存。
总体来说,留存呈现增长的趋势,反映出用户粘性在上升。
5.4 获取营收
1.时购买行为
hour_buy_user_num = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '小时']).groupby('小时')['用户ID'].count()
hour_active_user_num = df.drop_duplicates(['用户ID', '小时']).groupby('小时')['用户ID'].count()
hour_buy_rate = hour_buy_user_num / hour_active_user_num
attr = hour_buy_user_num.index
v1 = hour_buy_user_num.values
v2 = hour_buy_rate.values
line1 = Line('时购买行为分析')
line1.add('购买人数', attr, v1, mark_point=['max', 'min'], yaxis_formatter=' 人')
line2 = Line()
line2.add('购买率', attr, np.around(v2, 3), mark_point=['max', 'min'])
overlap = Overlap()
overlap.add(line1)
overlap.add(line2, is_add_yaxis=True, yaxis_index=1)
overlap.render()
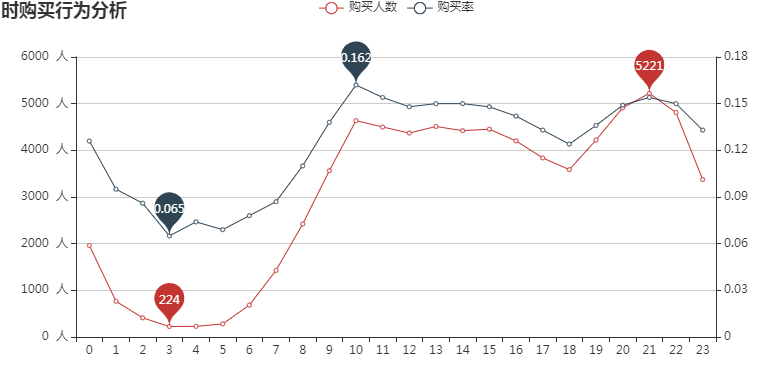
购买人数和购买率的走势大致相似,且均呈现明显的双峰走势,其中21时购买人数最多,而10时购买率最高,应当继续保持10时的活动,加大21时的活动力度。
2.日购买行为
day_buy_user_num = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '日期']).groupby('日期')['用户ID'].count()
day_active_user_num = df.drop_duplicates(['用户ID', '日期']).groupby('日期')['用户ID'].count()
day_buy_rate = day_buy_user_num / day_active_user_num
attr = day_buy_user_num.index
v1 = day_buy_user_num.values
v2 = day_buy_rate.values
line1 = Line('日购买行为分析')
line1.add('购买人数', attr, v1, mark_point=['max', 'min'], yaxis_formatter=' 人')
line2 = Line()
line2.add('购买率', attr, np.around(v2, 3), mark_point=['max', 'min'])
overlap = Overlap()
overlap.add(line1)
overlap.add(line2, is_add_yaxis=True, yaxis_index=1)
overlap.render()
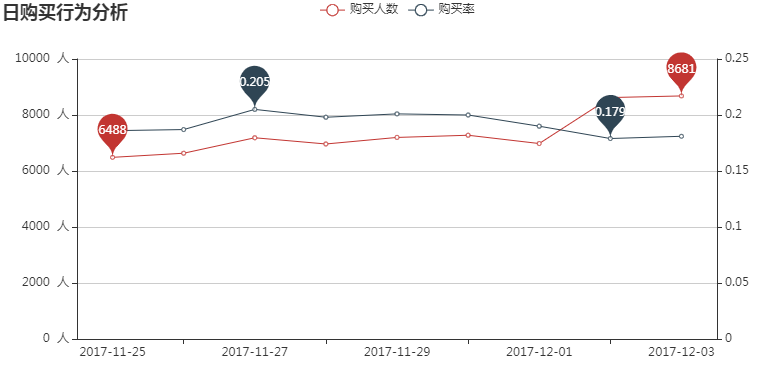
在12月1日之前,购买人数和购买率走势相类似,而在12月1日之后购买人数有所增加,但与之前相比购买率却在减少,商家应当优化产品本身并加大宣传推广。
3.九日复购率
df_rebuy = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '时间戳']).groupby('用户ID')['时间戳'].count()
df_rebuy[df_rebuy >= 2].count() / df_rebuy.count()
0.6323078771856036
如果以0.6作为合格标准的话,说明用户忠诚度表现一般,有大幅增长空间。
4.三日复购率和回购率
#计算复购率
for m, n in zip(range(1, 10), df.日期.unique()):
if m % 3 == 0:
df.loc[(df.日期 + timedelta(days=0) <= n) & (df.日期 + timedelta(days=2) >= n), '日期1'] = n
df.日期1.unique()
df_rebuy = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '时间戳']).groupby(['日期1', '用户ID'], as_index=False)['行为类型'].count()
df_rebuy_rate = df_rebuy[df_rebuy.行为类型 >= 2].groupby('日期1')['用户ID'].count() / df_rebuy.groupby('日期1')['用户ID'].count()
#计算回购率
days = []
back_buy_rates = []
for i in range(0, 2):
df_buy_users = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '时间戳']).groupby(['日期1'])['用户ID'].unique()
users_id = df_buy_users[i]
counts = 0
for user in users_id:
if user in df_buy_users[i+1]:
counts += 1
df_back_buy_rate = counts / len(df_buy_users[i])
back_buy_rates.append(df_back_buy_rate)
days.append(df_buy_users.index[i])
df_back_buy = pd.DataFrame({'日期': days, '回购率': back_buy_rates})
#绘制折线图
line = Line('用户每三日复购和回购行为分析')
line.add('回购率', df_back_buy.日期, np.around(df_back_buy.回购率, 3), is_label_show=True)
line.add('复购率', df_rebuy_rate.index, np.around(df_rebuy_rate.values, 3), is_label_show=True)
line.render()
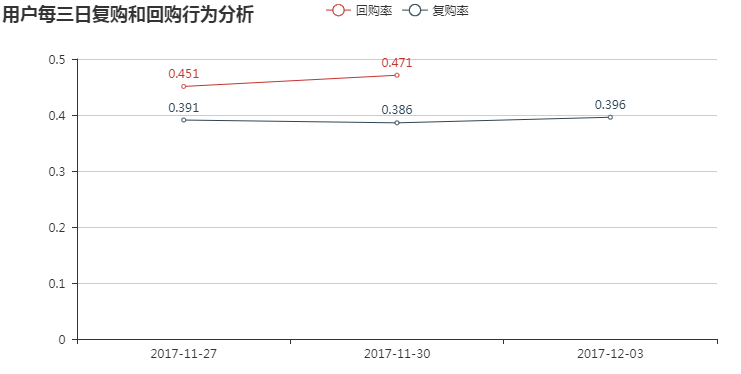
--用户回购率整体高于复购率,其波动性也明显强于复购率;
--用户复购率呈现先减后增的趋势,而用户回购率则是增加趋势 , 即第二周期购买用户的忠诚度较第一期高,整体说明用户忠诚度在增加。
6. 转化漏斗模型分析
from pyecharts import Funnel
pv_users = df[df.行为类型 == 'pv']['用户ID'].count()
fav_users = df[df.行为类型 == 'fav']['用户ID'].count()
cart_users = df[df.行为类型 == 'cart']['用户ID'].count()
buy_users = df[df.行为类型 == 'buy']['用户ID'].count()
attr = ['点击', '加入购物车', '收藏', '购买']
values = [np.around((pv_users / pv_users * 100), 2),
np.around((cart_users / pv_users * 100), 2),
np.around((fav_users / pv_users * 100), 2),
np.around((buy_users / pv_users * 100), 2)]
funnel = Funnel("用户行为转化漏斗", title_pos='center')#width=600, height=400,
funnel.add(
"",
attr,
values,
is_label_show=True,
label_formatter = '{b} {c}%',
label_pos="outside",
is_legend_show = False,
)
funnel.render()
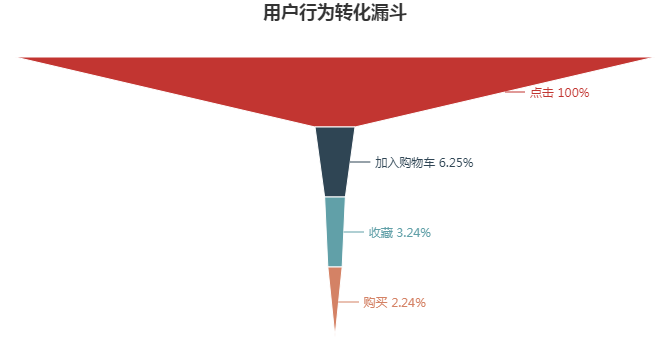
--总的点击量中,有6.25%加入购物车,有3.24%收藏,而到最后只有2.24%购买,整体来看,购买的转化率最低,有很大的增长空间;
--就颜色来看,红色部分的变化最大,即“点击-加入购物车“这一环节的转化率最低,按照“点击-加入购物车-收藏-购买”这一用户行为路径,我们可通过优化“点击-加入购物车”这一环节进而提升购买的转化率。
7. RF模型分析
R:Recency(最近一次消费),F:Frequency(消费频次),M:Monetary(消费金额)
由于我们的数据集中没有消费金额相关数据,因此这里就R和F对客户价值进行分析
from datetime import date
nowdate = date(2017, 12, 5)
recent_buy_date = df[df.行为类型 == 'buy'].groupby('用户ID')['日期'].apply(lambda x: x.sort_values().iloc[-1])
recent_buy_time = (nowdate - recent_buy_date).map(lambda x: x.days)
fre_buy = df[df.行为类型 == 'buy'].drop_duplicates(['用户ID', '时间戳']).groupby('用户ID')['日期'].count()
rf_module = pd.DataFrame({'用户ID': recent_buy_time.index,
'recency': recent_buy_time.values,
'frequency': fre_buy.values})
rf_module['recency_avg'] = rf_module.recency.mean()
rf_module['frequency_avg'] = rf_module.frequency.mean()
rf_module.to_excel(r'E:\Data\data2.xlsx')
保存至Excel文件,然后通过Tableau绘制波士顿矩阵如下所示:
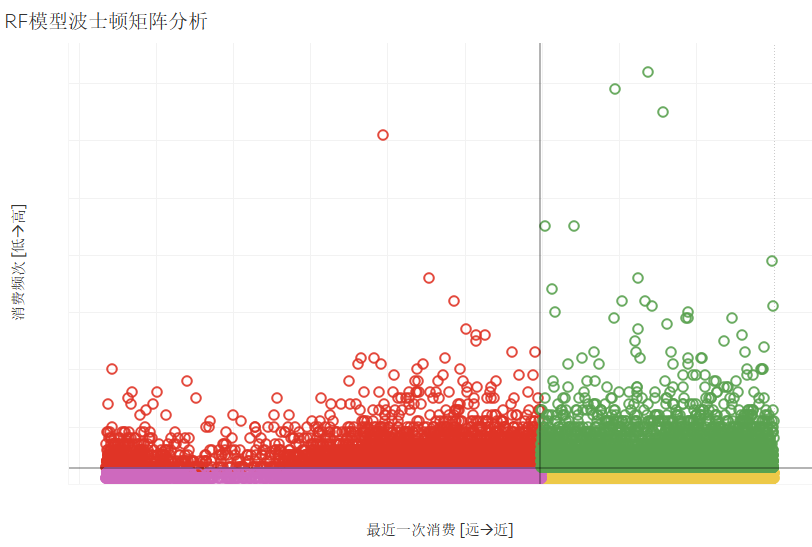
--第一象限(重要价值用户):该象限用户消费频次高、最近一次消费近,应当继续保持并给予支持;
--第二象限(重点保持用户):该象限用户消费频次高、最近一次消费远,可通过电话、短信等方式主动联系促进最近消费;
--第三象限(重点挽留用户):该象限用户消费频次低、最近一次消费远,可通过赠送礼品、加大折扣等方式进行挽回;
--第四象限(重点发展用户):该象限用户消费频次低、最近一次消费近,可通过发放优惠券、捆绑销售等方式增加用户购买频次。
总结
-
对比12月2日~12月3日与上一个周末的日pv、日uv和日活跃用户数,均发现有明显的上升趋势,且上升均是由老用户带来的,反映出老用户忠诚度表现不错,同时也说明了这两天的促活活动产生了效果;
-
在每天的19时22时为用户活跃高峰期,购买人数也最多,购买率略低;而在10时用户活跃度较低,购买人数也略低,但用户购买率却最高,因此就购买率来说,10时活跃用户产生的价值较高,应当对10时活跃用户的活动力度继续保持并给予支持,重点发展1922时的活跃用户。
-
在“点击-加入购物车-收藏-购买”转化漏斗中:就整体来说,购买转化率为2.24%表现最差,有很大的增长空间;就各环节来说,“点击-加入购物车”环节的转化率为6.25%表现最低,可以通过优化这一环节的转化率,来提升整体的购买转化率。
-
商家可根据RF模型的分析结果,对不同群体的用户进行精准营销,达到利益最大化。
以上便是我本次分享的内容,如有任何疑问,请在下方留言,或在公众号【转行学数据分析】联系我!!!

