环境
软硬件环境
硬件环境:
浪潮英信服务器NF570M3两台,华为OceanStor 18500存储一台,以太网交换机两台,光纤交换机两台。
软件环境:
操作系统:Redhat Enterprise Linux 6.7 x64
集群环境:RHCS
数据库:Oracle 11g R2
多路径软件:UltraPath for Linux
存储划分
| 类型 | 卷 | 大小 | 挂载点 | 用途 | 备注 |
| 内置硬盘 | 标准 | 500MB | /boot | 启动分区 |
两块内置硬盘作RAID1 |
| LVM | 20GB | /home | 用户分区 | ||
| 20GB | /var | 日志分区 | |||
| 20GB | /opt | 应用分区 | |||
| 32GB | N/A | SWAP分区 | |||
| 500GB | / | 根分区 | |||
| 共享存储 | LUN | 500GB | /oradata | 数据库数据区 | SAN存储分配一个500GB的LUN |
网络规划
| 主机名 | IP | 网口 | 用途 | 备注 |
| ZHXYHDB01 | 35.1.1.250 | bond0(eth0、eth2) | 业务IP |
心跳IP和Fence IP应在同一网段; 通常业务IP和此二者不在同一网段; |
| 50.3.1.200 | bond1(eth1、eth3) | 心跳IP | ||
| 50.3.1.202 | MGMT | Fence IP | ||
| ZHXYHDB02 | 35.1.1.251 | bond0(eth0、eth2) | 业务IP | |
| 50.3.1.201 | bond1(eth1、eth3) | 心跳IP | ||
| 50.3.1.203 | MGMT | Fence IP | ||
| 35.1.1.245 | 集群VIP |
集群拓扑

系统预配置
系统安装(略)
存储识别
已在华为OceanStor存储上为本项目分配了500GB LUN,只需在两台服务器上分别安装华为OceanStor UltraPath多路径软件,重启后即可正确识别存储裸设备。
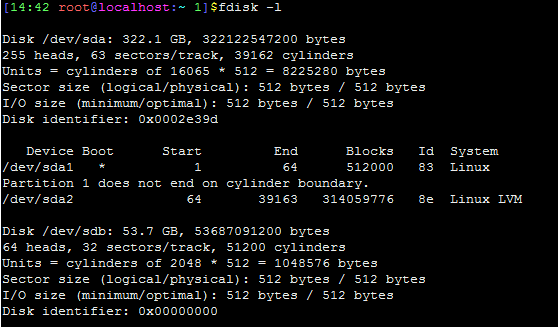
/dev/sdb即为识别到的共享存储,在两台服务器上均正确识别存储后,利用此共享存储空间创建LVM逻辑卷组和逻辑卷。以下操作均在其中一台服务器上进行:
1、使用fdisk对/dev/sdb新建磁盘分区sdb1(使用全部500GB共享存储空间):
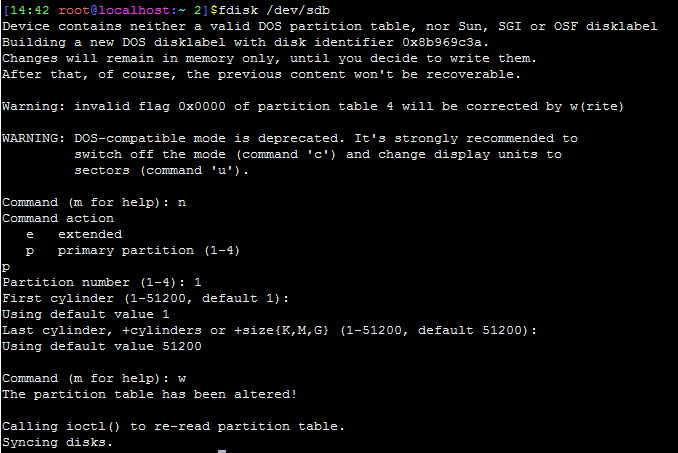
2、将其格式化为ext4文件系统格式:
# mkfs.ext4 /dev/sdb1
在两台服务器上分别创建/oradata目录,用于挂载共享存储,作为数据库数据区,修改该目录权限:
# mkdir /oradata
# chown oracle:oinstall /oradata
网络配置
网络配置需按照网络规划表在两台服务器上分别配置,正式配置前先关闭NetworkManager服务:
# service networkmanager stop
# chkconfig networkmanager off
业务IP和心跳IP均作网卡绑定,业务IP配置网关,心跳IP不配网关。在/etc/sysconfig/network-scripts目录下新建ifcfg-bond0和ifcfg-bond1,以业务IP配置为例,网卡绑定配置如下:
ifcfg-bond0:
DEVICE=bond0 NAME=bond0 BOOTPROTO=none ONBOOT=yes TYPE=Ethernet IPADDR=35.1.1.250 NETMASK=255.255.255.0 GATEWAY=35.1.1.1 #如果是心跳IP则不能配置此行 BONDING_OPTS="miimon=100 mode=1"
ifcfg-eth0:
DEVICE=eth0 TYPE=Ethernet ONBOOT=yes BOOTPROTO=none SLAVE=yes MASTER=bond0
ifcfg-eth2:
DEVICE=eth2 TYPE=Ethernet ONBOOT=yes BOOTPROTO=none SLAVE=yes MASTER=bond0
然后在/etc/modprobe.d/目录下新建bonding.conf文件,加入如下内容:
alias bond0 bonding
alias bond1 bonding
关闭NetworkManager服务,重启network服务:
# service NetworkManager stop
# chkconfig NetworkManager off
# service network restart
HA集群所需的Fence设备在本项目中可以直接使用浪潮服务器自带的IPMI,即MGMT管理口的服务器管理系统。Fence IP的配置需要重启服务器,进入BIOS中的Advance选项的IPMI或者BMC项中配置,此处建议配置网关。同样需要在两台服务器上分别配置。
检查网络是否调通,在两台服务器上分别ping 110.1.5.1网关、110.1.5.61--110.1.5.66的全部地址以及需要连通的其他网段地址。
最后在两台服务器上分别配置HOST文件,完成主机名与IP的映射(此步不是必须,如果主机名、心跳名无关紧要的话):
#/etc/hosts 35.1.1.250 ZHXYHDB01 35.1.1.251 ZHXYHDB02 35.1.1.245 ZHXYHDB 50.3.1.200 ZHXYHDB01-PRIV 50.3.1.201 ZHXYHDB02-PRIV
YUM本地源配置
本地源用于方便后续的RHCS集群软件以及oracle所需软件包的安装。需要在两台服务器上分别配置。
两台服务器上分别挂载RedHat 6.7系统镜像:
# mount -o loop redhat6.7.iso /mnt/iso
在/etc/yum.repos.d目录下新建rhel6.7.repo文件,写入如下内容:
#rhel6.7.repo
[Server] name=RHELServer baseurl=file:///mnt/iso/Server enabled=1 gpgcheck=0 [ResilientStorage] name=RHELResilientStorage baseurl=file:///mnt/iso/ResilientStorage enabled=1 gpgcheck=0 [ScalableFileSystem] name=RHELScalableFileSystem baseurl=file:///mnt/iso/ScalableFileSystem enabled=1 gpgcheck=0 [HighAvailability] name=RHELHighAvailability baseurl=file:///mnt/iso/HighAvailability enabled=1 gpgcheck=0 [LoadBalancer] name=RHELLoadBalancer baseurl=file:///mnt/iso/LoadBalancer enabled=1 gpgcheck=0
# yum clean all #终端输入此命令更新源
关闭SELinux和iptables防火墙
1、关闭防火墙
在两台服务器上分别执行以下命令:
# service iptables stop
# chkconfig iptables off
2、关闭SELinux:
修改/etc/selinux/config 文件 将SELINUX=enforcing改为SELINUX=disabled 重启机器即可
Oracle数据库安装
oracle数据库软件需要在两台服务器上分别安装,只安装数据库软件而不创建数据库实例。各种Linux发行版上安装Oracle 11g R2的详细需求和过程可参见官方文档:
https://docs.oracle.com/cd/E11882_01/install.112/e24326/toc.htm
下面是本项目的Oracle数据库完整安装过程。
数据库安装前配置
新建oracle用户和组
# groupadd oinstall # groupadd dba # useradd -g oinstall -G dba oracle # passwd oracle
配置oracle内核参数
内核参数配置在/etc/sysctl.conf文件中,配置参数说明:
在安装Oracle的时候需要调整linux的内核参数,但是各参数代表什么含义呢,下面做详细解析。 Linux安装文档中给出的最小值: fs.aio-max-nr = 1048576 fs.file-max = 6815744 kernel.shmall = 2097152 kernel.shmmax = 4294967295 kernel.shmmni = 4096 kernel.sem = 250 32000 100 128 net.ipv4.ip_local_port_range = 9000 65500 net.core.rmem_default = 262144 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.wmem_max = 1048586 各参数详解: kernel.shmmax: 是核心参数中最重要的参数之一,用于定义单个共享内存段的最大值。设置应该足够大,能在一个共享内存段下容纳下整个的SGA ,设置的过低可能会导致需要创建多个共享内存段,这样可能导致系统性能的下降。至于导致系统下降的主要原因为在实例启动以及ServerProcess创建的时候,多个小的共享内存段可能会导致当时轻微的系统性能的降低(在启动的时候需要去创建多个虚拟地址段,在进程创建的时候要让进程对多个段进行“识别”,会有一些影响),但是其他时候都不会有影响。 官方建议值: 32位linux系统:可取最大值为4GB(4294967296bytes)-1byte,即4294967295。建议值为多于内存的一半,所以如果是32为系统,一般可取值为4294967295。32位系统对SGA大小有限制,所以SGA肯定可以包含在单个共享内存段中。 64位linux系统:可取的最大值为物理内存值-1byte,建议值为多于物理内存的一半,一般取值大于SGA_MAX_SIZE即可,可以取物理内存-1byte。例如,如果为12GB物理内存,可取12*1024*1024*1024-1=12884901887,SGA肯定会包含在单个共享内存段中。 kernel.shmall: 该参数控制可以使用的共享内存的总页数。Linux共享内存页大小为4KB,共享内存段的大小都是共享内存页大小的整数倍。一个共享内存段的最大大小是16G,那么需要共享内存页数是16GB/4KB=16777216KB /4KB=4194304(页),也就是64Bit系统下16GB物理内存,设置kernel.shmall = 4194304才符合要求(几乎是原来设置2097152的两倍)。这时可以将shmmax参数调整到16G了,同时可以修改SGA_MAX_SIZE和SGA_TARGET为12G(您想设置的SGA最大大小,当然也可以是2G~14G等,还要协调PGA参数及OS等其他内存使用,不能设置太满,比如16G) kernel.shmmni: 该参数是共享内存段的最大数量。shmmni缺省值4096,一般肯定是够用了。 fs.file-max: 该参数决定了系统中所允许的文件句柄最大数目,文件句柄设置代表linux系统中可以打开的文件的数量。 fs.aio-max-nr: 此参数限制并发未完成的请求,应该设置避免I/O子系统故障。 推荐值是:1048576 其实它等于 1024*1024 也就是 1024K 个。 kernel.sem: 以kernel.sem = 250 32000 100 128为例: 250是参数semmsl的值,表示一个信号量集合中能够包含的信号量最大数目。 32000是参数semmns的值,表示系统内可允许的信号量最大数目。 100是参数semopm的值,表示单个semopm()调用在一个信号量集合上可以执行的操作数量。 128是参数semmni的值,表示系统信号量集合总数。 net.ipv4.ip_local_port_range: 表示应用程序可使用的IPv4端口范围。 net.core.rmem_default: 表示套接字接收缓冲区大小的缺省值。 net.core.rmem_max: 表示套接字接收缓冲区大小的最大值。 net.core.wmem_default: 表示套接字发送缓冲区大小的缺省值。 net.core.wmem_max: 表示套接字发送缓冲区大小的最大值。
其中kernel.shmmax关系到Oracle数据库的系统全局区SGA的最大大小,kernel.shmmax值不能小于SGA的大小,否则后面设置SGA时会因为kernel.shmmax太小而出错。kernel.shmmax的大小需要根据当前系统环境的内存大小和Oracle数据库的SGA所期望的大小进行设定。SGA和PGA大小的设定原则为:
Oracle官方文档推荐: MEMORY_TARGET=物理内存 x 80% MEMORY_MAX_SIZE=物理内存 x 80% 对于OLTP系统: SGA_TARGET=(物理内存 x 80%) x 80% SGA_MAX_SIZE=(物理内存 x 80%) x 80% PGA_AGGREGATE_TARGET=(物理内存 x 80%) x 20% 对于DSS系统: SGA_TARGET=(物理内存 x 80%) x 50% SGA_MAX_SIZE=(物理内存 x 80%) x 50% PGA_AGGREGATE_TARGET=(物理内存 x 80%) x 50%
本项目中服务器内存为32G,为SGA设置最大值为20G,因此将Oralce数据库内核参数配置为:
#oracle fs.aio-max-nr = 1048576 fs.file-max = 6815744 kernel.shmall = 5242880 kernel.shmmax = 21474836480 kernel.shmmni = 4096 kernel.sem = 250 32000 100 128 net.ipv4.ip_local_port_range = 9000 65500 net.core.rmem_default = 262144 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.wmem_max = 1048586
将以上代码加入/etc/sysctl.conf文件的末尾,并在终端输入sysctl -p 命令使配置立即生效。
配置Oracle系统资源限制
系统资源限制文件为/etc/security/limits.conf,该文件说明如下:
limits.conf的格式如下: username|@groupname type resource limit username|@groupname:设置需要被限制的用户名,组名前面加@和用户名区别。也可以用通配符*来做所有用户的限制。 type:有 soft,hard 和 -,soft 指的是当前系统生效的设置值。hard 表明系统中所能设定的最大值。soft 的限制不能比har 限制高。用 - 就表明同时设置了 soft 和 hard 的值。 resource: core - 限制内核文件的大小 date - 最大数据大小 fsize - 最大文件大小 memlock - 最大锁定内存地址空间 nofile - 打开文件的最大数目 rss - 最大持久设置大小 stack - 最大栈大小 cpu - 以分钟为单位的最多 CPU 时间 noproc - 进程的最大数目 as - 地址空间限制 maxlogins - 此用户允许登录的最大数目 要使 limits.conf 文件配置生效,必须要确保 pam_limits.so 文件被加入到启动文件中。查看 /etc/pam.d/login 文件中有: session required /lib/security/pam_limits.so
本项目的Oracle资源限制设置为:
oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofile 1024 oracle hard nofile 65536
将以上代码加入/etc/security/limits.conf文件末尾。
调整tmpfs大小
如果内存较大,sga target不能超过tmpfs大小,因此需要将tmpfs调整到一个大于sga target的值。编辑/etc/fstab,修改tmpfs行:
tmpfs /dev/shm tmpfs defaults,size=25600m 0 0 #如服务器内存32GB,sga target为20GB,则可设置tmpfs为25GB
重新mount并查看tmpfs设置是否生效:
[root@cheastrac01:~]$mount -o remount /dev/shm [root@cheastrac01:~]$df -h
配置Oracle环境变量
1、创建Oracle相关目录并更改相关权限:
# mkdir -p /opt/oracle/oracle11g
# mkdir -p /opt/oraInventory
# chown -R oracle:oinstall /opt/oracle
# chmod -R 775 /opt/oracle
# chown -R oracle:oinstall /opt/oraInventory
# chmod -R 775 /opt/oraInventory
2、配置Oracle环境变量:
在/etc/profile文件末尾加入如下内容:
#Oracle export ORACLE_BASE=/opt/oracle export ORACLE_HOME=$ORACLE_BASE/oracle11g export ORACLE_SID=zxbank #本项目的oracle实例名 export PATH=$ORACLE_HOME/bin:$PATH:$HOME/bin
终端输入如下命令使配置生效:
# . /etc/profile
安装相关软件包
Oracle数据库软件的安装和运行需要依赖部分第三方软件包,安装Oracle数据库前需要先安装这些软件包,根据Oracle官方安装文档,RedHat 6.7环境需要安装的软件包有:
binutils-2.20.51.0.2-5.11.el6 (x86_64) compat-libcap1-1.10-1 (x86_64) compat-libstdc++-33-3.2.3-69.el6 (x86_64) compat-libstdc++-33-3.2.3-69.el6.i686 elfutils-libelf-0.161-3.el6(x86_64) elfutils-0.161-3.el6(x86_64) elfutils-devel-0.161-3.el6(x86_64) elfutils-libs-0.161-3.el6(x86_64) elfutils-libelf-devel-0.161-3(el6.x86_64) gcc-4.4.4-13.el6 (x86_64) gcc-c++-4.4.4-13.el6 (x86_64) glibc-2.12-1.7.el6 (i686) glibc-2.12-1.7.el6 (x86_64) glibc-devel-2.12-1.7.el6 (x86_64) glibc-devel-2.12-1.7.el6.i686 ksh libgcc-4.4.4-13.el6 (i686) libgcc-4.4.4-13.el6 (x86_64) libstdc++-4.4.4-13.el6 (x86_64) libstdc++-4.4.4-13.el6.i686 libstdc++-devel-4.4.4-13.el6 (x86_64) libstdc++-devel-4.4.4-13.el6.i686 libaio-0.3.107-10.el6 (x86_64) libaio-0.3.107-10.el6.i686 libaio-devel-0.3.107-10.el6 (x86_64) libaio-devel-0.3.107-10.el6.i686 make-3.81-19.el6 sysstat-9.0.4-11.el6 (x86_64) unixODBC-2.2.14-11.el6 (x86_64) or later unixODBC-2.2.14-11.el6.i686 or later unixODBC-devel-2.2.14-11.el6 (x86_64) or later unixODBC-devel-2.2.14-11.el6.i686 or later
以上包均可通过使用yum命令从之前配置好的本地源中安装。
【注】:安装软件包技巧:软件包版本号无须完全一致,也无须一个个安装,只需利用通配符进行批量安装即可,如安装unixODBC的相关包,可直接使用
# yum -y install unixODBC*
命令一步到位,不会产生软件包漏装的问题。正式安装Oracle数据库时会有一个检查系统环境是否满足需求的过程,如果提示部分软件包没有安装,则在root账户下使用yum进行安装即可,如果只是软件包版本不对则可直接忽略。
Oracle数据库正式安装
切换到oracle用户下:
# su - oracle
将系统变量LANG暂时设置为英文,以免安装界面出现中文字符无法显示:
# export LANG=en_US
解压Oracle安装包,执行runInstaller进行图文界面安装。
# cd database
# ./runInstaller
不勾选也不填邮箱,点下一步,弹出提示点是。

选只安装数据库软件,下一步。
选单节点安装,下一步。

默认,下一步。
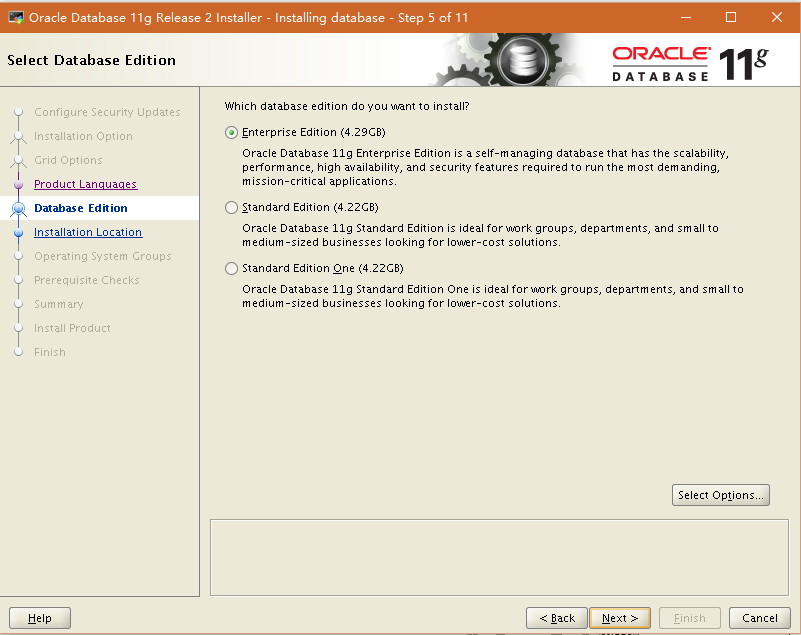
选企业版,下一步。

之前预安装配置没问题的话,这里会自动填上安装路径,直接下一步。

下一步。
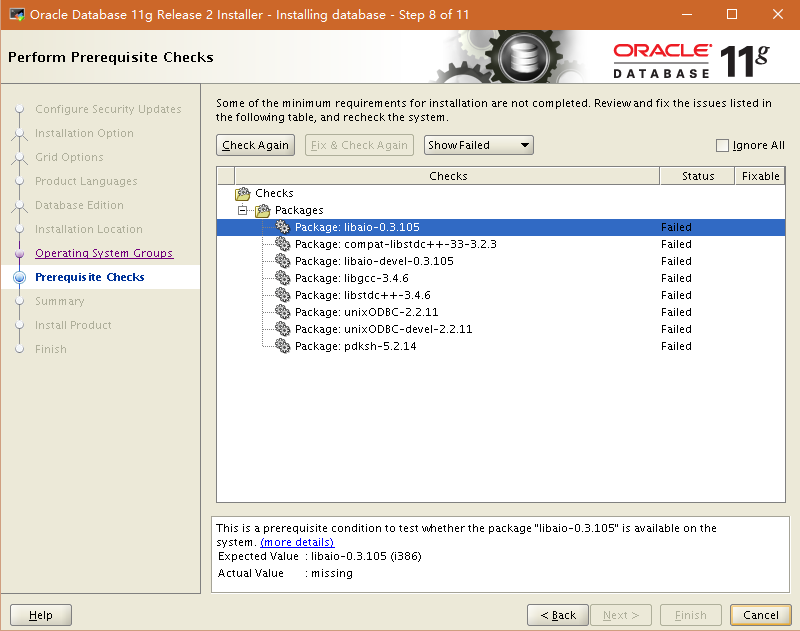
确定告警的这些包是否已经安装,如果都只是依赖包的版本问题,直接勾选‘Ingore all’,然后点Finish即可完成安装,完成后按要求使用root账号运行两个脚本。
监听器配置
切换到oracle账户下使用netca进行监听器的配置,具体步骤如下:
#oracle账户下操作 # export LANG=en_US #更改系统语言为英文,避免netca图像界面乱码 # netca
打开图形界面,一路Next即可完成一个默认监听器的配置。
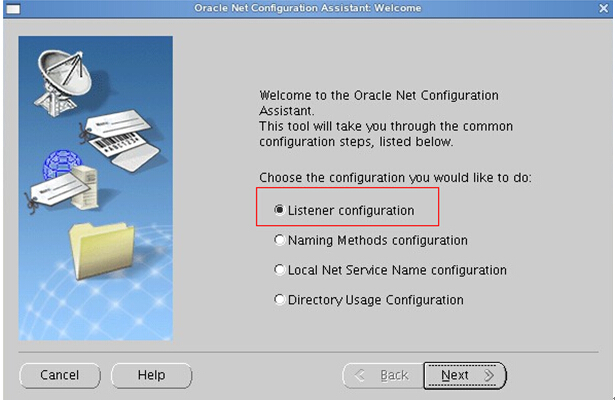
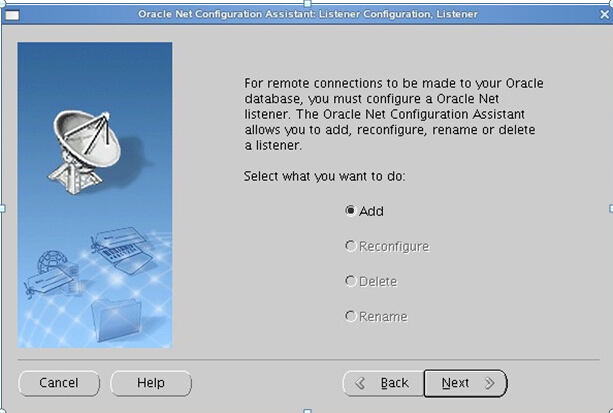

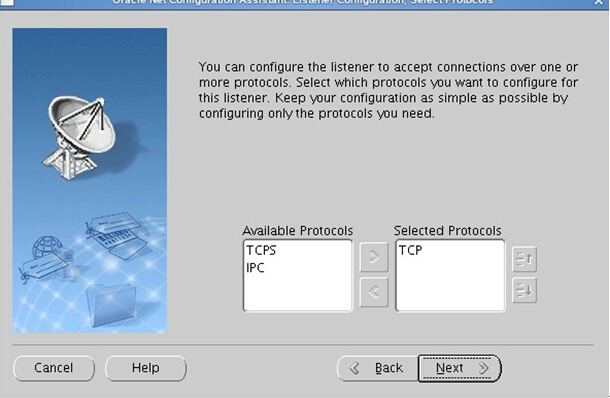

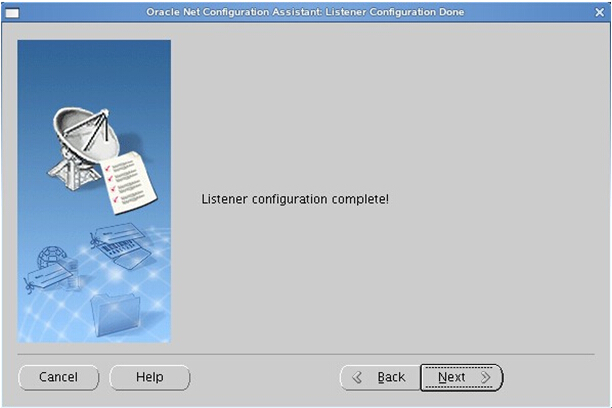
配置完成后会自动启动监听器,如未自动启动请在oracle账户下手动启动:
#oracle账户下操作 # lsnrctl start
自动配置的监听器只能提供本机(localhost)连接。这里先启用自动配置的监听器用于后续数据库实例的安装和配置。
数据库实例配置
注意:数据库实例需要创建在共享存储上,因此需要先进行后文中共享存储的挂载后才能进行此处的数据库实例的配置!
在一台节点服务器上挂载共享存储,开启监听器,然后在该存储上创建数据库实例,关闭实例,关闭监听器,完成后卸载共享存储。再将相应的实例配置信息复制到另外一台服务器上。最后在两台节点服务器上分别配置对应于浮动IP的监听器。这里我们在35.1.1.250节点上完成此操作。具体步骤如下:
root账户下,挂载共享存储:
# mount /dev/oraclevg/oraclelv /oradata
开启oracle监听器(保证监听器已经按照上文配置完成):
# lsnrctl start
监听器启动后状态应如下图所示:

切换到oracle账户下,开始进行实例创建,这里使用dbca在图形化界面创建,以下数据库实例创建和配置均在oracle账户下进行:
#oracle账户下操作 # export LANG=en_US #更改系统语言为英文,避免netca图像界面乱码 # dbca
(以下关于数据库实例创建图为网上所找,实际配置以图下说明文字为准)

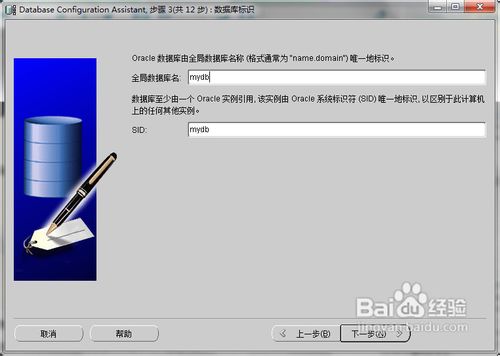
(本项目数据库名应为zxbank)
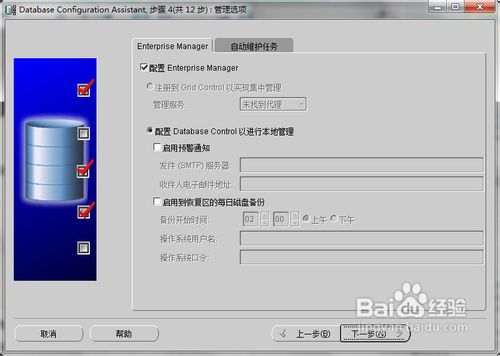
(本项目不启用Enterprise Manager)
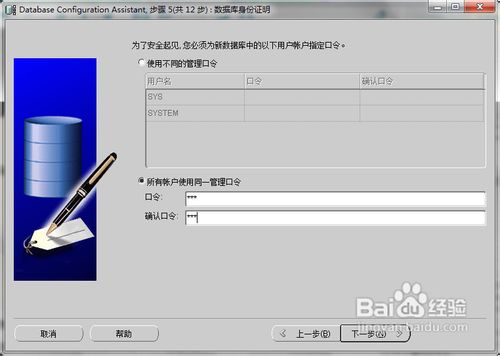
(本项目所有账户使用同一管理口令:Admin123,本口令不合法)

(本项目内存大小为20G,使用自动内存管理,字符集为UTF8)

(本项目不安装样本数据库)
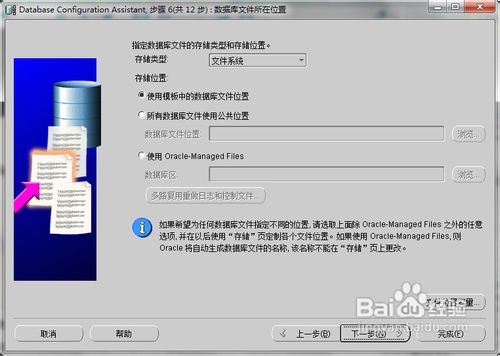
(本项目存储类型为文件系统,使用OMF自动管理文件系统,数据库区为之前指定的共享存储挂载点/oradata)

(本项目不启用闪回区)

完成创建
数据库实例创建完成后使用sysdba权限进入数据库,开启数据库:
# sqlplus / as sysdba > startup #环境变量中已经指定了ORACLE_SID,会自动启动此实例
进行项目相关的数据库表空间的创建以及用户的创建和授权。
使用OMF策略的话,创建表空间的语句更简单:
# CREATE TABLESPACE shop_tb #创建名为shop_tb的表空间
创建用户并将其默认表空间设置为上述表空间:
# CREATE USER shop IDENTIFIED BY shop DEFAULT TABLESPACE shop_tb
为用户授权:
# grant connect,resource to shop; # grant create any sequence to shop; # grant create any table to shop; # grant delete any table to shop; # grant insert any table to shop; # grant select any table to shop; # grant unlimited tablespace to shop; # grant execute any procedure to shop; # grant update any table to shop; # grant create any view to shop;
完成后关闭数据库和监听器:
> shutdown immediate # lsnrctl stop
将相关密码文件和参数文件复制到另外一个节点:
# cd $ORACLE_HOME/dbs # ls hc_zxbank.dat init.ora lkZXBANK orapwzxbank spfilezxbank.ora #scp orapwzxbank oracle@35.1.1.251:/opt/oracle/oracle11g/dbs/ #注意scp命令指定远程主机时使用oracle账户:oracle@35.1.1.251
#scp spfilezxbank.ora oracle@35.1.1.251:/opt/oracle/oracle11g/dbs/
登陆到另外一个节点上,跳转到$ORACLE_BASE目录的admin目录下实例目录下(admin和实例目录不存在则新建),本项目中完整路径为/opt/oracle/admin/zxbank。在该目录下创建数据库实例启动所需的目录。具体需要创建的目录可以对照之前创建数据库实例的节点的相同目录。如:
#cd $ORACLE_BASE/admin/zxbank # mkdir {adump,bdump,cdump,dpdump,pfile,udump}
#也可以采取scp整个admin目录到另外一个节点,然后再删除adump,bdump等目录下所有文件的方式
确保两节点的数据库实例和监听器都关闭后,移除/oradataa目录的挂载:
# umount /oradata
最后,分别确认一下两个节点相关目录的权限都是正确的:
# chown -R oracle:oinstall /opt/oracle #两节点分别执行
修改监听器配置
先确保两台节点监听器均处于关闭状态,然后在两台节点服务器上分别修改监听器配置文件,将远程连接IP设置为集群浮动IP:
#oracle账户下操作
# lsnrctl stop
# vi $ORACLE_HOME/network/admin/listener.ora
监听器配置文件修改如下:
# litener.ora Network Configuration File: /opt/oracle/oracle11g/network/admin/listener.ora
# Generated by Oracle configuration tools.
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 35.1.1.245)(PORT = 1521))
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /opt/oracle/oracle11g)
(ENVS = EXTPROC_DLLS=ANY)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME = zxbank)
(ORACLE_HOME = /opt/oracle/oracle11g)
(SID_NAME = zxbank)
)
)
ADR_BASE_LISTENER = /opt/oracle
完成后确保监听器处于关闭状态。
RHCS集群安装与配置
RHCS集群介绍
1. RHCS简介 RHCS是Red Hat Cluster Suite的缩写,即红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。高可用集群是RHCS的核心功能。当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以通过RHCS提供的高可用性服务管理组件自动、快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透明的,从而保证应用持续、不间断的对外提供服务,这就是RHCS高可用集群实现的功能。 2. RHCS集群组成介绍 RHCS是一个集群工具的集合,主要有下面几大部分组成: A、 分布式集群管理器(CMAN) Cluster Manager,简称CMAN,是一个分布式集群管理工具,它运行在集群的各个节点上,为RHCS提供集群管理任务。 CMAN用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的关系,当集群中某个节点出现故障,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。 B、锁管理(DLM) Distributed Lock Manager,简称DLM,表示一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制,在RHCS集群系统中,DLM运行在集群的每个节点上,GFS通过锁管理器的锁机制来同步访问文件系统元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。 DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大的提高了处理性能。同时,DLM避免了当单个节点失败需要整体恢复的性能瓶颈,另外,DLM的请求都是本地的,不需要网络请求,因而请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。 C、配置文件管理(CCS) Cluster Configuration System,简称CCS,主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态,当这个文件发生任何变化时,都将此变化更新到集群中的每个节点,时刻保持每个节点的配置文件同步。例如,管理员在节点A上更新了集群配置文件,CCS发现A节点的配置文件发生变化后,马上将此变化传播到其它节点上去。 rhcs的配置文件是cluster.conf,它是一个xml文件,具体包含集群名称、集群节点信息、集群资源和服务信息、fence设备等,这个会在后面讲述。 D、栅设备(FENCE) FENCE设备是RHCS集群中必不可少的一个组成部分,通过FENCE设备可以避免因出现不可预知的情况而造成的“脑裂”现象,FENCE设备的出现,就是为了解决类似这些问题,Fence设备主要就是通过服务器或存储本身的硬件管理接口,或者外部电源管理设备,来对服务器或存储直接发出硬件管理指令,将服务器重启或关机,或者与网络断开连接。 FENCE的工作原理是:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。 RHCS的FENCE设备可以分为两种:内部FENCE和外部FENCE,常用的内部FENCE有IBM RSAII卡,HP的iLO卡,还有IPMI的设备等,外部fence设备有UPS、SAN SWITCH、NETWORK SWITCH等 E、高可用服务管理器 高可用性服务管理主要用来监督、启动和停止集群的应用、服务和资源。它提供了一种对集群服务的管理能力,当一个节点的服务失败时,高可用性集群服务管理进程可以将服务从这个失败节点转移到其它健康节点上来,并且这种服务转移能力是自动、透明的。 RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。 在一个RHCS集群中,高可用性服务包含集群服务和集群资源两个方面,集群服务其实就是应用服务,例如apache、mysql等,集群资源有很多种,例如一个IP地址、一个运行脚本、ext3/GFS文件系统等。 在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的,所谓失败转移域是一个运行特定服务的集群节点的集合。在失败转移域中,可以给每个节点设置相应的优先级,通过优先级的高低来决定节点失败时服务转移的先后顺序,如果没有给节点指定优先级,那么集群高可用服务将在任意节点间转移。因此,通过创建失败转移域不但可以设定服务在节点间转移的顺序,而且可以限制某个服务仅在失败转移域指定的节点内进行切换。 F、集群配置管理工具 RHCS提供了多种集群配置和管理工具,常用的有基于GUI的system-config-cluster、Conga等,也提供了基于命令行的管理工具。 system-config-cluster是一个用于创建集群和配置集群节点的图形化管理工具,它有集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态。一般用在RHCS早期的版本中。 Conga是一种新的基于网络的集群配置工具,与system-config-cluster不同的是,Conga是通过web方式来配置和管理集群节点的。Conga有两部分组成,分别是luci和ricci,luci安装在一台独立的计算机上,用于配置和管理集群,ricci安装在每个集群节点上,Luci通过ricci和集群中的每个节点进行通信。 RHCS也提供了一些功能强大的集群命令行管理工具,常用的有clustat、cman_tool、ccs_tool、fence_tool、clusvcadm等,这些命令的用法将在下面讲述。 G、 Redhat GFS GFS是RHCS为集群系统提供的一个存储解决方案,它允许集群多个节点在块级别上共享存储,每个节点通过共享一个存储空间,保证了访问数据的一致性,更切实的说,GFS是RHCS提供的一个集群文件系统,多个节点同时挂载一个文件系统分区,而文件系统数据不受破坏,这是单一的文件系统,例如EXT3、EXT2所不能做到的。 为了实现多个节点对于一个文件系统同时读写操作,GFS使用锁管理器来管理I/O操作,当一个写进程操作一个文件时,这个文件就被锁定�%@C�此时不允许其它进程进行读写操作,直到这个写进程正常完成才释放锁,只有当锁被释放后,其它读写进程才能对这个文件进行操作,另外,当一个节点在GFS文件系统上修改数据后,这种修改操作会通过RHCS底层通信机制立即在其它节点上可见。 在搭建RHCS集群时,GFS一般作为共享存储,运行在每个节点上,并且可以通过RHCS管理工具对GFS进行配置和管理。这些需要说明的是RHCS和GFS之间的关系,一般初学者很容易混淆这个概念:运行RHCS,GFS不是必须的,只有在需要共享存储时,才需要GFS支持,而搭建GFS集群文件系统,必须要有RHCS的底层支持,所以安装GFS文件系统的节点,必须安装RHCS组件。
RHCS集群安装
在两台服务器上分别按照RHCS集群:
查询是否存在RHCS相关组件的yum源:
# yum grouplist
#是否存在High Availability和High Availability Management
#中文环境下则为‘高可用性’和‘高可用性管理’
如成功,则安装RHCS HA组件:
# yum –y groupinstall "High Availability Management" "High Availability" #中文环境下为:# yum –y groupinstall "高可用性" "高可用性管理"
安装完成后,如果集群需要使用共享存储,则需要额外安装配置lvm2-cluster:
# yum -y install lvm2-cluster
配置lvm2-cluster:
编辑/etc/lvm/lvm.conf文件,修改:locking_type = 3
RHCS集群配置
luci是RHCS默认的集群管理工具,可以完成集群的创建及管理工作。
A、集群启动:
在两台服务器上分别启动集群软件:
# service ricci start #启动集群软件,会自动启动cman和rgmanager # service cman start #如果已启动ricci,可无需执行此语句 # service rgmanager start #如果已启动ricci,可无需执行此语句 # chkconfig cman on # chkconfig rgmanager on # chkconfig ricci on #设置集群软件开机自动启动 # passwd ricci #设置集群节点密码
在其中一台服务器上安装luci集群管理工具并启动:
# service luci start #启动集群管理工具
# chkconfig luci on #设置luci开机启动
B、共享存储挂载
此步骤需要在集群节点配置完成后(添加集群资源前)再执行。以下操作在两台服务器上分别执行,:
1、创建挂载共享存储的目录:
# mkdir /oradata #创建目录用于存储的挂载
2、启动lvm2-cluster服务:
# service clvmd start #需要先启动上述集群服务再启动clvmd服务
# chkconfig clvmd on
以下操作在其中一台服务器上执行:
3、新建LVM卷组oraclevg,将共享存储/dev/sdb1创建为物理卷并加入卷组中,在卷组中创建逻辑卷oraclelv:
# pvcreate /dev/sdb1
# vgcreate oraclevg /dev/sdb1
# lvcreate -n oraclelv -L +500G /dev/oraclevg #可通过vgdisplay查看vg全部剩余PE,然后使用‘-l PE数’参数将vg全部剩余空间加入lv中,而无须使用-L +xxGB的方式
# mkfs.ext4 /dev/oraclevg/oraclelv
4、查看卷组和逻辑卷状态,如果显示为不可用(NOT Available),则需要激活卷组:
# vgdisplay # lvdisplay # vgchange -a y oraclevg #只在一台服务器上执行,如果vg或者lv状态为不可用,均激活vg即可,如果重启后状态又不可用,则需要将此命令写入/etc/rc.local中开机启动
5、查看lvm2-cluster是否识别到共享存储的卷组(注意:必须在clvmd服务启动后才能进行vg和lv的创建,否则lvm2-cluster将无法识别,vg和lv将无法添加到集群资源组中):
# vgdisplay # lvdisplay # vgchange -a y oraclevg #如果vg或者lv状态为不可用,均激活vg即可,如果重启后状态又不可用,则需要将此命令写入/etc/rc.local中开机启动
# service clvmd status #clvmd服务的状态必须如下才表示正确识别了用于集群的vg和lv
clvmd (pid 7978)正在运行...
Clustered Volume Groups: oraclevg
Active clustered Logical Volumes: oraclelv
此步骤完成后可以开始数据库实例的创建和配置,然后再进行集群的配置
C、集群配置:
1、集群创建(节点添加)
启动luci服务后即可使用浏览器打开luci进行集群创建和管理了。地址为:
https://35.1.1.250:8084 #用户名和密码与系统root账号相同
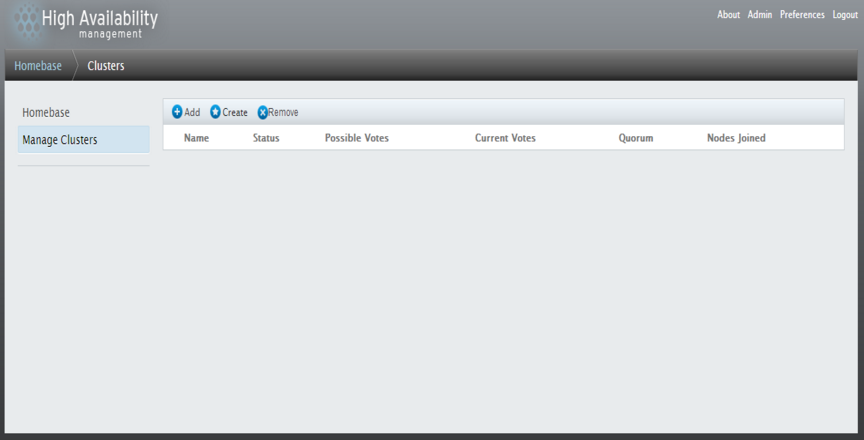
点击create创建集群:

配置说明:
cluster name:给集群添加一个命名即可。
然后分别添加两个节点:
Use the Same Password for All Nodes:所有节点使用相同的节点管理密码,建议勾选。
Node Name:节点名,与/etc/hosts文件中心跳IP的对应命名相同即可。也可以直接填写心跳IP。(两节点分别填写)
Password:节点管理密码,随便设置,建议与系统root密码相同。
Ricci Hostname:ricci主机名,默认与节点名相同,不用更改。
Ricci Port:ricci端口,默认11111即可。
节点添加完成后继续配置:
Download Packages:使用网络下载所需的相关包。
Use Locally Installed Packages:使用本地已安装的包,选择此项。
Reboot Nodes Before Joining Cluster:主机节点加入集群前先重启,建议不勾选。
Enable Shared Storage Support:共享存储支持,如果需要使用共享存储,需要勾选此项。(此项需要系统安装lvm2-cluster并启动clvmd服务)
点击Create Cluster创建集群,ricci会自动启动添加的节点服务器上的集群软件(cman和rgmanager),成功后即可完成集群的创建和节点的添加。
集群创建完成后如图:
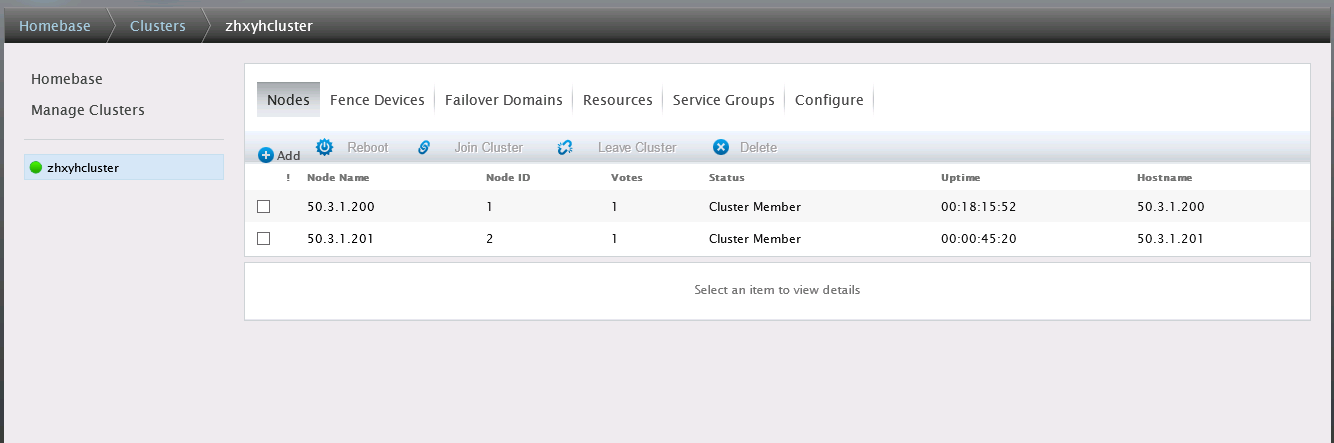
2、Fence设备添加
Fence设备可以防止集群资源(例如文件系统)同时被多个节点占有,保护了共享数据的安全性和一致性节,同时也可以防止节点间脑裂的发生。(Fence设备并非不可缺少,通常也可以使用仲裁盘代替Fence设备,本项目使用Fence方案)
切换到“Fence Devices”选项,“Add”添加两个Fence设备,对于华为浪潮等国产服务器,服务器本身的IPMI管理系统(MGMT管理口)即可充当Fence设备。一添加其中一个Fence设备为例:
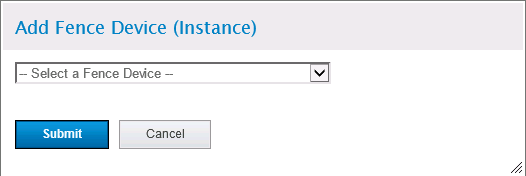
选择IPMI Lan:

Fence Type:Fence类型,本项目使用IPMI。;
Name:给Fence设备取个名字;
IP Address or Hostname:Fence设备IP地址或者设备名,这里直接填IP地址,即服务器管理口IP;
Login:Fence设备登陆账号,华为服务器通常是root/Huawei12#$,浪潮服务器可能是admin/admin,或者root/superuser等等。
Password:Fence设备登陆密码,如上;
Password Script:密码脚本,无视;
Authentication Type:认证类型,选择密码认证或者None;
Use Lanplus:部分服务器机型需要勾选此项Fence才可正常工作,建议做切换测试时根据测试结果选择是否勾选;
Privilege Level:需要操作权限在Opretor以上,一般default即可。
其他的可以不用管了,“submit”提交即可。
两个Fence均创建完成后如图:
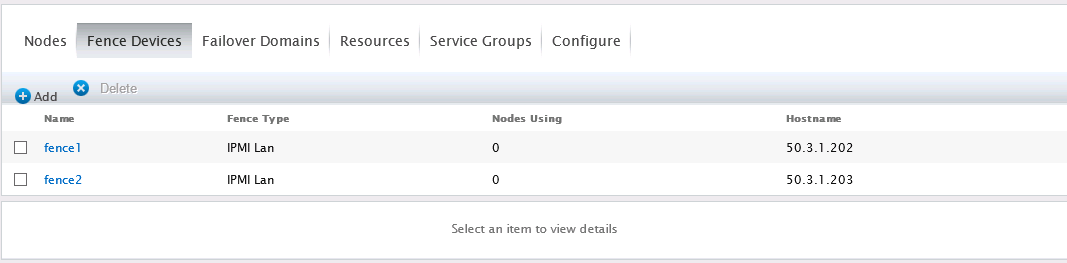
【注意】部分服务器IPMI口系统未自动启用ssh服务,需要登录到IPMI管理系统启用服务,否则fence配置无用!
Fence设备配置完成后,需要在Nodes页面为每个node指定相对应的Fence Device,如图:
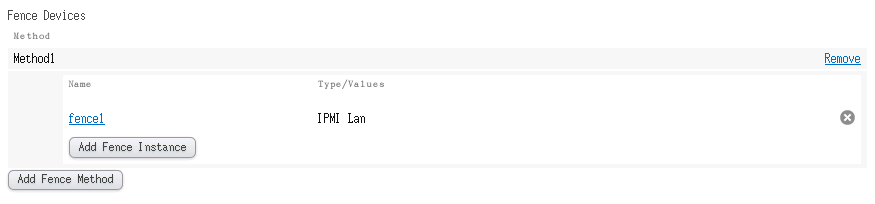

最后可以通过以下命令验证Fence是否可用:
# fence_ipmilan -v -P -a 50.1.2.221 -l admin -p admin -o status #通过fence设备查看主机状态, -o reboot可重启。
3、Failover Domains失败转移域创建
Failover Domains是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间。切换到“Failover Domains”选项,点击“add”,配置如下:
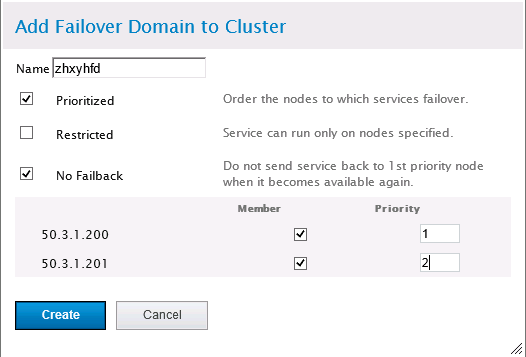
Name:给失败转移域策略取一个名字;
prioritized: 是否启用域成员节点优先级设置,这里启用;
Restricted:是否只允许资源在指定的节点间切换,这里只有两个节点互相切换,是否启用都行;
No Failback:是否启用故障回切功能,即当高优先级节点失效,资源切换到其他节点,而高优先级节点重新恢复正常时,资源是否再次切换回高优先级节点,这里选择不回切,即启用No Failback;
Member:选择失败转移域的成员,本项目只有两个节点,均勾选;
Priority:成员节点优先级,值越低优先级越高。高优先级通常作为主节点。
点击“Create”完成失败转移域创建,完成后如图:

4、添加资源
Resources是集群的核心,主要包含服务脚本、IP地址、文件系统等,本项目只涉及IP地址、文件系统和脚本的添加。
IP地址添加
“Add”选择添加IP Address:
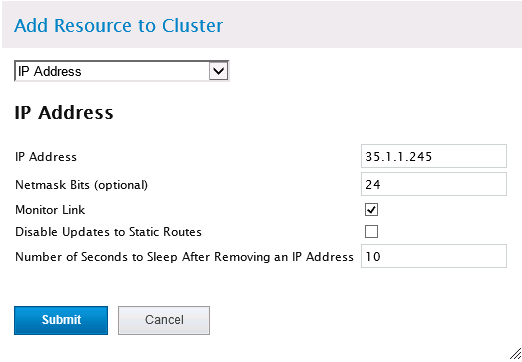
IP Address:IP地址,通常作为集群浮动IP;
Netmask Bits:子网掩码,本项目中是255.255.255.0,即24;
其他默认即可。点击“Submit”提交。
文件系统添加
由于之前我们将使用的共享存储做成了lvm逻辑卷系统,因此在添加文件系统时需要先添加HA LVM,注意启用HA LVM需要确保lvm2-cluster服务启动。之前创建的逻辑卷组为oraclevg,逻辑卷为oraclelv,因此添加HA LVM如下:
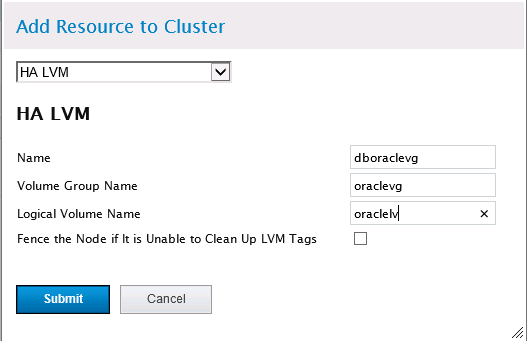
Name:给HA LVM取个名字;
Volume Group Name:共享存储的卷组名,这里为oraclevg;
Logical Volume Name:需要添加的逻辑卷名,这里为oraclelv;
Fence the Node if It is Unable to Clean Up LVM Tags:当节点LVM标记无法清除时认为节点脑裂,这里不启用。
点击“Submit”提交。
然后再添加文件系统:

Name:给文件系统取个名字;
Filesystem Type:指定文件系统类型,之前创建逻辑卷时将其格式化为ext4格式了,可以选择ext4,也可以选Autodetect自动检测;
Mount Point:设备挂载位置。选择之前创建好的目录/oradata,逻辑卷将自动挂载在当前主节点的该目录上;
Device,FS Label, or UUID:需要挂载的设备,本项目使用的是LVM逻辑卷,所以这里填写逻辑卷路径即可:/dev/oraclevg/oraclelv;
Mount Options和Filesystem ID无视即可。
Force Unmount:是否强制卸载,集群切换时挂载的设备有时候会因为资源占用等问题无法卸载,导致集群切换失败,这里启用强制卸载,可以防止此问题发生;
Force fsck:是否强制文件系统检查,文件系统检查会拖慢集群切换时间,这里不启用;
Enable NFS daemon and lockd workaround:启用NFS守护进程和上锁的解决方法,无视;
Use Quick Status Checks:使用快速状态检查,无视;
Reboot Host Node if Unmount Fails:设备卸载失败时是否重启该节点,同样可以防止设备卸载失败导致集群切换失败的问题,可以勾选,这里无视。
点击“Submit”提交。
脚本添加
本项目添加的脚本主要用于控制集群切换时oracle数据库监听器和实例的起停。RHCS集群对于脚本有专门的格式要求,通常需要有start、stop等函数进行自动调用。脚本应当先分别保存在/etc/init.d目录下并赋予可执行权限,如本项目脚本名为dbora,使用root账户创建并授权:
# chmod 755 /etc/init.d/dbora
dbora脚本内容如下:
#!/bin/bash export ORACLE_HOME=/oracle/oracle11g #之前配置好的ORACLE_HOME和ORACLE_SID,保险起见在脚本中export一次 export ORACLE_SID=zxbank start() { su - oracle<<EOF echo "Starting Listener...." $ORACLE_HOME/bin/lsnrctl start echo "Starting Oracle11g Server... " sqlplus / as sysdba startup exit; EOF } stop() { su - oracle<<EOF echo "Shutting down Listener......" $ORACLE_HOME/bin/lsnrctl stop echo "Shutting down Oracle11g Server..." sqlplus / as sysdba shutdown immediate; exit EOF } restart() { stop start } status() { ps -ef |grep -v grep |grep ora_smon_${ORACLE_SID} if [ $? = 0 ]; then exit 0 fi } case "$1" in start) start ;; stop) stop ;; restart) restart ;; status) status ;; *) echo "Usage: $0 {start|stop|restart|status}" ;; esac
资源添加中选择添加Script:

至此资源全部添加完成,如图所示:
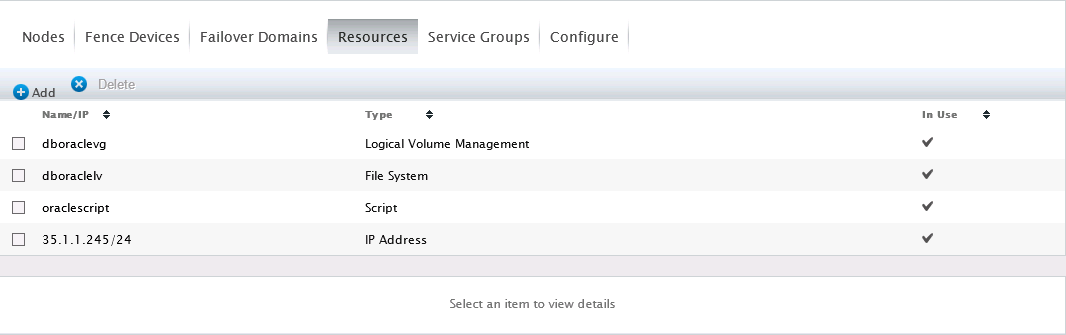
PS:
1、本项目中的共享存储是作为Oracle数据库的Data Area,实例运行其中,因此不能将共享存储同时挂在两个节点上。我们选择了使用HA LVM作为集群资源的方式进行挂载。事实上,我们也可以直接使用脚本来控制/dev/oraclevg/oraclelv的挂载,而不用将其添加到集群资源中。
2、如果项目中使用的共享存储是基于NFS方式共享的(NAS),我们可以直接将存储资源同时挂载在集群节点上,而不用在集群中添加资源。但RHCS也可以直接将NFS添加到集群资源中由集群动态控制NFS挂载在哪个节点。这里再介绍一下NFS文件系统加入集群资源的方法。假设在主机35.1.1.10上有NFS目录/nas,集群节点服务器上有空目录/share。在集群中添加该资源的方法为,“Add”选择NFS/CIFS Mount:

Name:给NFS挂载取个名字;
Mount Point:挂载到集群节点的位置,这里为/share;
Host:远程NFS服务器地址,这里为35.1.1.10;
NFS Export Directory Name or CIFS Share:远程NFS服务器上的NFS共享目录;
其他默认即可,Force Unmount同样建议勾选。
5、创建资源组
集群资源需要加入资源组中才能真正被集群中的节点所使用。
点击“Add”创建资源组:
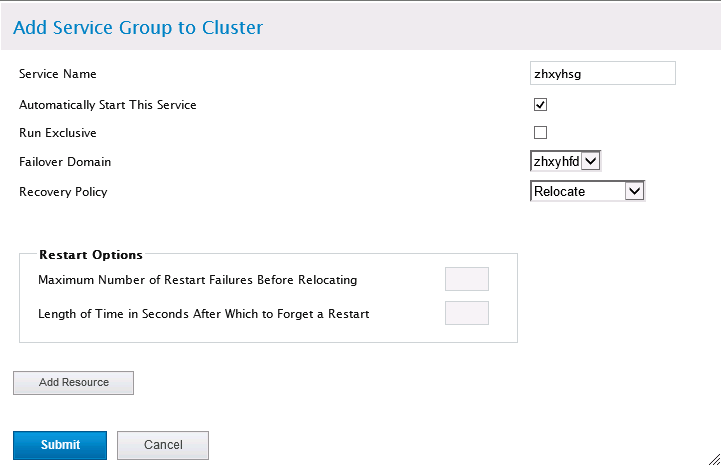
Service Name:给资源组取个名字;
Automatically Start This Service:自动启动集群资源组服务,勾选;
Run Exclusive:集群服务独占方式运行,拒绝其他集群服务运行在节点服务器上,这里是否勾选都行,建议不勾选;
Failover Domain:指定刚才配置的失败转移域;
Recovery Policy:恢复策略,选择Relocate迁移,一旦节点失效立刻迁移到其他节点。
Restart Options:节点重启策略,默认即可。
然后我们需要为资源组添加资源,依次添加之前已经配置好的IP Address,HA LVM和Script资源即可。注意Filesystem资源是添加到HA LVM的子资源而不是直接作为资源组的资源的。完成后如图:
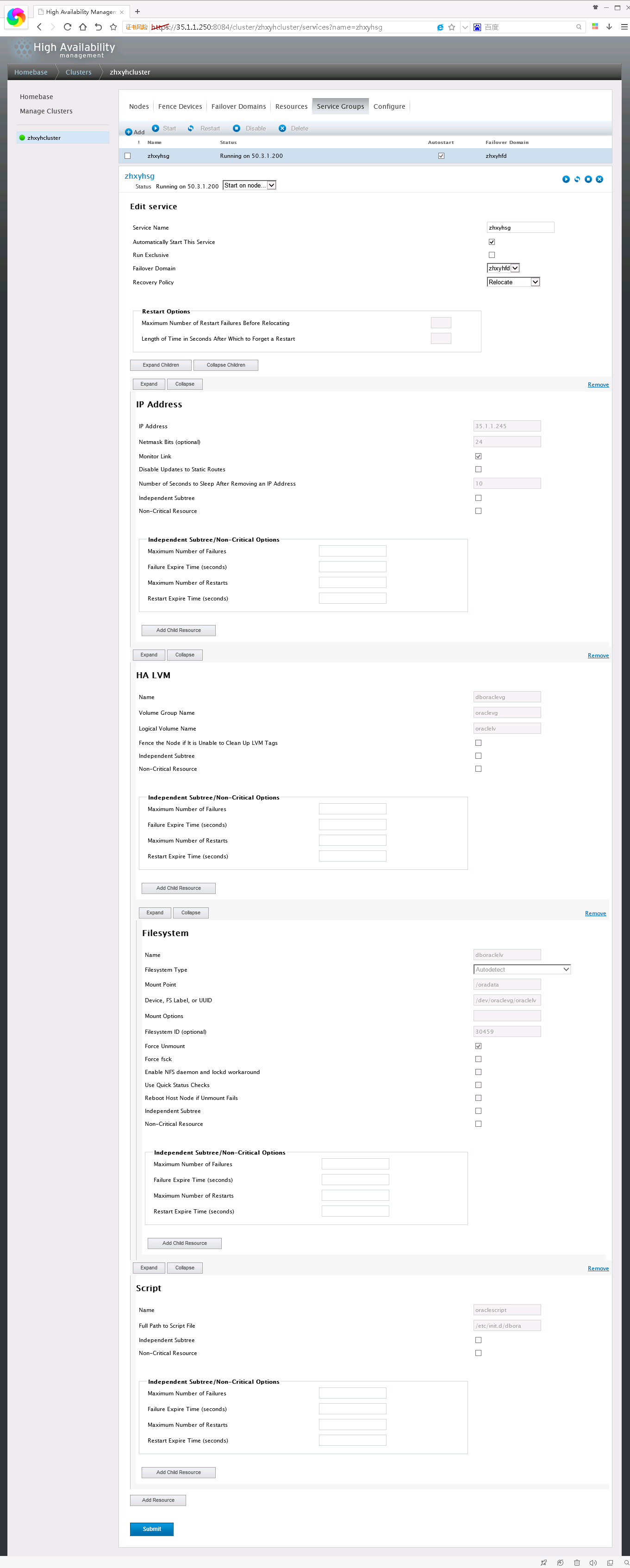
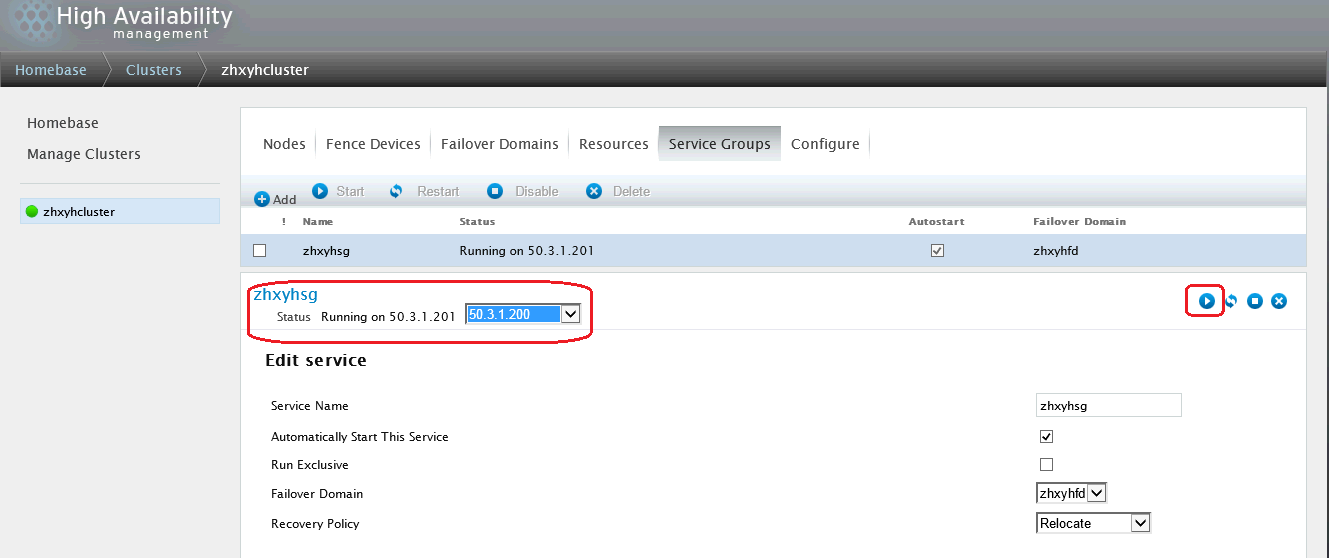
至此,RHCS集群配置完成,可以通过重启节点设备验证集群是否正常工作。或者在RHCS的资源组中进行直接切换:
选择需要切换到的节点,点击右侧"start"按钮即可进行切换。
6、常用RHCS集群管理命令
查看状态:
#1.1 clustat查看集群状态(最常用)
在节点1查看的,状态中的Local就在节点1上显示。
# clustat
Cluster Status for new_cluster @ Tue Sep 1 12:23:09 2015
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
heartdb1 1 Online, Local, rgmanager
heartdb2 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:orares heartdb1 started
#1.2 cman_tool status 查看
# cman_tool status
Version: 6.2.0
Config Version: 18
Cluster Name: new_cluster
Cluster Id: 23732
Cluster Member: Yes
Cluster Generation: 432
Membership state: Cluster-Member
Nodes: 2
Expected votes: 1
Total votes: 2
Quorum: 1
Active subsystems: 8
Flags: 2node Dirty
Ports Bound: 0 177
Node name: heartdb1
Node ID: 1
Multicast addresses: 239.192.92.17
Node addresses: 192.168.1.1
#1.3 cman_tool 查看nodes信息
# cman_tool nodes -a
Node Sts Inc Joined Name
1 M 404 2015-08-03 17:52:20 heartdb1
Addresses: 192.168.1.1
2 M 432 2015-09-01 14:32:27 heartdb2
Addresses: 192.168.1.2
2. 集群正常启动
先启动cman,再启动rgmanager.
service cman start
service rgmanager start
下面是集群正常启动过程示例:
注: 各节点先依次启动cman再依次启动rgmanager,注意启动顺序。
# service cman start
Starting cluster:
Loading modules... done
Mounting configfs... done
Starting ccsd... done
Starting cman... done
Starting daemons... done
Starting fencing... done
[确定]
# service rgmanager start
启动 Cluster Service Manager:[确定]
管理集群:
| 服务操作 | 描述 | 命令语法 |
|---|---|---|
有条件地在首选对象中,根据故障切换域规则自选启动服务。二者缺一,则运行 clusvcadm的本地主机将会启动该服务。如果原始启动失败,则该服务的行为会类似重新定位请求(请参考本表格中的 |
clusvcadm -e <service_name> 或者 clusvcadm -e <service_name> -m <member>(使用 -m 选项指定要启动该服务的首选目标成员。) |
|
| 停止该服务使其处于禁用状态。当某个服务处于失败状态时,这是唯一允许的操作。 | clusvcadm -d <service_name> |
|
将该服务移动到另一个节点中。您也可以指定首选节点接受此服务,但如果在那个主机中无法运行该服务(例如:如果服务无法启动或者主机离线),则无法阻止重新定位,并选择另一个节点。rgmanager 尝试在该集群的每个有权限的节点中启动该服务。如果集群中的没有任何有权限的目标可以成功启动该服务,则重新定位就会失败,同时会尝试在最初拥有者中重启该服务。如果原始拥有者无法重启该服务,则该服务会处于停止的状态。 |
clusvcadm -r <service_name> 或者 clusvcadm -r <service_name> -m <member>(使用 -m 选项指定要启动该服务的首选目标成员。) |
|
| 停止该服务并使其处于停止状态。 | clusvcadm -s <service_name> |
|
| 在目前运行某个服务的节点中冻结该服务。这样会在节点失败事件中或者 rgmanager 停止时,阻止服务状态检查以及故障切换。这可用来挂起服务以便进行基础资源维护。有关使用冻结和解冻操作的重要信息请参考 “使用冻结和解冻操作的注意事项”一节。 | clusvcadm -Z <service_name> |
|
| 解冻会使服务脱离冻结状态。这会重新启用状态检查。有关使用冻结和解冻操作的重要信息请参考 “使用冻结和解冻操作的注意事项”一节。 | clusvcadm -U <service_name> |
|
| 将虚拟机迁移到另一个节点中。您必须指定目标节点。根据失败的情况,迁移失败可能导致虚拟机处于失败状态,或者在最初拥有者中处于启动的状态。 | clusvcadm -M <service_name> -m <member>
重要 在迁移操作中您必须使用
-m <member> 选项指定目标节点。 |
|
| 在当前运行该服务的节点中重启服务。 | clusvcadm -R <service_name> |
本文链接:http://www.cnblogs.com/xshrim/p/5367628.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号