
索引对于数据库的性能有着举足轻重的作用。上一篇文章已经介绍了没有索引的情况下表扫描访问相关知识,本文讨论有索引的情况下数据库系统如何使用索引进行数据访问,内容会比较复杂,强烈建议参看《深入理解DB2索引(Index)》,理解DB2索引的结构,特别是B+树后再阅读本文,否则看起来可能会比较吃力。
由于“基于索引的访问”内容比较庞杂,现在只准备介绍对于一张表使用索引的情况,不考虑多表连接的问题。分三篇进行介绍,这一篇先介绍简单索引访问,下一篇介绍匹配索引扫描和复合索引,最后再介绍一下多索引访问。
基于索引的访问不一定是需要进行扫描的,但是为了表述习惯,这里统称为索引扫描(Index Scan)。
可索引谓词和不可索引谓词(Indexable Predicate and Non-Indexable Predicate)
谓词(Predicate)
对于SQL语句,Where子句后面的条件表达式称为谓词。例如:Select * From EMPLOYEE Where EMPNO=000110 . EMPNO=000110就是谓词。
如果我们在EMPNO列上建立一个索引,那么上述SQL查询就可以使用索引提高查询效率,EMPNO=000110就是可索引谓词。
但是考虑SQL语句:Select * From EMPLOYEE Where EMPNO<>000110 .
即便在EMPNO列上建立了索引,进行该SQL查询时,仍然不能使用该索引,这是因为<>(不等于)操作符无法利用索引B+树结构的优势,如果使用了该索引,不仅要将索引页读入内存进行无意义的查找工作(查找不等于的值就等于所有叶结点都要扫描一遍),还需要将几乎所有的数据页读入内存(凡是EMPNO不等于000110的所有数据页都要读入内存)。还不如直接进行表扫描,省了读入索引页和扫描索引的开销。
这种即便使用了索引也无法带来效率提升的谓词就称为不可索引谓词。
因此,数据库系统优化器只会对可索引谓词考虑使用索引扫描,不可索引谓词即便在相应列上建立了索引也依然使用表扫描。
划分
下表是常见谓词是否可索引谓词的列表:
|
谓词类型 |
Indexable? |
Stage 1? |
注 释 |
|
COL = value |
Y |
Y |
16 |
|
COL = noncol expr |
Y |
Y |
9,11,12,15 |
|
COL IS NULL |
Y |
Y |
20,21 |
|
COL op value |
Y |
Y |
13 |
|
COL op noncol expr |
Y |
Y |
9,11,12,13 |
|
COL BETWEEN value1 AND value2 |
Y |
Y |
13 |
|
COL BETWEEN noncol expr1 AND noncol expr2 |
Y |
Y |
9,11,12,13,23 |
|
value BETWEEN COL1 AND COL2 |
N |
N |
|
|
COL BETWEEN COL1 AND COL2 |
N |
N |
10 |
|
COL BETWEEN expression1 AND expression2 |
Y |
Y |
6,7,11,12,13,14 |
|
COL LIKE 'pattern' |
Y |
Y |
5 |
|
COL IN (list) |
Y |
Y |
17,18 |
|
COL <> value |
N |
Y |
8,11 |
|
COL <> nocol expr |
N |
Y |
8,11 |
|
COL IS NOT NULL |
Y |
Y |
21 |
|
COL NOT BETWEEN value1 AND value2 |
N |
Y |
|
|
谓词类型 |
Indexable? |
Stage 1? |
注释 |
|
COL NOT BETWEEN noncol expr1 AND noncol expr2 |
N |
Y |
|
|
value NOT BETWEEN COL1 AND COL2 |
N |
N |
|
|
COL NOT IN (list) |
N |
Y |
|
|
COL NOT LIKE ' char' |
N |
Y |
5 |
|
COL LIKE '%char' |
N |
Y |
1,5 |
|
COL LIKE '_char' |
N |
Y |
1,5 |
|
COL LIKE host variable |
Y |
Y |
2,5 |
|
T1.COL = T2 col expr |
Y |
Y |
6,9,11,14,15 |
|
T1.COL op T2 col expr |
Y |
Y |
6,9,11,12,13,14,15 |
|
T1.COL <> T2 col expr |
N |
Y |
8,11 |
|
T1.COL1 = T1.COL2 |
N |
N |
3 |
|
T1.COL1 op T1.COL2 |
N |
N |
3 |
|
T1.COL1 <> T1.COL2 |
N |
N |
3 |
|
COL=(nocor subq) |
Y |
Y |
|
|
COL = ANY (nocor subq) |
N |
N |
22 |
|
COL = ALL (nocor subq) |
N |
N |
|
|
COL op (nocor subq) |
Y |
Y |
|
|
COL op ANY (nocor subq) |
Y |
Y |
22 |
|
COL op ALL (nocor subq) |
Y |
Y |
|
|
COL <> (nocor subq) |
N |
Y |
|
|
COL <> ANY (nocor subq) |
N |
N |
22 |
|
COL <> ALL (nocor subq) |
N |
N |
|
|
COL IN (nocor subq) |
Y |
Y |
24 |
|
(COL1,…,COLn) IN (nocor subq) |
Y |
Y |
|
|
COL NOT IN (nocor subq) |
N |
N |
|
|
(COL1,…,COLn) NOT IN (nocor subq) |
N |
N |
|
|
COL=(cor subq) |
N |
N |
4 |
|
COL = ANY (cor subq) |
N |
N |
22 |
|
COL = ALL (cor subq) |
N |
N |
|
|
COL op (cor subq) |
N |
N |
4 |
|
COL op ANY (cor subq) |
N |
N |
22 |
|
谓词类型 |
Indexable? |
Stage 1? |
注 释 |
|
COL op ALL (cor subq) |
N |
N |
|
|
COL <> (cor subq) |
N |
N |
4 |
|
COL <> ANY (cor subq) |
N |
N |
22 |
|
COL <> ALL (cor subq) |
N |
N |
|
|
COL IN (cor subq) |
N |
N |
19 |
|
(COL1,…,COLn) IN (cor subq) |
N |
N |
|
|
COL NOT IN (cor subq) |
N |
N |
|
|
(COL1,…,COLn) NOT IN (cor subq) |
N |
N |
|
|
COL IS DISTINCT FROM value |
N |
Y |
8,11 |
|
COL IS NOT DISTINCT FROM value |
Y |
Y |
16 |
|
COL IS DISTINCT FROM noncol expr |
N |
Y |
8,11 |
|
COL IS NOT DISTINCT FROM noncol expr |
Y |
Y |
9,11,12,15 |
|
T1.COL1 IS DISTINCT FROM T2.COL2 |
N |
N |
3 |
|
T1.COL1 IS NOT DISTINCT FROM T1.COL2 |
N |
N |
3 |
|
T1.COL1 IS DISTINCT FROM T2 col expr |
N |
Y |
8,11 |
|
T1.COL1 IS NOT DISTINCT FROM T2 col expr |
Y |
Y |
6,9,11,12,14,15 |
|
COL IS DISTINCT FROM (noncor subq) |
N |
Y |
|
|
COL IS NOT DISTINCT FROM (noncor subq) |
Y |
Y |
|
|
COL IS DISTINCT FROM ANY (noncor subq) |
N |
N |
22 |
|
COL IS NOT DISTINCT FROM ANY (noncor subq) |
N |
N |
22 |
|
COL IS DISTINCT FROM ALL (noncor subq) |
N |
N |
|
|
COL IS NOT DISTINCT FROM ALL (noncor subq) |
N |
N |
4 |
|
COL IS DISTINCT FROM (cor subq) |
N |
N |
4 |
|
COL IS NOT DISTINCT FROM (cor subq) |
N |
N |
22 |
|
COL IS DISTINCT FROM ANY (cor subq) |
N |
N |
22 |
|
COL IS NOT DISTINCT FROM ANY (cor subq) |
N |
N |
22 |
|
COL IS DISTINCT FROM ALL (cor subq) |
N |
N |
|
|
COL IS NOT DISTINCT FROM ALL (cor subq) |
N |
N |
|
|
EXISTS (subq) |
N |
N |
19 |
|
NOT EXISTS (subq) |
N |
N |
|
|
expression = value |
N |
N |
|
|
expression <> value |
N |
N |
|
|
expression op value |
N |
N |
|
|
expression op (subq) |
N |
N |
|
匹配索引扫描和非匹配索引扫描(Matching Index Scan and Non-Matching Index Scan)
现在假设有一张联系人表PHONEBOOK,该表上有LASTNAME、FIRSTNME等若干列,在LASTNAME,FIRSTNME列上建有一个索引:
CREATE INDEX PHONEBOOK_IDX ONPHONEBOOK (LASTNAME,FIRSTNME) //为方便解释,假设这个索引是一个2层索引
注意这个索引是一个复合索引(Composite Index),列的排列顺序是非常重要的,第一个列是主索引列,其他列都是从索引列。
该表结构如图:
匹配索引扫描(Matching Index Scan)
如果现在有查询语句:
Select * From PHONEBOOK Where LASTNAME Like 'S%' .
那么整个索引扫描过程就是这样的:
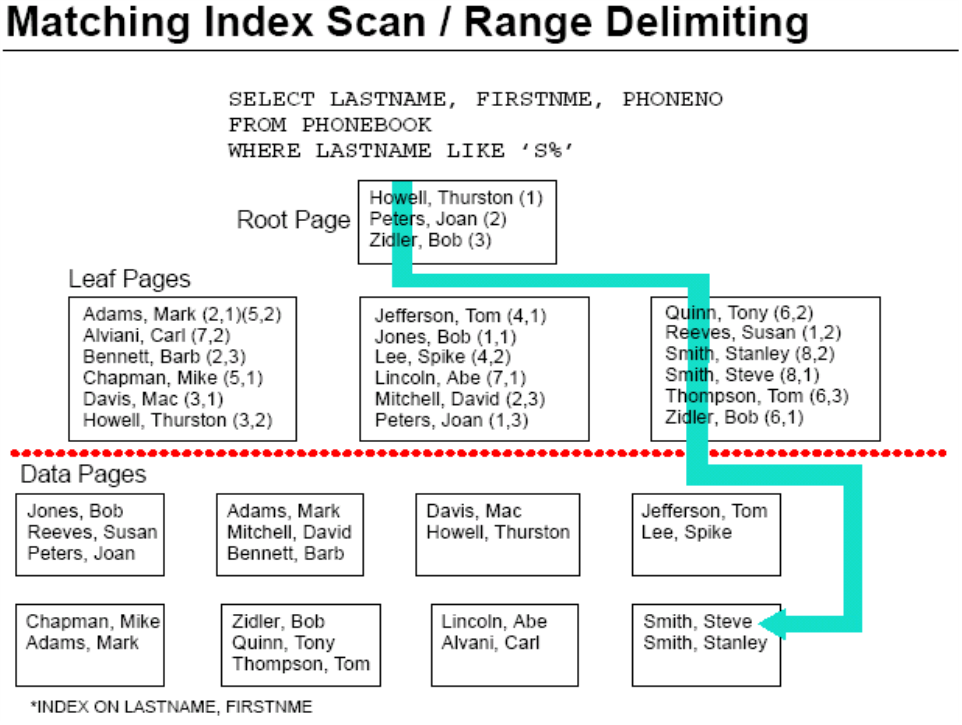
这张图所表述的意思是:
索引由根结点页(Root Page)和叶结点页(Leaf Pages)构成,只有两层,没有非叶结点页。
索引项由两部分组成:由LASTNAME和FIRSTNME构成的搜索码和索引指针(图中括号内的数字)。
LASTNAME的值中字母排序小于或等于Howell的索引项位于最左侧的页结点,且这些页索引项按LASTNAME排序,LASTNAME相同的再按FIRSTNME排序;大于Howell且小于或等于Peters的位于中间的页结点;大于Peters且小于或等于Zidler的位于右侧页结点。(其实这个就是B+树的规范结构,这里粗略解释一下)
红线以上的是索引页,红线以下的是数据页。数据页从左到右编号,页中的数据行从上到下编号。比如:索引项Quinn,Tony(6,2)就表示LASTNAME为Quinn,FIRSTNME为Tony的数据行的位置是:6号数据页的2号槽位。 (这个就是数据页内部结构,不理解的话参看:《深入理解数据库磁盘存储(Disk Storage)》)
青色线表示扫描路径,青色线穿过的页为索引扫描过的页。SQL语句查找的是LASTNAME以S开头的行,所以从根结点页开始,直接找到右侧的索引页,再由该页中的满足条件的索引项的行指针找到数据页的位置。注意:整个扫描过程中没有经过左侧和中间的叶结点页。
这种使用索引并且索引中的主搜索码可用的索引扫描方式就称为匹配索引扫描。可用的索引谓词就称为匹配谓词(Matching Predicate)。
当然了,对于非复合索引,即单列索引,如果该列上建有索引且SQL语句的Where子句后的条件谓词是可索引谓词,那么该查询的访问方式自然也是匹配索引扫描。
比如表T1的C1列上有索引C1X,则SQL查询: Select * From T1 Where C1=10 的访问方式是匹配索引扫描。
非匹配索引扫描(Non-Matching Index Scan)
现在考虑查询:
Select * From PHONEBOOK Where FIRSTNME = ‘Abe’
这个SQL语句的条件谓词是FIRSTNME = ‘Abe’,但是索引的主搜索码是LASTNAME。也就是说,索引的B+树结构是根据LASTNAME来构建的,Where子句后面如果没有LASTNAME的条件谓词,就不可能像上面匹配索引扫描一样,直接找到满足条件的索引页。那么,如果要使用这个索引,就只能遍历所有的叶结点索引页才能找到所有满足条件的索引项,获取相应的数据页指针。其扫描过程是这样的:
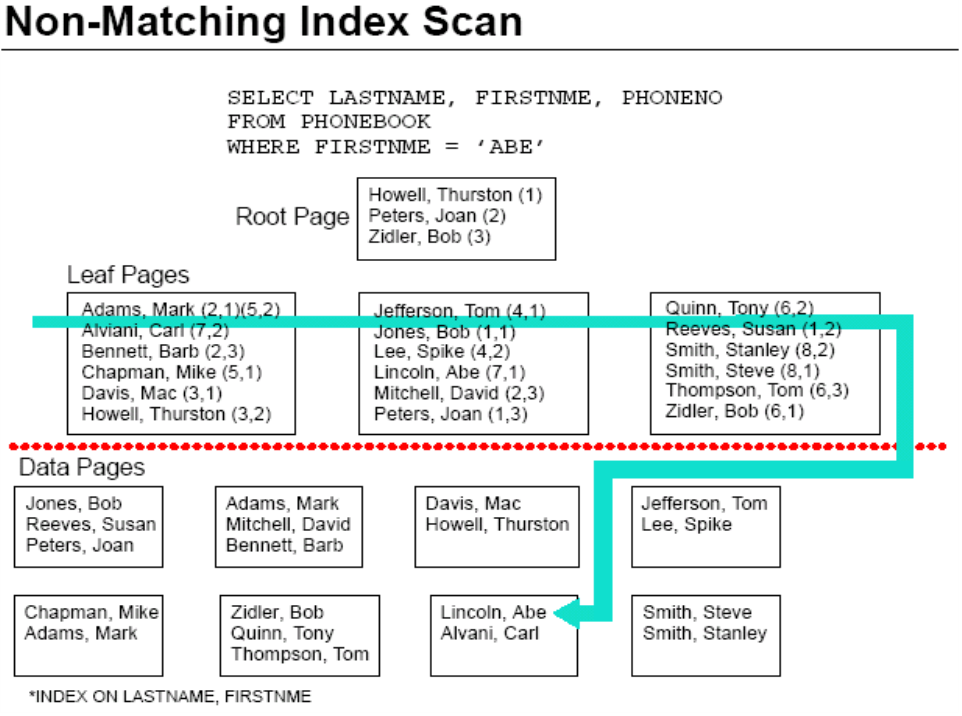
这个图就不再细说了,对比着上图就能看懂了。需要注意的是:因为无法使用主搜索码,扫描时就没有访问根结点页,直接遍历了所有的叶结点页(B+树的特点就是所有的搜索码都存在于叶结点页中)。
这种使用了索引但因为索引的主搜索码不可用(SQL语句中条件谓词不含主搜索码或含主搜索码的条件谓词是不可索引谓词)而必须逐个扫描索引叶结点页的索引扫描方式称为非匹配索引扫描。
疑问
这里就有一个疑问了:
既然非匹配索引扫描需要遍历索引的全部叶结点页,同样是遍历:表扫描直接遍历数据页,非匹配索引扫描则是遍历索引页然后找到数据页。那么这种情况为什么不直接进行表扫描呢?
我们知道,数据页和索引页是相同大小的页。数据页中的一条记录是一个数据行,索引页中的一条记录是一个索引项(搜索码+指针)。很显然,一个数据行通常会比一个索引项大很多,也就是说,一个相同大小的页,索引页中能容纳的记录数要远大于数据页中能容纳的记录数。假设一个数据页能容纳10行数据,一个索引页能容纳100个索引项,表中有10000行数据,那么需要的数据页为10000/10=1000页。而索引页只需10000/100=100页(由于可能存在搜索码重复的行以及DB2的索引压缩技术,实际需要的索引页会更少)。
如果使用非匹配索引扫描,只需要将100个索引页调入缓冲池逐个扫描然后将满足条件的数据页读入缓冲池,假设满足条件的数据页有10页,则总共需要的I/O次数为:
100+10=110次。
而如果使用表扫描,则需要将1000个数据页读入缓冲池然后逐个扫描,则总共需要的I/O次数为:1000次。
很显然,1000 >>110,另外,由于DB2采用的特殊算法,系统对索引页的扫描速度是远快于对数据页的扫描速度的。所以当然是使用非匹配索引扫描更好了。
那么既然扫描索引页更快且需要读入缓冲池的页面更少,为什么对于有索引,但条件谓词是不可索引谓词的情况却不使用索引扫描呢?
原因其实开始已经解释过了,不可索引谓词的特点是满足条件的行比不满足条件的行多得多,比如"<>(不等于)"这个条件,大部分页都是满足条件的,这就导致大量的满足条件的数据页需要被读入缓冲池。还是考虑上面的例子,如果使用非匹配索引扫描,则不仅要读100个索引页到缓冲池,还要读990个数据页,总共的I/O次数为100+990=1090次,大于直接使用表扫描的1000次。当然要选择表扫描了。
事实上,满足非匹配索引扫描条件的情况也不一定都是使用非匹配索引扫描的,因为有的情况下,表扫描的I/O开销仍然会优于非匹配索引扫描的I/O开销。而且成本估算也不单单考量I/O开销,优化器综合各种统计信息最终选择的最优访问计划很可能是表扫描而不是非匹配索引扫描。
直接索引查找
直接索引查找是一种比较特殊的索引查找方式。其意思是:如果SQL语句的Where子句后面的谓词包含了对索引中全部的搜索码的条件判断,那么就不需要对索引页进行扫描就可以直接定位了。例如表T1(C1,C2,C3,C4,C5)上建立索引CX(C1,C2,C3),现在有SQL查询:
Select * From T1 Where C1=10 And C2=5 And C3=3
索引上三个搜索码都在查询语句中给出了明确的条件,所以可以直接定位到相应索引页。
但是如果SQL查询语句是这样的:
Select * From T1 Where C1=10 And C2=5
那么由于C3未指定,满足C1和C2条件的索引项可能位于不同的索引页上(比如索引页A上有索引项[C1=10,C2=5,C3=2],索引页B上有索引项[C1=10,C2=5,C3=3],这两个索引项都是满足条件的,但位于不同的索引页),这就需要在找到第一个满足条件的索引页后对后面的索引页也要进行遍历才能保证不漏掉满足条件的索引项。可想而知,这样的索引结构只有所有行在C1和C2列上有大量重复值的情况下才出现。
第一种情况就是直接索引查找,第二种情况就是匹配索引扫描了。我们仍然可以认为直接索引查找就是匹配索引扫描的一种特例。就不进行单独讨论了。
只扫描索引(Index-Only Access)
这种索引扫描方式是所有索引扫描中效率最高的,因为它只需要扫描索引页,而无需将数据页读入缓冲池。
出现这种扫描的可能情况有两种:
A.索引是一个包含索引(要求索引是唯一索引),即索引包含了额外的列值,而SQL查询语句所查询的就是这个列值,那么直接在索引项中就能读取到所需的列值,自然不必去读对应的数据页了。
例如索引:
CREATE UNIQUE INDEX CX ON T1 ( C1 ) INCLUDE ( C2 )
SQL语句:
Select C2 From T1 Where C1=10
直接从索引页读取C2值。
B.要查询的列就在索引的搜索码中。
例如索引:
CREATE UNIQUE INDEX CX ON T1 ( C1,C2 )
SQL语句:
Select C2 From T1 Where C1=10
同样直接从索引页就能够读取C2值。
其实这两种情况本质上是一样的。下面也给一个只扫描索引的示意图:
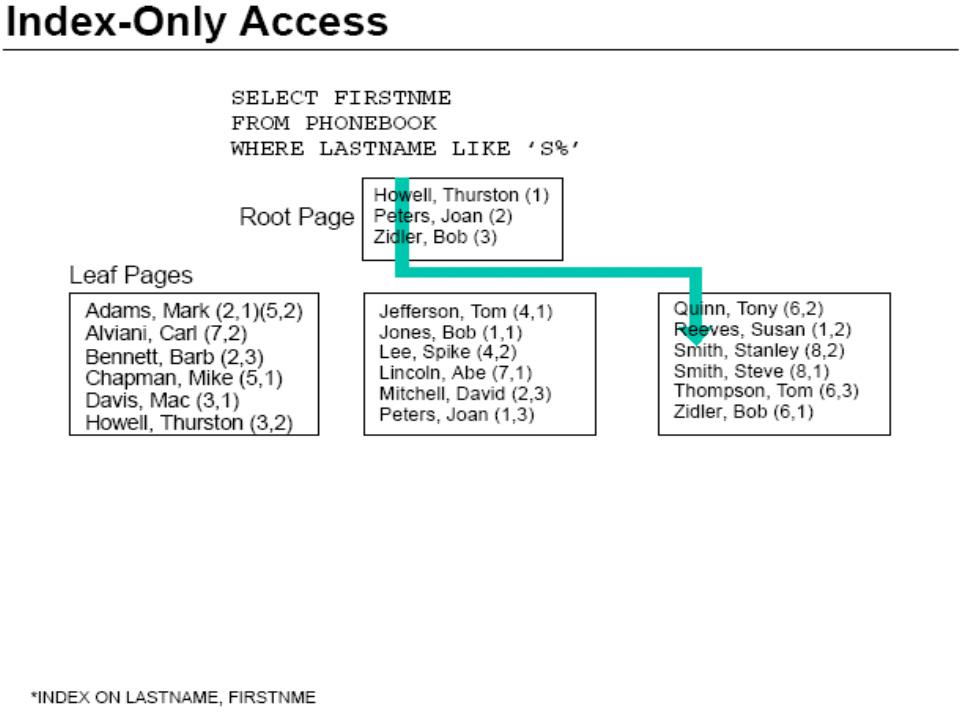
注:以下讨论的索引扫描都是匹配索引扫描
唯一索引扫描和非唯一索引扫描(Unique Index Scan and Non-Unique Index Scan )
唯一索引是指表中所有的数据行在索引列值上的值都是唯一的,不存在重复值。对于使用唯一索引和非唯一索引进行数据访问的扫描方式实际上区别不大,最主要的区别是二者的索引结构可能会有区别,这会导致进行索引扫描的I/O开销的不同(不过扫描索引的I/O开销通常是微不足道的),至于取数据页的开销就没有讨论的必要了,唯一索引扫描最终只需要将一个数据页读入内存,而非唯一索引扫描可能需要取若干页。下面以一个具体的例子解释一下唯一索引扫描和非唯一索引扫描。
有一张统计各手机号段的归属信息的表MOBILE,该表有ID、MOBILENUM、PROVINCE、CITY、MOBILETYPE、POSTCODE、AREACODE这7个列,表中有50000000行数据。表中一行数据的长度是400个字节(400B),其中MOBILENUM列长度为36B,CITY列长度为8B。表存储在4KB页的表空间中,假设为MOBILE表提供的所有数据页和索引页的PCTFREE都是0(即所有页空间都用于数据存储)。
一个数据行长度为400B,则一个4KB数据页能容纳4KB/400B=10行。容纳全部50000000行数据需要50000000/10=5000000页数据页。
现在在表Mobile上建立一个MOBILENUM列上的唯一索引NUM_IDX和一个在CITY列上的普通索引CITY_IDX。
先来考虑唯一索引NUM_IDX的结构
由于一个索引项由搜索码+逻辑指针(RID,行指示器)构成,NUM_IDX的搜索码MOBILENUM长度为36B,DB2中一个逻辑指针(RID)的长度为4B(这是常规表空间的RID,新版大型表空间的RID为6B),则一个索引项大小为36B+4B=40B;
一个索引页大小为4KB,除去数据页头部的空间占用,可用于存储索引项的空间为4000B,则一个索引页能够存储的索引项个数为4000B/40B=100个;
由于该索引是唯一索引,所以值不同的搜索码的个数与表中行的个数相同,为50000000行,即索引项的个数为50000000行。因此总共需要的叶结点索引页数为50000000/100=500000页;
一个索引页能够存储的索引项个数为100个,则根据B+树的特点,叶结点的上层非叶结点的个数最多为500000/100=5000页;
同理,该非叶结点的上层非叶结点的个数为最多为5000/100=50页。
50<100,因此该层非叶结点的上层为根结点。如此,该唯一索引的B+树为4层结构:根结点+2层非叶结点+页结点。
现在考虑该索引结构的开销:
对于SQL查询语句:
Select * From MOBILE Where MOBILENUM=1500000
很明显,需要扫描索引,首先向缓冲池读入根结点页,根据根结点读入满足条件的非叶结点页,然后再次读入下一级非叶结点页,最后读入符合条件的叶结点页。总共需要4次随机I/O;
然后根据叶结点页中的RID找到相应的数据页,读入该数据页,进行1次随机I/O;
因此,该查询总的I/O开销为:4次随机I/O+1次随机I/O。
再来考虑普通索引CITY_IDX的结构
由于CITY列上会有重复值,我们不妨假设所有的数据行中,不同的CITY值一共有100个,这就相当于每一个CITY值有50000000/100=500000个重复行。因此,对于索引中的一个搜索码值,可能对应500000个左右的逻辑指针(RID)。
由于DB2对于有重复值的搜索码采用的高效索引压缩技术,一个逻辑块中存储一个搜索码+N个逻辑指针(RID),这N个逻辑指针指向拥有该搜索码的N个不同的数据页。
由于这种逻辑块结构与先前讨论的索引项结构是完全不同的,所以只能用一种新的角度来讨论这种情况下的索引项了。(关于DB2索引逻辑块结构可以参看:《深入理解DB2索引(Index)》)
由于一个逻辑块最多可以包含255个RID,一个RID大小为4B,因此一个逻辑块大小为2B(逻辑块前缀的大小)+8B(CITY列的长度)+255*4B=1030B,为方便计算,以1000B计;
那么一个4KB页能容纳的逻辑块个数为4KB/1000B=4个。由于一个逻辑块中RID的个数为255个,因此一个4KB索引页中容纳了约1000个RID;
对于无重复搜索码值的索引而言,一个搜索码对应一个RID,即一个索引项对应一个RID,一个RID又对应一个数据行。那么,对于有重复搜索码值的情况,同样是一个RID对应了一个数据行,如果我们还是认为一个索引项由一个搜索码和一个RID构成的话,那么可以说:一个索引页中包含1000个索引项(因为一个索引页中有1000个RID呀,只是搜索码被压缩了,若干个RID共用了一个搜索码而已);
这个应该是可以理解的。但是要区分清楚,对于有重复搜索码值的索引,页结点索引页实际上是由若干个逻辑块组成的(一个逻辑块就是一个页中的一条记录),其效果等同于一个索引页包含了1000个索引项而已。毕竟,一个4KB页能容纳的记录数最大为255个(槽号只有1个字节大小),是不可能容纳1000条记录的;
还有一点需要注意:这种索引压缩技术仅仅应用于叶结点的索引页,因为非页结点和根结点的结构依然是“一个页对应若干个索引项,一个索引项对应一个RID”的结构,无需进行压缩。这一点应该也是可以理解的;
理解了索引压缩后,我们就可以继续按照之前的讨论方式进行计算了。
上面说了,一个叶结点索引页包含1000个索引项,那么对于50000000行数据,所需要的叶结点页的个数为50000000/1000=50000页;
由于非叶结点页没有使用压缩技术,索引项结构依然是搜索码长度+RID长度。则一个非叶结点页能容纳的索引项个数为4KB/(4B+8B)=333个,那么50000个叶结点页需要的上层非叶结点页个数最多为50000/333=151页;
151<333,故该非叶结点层的上层为根结点。如此,该普通索引的B+树结构为3层结构:根结点+1层非叶结点+叶结点;
现在考虑该索引结构的开销:
对于SQL查询语句:
Select * From MOBILE Where CITY='武汉'
很明显,需要扫描索引,首先向缓冲池读入根结点页,根据根结点读入满足条件的非叶结点页。这就需要2次随机I/O;
由于不同的CITY值一共有100个,总的数据行数为50000000行,那么我们可以认为CITY='武汉'的行数为500000行。由于一个叶结点页包含1000个RID,一个数据行对应一个RID,因此,至少要读入500000/1000=500个叶结点页。由于叶结点索引页通常是连续存储在磁盘上的,所以对于叶结点索引页的读取可以使用顺序预取I/O,即需要500次顺序预取I/O。
由于CITY='武汉'的各个数据行可能散落于各个数据页中,因此最多需要读入缓冲池的数据页为500000页,即进行500000次I/O,由于数据页不一定是连续的,因此最坏情况下,使用随机I/O进行这500000次读取。
因此,该查询总的I/O开销为:2次随机I/O+500次顺序预取I/O+500000次随机I/O。
其实,唯一索引扫描和非唯一索引扫描比较的意义并不大,因为通常,唯一索引扫描都会快于非唯一索引扫描,毕竟由于满足条件的行是唯一的,唯一索引扫描无论是在取索引阶段还是在取数据阶段,都只需要取一页。而非唯一索引扫描由于满足条件的行通常是不唯一的,取索引和取数据都需要取若干行。
之所以合起来介绍,只是想介绍一下索引页内部结构不同的两种索引扫描方式的I/O开销计算方法。
另外,在实际的数据库系统中,索引的根结点页和非叶结点页通常是常驻缓冲池的(因为频繁使用),它们无需花费I/O开销。
聚簇匹配索引扫描和非聚簇匹配索引扫描(Clustered Matching Index Scan and Non-Clustered Matching Index Scan)
这两种索引扫描方式其实没有什么区别,唯一的不同在于,对于聚簇匹配索引扫描,在进行数据页的读取的过程中,由于数据页是有序存储的,可以使用I/O顺序预取。而对于非聚簇匹配索引扫描,由于数据页通常是乱序的,所以只能使用I/O列表预取或者随机I/O。两种方式的效率自然是不能相提并论了。
不过要说明的是,对于非聚簇匹配索引扫描,并不是一定不能使用I/O顺序预取。如果优化器探知其数据页也是有序存放的(只是没有声称自己是聚簇的而已),同样可以使用I/O顺序预取。
比较简单,就不细说了。

