
索引 是帮助MySql高效获取数据的排好序的数据结构
Mysql中的索引底层使用的是B+树
为什么加索引能优化sql查询呢---
首先 如果对一条 select * from 表 where 条件; 假设这张表没有索引的情况下,执行这条sql语句是一条一条逐条查找的,
因为一张表最终是存储在磁盘的各个位置(查找一个位置就是一次I/O),磁盘存取=寻道时间(慢)+旋转时间(快);
假设将索引存储在二叉树中,二叉树中的每一个节点是一个 key--value,key 是索引列的值,value 是磁盘的位置(二叉树--左边节点小于根,右边节点大于根);然后再去执行上边的select语句,磁盘的I/O次数明显减少
那mysql底层为什么不用红黑树,二叉树,而要用B+树呢,
1.二叉树: 如果使用的是自增主键作为索引,那么,二叉树的节点全部在右子树上一次递增,查询速率和不用索引一样
2.红黑树:红黑树是一种平衡二叉树,告诉第2^n(n是高度),那么如果数据很大的话,红黑树的深度不可控,因为红黑树的一个节点只能存放两个数(key--value)
所以就可以横向扩容---B树,(左边节点的所有子元素都小于父节点,右边所有节点的所有子元素都大于父节点--多叉平衡树),B树中的value可以使地址,也可以是除去索引的其他值,取决于MySal的存储结构(MyISAM和InnoDB),但是B树的每个节点都带着value值,占用内存,并且在范围查找时,每次都要从头在查找
--最终使用的是B+树,B树的非叶子节点和叶子节点一样带着value值,但是B+树在给叶子节点只有key也就是只有索引的值,没有value值,存在着key的冗余,并且在叶子节点中多了指向下一个叶子节点的指针,这样在范围查找时提高了速率,
MySql的存储引擎是形容数据表的
MyISAM 索引实现(非聚集)---在mysql的安装位置的data文件中有三个文件 .frm(表结构) . MYD(表数据) .MYI(表索引)
InnoDB索引实现(聚集)----在mysql的安装位置的data文件中有两个文件 .frm (表结构) .idb (表结构和表数据)
对于MyISAM 叶子节点中data存储的是磁盘的地址,
对于InnoDB 叶子节点中data存储的是除了索引以外的其他数据 (InnoDB在现在经常使用)
那为什么B+树在非叶子节点中不存发data,而B树在非叶子节点存放data
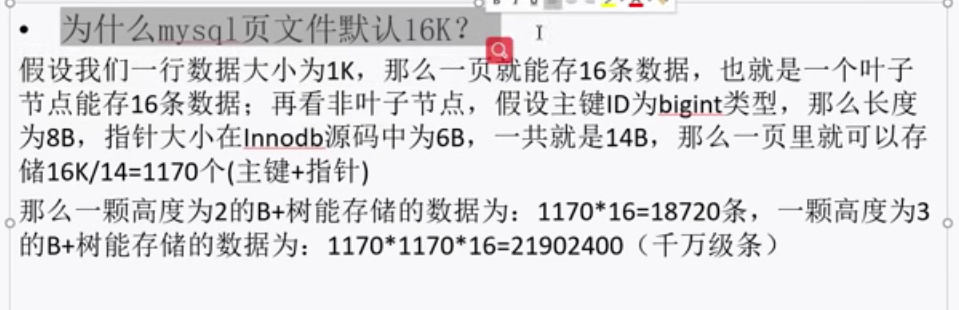
首先 可能有人会觉得既然B树可以扩容,横向有更多的节点,为什么不全部存放在第一个节点上呢?因为 操作系统中的加载单位是页,而cpu一次读取的页数是有限的,不能太多,所以一次I/O读不完横向存储的过多数据,不能够提高速度---所以mysql设定一个节点的大小是16K,所以将数据移到叶子节点,给非叶子节点更大的空间,存储更多的数。

为什么InnoDB推荐使用 整形的 自增的主键
整形:因为mysql查找的时候是通过二叉树比较大小查找的,明显 整形术比字符串更容易比较大小,而且 整形存储是占的空间也比字符串占用的空间小。
自增:使用自增的主键的话,节点是从左到右递增的,直接在末尾插入,但是 如果不是自增的,在插入的时候,B+树 需要做分裂,速度慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号