


转载:https://zhuanlan.zhihu.com/p/52233472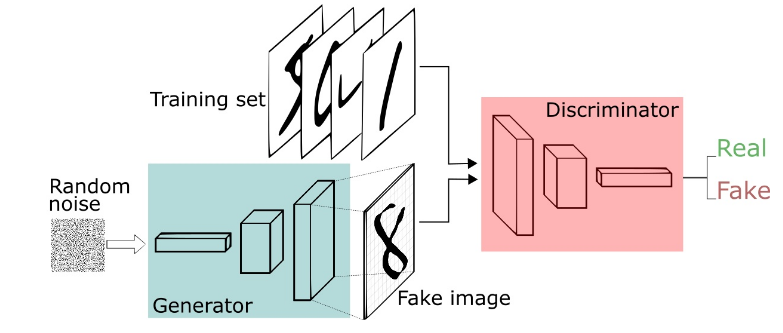
GAN由生成器(Generator)和判别器(Discriminator)组成。
生成器(Generator)
生成器的基本概念比较好理解,即给定训练集X,假设是几千张猫的图片。将一个随机向量输入给生成器G(x),让G(x)生成跟训练集类似的图片。话句话说,就是输入一个向量,通过一个NN,输出一个高维向量(可以是图片,文字...)通常Input向量的每一个维度都代表着一些特征。如下图:
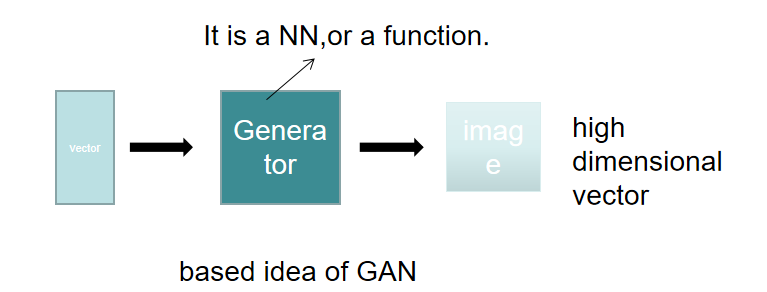
总的来说,生成器的目的是学习训练数据的分布,生成尽可能真实的猫图片,以确保判别器无法区分。
判别器(Discriminator)
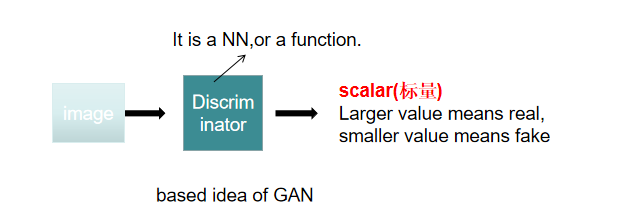
判别器D(x)是一个二分类分类器,其试图区分真实的猫图片和生成器生成的假猫图片。判别器需要不断地学习生成器的“造假图片”,以防止自己被欺骗。它的输入是你想产生的东西也就是生成器的output,比如一张图片,或者一段语音...它的输出是一个标量,这个标量代表的是这个Input的质量如何,这个数字越大,表示这个输入越真实
 生成器和判别器的关系
生成器和判别器的关系
两者之间好比一种博弈、竞争的关系。其实就是生成器生成一个东西,输入到判别器中,然后由判别器来判断这个输入是真实的数据还是机器生成的,如果没有骗过判别器,那么生成器继续进化,输出第二代Output,再输入判别器,判别器同时也在进化,对生成器的output有了更严格的要求。这样生成器和判别器不断进化,形成一种竞争关系。
GAN的算法流程
1.初始化generator和discriminator
2每一次迭代过程中:
1)固定generator,只更新discriminator的参数。从准备的数据集中随机选择一些,再从generator的output中选择一些,现在等于discriminator有两种input,然后discriminator的学习目标就是如果input是来自于真实数据集,则给高分,反之,给低分。
2)接下来,固定discriminator的参数,更新generator。将一个向量输入generator,得到一个output,将output丢进discriminator,然后会得到一个分数,这个阶段的discriminator的参数已经被固定了,generator需要调整自己的参数使得这个output的分数越大越好。
GAN算法——具体操作
初始化 for D( discriminator) ,
for G( generator)
在每次迭代中:
- 从数据集
中sample出m个样本点
,这个m也是一个超参数,需要自己去调
- 从一个分布(可以是高斯,正态..., 这个不重要)中sample出m个向量
- 将第2步中的z作为输入,获得m个生成的数据
- 更新discriminator的参数
来最大化
, 我们要使得
越小越好,也就是去压低generator的分数,会发现discriminator其实就是一个二元分类器:
(
也是超参数,需要自己调)
1~4步是在训练discriminator, 通常discriminator的参数可以多更新几次
5. 从一个分布中sample出m个向量 注意这些sample不需要和步骤2中的保持一致。
6. 更新generator的参数 来最小化:
5~6步是在训练generator,通常在训练generator的过程中,generator的参数最好不要变化得太大,可以少update几次。

