

1.硬件问题
1)硬盘:查看/var/log/daemon, kern日志,smartctl测试,EUD
2)PSU: 查看LCD报警,/var/log/ltm,EUD等
3)内存:可能导致设备突然重启或无法启动,查看console日志等
4)其他:日志,EUD等
2.软件、告警、网络等问题
1)重启,切换,进程重启等,可以查看进程状态(bigstart status) ,日志/var/log/ltm及tmm等。
2)网络,业务问题一定要抓取Tcpdump。
3.一般故障现场需要收集的信息
1)抓包文件:
使用tcpdump在F5上抓包,如果有可能在backend server/client machine同时抓包或同时在浏览器运行httpwatch,抓包命令如下:
#tcpdump–nni0.0:nnn –s0 –w /var/tmp/xxxx.cap host <client IP> or host <VIP> or host <pool member IP 1> or host <pool member IP2>
*由于F5采用的是full-proxy模式,抓客户IP和VIP只能抓到客户端的traffic,不能抓到server端的,请进行抓包时多加考虑,添加合适的IP地址
*可以添加端口号或协议名抓取特定的数据包
*可以加-c 抓取一定数量的包,针对业务流量大的情况下
*如果抓包文件是关于ssl流量的,请用ssldump命令在F5上解开tcpdump,解成明文,然后将解密的明文和tcpdump一起提交给support,便于查看:
抓取qkview:qkview尽量在故障的时候抓取,重启之后抓取的qkview十分干净,几乎看不出来任何信息。命令如下:
# qkview, then take out $HOSTNAME.tech.outfrom /var/tmp/
抓取log日志,这个一定要抓取,qkview中的log不全。命令如下:
# tar zcvf/var/tmp/$HOSTNAME-logs.tar.gz /var/log/*, then take out $HOSTNAME-logs.tar.gz from /var/tmp/
抓取RRD data tarball:
# tar zcvf/var/tmp/$HOSTNAME-rrd.tar.gz /var/rrd/*, then take out $HOSTNAME-rdd.tar.gz from /var/tmp/
抓取SCCP log tarball:
# sshsccp"tar czvf-/var/log/" > /var/tmp/$HOSTNAME-sccp-logs.tar.gz, then take out $HOSTNAME-sccp-logs.tar.gz from /var/tmp/
2) 抓取故障截图,在客户端是什么表现?网页打不开?服务能否登录?客户收到了什么样的报错信息?
3) 如果怀疑硬件问题,尽快安排时间做EUD。运行EUD的时候请拔下所有的网线,连好console,留存console output,和EUD report一起提交给support以节省时间。
4.1)两台F5设备均为ACTIVE状态
不对业务造成影响,但存在隐患
处理方案:
1.确认两台active状态的F5设备中,哪一台是当前在用的,通过以下两种方式进行确认,正常情况下,因为冗余连接失效,当前在用的F5设备应该是原先备用的那一台。
1)使用https登录到两台F5设备的shared ip,查看是哪一台设备;
2)在核心交换机上查看arp表中,以cisco交换机命令为例,show ip arp“shared ip”,确认对应的是哪一台F5设备的MAC地址。
3)检查心跳线连接,排除由于心跳线松动造成冗余连接失败的情况。
4)心跳线连接恢复正常后,对当前处在备用状态的F5设备进行重启操作(应该是原先主用的那台F5设备)。这时网络中会恢复为只有一台主用F5设备的情况(重启备机不会影响业务)。
2)主用F5设备发生故障
具体现象:主用F5上所有业务受到影响。
影响范围:该套F5上所有业务。
处理方案:
1、行进行主备切换,检测是否切换成功。
2、如果失败,则通过下电方式关闭主用故障F5。
3、SSH方式登陆备机,判断备机状态是否已经变为active。
3)两台F5设备同时出现故障
具体现象:两台F5设备同时不可用,该套F5上所有业务受到影响。
影响范围:该套F5上所有业务。
处理方案:
1、强制切换,关闭原先主用的F5设备,检测是否切换成功。
2、如果仍然故障,则关闭原先备用的F5设备,下电重启原先主用设备后,检测系统状态。
3、仍不能恢复正常的话,采用冷备设备作为应急。
4)客户端异常行为导致F5性能容量耗尽
具体现象:主用F5设备出现CPU或内存利用率持续超警戒阀值(警戒阀值的具体值可根据该套F5所承载的应用数量及性能状况等因素来设定)。
网络部监控到F5产生如下告警:Inetport exhaustion on X.X.X.X to A.B.C.D:X (proto 6)。
安全部监控到分行某个客户端X.X.X.X向此套F5设备上的某个访问地址A.B.C.D大量发异常数据包。
影响范围:该套F5上所有业务。
处理方案:
1、确认客户端X.X.X.X是否与此套F5设备上的某个访问地址A.B.C.D大量建立连接。
2. 登录相应与F5互联的交换机,将客户端X.X.X.X进行隔离
3. 通过命令行:top或网管proviso系统确认此台F5设备性能容量是否恢复正常(CPU及内存利用率均处于30%以下)。
5)F5并发连接数超阀值
具体现象:网络部监控发现F5并发连接数超阀值,且持续时间较长。
影响范围:该套F5上业务均受到不同程度影响。
处理方案:
1、HTTPS方式登陆F5,依次点击“Virtual Server”->“Statistics”,确认当前访问量最高的3个应用;
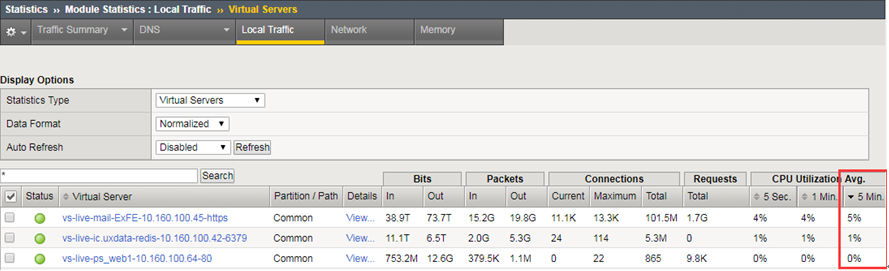
2、临时规避方法为在F5上限制这3个应用的并发连接数,由于会影响到正常访问,需征求相关部门意见;
3、登陆相关F5,进入相应Virtual Server,临时将connection limit设置为XXX(一般为服务器台数*100),待F5并发连接数恢复正常后,再商开发中心、应用部门逐步调大connection limit限制;
4、网络尽快确定方案,利用备机,完成F5扩容,彻底解决F5并发连接数高对设备造成冲击,届时再取消connection limit限制。


