


Docker提供了两个版本:社区版(CE)和企业版(EE)。
Docker社区版(CE)是开发人员和小型团队开始使用Docker并尝试使用基于容器的应用的理想之选。Docker CE有两个更新渠道,即stable和edge:
- Stable每个季度为您提供可靠更新
- Edge每个月为您提供新功能
Docker企业版(EE)专为负责在生产环境中大规模构建、交付和运行业务关键型应用程序的企业开发和 IT 团队设计
docker-ce安装
配置yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum list docker-ce.x86_64 --showduplicates | sort -r
yum install docker-ce -y
systemctl start docker
systemctl enable docker
systemctl status docker
离线安装,可事先下载rpm包(https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/7/x86_64/stable/Packages/),使用yum localinstall或rpm -ivh安装
宿主机开启ip转发(docker安装完成后直接启动docker程序不会自动开启,重启一次docker即可自动开启,docker守护程序默认启用--ip-forward选项)
为dockerd设置NDS服务器/开启IPv6支持(仅linux支持)/加速器配置:
cat >>/etc/docker/daemon.json<<-end
{
"dns": ["1.1.1.1","10.0.91.7"],
"ipv6":"true",
"registry-mirrors": ["https://registry.docker-cn.com"]
}
end
systemctl restart docker
docker --version
docker info
docker run hello-world
Docker Daemon连接方式
Docker为C/S架构,服务端为docker daemon,客户端为docker.service,支持本地unix socket域套接字通信与远程socket通信。
默认为本地unix socket通信,要支持远程客户端访问需要做如下设置(不安全,仅用于测试),
1. UNIX域套接字
默认就是这种方式,会生成一个/var/run/docker.sock文件,UNIX域套接字用于本地进程之间的通讯, 这种方式相比于网络套接字效率更高,但局限性就是只能被本地的客户端访问。
2. TCP端口监听
服务端开启端口监听 dockerd -H|--host IP:PORT , 客户端通过指定IP和端口访问服务端 docker -H IP:PORT
通过这种方式,任何人只要知道暴露的ip和端口就能随意访问docker服务(因为docker的权限很高,一旦被突破就能够取得服务端宿主机的最高权限)
3. 启动docker守护进程时可以同时监听多个socket
dockerd -H unix:///var/run/docker.sock -H tcp://127.0.0.1:2376 -H tcp://127.0.0.1:2377
...
INFO[0004] API listen on 127.0.0.1:2377
INFO[0004] API listen on /var/run/docker.sock
INFO[0004] API listen on 127.0.0.1:2376
启用TLS安全连接
上述的http方式远程连接很不安全,解决的办法是启用TLS证书实现客户端和服务端的双向认证, 以此来保证安全性。
创建TLS证书(根证书、服务端证书、客户端证书)
cat gencert.sh
#/bin/bash
#
if [ $# != 1 ] ; then
echo "USAGE: $0 [HOST_IP]"
exit 1;
fi
COUNTRY=CN
PROVINCE=Jiangsu
CITY=Nanjing
ORGANIZATION=Hiynn
GROUP=Quality
HOST=$1
EMAIL=haiyun@hiynn.com
SUBJ="/C=$COUNTRY/ST=$PROVINCE/L=$CITY/O=$ORGANIZATION/OU=$GROUP/CN=$HOST/emailAddress=$EMAIL "
echo "the host(IP) is: $1"
# 1.生成根证书RSA私钥,PASSWORD作为私钥文件的密码(这里一旦设定密码,后面在使用该私钥时,必须提供密码)
openssl genrsa -aes256 -out ca-key.pem 4096
# 2.用根证书RSA私钥生成自签名的根证书
openssl req -new -x509 -days 3650 -key ca-key.pem -sha256 -out ca.pem -subj $SUBJ
# 3.生成服务端私钥
openssl genrsa -out server-key.pem 4096
# 4.生成服务端证书请求文件
openssl req -new -sha256 -key server-key.pem -out server.csr -subj "/CN=$HOST"
# 5.使tls连接能通过ip地址方式,绑定IP
echo subjectAltName = IP:127.0.0.1,IP:$HOST > extfile.cnf
# 6.使用根证书签发服务端证书
openssl x509 -req -days 3650 -sha256 -in server.csr -CA ca.pem -CAkey ca-key.pem -out server-cert.pem -CAcreateserial -extfile extfile.cnf
# 7.生成客户端私钥
openssl genrsa -out key.pem 4096
# 8.生成客户端证书请求文件(这里这里的/CN=client,client为客户端主机的主机名或IP地址)
openssl req -subj '/CN=client' -new -key key.pem -out client.csr
# 9.客户端证书配置文件
echo extendedKeyUsage = clientAuth > extfile.cnf
# 10.使用根证书签发客户端证书
openssl x509 -req -days 3650 -sha256 -in client.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out cert.pem -extfile extfile.cnf
# 删除中间文件(可选)
rm -fm client.csr server.csr ca.srl extfile.cnf
# 移动文件
mkdir client server
cp {ca,cert,key}.pem client
cp {ca,server-cert,server-key}.pem server
rm {cert,key,server-cert,server-key}.pem
# 设置私钥权限为只读
chmod -f 0400 ca-key.pem server/server-key.pem client/key.pem
执行服务端配置
给脚本添加运行权限
chmod +x gencert.sh
HOST_IP=127.0.0.1
./gencert.sh $HOST_IP
# 客户端需要的证书保存在client目录下, 服务端需要的证书保存在server目录下
cp server/ca* /etc/docker
# 修改配置
cat >> /etc/default/docker<<end
DOCKER_OPTS="\
--selinux-enabled \
--tlsverify \
--tlscacert=/etc/docker/ca.pem \
--tlscert=/etc/docker/server-cert.pem \
--tlskey=/etc/docker/server-key.pem \
-H=unix:///var/run/docker.sock \
-H=0.0.0.0:2375"
end
vi /lib/systemd/system/docker.service [Service]中添加如下一行
EnvironmentFile=/etc/default/docker
systemctl daemon-reload
systemctl restart docker
systemd服务文件介绍:
http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-part-two.html
如果不想进行上述配置,可将配置文件写入到/etc/docker/daemon.json文件中
cat >>/etc/docker/daemon.json<<end
--selinux-enabled \
--tlsverify \
--tlscacert=/etc/docker/ca.pem \
--tlscert=/etc/docker/server-cert.pem \
--tlskey=/etc/docker/server-key.pem \
-H=unix:///var/run/docker.sock \
-H=0.0.0.0:2375"
end
接着按之前的方式连接服务端就出错了
docker -H tcp://127.0.0.1:2375 version
API访问同样报错:
Get http://127.0.0.1:2375/v1.29/version: malformed HTTP response "\x15\x03\x01\x00\x02\x02".
* Are you trying to connect to a TLS-enabled daemon without TLS?
正确的访问方式:
# 客户端加tls参数访问
docker --tlsverify --tlscacert=client/ca.pem --tlscert=client/cert.pem --tlskey=client/key.pem -H tcp://127.0.0.1:2375 version
# Docker API方式访问
curl https://127.0.0.1:2375/images/json --cert client/cert.pem --key client/key.pem --cacert client/ca.pem
# 简化客户端调用参数配置
cp client/* ~/.docker
# 追加环境变量
echo -e "export DOCKER_HOST=tcp://$HOST_IP:2375 DOCKER_TLS_VERIFY=1" >> ~/.bashrc
docker version
docker三大组件
镜像、容器、仓库
1、镜像
docker images
-q 仅显示容器的ID
-a 显示所有镜像(中间层镜像也会显示出来),可能会看到很多无标签的镜像,这些镜像是其它镜像的依赖镜像,不可删除
-f 过滤器: dangling=true过滤出虚悬镜像;
before|since=mysql:5.6 过滤出mysql:5.6之前或之后建立的所有镜像
如果构建镜像时指定了label,也可通过label过滤(docker images -f label=...)
--format 按照go模板显示
示例:
docker images --format "{{.ID}}: {{.Repository}}"
docker images --format "table {{.ID}}\t{{.Repository}}\t{{.Tag}}"
docker rmi <Images ID> #删除镜像
docker inspect <Images ID> #显示镜像的详细信息
docker image prune #要删除悬空(dangling)图像:
docker image prune -a #删除现有容器未使用的所有图像,请使用以下-a标志
使用带有--filter标志的过滤表达式限制修剪哪些图像。例如,要仅考虑超过24小时前创建的镜像:
docker image prune -a --filter "until=24h"
docker search centos
docker pull centos
docker image ls
docker save centos > /opt/centos.tar.gz #保存镜像
docker save -o centos.tar.gz centos #同上
docker load < /opt/centos.tar.gz #加载镜像
docker load --input /opt/centos.tar.gz #同上
docker run -itd --name test centos [/bin/bash]
docker attach
nsenter
docker login
docker pull
docker push
构建镜像
yum install python2-pip
配置pip国内源
mkdir -p /root/.pip
cat >> /root/.pip/pip.conf<<end
[global]
trusted-host=mirrors.aliyun.com
index-url=http://mirrors.aliyun.com/pypi/simple/
end
构建镜像指令:docker build 或docker image build
Dockerfile初识:
cat >>Dockerfile<<end
FROM python:2.7-slim
WORKDIR /app
ADD . /app
RUN pip install -r requirements.txt
EXPOSE 80
ENV NAME World
CMD ["python", "app.py"]
end
cat >>requirements.txt<<end
Flask
Redis
end
cat >> app.py<<end
from flask import Flask
from redis import Redis, RedisError
import os
import socket
# Connect to Redis
redis = Redis(host="redis", db=0, socket_connect_timeout=2, socket_timeout=2)
app = Flask(__name__)
@app.route("/")
def hello():
try:
visits = redis.incr("counter")
except RedisError:
visits = "<i>cannot connect to Redis, counter disabled</i>"
html = "<h3>Hello {name}!</h3>" \
"<b>Hostname:</b> {hostname}<br/>" \
"<b>Visits:</b> {visits}"
return html.format(name=os.getenv("NAME", "world"), hostname=socket.gethostname(), visits=visits)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
end
docker build -t friendlyhello .
Dockerfile详解:
格式:
# Comment
INSTRUCTION arguments
注意事项:
1)、如果一行太长,使用反斜线 \ 续行
2)、在行首使用#符号,表示注释(注释中不支持 \续行)
3)、INSTRUCTION不区分大小写。惯例是让它们成为大写的,以便更容易地将它们与参数区分开来
共18个指令
1、FROM #必要指令,通常是第一条(引用变量及多阶段构建例外),可有多条(多阶段构建)
FROM <image> [AS <name>]
或
FROM <image>[:<tag>] [AS <name>]
或
FROM <image>[@<digest>] [AS <name>]
scratch镜像:
FROM scratch
ADD hello /
CMD ["/hello"]
说明:
1、可通过添加AS name来为该构建阶段命名。该名称可用于后续FROM和COPY --from=<name|index>指令,以引用此阶段构建的镜像。
2、tag或digest值是可选的。如果省略其中任何一个,则构建器默认采用latest标记
3、FROM指令支持变量,变量在第一个FROM指令之前使用ARG声明
ARG CODE_VERSION=latest
FROM base:${CODE_VERSION}
CMD /code/run-app
2、MAINTAINER 镜像维护者信息
MAINTAINER username@domain.com
说明:指定该镜像维护者信息,尽量使用LABEL替代
docker inspect <Container ID> |grep -A 6 Labels
3、RUN 执行命令
用来执行命令,有2种格式
格式一:
shell格式: RUN <命令>
如:RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html
说明:
1、这种格式在shell中运行,会转换为/bin/sh -c <命令>执行
2、可以使用SHELL命令更改默认的shell,或使用exec形式
3、要使用除“/bin/sh”之外的其他shell,请使用exec形式。例如,RUN ["/bin/bash", "-c", "echo hello"]
4、命令中支持变量扩展
示例:
RUN /bin/bash -c source $HOME/.bashrc; \
echo $HOME'
格式二:
exec格式: RUN ["executable", "param1", "param2"]
说明:
1、 这种格式不会被转换
2、 不支持变量扩展
3、 exec形式被解析为JSON数组,这意味着必须使用双引号(")来包括单词而不是单引号(')
4、 在JSON形式中,必须转义反斜杠\(windows中作为路径分隔符经常遇到)
注意:
1、可使用反斜杠(续行符)分隔的多行上拆分长或复杂语句,使Dockerfile更具可读性,可理解性和可维护性
示例:
RUN yum update && yum install -y \
package-bar \
package-baz \
package-foo=1.3.*
2、使用管道
某些RUN命令依赖于使用管道符(|)将一个命令的输出传递到另一个命令的能力,如下例所示:
RUN wget -O - https://some.site | wc -l > /number
Docker使用/bin/sh -c解释器执行这些命令,解释器仅评估管道中最后一个操作的退出代码以确定成功。
在上面的示例中,只要wc -l命令成功,即使wget命令失败,此构建步骤也会成功并生成新映像。
如果希望命令因管道中任何阶段的错误而失败,预先使用set -o pipefail 设置bash环境变量,确定意外错误可防止构建无意中成功。
例如:
RUN set -o pipefail && wget -O - https://some.site | wc -l > /number
注:并非所有shell都支持该-o pipefail选项
4、CMD 为执行容器提供默认值 #只能有一条,如果列出多个只有最后一条生效
有三种形式:
- CMD ["executable","param1","param2"](exec形式,这是首选形式)
- CMD command param1 param2(shell形式)
- CMD ["param1","param2"](必须配合ENTRYPOINT使用,作为其默认参数,单独使用无效果)
说明:
1)exec形式不支持变量扩展,shell形式支持
2)exec形式被解析为JSON数组,这意味着必须使用双引号(")来包括单词而不是单引号(')
3)在JSON形式中,必须转义反斜杠\(windows中经常遇到)
注意:不要混淆RUN和CMD。RUN实际上运行一条命令并提交结果,CMD在构建过程中不执行任何操作,而是作为镜像的默认指令(即使用该镜像启动容器时默认执行的指令)。
5、LABEL 将元数据添加到镜像
LABEL <key>=<value> <key>=<value> <key>=<value> ...
LABEL是键值对,要在LABEL值中包含空格,请使用(双)引号或反斜杠转义,就像在命令行解析中一样
示例:
LABEL "com.example.vendor"="ACME Incorporated"
LABEL com.example.label-with-value="foo"
LABEL version="1.0"
LABEL description="This text illustrates \ #续行符
that label-values can span multiple lines."
镜像可以有多个标签,可以在一行中指定多个标签:
两种示例:
LABEL multi.label1="value1" multi.label2="value2" other="value3"
LABEL multi.label1="value1" \
multi.label2="value2" \
other="value3"
6、EXPOSE 容器运行时侦听其服务端口
EXPOSE <port1> [<port2>/<protocol>...] #多个端口之间使用空格间隔
EXPOSE指令通知Docker容器在运行时侦听指定的网络端口。
可以指定端口是侦听TCP还是UDP,如果未指定协议,则默认为TCP
7、ENV 设置环境变量
有两种形式:
形式一:
ENV <key> <value> #第二个空格后的整个字符串将被视为<value>,包括空格字符
形式二:
ENV <key>=<value> ... # ENV指令将环境变量<key>的值设置为<value>
该环境变量在构建阶段所有后续指令的环境中生效,并且使用ENV设定的环境变量会在镜像中一直存在
示例:
ENV myName="John Doe" myDog=Rex\ The\ Dog \
myCat=fluffy
和
ENV myName John Doe
ENV myDog Rex The Dog
ENV myCat fluffy #效果相同
ENV指令中可使用变量:
ENV abc=hello
ENV abc=bye def=$abc
ENV ghi=$abc
示例:
ENV PG_MAJOR 9.3
ENV PG_VERSION 9.3.4
RUN curl -SL http://example.com/postgres-$PG_VERSION.tar.xz | tar -xJC /usr/src/postgress &&…
ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH
注意:
1、可以使用docker inspect查看变量值,使用docker run --env <key>=<value>在构建容器时更改变量的值。
2、Dockerfile中能够扩展变量的指令:
FROM/ADD/COPY/ENV/EXPOSE/LABEL/STOPSIGNAL/USER/VOLUME/WORKDIR/ONBUILD
8、ARG #设置构建过程中的环境变量
格式:
ARG <参数名>[=<默认值>]
ARG指令可以可选地包括一个默认值:
示例:
FROM busybox
ARG user1=someuser #指定了默认值
ARG buildno=1 #指定了默认值
...
说明:
如果ARG指令具有默认值,并且在构建时没有传递值,将使用默认值,
如果构建时传递值,将不使用默认值,而是用传递的值
注意:
1、效果和ENV一样,都是设置环境变量,不同的是:ARG设置的环境变量,在将来容器运行时,不再存在,仅在构建镜像时存在
2、可在构建命令docker build使用--build-arg <参数名>[=<值>]选项覆盖Dockerfile中设定的默认值,参数名必须在Dockerfile中已经使用ARG指令构建,否则会报错或警告
3、一个ARG指令生效范围,在其之后,且在其构建阶段内。若在多阶段构建中的每个阶段均使用ARG,每个阶段都必须包含ARG指令。
示例:多阶段构建
FROM busybox
ARG SETTINGS
RUN ./run/setup $SETTINGS
FROM busybox
ARG SETTINGS
RUN ./run/other $SETTINGS
4、Dockerfile可以包括一个或多个ARG指令。
例如,以下是有效的Dockerfile:
FROM busybox
ARG user1
ARG buildno
...
警告:
不要使用构建时变量来传递密码,如github密钥,用户凭据等,构建时变量值对于任何用户都是可见的
5、ARG生效范围
ARG变量定义从Dockerfile中定义的行开始生效,直到其所在构建阶段结束
示例:
FROM busybox
USER ${user:-some_user}
ARG user
USER $user
...
通过以下指令构建:
$ docker build --build-arg user=what_user .
第2行USER使用some_user作为user变量的值。
第4行USER使用what_user作为user变量的值,且what_user在命令行上传递的值。
在通过ARG指令定义之前,对变量的任何使用都会导致空字符串
6、使用ARG变量
可以使用ARG或ENV指令指定在RUN指令中可用的变量。ENV指令定义的环境变量始终覆盖ARG定义的同名变量。
示例:
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER v1.0.0
RUN echo $CONT_IMG_VER
然后,假设使用此命令构建此映像:
$ docker build --build-arg CONT_IMG_VER=v2.0.1 .
在这种情况下,RUN指令使用v1.0.0而不是ARG用户传递的设置:v2.0.1,
9、COPY 复制上下文中的文件或目录到容器中
COPY有两种形式:
- COPY [--from=<name|index>] [--chown=<user>:<group>] <src>... <dest>
- COPY [--from=<name|index>] [--chown=<user>:<group>] ["<src>",... "<dest>"](包含空格的路径使用此形式)
--chown功能仅在用于构建Linux容器
注意:
1、源路径,一定是相对于build指令中指定的上下文的相对路径
如COPY package.json /usr/src/app/
2、目标路径,可以是容器内的绝对路径,也可以是相对于工作目录的相对路径(工作目录可以使用WORKDIR指令来指定)
3、目标路径不需要事先创建,如果目录不存在,在复制文件之前会自动创建
4、使用COPY指令时,源文件的各种元数据都会被保留,如读写执行权限,文件的相关时间属性等
5、源路径可以是多个,甚至可以含有通配符,通配符要符合Go的filepath.Match规则:
COPY hom* /mydir
COPY hom?.txt /mydir
6、如果使用--chown选项,最好使用数字形式的GID和UID(如果使用用户名和组名,在容器文件系统中不存在/etc/passwd及/etc/group,将会导致构建失败)
示例:
COPY --chown=55:mygroup files* /somedir/
COPY --chown=bin files* /somedir/ #不指定组名,使用与用户名同名的组
COPY --chown=1 files* /somedir/ #GID也为1
COPY --chown=10:11 files* /somedir/
7、(可选)COPY接受一个标志--from=<name|index>
该选项将用于替代用户发送先前构建阶段的构建上下文
如果先前构建阶段使用FROM .. AS <name>,则--from可通过name引用
如果先前构建阶段未使用FROM ..
AS <name>,则--from可通过索引值index引用,如果先前构建阶段是第一阶段,index为0,以此类推
如果找不到具有指定名称的构建阶段,则尝试使用具有相同名称的镜像
COPY遵守以下规则:
- <src>路径必须位于build构建时的context上下文中;不能COPY ../something /something,因为第一步docker build是将上下文目录(和子目录)发送到docker守护程序
- 如果<src>是目录,则复制目录中的全部内容,包括文件系统元数据
注意:不复制目录本身,只复制其内容
- 如果<src>是任何其他类型的文件,则将其与元数据一起单独复制。在这种情况下,如果<dest>以尾部斜杠结尾/,则将其视为目录,<src>并将写入内容<dest>/base(<src>)。
- 如果<src>直接或由于使用通配符指定了多个资源,则<dest>必须是目录,并且必须以斜杠结尾/。
- 如果<dest>不以尾部斜杠结束,则将其视为常规文件,并将<src>的内容写入<dest>文件中。
- 如果<dest>不存在,则会在其路径中创建所有缺少的目录。
10、ADD 复制本地文件到上下文中
从<src>中复制文件、目录或远程文件URL,并将它们添加到路径上镜像的文件系统<dest>中
ADD有两种形式:
- ADD [--chown=<user>:<group>] <src>...<dest>
- ADD [--chown=<user>:<group>] ["<src>",..."<dest>"](包含空格的路径需要使用这种形式)
ADD指令的所有使用注意事项及遵守规则与COPY相同
与COPY不同的是:
源路径:
1、可以是URL,Docker引擎会尝试下载这个链接文件,放入到<dest>中,下载后文件的权限为600,若是想更改文件的权限,还需要增加一层RUN指令
2、如果下载的是压缩包,还需要增加一层RUN指令进行解压
3、如果<src>是一个上下文中的tar压缩文件(gzip、bzip2、xz),ADD指令会自动解压放入到<dest>中,如果不希望压缩文件解压,则使用COPY(这是ADD指令最大的用处)
4、仅在需要自动解压时,才会选择使用ADD指令,否则复制文件尽可能使用COPY
5、ADD指令会令镜像构建缓存失效,从而可能使镜像构建过程非常缓慢(因此多阶段构建时,尽可能不要使用)
11、ENTRYPOINT 入口点 #只能有一条,若有多条仅最后一条生效
ENTRYPOINT有两种形式:
- ENTRYPOINT ["executable", "param1", "param2"](exec形式,首选)
- ENTRYPOINT command param1 param2(shell形式,最好在command前使用exec指令,以使该进程作为容器的PID 1进程)
exec形式:
docker run <image>的命令行参数将附加在exec形式的ENTRYPOINT的所有元素之后,作为ENTRYPOINT指令的参数,并将覆盖所有使用CMD指定的元素。
可以使用docker run --entrypoint标志覆盖exec形式的ENTRYPOINT指令
shell形式:
shell形式防止任何被CMD或run使用的命令行参数,缺点是ENTRYPOINT将被作为/bin/sh -c的一个子命令,且不传递信号。这意味着可执行文件将不是容器中PID为1的进程,并且不会收到Unix信号,因此可执行文件将不会收到来自docker stop <container>的SIGTERM信号。
从命令行工具的镜像示例:
cat >>Dockerfile<<end
FROM centos
RUN yum install curl -y
CMD ["curl", "-s", "http://ip.cn"]
end
docker build -t myip:1.0 .
docker run --name myip01 myip:1.0
docker run --name myip02 myip:1.0 -i #此时会报错
原因:执行docker run myip -i 镜像名称myip后的手动指定的主进程将会替换构建镜像时CMD指定的主进程,
这里替换后相当于执行-i指令,但实际上没有该指令,提示executable file not found in $PATH
正确用法:docker run myip curl -s http://ip.cn -i
使用ENTRYPOINT解决:
使用如下的dockerfile构建镜像
cat >> Dockerfile<<end
FROM centos
RUN yum install curl -y
ENTRYPOINT ["curl", "-s", "http://ip.cn"]
end
docker build -t myip2:1.0 .
docker run --name myip201 myip2:1.0
docker run --name myip202 myip2:1.0 -i
这种方式很有用,因为镜像名称可以兼作二进制文件的引用
ENTRYPOINT指令还可以与辅助脚本结合使用,使其能够以与上述命令类似的方式运行,即使启动该工具可能需要多个步骤
例如,Postgres官方镜像使用以下脚本作为其ENTRYPOINT:
#!/bin/bash
set -e
if [ "$1" = 'postgres' ]; then
chown -R postgres "$PGDATA"
if [ -z "$(ls -A "$PGDATA")" ]; then
gosu postgres initdb
fi
exec gosu postgres "$@"
fi
exec "$@"
配置应用为容器中PID为1进程
此脚本使用的exec bash命令,以使最终运行的应用程序成为容器的PID 1,这允许应用程序接收发送到容器的任何Unix信号
帮助程序脚本被复制到容器中并通过ENTRYPOINT容器启动运行:
COPY ./docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]
CMD ["postgres"]
该脚本允许用户以多种方式与Postgres交互。
它可以简单地启动Postgres:
$ docker run postgres
或者,它可用于运行Postgres并将参数传递给服务器:
$ docker run postgres postgres --help
最后,它还可以用来启动一个完全不同的工具,比如Bash:
$ docker run --rm -it postgres bash
Exec形式的ENTRYPOINT示例
可以使用exec形式ENTRYPOINT设置默认命令和参数,然后使用任一形式CMD设置可更改的其他默认值。
FROM ubuntu
ENTRYPOINT ["top", "-b"]
CMD ["-c"]
构建镜像,启容器
检查结果:
$ docker exec -it test ps aux

可以使用docker stop优雅地请求top进程关闭
可再次使用docker start启动
以下Dockerfile显示使用ENTRYPOINT在前台运行Apache(即作为容器的PID 1进程):
FROM debian:stable
RUN apt-get update && apt-get install -y --force-yes apache2
EXPOSE 80 443
VOLUME ["/var/www", "/var/log/apache2", "/etc/apache2"]
ENTRYPOINT ["/usr/sbin/apache2ctl", "-D", "FOREGROUND"]
注意:
1、exec形式被解析为JSON数组,这意味着必须使用双引号(")来引用而不是单引号(')。
2、与shell形式不同,exec形式不会调用命令shell,因此不能扩展变量。例如,ENTRYPOINT [ "echo", "$HOME" ]不会对变量进行替换$HOME。
3、如果想要shell处理,那么要么使用shell形式,要么直接执行shell,例如:ENTRYPOINT [ "sh", "-c", "echo $HOME" ]
Shell形式的ENTRYPOINT示例
可以为ENTRYPOINT指定一个纯字符串指令,将在/bin/sh -c中执行。该形式支持环境变量扩展,并将忽略任何CMD或docker run命令行参数。为了确保docker stop能够正确地发出任何信号给长时间运行的ENTRYPOINT可执行文件,需要记住使用exec指令执行相关指令:
FROM ubuntu
ENTRYPOINT exec top -b
运行此镜像时,将看到单个PID 1进程:
$ docker run -it --rm --name test top

执行docker stop关闭及docker start启动容器
如果shell形式中未使用exec执行ENTRYPOINT中的指令:
FROM ubuntu
ENTRYPOINT top -b
CMD -d 5
启容器:
$ docker run -it --name test

从输出中top看到指定ENTRYPOINT的不是PID 1
如果运行docker stop test,容器将不会干净地退出(最终容器也会推出,但是通过将信号发送给sh,而不是发送给应用程序指令top)
CMD和ENTRYPOINT如何相互作用:
- Dockerfile应至少指定一个CMD或ENTRYPOINT命令
- ENTRYPOINT应该在将容器用作可执行文件时使用
- CMD应该用作定义ENTRYPOINT命令的默认参数
- CMD在使用替代参数运行容器时将被覆盖
下表显示了针对不同ENTRYPOINT/CMD组合执行的命令:
|
没有ENTRYPOINT |
ENTRYPOINT exec_entry p1_entry |
ENTRYPOINT [“exec_entry”,“p1_entry”] |
|
|
没有CMD |
错误,不允许 |
/bin/sh -c exec_entry p1_entry |
exec_entry p1_entry |
|
CMD [“exec_cmd”,“p1_cmd”] |
exec_cmd p1_cmd |
/bin/sh -c exec_entry p1_entry |
exec_entry p1_entry exec_cmd p1_cmd |
|
CMD [“p1_cmd”,“p2_cmd”] |
p1_cmd p2_cmd |
/bin/sh -c exec_entry p1_entry |
exec_entry p1_entry p1_cmd p2_cmd |
|
CMD exec_cmd p1_cmd |
/bin/sh -c exec_cmd p1_cmd |
/bin/sh -c exec_entry p1_entry |
exec_entry p1_entry /bin/sh -c exec_cmd p1_cmd |
12、VOLUME
格式:
VOLUME ["/data"]
VOLUME ["/var/log/","/data "]
VOLUME /var/log
VOLUME /var/log /var/db
VOLUME指令创建具有指定名称的挂载点,并将其标记为从本机或其他容器保存外部挂载的卷。该值可以是JSON数组,VOLUME ["/var/log/"]或具有多个参数的普通字符串,如VOLUME /var/log或VOLUME /var/log /var/db
示例:
FROM centos
RUN mkdir /myvol
RUN echo "hello world" > /myvol/greeting
VOLUME ["/myvo","/data"]
CMD ["/bin/bash"]
docker volume ls
docker volume inspect
ll /var/lib/docker/volumes/
注意:
宿主机目录在容器运行时声明:宿主机目录(mountpoint)本质上是依赖于主机的。这是为了保持镜像的可移植性,因为不能保证给定的主机目录在所有主机上都可用。因此,无法从Dockerfile中安装主机目录。VOLUME指令不支持指定host-dir参数,必须在创建或运行容器时指定挂载点
13、USER
USER <user>[:<group>] 或
USER <UID>[:<GID>]
当构建镜像时,在Dockerfile文件中有RUN、CMD、ENTRYPOINT指令时,USER指令用于设置执行这些指令的用户(UID),及可选的用户组(GID),用户或组必须事先存在
警告:当用户没有主组时,镜像(或下一个指令)将使用root组运行
14、WORKDIR
WORKDIR /path/to/workdir
WORKDIR指令用于在Dockerfile中设置RUN,CMD,ENTRYPOINT,COPY和ADD指令的工作目录。如果WORKDIR指定的目录事先不存在,则会自动被创建。
在Dockerfile中可多次使用WORKDIR指令。如果提供了相对路径,则它将相对于前一条WORKDIR指令的路径。
例如:
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd
最终pwd命令的输出将是/a/b/c
WORKDIR指令可以解析先前使用ENV设定的环境变量。只能使用Dockerfile文件中显式设置的环境变量。
例如:
ENV DIRPATH /path
WORKDIR $DIRPATH/$DIRNAME
RUN pwd
最终pwd命令的输出Dockerfile将是/path/$DIRNAME
15、ONBUILD
ONBUILD [INSTRUCTION]
当镜像用作另一个构建的基础时,该ONBUILD指令向镜像添加将在稍后执行的触发指令。触发器将在下游构建的上下文中执行,就好像它在下游Dockerfile中FROM指令之后立即插入一样。
任何构建指令都可以注册为触发器
16、HEALTHCHECK #只能有一条,如果列出多个,则只有最后一个生效
该HEALTHCHECK指令有两种形式:
- HEALTHCHECK [OPTIONS] CMD command(通过在容器内运行命令来检查容器运行状况)
- HEALTHCHECK NONE(禁用从基础映像继承的任何运行状况检查)
当容器指定了运行状况检查时,除了正常状态外,它还具有运行状况:
这个状态最初是starting
每当健康检查通过时,它就会变成healthy
经过一定数量的连续失败后,它就变成了unhealthy
OPTIONS:
- --interval=DURATION(默认值:30s) 检查时间间隔
- --timeout=DURATION(默认值:30s) 单次检查超时秒数,若超时视为检查失败
- --retries=N(默认值:3) 连续重试N次后,健康检查均失败,认为容器为unhealthy
- --start-period=DURATION(默认值:0s) 为需要时间引导的容器提供初始化时间,在此期间探测失败将不计入最大重试次数。但如果在启动期间运行状况检查成功,则会将容器视为已启动,并且所有连续失败将计入最大重试次数
CMD关键字后面的命令可以是shell命令(如HEALTHCHECK CMD /bin/check-running)或exec形式
命令的退出状态指示容器的运行状况。可能的值是:
- 0:成功 - 容器健康且随时可用
- 1:不健康 - 容器无法正常工作
- 2:保留 - 不要使用此退出代码
示例:
要检查每五分钟左右网络服务器能够在三秒钟内为网站的主页面提供服务:
HEALTHCHECK --interval=5m --timeout=3s CMD curl -f http://localhost/ || exit 1
17、SHELL
SHELL ["executable", "parameters"]
该指令允许覆盖用于shell形式的命令的默认shell。
Linux上默认shell是["/bin/sh", "-c"]
Windows上默认shell是["cmd", "/S", "/C"]。该SHELL指令必须以JSON格式写入Dockerfile
Windows上经常使用
18、STOPSIGNAL
STOPSIGNAL signal
STOPSIGNAL指令设置将发送到容器的系统调用信号以退出。此信号可以是与内核的系统调用表中的位置匹配的有效无符号数,例如9,或SIGNAME格式的信号名,例如SIGKILL
默认的stop signal是SIGTERM,在docker stop的时候会给容器内PID为1的进程发送这个signal,通过--stop-signal可以设置自己需要的signal,主要的目的是为了让容器内的应用程序在接收到signal之后可以先做一些事情,实现容器的平滑退出,如果不做任何处理,容器将在一段时间之后强制退出,会造成业务的强制中断,这个时间默认是10s
Dockerfile说明
Docker镜像由只读层组成,每个层都代表一个Dockerfile指令。这些层是堆叠的,每一层都是前一层变化的增量。
Dockerfile:
FROM ubuntu:15.04
COPY . /app
RUN make /app
CMD python /app/app.py
每条指令创建一个层:
- FROM从ubuntu:15.04Docker镜像创建一个层。
- COPY从Docker客户端的当前目录添加文件。
- RUN用你的应用程序构建make。
- CMD指定在容器中运行的命令。
运行镜像并生成容器时,可以在基础层的顶部添加新的可写层writable layer(“容器层”)。对正在运行的容器所做的所有更改(例如写入新文件,修改现有文件和删除文件)都将写入此可写容器层。
上下文的概念
执行docker build命令时,宿主机上的当前工作目录称为构建上下文。默认情况下,假定Dockerfile位于本地当前目录,但可以使用选项(-f)指定其他位置。无论Dockerfile实际存在的位置如何,当前目录中的所有文件和目录的递归内容都将作为构建上下文发送到Docker守护程序(构建由Dockerd守护程序运行,而不是由CLI运行)
Usage: docker build [OPTIONS] PATH | URL | -
从构建上下文(.)中构建映像:
mkdir project && cd project
echo "hello" > hello
echo -e "FROM busybox\nCOPY /hello /\nRUN cat /hello" > Dockerfile
docker build -t helloapp:v1 .
移动Dockerfile和hello文件到单独的目录
构建映像的第二个版本(不依赖于上一个版本的缓存)
使用-f指向Dockerfile并指定构建上下文的目录:
mkdir -p dockerfiles context
mv Dockerfile dockerfiles && mv hello context
docker build --no-cache -t helloapp:v2 -f dockerfiles/Dockerfile context
Docker 17.05增加了Dockerfile通过stdin使用本地或远程构建上下文进行管道来构建映像的功能。
在早期版本中,使用来自stdin的Dockerfile构建映像,不支持发送构建上下文
Docker 17.04及更低版本
docker build -t foo - <<EOF
FROM busybox
RUN echo "hello world"
EOF
Docker 17.05及更高版本(本地构建上下文)
docker build -t foo . -f - <<EOF
FROM busybox
RUN echo "hello world"
COPY . /my-copied-files
EOF
Docker 17.05及更高版本(远程构建上下文)
docker build -t foo https://github.com/thajeztah/pgadmin4-docker.git -f - <<EOF
FROM busybox
COPY LICENSE config_local.py /usr/local/lib/python2.7/site-packages/pgadmin4/
EOF
排除上下文中与构建无关的文件,使用上下文中的.dockerignore文件(每个要排除的文件或目录独占一行)
示例.dockerignore文件(支持通配):
# comment
*/temp*
*/*/temp*
temp?
**匹配任意数量目录(包括零)的特殊通配符字符串
例如,**/*.go将排除.go在所有目录中找到的以该结尾的所有文件,包括构建上下文的根
以!(感叹号)开头的行可用于对排除项进行例外处理
以下是.dockerignore使用此机制的示例文件:
*.md
!README.md
除README.md上下文外,所有以md为扩展名的文件除外(也就是README.md文件不会被排除)
示例:
*.md
README-secret.md
!README*.md
包含所有README文件。中间一行没有效果,因为!README*.md匹配README-secret.md并且最后。
甚至可以使用该.dockerignore文件来排除Dockerfile和.dockerignore文件
注意:这些文件仍然发送到守护程序,因为它需要它们来完成它的工作。但是ADD和COPY指令不会将它们复制到镜像中
使用多阶段构建:
多阶段构建(在Docker 17.05或更高版本中)可大幅减小最终镜像的大小,而不必费力地减少中间层和文件的数量。
由于镜像是在构建过程的最后阶段构建的,因此可以通过利用构建缓存来最小化镜像层。
#第一阶段
Dockerfile:
FROM golang:1.7.3
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
#第二阶段
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=0 /go/src/github.com/alexellis/href-counter/app .
CMD ["./app"]
只需要单个Dockerfile,也不需要单独的构建脚本。只要运行docker build
$ docker build -t alexellis2/href-counter:latest .
默认情况下,阶段未命名,可以通过整数来引用它们,第一条FROM指令从0开始。但是,可以通过as <NAME>在FROM指令中添加一个来命名您的阶段。
此示例通过命名阶段并使用COPY指令中的名称来改进前一个示例。这意味着即使Dockerfile中的指令稍后重新排序,COPY也不会中断。
FROM golang:1.7.3 as builder
WORKDIR /go/src/github.com/alexellis/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
CMD ["./app"]
停在特定的构建阶段
构建镜像时,不一定需要构建整个Dockerfile,包括每个阶段。可以指定目标构建阶段。
以下命令假定您使用的是前一个Dockerfile但在名为builder的阶段停止:
$ docker build --target builder -t alexellis2/href-counter:latest .
一些可能的场景:
- 调试特定的构建阶段
- 使用debug阶段,该阶段启用了所有调试符号或工具,以及lean production阶段
- 使用testing阶段,该阶段应用程序填充测试数据,但使用实际数据的不同阶段构建生产环境
使用外部镜像作为“stage”
使用多阶段构建时,不仅可以从先前在Dockerfile中的构建阶段进行复制。还可以使用该COPY --from指令从单独的镜像进行复制,使用本地镜像名称,本地或Docker仓库中可用的标记或标记ID。
如有必要,Docker客户端会提取镜像,并从镜像中复制工件。语法是:
COPY --from=nginx:latest /etc/nginx/nginx.conf /nginx.conf
管理镜像
使自己的镜像可供组织内部或外部的其他人使用的最简单方法是使用Docker registry,例如Docker Hub,Docker Trusted Registry,或运行自己的私有注册服务器。
Docker Hub
注册及使用(演示使用过程)
Docker注册服务器
Docker Registry是Docker生态系统的一个组件。registry是一个存储和内容传送系统,包含命名的Docker映像,可以使用不同的标记版本
docker images
docker run -p 4000:80 friendlyhello #启容器
docker tag image username/repository:tag
docker push #发布镜像
docker kill #强制关闭指定的容器
docker rm
docker rm $(docker ps -a -q)
docker images -a
docker rmi <imagename>
容器中数据的简单管理(基础)
docker中数据有两种:
1、数据卷
-v /data #卷,等同于Dockerfile中的VOLUME指令(生产环境使用)
-v src:dst:ro|rw #绑定挂载,docker不能直接管理(开发及测试环境使用)
说明:
src 为宿主机上的目录
dst 为容器中的目录,将会被挂载到宿主机
src和dst均不需要事先创建
src和dst也可是文件
2、数据卷容器
--volumes-from
示例:
docker run -itd --name nginx-volume-test -v /data nginx
docker run -itd --name nginx-volume-test2 -v /data_nginx:/data2 nginx
docker inspect -f {{.Mounts}} <Container ID >
docker run -itd -v /root/.bash_history:/root/.bash_history nginx /bin/bash
docker run -itd --name datasource -v /root/.datasource:/data nginx
docker run -itd --volumes-from datasource centos
配置网络
Docker的网络子系统是可插拔的,使用驱动程序。默认情况下存在多个驱动程序,并提供核心网络功能:
- bridge:docker默认的网络驱动。如果未指定驱动程序,则这是需要创建的网络类型。当应用程序在需要通信的独立容器中运行时,通常会使用桥接网络。
- host:对于独立的容器,删除容器和Docker主机之间的网络隔离,并直接使用主机的网络(若启用特权容器,将可以直接修改宿主机网络设置)。host仅适用于Docker 17.06及更高版本上的swarm群集服务。
- overlay:Overlay networks将多个Docker守护程序连接在一起,并使swarm群集服务能够相互通信。还可以使用Overlay networks来促进swarm群集服务和独立容器之间的通信,或者在不同Docker守护程序上的两个独立容器之间进行通信。此策略无需在这些容器之间执行OS级别的路由。
- macvlan:Macvlan网络允许为容器分配MAC地址,使其显示为网络上的物理设备。Docker守护程序通过其MAC地址将流量路由到容器。macvlan在处理期望直接连接到物理网络的传统应用程序时,使用该驱动程序有时是最佳选择,而不是通过Docker主机的网络堆栈进行路由。
- none:对于此容器,禁用所有网络。通常与自定义网络驱动程序一起使用,none不适用于swarm集群服务。
1、在同一个Docker宿主机上多个容器进行通信时,用户定义的桥接网络(即自定义bridge)是最佳选择
2、不同Docker宿主机上运行的容器进行通信时,或者当多个应用程序使用swarm服务协同工作时,overlay网络是最佳选择
3、从VM设置迁移或需要容器看起来像网络上的物理主机(每个都具有唯一的MAC地址)时,Macvlan网络是最佳选择
bridge网络
桥接网络适用于在同一个Docker守护程序宿主机上运行的容器之间通信。
对于在不同Docker守护程序宿主机上运行的容器之间的通信,可以在操作系统级别管理路由,也可以使用overlay网络
启动Docker时,会自动创建默认桥接网络(也称为bridge),并且除非另行指定,否则新启动的容器将连接到该桥接网络。还可以创建用户自定义网桥,用户定义的网桥优于默认bridge网桥
用户定义的网桥与默认网桥之间的差异:
- 用户定义的桥接器可在容器化应用程序之间提供更好的隔离和互操作性。
连接到同一个用户自定义的网桥的容器会自动将所有端口相互暴露,而不会向外界显示任何端口
- 用户定义的桥接器在容器之间提供自动DNS解析。
默认网桥上的容器只能通过IP地址相互访问,除非使用--link选项。在用户定义的桥接网络上,容器可以通过主机名相互解析。
- 容器可以在运行中与用户自定义的网络连接和分离。
在容器的生命周期中,可以动态地将其与用户自定义的网络连接或断开。而从默认桥接网络中删除容器,则需要停止容器并使用不同的网络选项重新创建容器
- 每个用户定义的网络都会创建一个可配置的网桥。
如果容器使用默认桥接网络,则可以对其进行配置,但所有容器都使用相同的设置,如MTU和iptables规则。此外,配置默认桥接网络发生在Docker服务之外,并且需要重新启动Docker。
- 默认桥接网络上的相互链接容器(即使用--link选项互联)共享环境变量。
最初,在两个容器之间共享环境变量的唯一方法是使用--link选项链接,用户定义的网络无法实现这种类型的变量共享。但有更好的方法来共享环境变量。
一些想法:
使用docker network create创建和配置用户定义的网桥。如果不同的应用程序组具有不同的网络要求,则可以在创建时单独配置每个用户定义的网桥。
1、管理用户自定义网络
docker network create \
--subnet 172.20.0.1/16 \
--ip-range 172.20.0.1/24 \
--gateway 172.20.0.1 \
my-net
可以指定子网,IP地址范围,网关和其他选项
docker network rm my-net #删除用户定义的桥接网络
当创建或删除用户定义的网桥或从用户定义的网桥连接或断开容器时,Docker使用特定于操作系统的工具来管理底层网络基础结构(例如iptables在Linux上添加或删除网桥设备或配置规则)
2、将容器连接到用户定义的桥
创建新容器时,可以指定一个或多个--network标志
此示例将Nginx容器连接到my-net网络。它还将容器中的端口80发布到Docker宿主机上的端口8080,因此外部客户端可以访问该端口8080。连接到my-net网络的任何其他容器都可以访问my-nginx容器上的所有端口,反之亦然。
$ docker create --name my-nginx \
--network my-net \
--publish 8080:80 \
nginx:latest
若要将正在运行的容器连接到现有的用户定义的桥,使用docker network connect命令。
以下命令将已在运行的my-nginx容器连接到已存在的my-net网络:
$ docker network connect my-net my-nginx
要断开正在运行的容器与用户定义的桥接器的连接,使用docker network disconnect命令。
以下命令将my-nginx容器与my-net网络断开连接。
$ docker network disconnect my-net my-nginx
示例:
docker network inspect bridge
docker run -itd --name alpine1 alpine
docker run -itd --name alpine2 alpine
docker network inspect bridge
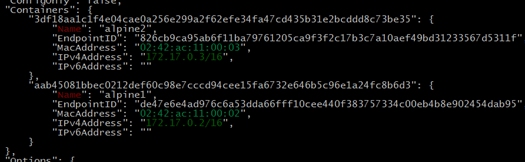
进入两个容器中分别使用ip地址、容器名、主机名互ping
docker container stop alpine1 alpine2
docker container rm alpine1 alpine2
docker run -dit --name alpine1 --network my-net alpine
docker run -dit --name alpine2 --network my-net alpine
docker run -dit --name alpine3 alpine
docker run -dit --name alpine4 --network my-net alpine
docker network connect bridge alpine4
docker network disconnect my-net alpine4
docker container stop alpine1 alpine2 alpine3 alpine4
docker container rm alpine1 alpine2 alpine3 alpine4
docker network rm my-net
启用从Docker容器转发到外部网络
默认情况下,来自连接到默认网桥的容器的流量不会转发到外部。要启用转发,需要更改两个设置。这些不是Docker命令,它们会影响Docker主机的内核。
- 配置Linux内核以允许IP转发。
$ sysctl net.ipv4.conf.all.forwarding=1
- 将策略的iptables FORWARD策略更改DROP为ACCEPT。
$ sudo iptables -P FORWARD ACCEPT
默认bridge网络不建议用于生产用途
配置dockerd的默认网桥
要配置默认bridge网络,请在daemon.json中指定选项。这是一个daemon.json指定了几个选项的示例。仅指定需要自定义的设置。
{
"bip": "192.168.1.5/24",
"fixed-cidr": "192.168.1.5/25",
"fixed-cidr-v6": "2001:db8::/64",
"mtu": 1500,
"default-gateway": "10.20.1.1",
"default-gateway-v6": "2001:db8:abcd::89",
"dns": ["10.20.1.2","10.20.1.3"]
"ipv6":"true"
}
重新启动Docker以使更改生效。
容器的资源限制
在启动容器时可通过docker run的相关选项,进行资源限制
1、CPU相关限制选项
--cpu-period int 限制 CPU CFS(完全公平调度器)的周期,范围从 1ms~1s,即[1000, 1000000],单位微秒
--cpu-quota int 限制 CPU CFS(完全公平调度器)配额,必须不小于1ms,即 >= 1000,单位微秒
--cpu-rt-period int Limit CPU real-time period in microseconds
--cpu-rt-runtime int Limit CPU real-time runtime in microseconds
-c, --cpu-shares int 用于设置多个容器竞争 CPU 时,各个容器相对分配到的CPU时间比例
--cpus decimal CPU个数
--cpuset-cpus string 用于设置容器可以使用的vCPU核(即亲核绑定),即允许使用的CPU集,值可以为0-3,0,1
--cpuset-mems string 允许在指定的内存节点(MEMs)上运行容器中的进程,只对NUMA系统有效(0-3, 0,1),很少使用
Docker的资源限制和隔离完全基于 Linux cgroups
对CPU资源的限制方式也和cgroups相同。
Docker提供的CPU 源限制选项可以在多核系统上限制容器能利用哪些vCPU。
而对容器最多能使用的CPU时间有两种限制方式:
一是有多个CPU密集型的容器竞争CPU时,设置各个容器能使用的CPU时间相对比例。
二是以绝对的方式设置容器在每个调度周期内最多能使用的CPU时间
CPU集
可以设置容器可以在哪些CPU核上运行。
示例:
$ docker run -it --cpuset-cpus="1,3" ubuntu:14.04 /bin/bash
表示容器中的进程可以在 cpu 1 和 cpu 3 上执行
$ docker run -it --cpuset-cpus="0-2" ubuntu:14.04 /bin/bash
表示容器中的进程可以在 cpu 0、cpu 1 及 cpu 2 上执行
在NUMA系统上,可以设置容器可以使用的内存节点
内存节点概念参考:
https://blog.csdn.net/gatieme/article/details/52384075
https://www.cnblogs.com/youngerchina/p/5624516.html
示例:
$ docker run -it --cpuset-mems="1,3" ubuntu:14.04 /bin/bash
表示容器中的进程只能使用内存节点1和3上的内存。
$ docker run -it --cpuset-mems="0-2" ubuntu:14.04 /bin/bash
表示容器中的进程只能使用内存节点 0、1、2 上的内存。
CPU资源的相对限制
默认情况下,所有的容器得到同等比例的CPU周期。
在有多个容器竞争CPU时,可以设置每个容器能使用的CPU时间比例。这个比例称为共享权值,通过-c或--cpu-shares设置。
Docker默认每个容器的权值为1024,不设置或将其设置为0,都将使用这个默认值。
系统会根据每个容器的共享权值和所有容器共享权值和比例来给容器分配CPU时间。
假设有三个正在运行的容器,这三个容器中的任务都是CPU密集型的。
第一个容器的cpu共享权值是1024,其它两个容器的cpu共享权值是512。
第一个容器将得到50%的CPU时间,而其它两个容器就只能各得到25%的CPU时间了。
如果再添加第四个cpu共享值为1024的容器,每个容器得到的CPU时间将重新计算。
第一个容器的CPU时间变为33%,其它容器分得的 CPU 时间分别为 16.5%、16.5%、33%。
必须注意的是,这个比例只有在CPU密集型的任务执行时才有用!!!!!!!
在四核的系统上,假设有四个单进程的容器,它们都能各自使用一个核的100% CPU时间,不管它们的cpu共享权值是多少。
在多核系统上,CPU时间权值是在所有CPU核上计算的。即使某个容器的CPU时间限制少于 100%,它也能使用各个CPU核的100%时间。
假设有一个不止三核的系统。用-c=512的选项启动容器{C0},并且该容器只有一个进程,用-c=1024的启动选项为启动容器C2,并且该容器有两个进程。
CPU 权值的分布可能是这样的:
PID container CPU CPU share
100 {C0} 0 100% of CPU0
101 {C1} 1 100% of CPU1
102 {C1} 2 100% of CPU2
CPU 资源的绝对限制
Linux 通过CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对CPU的使用。CFS默认的调度周期是100ms。
可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少CPU时间。
使用--cpu-period即可设置调度周期,使用--cpu-quota即可设置在每个周期内容器能使用的CPU时间,两者一般配合使用。
例如:
$ docker run -it --cpu-period=50000 --cpu-quota=25000 ubuntu:16.04 /bin/bash
将 CFS 调度的周期设为 50000,将容器在每个周期内的CPU配额设置为25000,表示该容器每50ms可以得到50%的CPU运行时间。
$ docker run -it --cpu-period=10000 --cpu-quota=20000 ubuntu:16.04 /bin/bash
将容器的 CPU 配额设置为 CFS 周期的两倍,CPU 使用时间怎么会比周期大呢?
其实很好解释,给容器分配两个 vCPU 就可以了。该配置表示容器可以在每个周期内使用两个 vCPU 的 100% 时间。
CFS 周期的有效范围是 1ms~1s,对应的--cpu-period的数值范围是 1000~1000000。
而容器的CPU配额必须不小于1ms,即--cpu-quota的值必须 >= 1000,这两个选项的单位都是us。
正确的理解“绝对”
注意前面我们用--cpu-quota设置容器在一个调度周期内能使用的CPU时间时实际上设置的是一个上限,并不是说容器一定会使用这么长的CPU时间。
比如:先启动一个容器,将其绑定到cpu 1上执行。给其--cpu-quota和--cpu-period都设置为 50000。
$ docker run --rm --name test01 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc
调度周期为50000,容器在每个周期内最多能使用50000 cpu 时间。
再用docker stats test01可以观察到该容器对CPU的使用率在100%左右。
然后,再以同样的参数启动另一个容器:
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc
再用docker stats test01 test02可以观察到这两个容器,每个容器对 cpu 的使用率在 50% 左右。说明容器并没有在每个周期内使用 50000 的 cpu 时间。
使用docker stop test02命令结束第二个容器,再加一个参数-c 2048启动它:
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 -c 2048 deadloop:busybox-1.25.1-glibc
再用docker stats test01命令可以观察到:
第一个容器的 CPU 使用率在 33% 左右,
第二个容器的 CPU 使用率在 66% 左右。
因为第二个容器的共享权值是2048,第一个容器的默认共享权值是 1024,所以第二个容器在每个周期内能使用的 CPU 时间是第一个容器的两倍
2、内存相关限制
相关选项:
--kernel-memory bytes 核心内存限制。格式是数值加单位,单位可以为 b,k,m,g,最小为 4M
-m, --memory bytes 内存限制,格式同上,单位可以为 b,k,m,g。最小为 4M
--memory-swap bytes 内存+交换分区大小总限制,格式同上。必须比-m设置的大,'-1'表示表示不限制swap的使用,即可使用宿主机上的最大swap
--memory-reservation bytes 内存的软性限制。格式同上
--memory-swappiness int 设置容器的虚拟内存控制行为。值为0~100之间的整数(默认值-1)
--oom-kill-disable 是否阻止 OOM killer 杀死容器,默认未设置
--oom-score-adj int 容器被 OOM killer 杀死的优先级,范围是[-1000, 1000],默认为 0
用户内存限制
用户内存限制就是对容器能使用的内存和交换分区的大小作出限制。
使用时要遵循两条直观的规则:
-m,--memory选项的参数最小为 4 M
--memory-swap不是交换分区,而是内存加交换分区的总大小,所以--memory-swap必须比-m,--memory大。
在这两条规则下,一般有四种设置方式:
如果在进行内存限制的实验时发现docker run命令报错:
WARNING: Your kernel does not support swap limit capabilities, memory limited without swap.
原因是宿主机内核的相关功能没有打开,按照下面的设置就行:
step1:编辑/etc/default/grub文件,将GRUB_CMDLINE_LINUX一行改为GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"
step 2:更新GRUB,即执行sudo update-grub(Ubuntu系列)指令(红帽系列使用grub2-mkconfig -o /boot/grub2/grub.cfg)
step 3: 重启系统。
方式一:不设置
如果不设置-m,--memory和--memory-swap,容器默认可以用完宿主机机的所有内存和swap 分区。
不过注意,如果容器占用宿主机的所有内存和 swap 分区超过一段时间后,会被宿主机系统杀死(如果没有设置--oom-kill-disable=true的话)。
方式二:设置-m,--memory,不设置--memory-swap
给-m或--memory设置一个不小于 4M 的值,假设为 a,不设置--memory-swap,或将--memory-swap设置为 0。
这种情况下,容器能使用的内存大小为 a,能使用的交换分区大小也为 a。因为 Docker 默认容器交换分区的大小和内存相同
如果在容器中运行一个一直不停申请内存的程序,会观察到该程序最终能占用的内存大小为 2a。
比如:
$ docker run -m 1G ubuntu:16.04
该容器能使用的内存大小为 1G,能使用的 swap 分区大小也为 1G。
容器内的进程能申请到的总内存大小为 2G。
方式三:设置-m,--memory=a,--memory-swap=b,且b > a
给-m设置一个参数 a,给--memory-swap设置一个参数 b。
a是容器能使用的物理内存大小,b是容器能使用的物理内存大小 + swap 分区大小。
所以 b 必须大于 a,b-a 差值即为容器能使用的 swap 分区大小
比如:
$ docker run -m 1G --memory-swap 3G ubuntu:16.04
该容器能使用的内存大小为 1G,能使用的 swap 分区大小为 2G。容器内的进程能申请到的总内存大小为 3G。
方式四:设置-m,--memory=a,--memory-swap=-1
给-m参数设置一个正常值,而给--memory-swap设置成 -1。
这种情况表示限制容器能使用的内存大小为a,而不限制容器能使用的swap分区大小
这时候,容器内进程能申请到的内存大小为 a + 宿主机的swap 大小。
Memory reservation
是一种软性限制,用于节制(节约)容器内存使用。它不保证任何时刻容器使用的内存不会超过--memory-reservation限定的值,它只是确保容器不会长时间占用超过--memory-reservation限制的内存大小
给--memory-reservation设置一个比-m小的值后,虽然容器最多可以使用-m使用的内存大小,但在宿主机内存资源紧张时,在系统的下次内存回收时,系统会回收容器的部分内存页,强迫容器的内存占用回到--memory-reservation设置的值大小。
没有设置时(默认情况下)--memory-reservation的值和-m的限定的值相同。
将它设置为 0 或设置的比-m的参数大等同于没有设置。
示例:
$ docker run -it -m 500M --memory-reservation 200M ubuntu:16.04 /bin/bash
如果容器使用了大于 200M 但小于 500M 内存时,下次系统的内存回收会尝试将容器的内存锁紧到 200M 以下
$ docker run -it --memory-reservation 1G ubuntu:16.04 /bin/bash
容器可以使用尽可能多的内存。--memory-reservation确保容器不会长时间占用太多内存
虚拟内存控制行为
默认情况下,容器的内核可以交换出一定比例的匿名页,--memory-swappiness选项就是用来设置这个比例的,可以设置值为从 0 到 100,默认值-1表示表示不限制。
0 表示关闭匿名页面交换;100表示所有的匿名页都可以交换。
默认情况下,如果不使用--memory-swappiness,则该值从父进程继承而来。
示例:
$ docker run -it --memory-swappiness=0 ubuntu:16.04 /bin/bash
将--memory-swappiness设置为 0 可以保持容器的工作状态,避免交换代理的性能损失。
核心内存和用户内存不同的地方在于核心内存不能被交换出
不能交换出去的特性使得容器可以通过消耗太多内存来堵塞一些系统服务。
核心内存包括:
stack pages(栈页面)
slab pages
socket memory pressure
tcp memory pressure
可以通过设置核心内存限制来约束这些内存。
例如,每个进程都要消耗一些栈页面,通过限制核心内存,可以在核心内存使用过多时阻止新进程被创建
核心内存和用户内存并不是独立的,必须在用户内存限制的上下文中限制核心内存!!!!!!
假设用户内存的限制值为U,核心内存的限制值为K,有三种可能限制核心内存的方式:
1)U != 0,不限制核心内存。这是默认的标准设置方式
2)K < U,核心内存是用户内存的子集。这种设置在部署时,每个 cgroup 的内存总量被过度使用。
过度使用核心内存限制是绝不推荐的,因为系统还是会用完不能回收的内存。
在这种情况下,可以设置 K,这样 groups 的总数就不会超过总内存了。然后,根据系统服务的质量自由地设置 U。
3)K > U,因为核心内存的变化也会导致用户计数器的变化,容器核心内存和用户内存都会触发回收行为。
这种配置可以让管理员以一种统一的视图看待内存,对想跟踪核心内存使用情况的用户也是有用的。
示例:
$ docker run -it -m 500M --kernel-memory 50M ubuntu:16.04 /bin/bash
容器中的进程最多能使用 500M 内存,在这 500M 中,最多只有 50M 核心内存。
$ docker run -it --kernel-memory 50M ubuntu:16.04 /bin/bash
没用设置用户内存限制,所以容器中的进程可以使用尽可能多的内存,但是最多能使用 50M 核心内存。
默认情况下,在出现 out-of-memory(OOM) 错误时,系统会杀死容器内的进程来获取更多空闲内存。这个杀死进程来节省内存的进程,称为OOM killer。
可以通过设置--oom-kill-disable选项来禁止 OOM killer 杀死容器内进程。
必须确保只有在使用了-m/--memory选项时才使用--oom-kill-disable禁用OOM killer。
如果没有设置-m选项,却禁用了 OOM-killer,可能会造成出现 out-of-memory 错误时,系统通过杀死宿主机进程或获取更多内存。
下面的例子限制了容器的内存为 100M 并禁止了 OOM killer:
$ docker run -it -m 100M --oom-kill-disable ubuntu:16.04 /bin/bash #是正确的使用方法。
而下面这个容器没设置内存限制,却禁用了 OOM killer 是非常危险的:
$ docker run -it --oom-kill-disable ubuntu:16.04 /bin/bash
容器没用内存限制,可能会导致系统无内存可用,并尝试时杀死系统进程来获取更多可用内存。
一般一个容器只有一个进程,这个唯一进程被杀死,容器也就被杀死了。
可以通过--oom-score-adj选项来设置在系统内存不够时,容器被杀死的优先级。负值更不可能被杀死,而正值更有可能被杀死。
3、限制磁盘空间
相关选项
--storage-opt list 容器的存储驱动选项
默认每个容器有10GB的空间,有时候它太大了,有时候太小,不能满足所有的数据放在这里,容器一旦被创建就不能改变。
唯一能做的事情就是改变新容器的默认值,
如果一些其他的值(比如5GB)更适合自己的情况,可以通过指定docker run 的 --storage-opt来实现(另外Docker daemon即docker守护程序也有该选项,对所有容器生效),像这样:
$ docker run --storage-opt dm.basesize=5G
此(size)将允许在创建时将容器的rootfs大小设置为5G。此选项仅适用于devicemapper,btrfs,overlay2,windowsfilter和zfs存储驱动。对于devicemapper,btrfs,windowsfilter和zfs存储驱动,用户无法传递小于Default BaseFS Size的大小(即10G)。对于overlay2存储驱动,size选项仅在文件系统为xfs并使用pquota选项挂载时可用,在这种条件下,用户可以传递任何大小。

