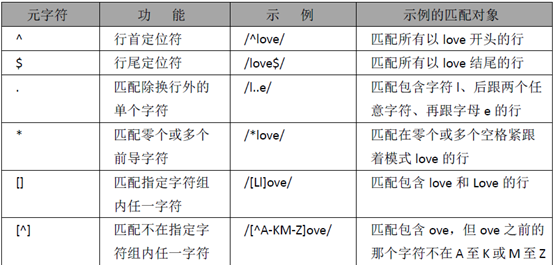
接受正则表达式,按行匹配,将会过滤出匹配的所有行
格式:
grep [OPTION]... PATTERN [FILE]...
可以看出,grep后可以同时接多个文件
选项OPTION:
--color=auto 通常情况下grep过滤后不会有颜色区分,使用该选项添加颜色
-E 支持扩展的正则表达式
-o grep默认输出匹配的行,使用该选项仅输出匹配的关键词
-v 反向匹配
-c 匹配行的数量,而不是匹配次数(一行之内有多个匹配,仅计数1)
-n 输出行号
-i 忽略大小写
-P 支持perl的正则
-w 把表达式作为单词来查找,相当于正则中的"\<...\>"(...表示你自定义的规则)
-x 被匹配到的内容和某行完全相同才能别过滤出来,相当于正则"^...$"
-m NUM 只在前NUM行进行匹配,之后的所有行不再匹配
-q 不输出匹配的字符串,而只是想知道是否能够成功匹配(通过返回值)
-a 搜索二进制文件
-b 通常配合-o选项使用,打印出匹配行的字节偏移量(注意是行的字节偏移量,不是关键词)
-l 在多个文件中搜索匹配文本,找出位于哪个文件,仅会输出文件列表(不在输出匹配行)
-L 和-l相反,列出不匹配的文件列表
-r和-R 在某个目录中搜索匹配的模式,且递归进行
-e 匹配多个模式:$ grep -e "pattern1" -e "pattern2"
-f pattern_file 在文件中指定多个样式,每个样式一行,也可匹配多个模式
-Z 输出每个匹配行或文件列表(-l或-L的输出)时,使用null(\0)作为文件分隔,而不是默认的\n
--include *.{c,cpp} 仅搜索以.c或.cpp结尾的文件
--exclude "readme.txt" 在除readme.txt之外的文件中进行搜索
--exclude-dir DIR 排除某个目录,不进行搜索
--exclude-from FILE 从文件中读取要排除的文件列表
-A n 输出匹配行之后的n行
-B n 输出匹配行之前的n行
-C n 输出匹配行之前及之后各n行
示例:
[root@slave1 ~]# alias
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto' #


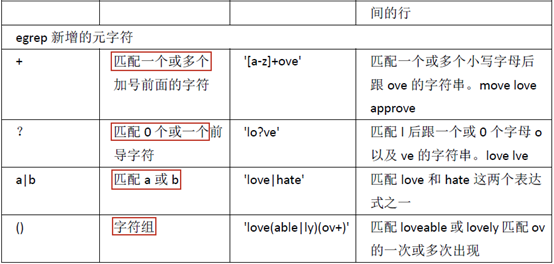
egrep扩展
egrep在grep的基础上增加了更多的元字符。但是egrep不允许使用\(\),\{\},因为egrep本身就支持扩展的正则表达式
egrep使用的正则表达式元字符