Redis主从同步及安装
Redis主从复制
从Redis 2.8开始,引入了PSYNC命令代替SYNC命令来执行复制时的同步操作。PSYNC命令具有全量同步(full resynchronization)和增量同步(partial resynchronization)。
主从同步策略
从库刚开始连接主库时,实行全量同步。全量同步结束后,进行增量同步,主库每执行一个写命令、删除命令就会向从服务器发送相同的命令,从服务器接收并执行收到的命令;
主服务器需要生成RBD文件,这个生成的操作会消耗主服务器的CPU、内存和磁盘I/O资源;而将自己生成的RDB文件发送给从服务器,这个发送操作会消耗掉主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响;
从服务器在接收到RDB文件的从服务器需要载入主服务器发来的RDB文件,并且在载入内存的这个时间段,从服务器会因为阻塞而没办法处理命令请求;
主从同步特点
主从复制对于主redis服务器来说是非阻塞的,说明当从服务器进行主从同步的过程中,主redis仍然可以处理外界访问请求;
而从redis服务器也是非阻塞的,说明当服务器进行主从复制过程中也可以接受外界的查询请求,但是此时查询的数据时以前老的数据,我们可以在配置文件中进行设置,那么从redis在复制同步过程中来自外界的查询请求都会返回错误给客户端;
虽然主从复制过程中对于从redis是非阻塞的,但是当slave库从主redis库同步过来最新的数据后还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻;
主从同步的缓冲区
主从集群间的数据复制包括全量复制和增量复制两种。全量复制是同步所有数据,而增量复制只会把主从库网络断连期间主库收到的命令,同步给从库。无论在哪种形式的复制中,为了保证主从节点的数据一致,都会用到缓冲区。
全量同步
1、slave初始化时向主库发送psync同步命令,这时需要主库将所有数据都复制一份
2、master收到slave的同步命令后,master执行bgsave命令,在后台开启一个线程把收集所有修改数据的命令,把要同步的数据整理为一个RBD文件,然后传送给slave
3、slave 接受到RBD文件后,先把RBD文件保存在磁盘上,然后加载到内存中,后续若在产生新数据,master会继续将数据传给slave,从而完成同步。

1. 设置主节点的地址和端口
简而言之,是执行SLAVEOF命令,该命令是个异步命令,在设置完masterhost和masterport属性之后,从节点将向发送SLAVEOF的客户端返回OK。表示复制指令已经被接受,而实际的复制工作将在OK返回之后才真正开始执行。
2. 创建套接字连接。
在执行完SLAVEOF命令后,从节点根据命令所设置的IP和端口,创建连向主节点的套接字连接。如果创建成功,则从节点将为这个套接字关联一个专门用于处理复制工作的文件事件处理器,这个处理器将负责执行后续的复制工作,比如接受RDB文件,以及接受主节点传播来的写命令等。
3. 发送PING命令。
从节点成为主节点的客户端之后,首先会向主节点发送一个PING命令,其作用如下:
1. 检查套接字的读写状态是否正常。
2. 检查主节点是否能正常处理命令请求。
如果从节点读取到“PONG”的回复,则表示主从节点之间的网路连接状态正常,并且主节点可以正常处理从节点发送的命令请求。
4. 身份验证
从节点在收到主节点返回的“PONG”回复之后,接下来会做的就是身份验证。如果从节点设置了masterauth选项,则进行身份验证。反之则不进行。
在需要进行身份验证的情况下,从节点将向主节点发送一条AUTH命令,命令的参数即可从节点masterauth选项的值。
5. 发送端口信息。
在身份验证之后,从节点将执行REPLCONF listening-port <port-number>,向主节点发送从节点的监听端口号。
主节点会将其记录在对应的客户端状态的slave_listening_port属性中,这点可通过info Replication查看。
6. 同步。
从节点向主节点发送PSYNC命令,执行同步操作,并将自己的数据库更新至主节点数据库当前所处的状态。
7. 命令传播
当完成了同步之后,主从节点就会进入命令传播阶段。这时主节点只要一直将自己执行的写命令发送到从节点,而从节点只要一直接收并执行主节点发来的写命令,就可以保证主从节点保持一致了。
8. 心跳检测
在命令传播阶段,从节点默认会以每秒一次的频率,向主节点发送命令。
REPLCONF ACK <replication_offset>
其中,replication_offset是从节点当前的复制偏移量。
发送REPLCONF ACK主从节点有三个作用:
1> 检测主从节点的网络连接状态。
2> 辅助实现min-slave选项。
3> 检查是否存在命令丢失。
REPLCONF ACK命令和复制积压缓冲区是Redis 2.8版本新增的,在此之前,即使命令在传播过程中丢失,主从节点都不会注意到。
增量同步
当从库开始正常工作时主服务器发生的增删改操作同步到从服务器的过程,增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
增量同步由三个部分构成:
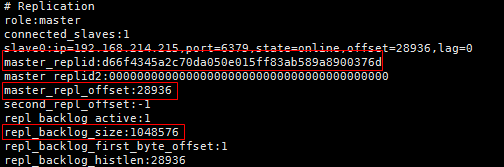
一一主服务器的复制偏移量(master_repl_offset)和从服务器的复制偏移量
一一主服务器的复制积压缓冲区(replication backlog)
一一服务器运行的ID(RUN ID)
1、复制偏移量
主从同步的双方都会维护自己的一个偏移量,主服务器每向从服务器器传递N个字节的数据时,就将自己的复制偏移量的值加上N;
从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N;
如果主从服务器处于一致状态,那么它们的偏移量就会是一致的,相反表明主从服务器并未处于一致状态。如下图所示:
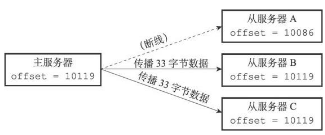
此时需要思考,若是因故障停止的slave库,修复好启动成功连接主库后,slave库会向主库发送同步命令,告知自己的偏移量,那么主库会对从库执行全量同步还是增量同步,若执行增量同步,主库会如何去发送在slave库宕机期间丢失的数据。
2、复制积压缓冲区(repl_backlog_buffer)
复制积压缓冲区是由主服务器维护的一个固定长度(fixed-size)先进先出(FIFO)队列,默认大小为1MB。和普通先进先出队列随着元素的增加和减少而动态调整长度不同,固定长度先进先出队列的长度是固定的,当入队元素的数量大于队列长度时,最先入队的元素会被弹出,而新元素会被放入队列。
当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区里面,主节点上会为每个从节点都维护一个复制缓冲区,来保证主从节点间的数据同步。如图所示:
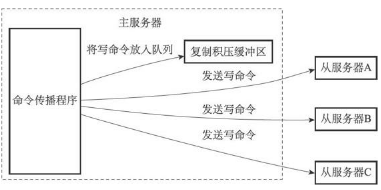

repl_backlog_buffer 是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,这是所有从库共享的。主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,会把自己的复制进度(slave_repl_offset)发给主库,主库就可以和它独立同步。
所以,可以看出主服务器的复制积压缓冲区里面会保存着一部分最近传播的写命令,并且复制积压缓冲区会为队列中的每个字节记录相应的复制偏移量。
当从服务器重新连上主服务器时,从服务器会通过同步命令将自己的复制偏移量offset发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作:
若偏移量之后的数据还存在于复制缓冲区里,那么主服务器将对从服务器执行部分重同步操作;而如果offset偏移量之后的数据已经不存在于复制积压缓冲区,那么主服务器将对从服务器执行完整重同步操作。
根据需要调整复制缓冲区的大小
Redis复制缓冲区默认为1MB,如果主服务器需要执行大量写命令,或者主从服务器断线后重连接所需的时间比较长,则需要调整复制缓冲区(repl-backlog-size)的大小。
复制积压缓冲区的最小大小可以根据公式second*write_size_per_second来估算:
second为从服务器断线后重新连接上主服务器所需的平均时间(以秒计算);
write_size_per_second则是主服务器平均每秒产生的写命令数据量(协议格式的写命令的长度总和)
例子,如果主库每秒写入 2000 个操作,每个操作的大小为 2KB,网络每秒能传输 1000 个操作,那么,有 1000 个操作需要缓冲起来,这就至少需要 2MB 的缓冲空间。否则,新写的命令就会覆盖掉旧操作了。为了应对可能的突发压力,我们最终把 repl_backlog_size 设为 4MB。
3、服务器运行ID
复制偏移量和复制积压缓冲区之外,实现部分重同步还需要用到服务器运行ID(run ID)
每个redis服务器在运行的时候,都会有自己的运行ID
运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成,例:d66f4345a2c70da050e015ff83ab589a8900376d
当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来;
当从服务器宕机并重新连上一个主服务器时,从服务器将向当前连接的主服务器发送之前保存的运行ID
若从服务器保存的运行ID和当前连接的主服务器的运行ID相同,那么说明从服务器断线之前复制的就是当前连接的这个主服务器,主服务器可以继续尝试执行部分重同步操作;
若从服务器保存的运行ID和当前连接的主服务器的运行ID并不相同,那么说明从服务器断线之前复制的主服务器并不是当前连接的这个主服务器,主服务器将对从服务器执行完整重同步操作。
环境准备:部署2台redis数据库
环境:
角色 ip地址 操作系统 Redis版本
主 master 192.168.214.214 redhat6.4 redis-4.0.8
从 slave 192.168.214.215 redhat6.4 redis-4.0.8
一、配置主从复制
1、连接进入要配置的slave库
[root@localhost ~]# redis-cli -h 192.168.214.215 -p 6379
2、查看信息,每个redis启动时都是默认自己为主库
192.168.214.215:6379>auth 123456
192.168.214.215:6379> info replication
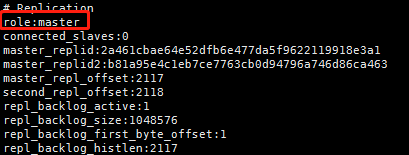
3、指定哪一台服务器为自己的主库
192.168.214.215:6379> slaveof 192.168.214.214 6379 (slaveof ip地址 端口号)
OK
slaveof no one #取消主从配置
4、查看主从配置
###同时在master主库查看信息
[root@localhost ~]# redis-cli -h 192.168.214.214 -p 6379 //连接数据库
192.168.214.214:6379>auth 123456
192.168.214.214:6379> info replication //查看主从信息

5、验证主从同步
1)主库插入数据
192.168.214.214:6379> set name wushaoyu
OK
2)查看插入数据
192.168.214.214:6379> get name
"wushaoyu"
3)从库查看数据
192.168.214.215:6379> keys *
(empty list or set)
ps:这里为什么为空???
1)是因为主库设置了密码验证,从库虽然配置了主从,但是当其去连接主库同步数据的时候无法通过验证,从而无法同步数据
2)命令行配置主从同步只是临时起效,当因某种原因重启从库redis数据库后,主从同步即失效!!而若想保持永久主从同步,则需把主从配置写进从库配置文件,并且把从库连接主库同步数据的密码一并写入配置文件中,这样既可完成永久同步且从库能够在主库开启密码验证的情况下同步数据。
在从库配置文件中新添2行配置:
slaveof 192.168.214.214 6379 //主从配置
masterauth 123456 //主库认证密码
4)此时在从库查看name变量的值
192.168.214.215:6379> keys *
1) "name"
192.168.214.215:6379> get name
"wushaoyu"

