
开发者通常负责设计关系型数据模型,编写程序计算和展现数据,数据库管理员负责数据文件存放位置、表空间存储参数等的架构设计。但是,数据库管理员往往不了解业务,不了解数据的特点,数据存储设计表现为千“表”一律。
数据存储设计模式是根据数据的真正特点,仔细分析数据流向、数据访问特点、数据量、数据增长量和数据生命周期,对数据进行分类,然后根据不同类型的数据设计不同的存储策略。正确的应用数据存储设计模式,可以几倍,甚至几十倍的提高数据访问效率。
2 大数据量下的数据特点
全球最大数据库的数据量已经先后越过了MB量级、GB量级和TB量级,站到了PB量级的门口。在庞大的数据量面前,对数据进行分类显得尤为重要。人们对数据感兴趣的时间是不一样的,大量的数据进入数据库后,经过计算、聚集和转换,仅有少量的活跃数据需要长期保留在数据库中,剩下的数据只有备查的价值,可以暂时存储在数据库中或者离线备份,等到休眠数据完全没有价值后直接删除。
需要长期保留在数据库的活跃数据可以称之为核心数据,它是整个商业活动中最有价值的数据,需要长期甚至永久的保留。程序完成处理后只需要备查的休眠数据可以称之为过程数据,是伴随核心数据流动所产生的数据,它的存在周期视商业活动的重要性而定。
数据的分类有利于把资源聚焦于有价值的数据,我们可以通过以下几个方面识别核心数据和过程数据:
|
识别项 |
核心数据 |
过程数据 |
|
数据流向 |
几乎不流动 |
按工作流的方式运动 |
|
数据的访问特点 |
主要读,多半是关联查询 |
主要写,更新和删除涉及到查询 |
|
数据量 |
大 |
非常大 |
|
数据的增长量 |
增长缓慢或者完全不增长 |
增长迅速,甚至是爆发性的 |
|
数据生命周期 |
长,甚至永久的保留 |
短,几天到几个月不等 |
在大数据量环境下,数据库服务器的资源是昂贵的,混合核心数据和过程数据的后果就是资源被不重要的数据占用,被不必要的进程占用,导致性能缓慢和堵塞。常见的误解数据特点的现象包括:
l 核心数据和过程数据以不同字段的形式在同一条记录里存放
l 核心数据和过程数据以不同记录的形式在同一张表里存放
l 把不同队列的过程数据在同一张表里存放
l 过程数据没有合适的退出机制,长期保留在数据库中
3 数据表的分类
在一个大数据量环境中,表的数量往往达到数千张。根据核心数据和过程数据的不同特点,可以将表大致分为2个大类,4个子类。
核心表及子类的明细定义如下:
|
表类型 |
表说明 |
|
核心表 |
数据生命周期长,读比写的访问频率高,数据增长慢 |
|
恒数表 |
数据量小,总是读,很少写 |
|
递增表 |
数据量大,经常读,很少写。某些情况会频繁写。 |
在核心表的关系型数据模型设计阶段,有以下原则需要遵守:
l 务必要尊重范式,即确保原子性,检查对键的依赖性,检查属性独立性等三个原则。
l 严格控制关键递增表的字段个数和字段长度。
l 重要的递增表的属性一旦定义,不允许随意添加字段。后续业务升级最好是增加新的递增表。
l 如果递增表总是需要做范围查询,应重新审视关系型模型。
过程表及子类的明细定义如下:
|
表类型 |
表说明 |
|
过程表 |
数据生命周期短,写比读的访问频率高,数据增长快 |
|
流水表 |
数据量大,经常写,很少读。只插不改,定期删。 |
|
状态表 |
数据量大,经常写,经常读。边插边改边删。 |
在过程表的关系型数据模型设计阶段,有以下原则需要遵守:
l 设计明显的代表数据生命周期终止的字段
l 从增删改的代价来考虑,插入代价最小,修改需检索数据,删除最为昂贵,可考虑多设计流水表,少设计状态表。
数据库存储设计模式
李强分析了大数据量的特点,解释了存储设计模式,他认为,数据混放后果将十分严重。在分析数据模式时,可以在数据流向,数据访问特点,数据量,数据的增长量,数据的生命周期等几个方面对数据进行多维度划分分析,然后根据模式对数据表进行分类,可以分为恒数表,递增表,流水表,状态表。
在进行数据模型设计时,必须遵循相关要点,如:对核心表, 务必要尊重范式,注意字段个数和字段长度, 注意范围查询;对过程表,设计明显的代表数据生命周期终止的字段,从增删改的代价来考虑,插入代价最小,修改需检索数据,删除最为昂贵。对恒数表,设计符合表大小的数据分配参数,较小的恒数表不建议建立索引;对于递增表,严格区别核心数据和过程数据,分区的大小尽量均衡,索引的键值选择性尽量高,谨慎使用复合索引,按照关联关系设计合适的分区和索引;对流水表,要注意分区的粒度和选择,不建议建立太多索引。
对于状态表的设计,需要考虑更多状态的转换:
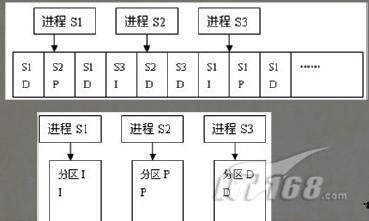
软件架构中的存储设计模式:

数据库设计如何重构
关于重构,我们更多的是听到代码重构,对于设据库设计,同样需要通过重构的手段来演进设计。但数据库领域一向对待变更缺乏很好的应对机制,面临巨大的挑战,对开发者来说,尽管现在是“敏捷”的时代,可是数据似乎无法敏捷;对客户而言,现在是“随需应变”的时代,可是数据却很难变更。
Flower在《代码重构》一书中提到“代码味道”的概念,重构时,我们需要找出有“坏味道”的代码块。对数据库而言,同样也要找出“数据库的味道”,如: 多用途的列,智能的列,多用途的表,行或列太多的表,重复的数据等。
李强认为,在敏捷成为主流的今天,重构是使数据库社区跟上时代的快车道, 重构是低成本提升系统可靠性的法宝。比如,拆分表;关联表就是典型的数据库重构操作。
关于数据访问模式设计,李强谈到,通过改善中间件的数据访问模式设计,可以大规模提高系统整体性能,实现架构的平滑扩展,还可以屏蔽数据库的差异性。最后,他举例说明了并发模式和缓存模式这2种最常见的数据库访问设计模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号