

微软官方简介
SQL 服务器 2012年引入了一种新的名为 ColumnStore 的索引。ColumnStores 是所有有关性能和提高的性价比。中非 ColumnStore 查询处理的每个数据行。与 ColumnStore,可以将 SQL Server 进程行在批处理。不只是数据在多个行的列存储在单个数据页中,但您也可以在批处理中处理它。最重要的是大量压缩数据。这工作是比率大约为 7-1。
ColumnStore 提供了很多更好的吞吐量,因为 CPU 开销减少执行查询时。处理需要较少的 I/O 和 RAM,非常适合于快速跟踪数据仓库体系结构。ColumnStore 索引提供大规模的 10 到 100 倍性能改进对经常基于行的索引。
限制:
SQL Server 的索引有很多种,详见:http://msdn.microsoft.com/zh-cn/library/ms175049.aspx
是不是有了列存储索引,其他类型的索引就都可以光荣下岗了?以后什么情况下我们都可以使用列存储索引吗?
显然不是这样的,列存储索引有着很大的局限性,我们看一下它有哪些限制?
1.列存储索引包含的列数不能超过 1024。
在SQL Server 2012的最大容量规范中提到每个select ,每个insert ,每个update的列数最多是4096。SQL Server 2008用稀疏列突破了单表1024列的限制,列存储索引限制为不能超过1024列(个人认为这个限制并无大碍,毕竟那么多字段的表还是很少见的)。
2.无法聚集。只有非聚集列存储索引才可用。
例如我们把刚才的索引删掉,重新创建聚集索引。
on TestTable(c1,c2,c3,c4,c5)
错误信息是这样的:不支持聚集列存储索引。
3.非聚集索引也只能创建一个。
on TestTable(c1,c2)
错误信息是这样的:不支持多个非聚集列存储索引。
4.不能是唯一索引。
我们再把刚才的索引删掉,重新创建聚集索引。
on TestTable(c1,c2,c3,c4,c5)
错误信息是这样的:由于列存储索引不是唯一的,CREATE INDEX 语句失败。请在不使用 UNIQUE 关键字的情况下创建该列存储索引,或在不使用 COLUMNSTORE 关键字的情况下创建一个唯一索引。
5.不能基于视图或索引视图创建。
as
select top 100* from TestTable
go
create nonclustered columnstore index PK__TestTabl__ColumnStore
on v_ColumnStore(c1,c2,c3,c4,c5)
错误信息是这样的:由于无法对视图创建列存储索引,CREATE INDEX 语句失败。请考虑对基表创建列存储索引,或不带 COLUMNSTORE 关键字对视图创建一个索引。
6.不能包含稀疏列。
创建一个2050个字段的表:
set @sql='create table TestColumn (maco xml column_set for all_sparse_columns'
select
@sql=@sql+','+'C'+ltrim(number)+' int sparse '
from master..spt_values where type='p'
exec(@sql+')')
go
alter table TestColumn add newcol int
新建的表中除了newcol,maco列外,其他2048个列都是稀疏列。
on TestColumn(newcol)
错误信息是这样的:由于不能对稀疏列创建列存储索引,CREATE INDEX 语句失败。请考虑对不包含任意稀疏列的列子集创建非聚集列存储索引。
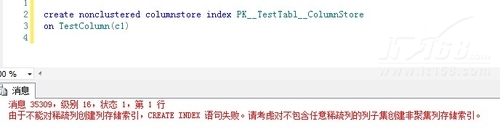
▲图F
7.不能作为主键或外键
原文是Cannot act as a primary key or a foreign key.
我上面的测试数据表中是有主键的,我们在主键上创建一个列存储索引试一试。
on TestTable(id)
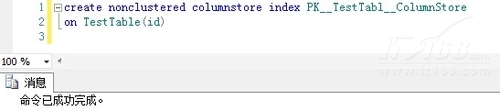
▲图G
结果是成功的。我们再测试一下性能:

▲图H
测试结果表明对主键再添加列存储索引是可以加上的,但是不起作用,应该说是起副作用。
8.不能使用 ALTER INDEX 语句更改。而应在删除后重新创建列存储索引。
错误信息是这样的:由于不能重新组织列存储索引,ALTER INDEX 语句失败。重新组织列存储索引不是必需的。
我们可以使用 ALTER INDEX 禁用和重新生成列存储索引。
alter index PK__TestTabl__ColumnStore on TestTable disable
--重启
alter index PK__TestTabl__ColumnStore on TestTable rebuild
9.不能使用 INCLUDE 关键字创建。
on TestTable(c1) include(c2,c3)
错误信息是这样的:由于列存储索引不能有包含的列,CREATE INDEX 语句失败。
10.不能包括用来对索引排序的 ASC 或 DESC 关键字。
根据压缩算法对列存储索引排序。不允许在索引中进行排序。可能按照搜索算法对从列存储索引中选择的值进行排序,但是您必须使用 ORDER BY 子句来确保对结果集进行排序。
11.不以传统索引的方式使用或保留统计信息。
查询优化的统计信息是一些对象,这些对象包含与值在表或索引视图的一列或多列中的分布有关的统计信息。查询优化器使用这些统计信息来估计查询结果中的基数或行数。通过这些基数估计,查询优化器可以创建高质量的查询计划。例如,查询优化器可以使用基数估计选择索引查找运算符而不是耗费更多资源的索引扫描运算符,从而提高查询性能。列存储索引是基于列的,不关心行数和行中数据的分布情况,所以不以传统索引的方式使用或保留统计信息。
12.不能对计算列加列存储索引。
alter table TestTable add c6 as c1+c5
--给计算列添加列存储索引
create nonclustered columnstore index PK__TestTabl__ColumnStore
错误信息是这样的:由于表“TestTable”的列“c6”为计算列,不能对计算列创建列存储索引,CREATE INDEX 语句失败。请考虑对不包含该列的列子集创建非聚集列存储索引。
13.不能包含具有 FILESTREAM 属性的列。表中未在索引中使用的其他列可以包含 FILESTREAM 属性。
从SQL Server 2008开始,增加了对FileStream的支持。FileStream定义在字段后面,标识该字段用于文件流,该列依然是用二进制保存的。
一般都是在数据库中要特别添加一个文件组和一个或多个文件用来存储FileStream的数据的。
如果表中的字段有filesteam属性则不能在该列上创建列存储索引。
14.有列存储索引后,表变成只读表,不能进行添加,删除,编辑的操作。
错误信息是这样的:由于不能在包含列存储索引的表中更新数据,INSERT 语句失败。
微软提供了三种方式来解决这个问题,这里简单介绍两种:
1) 若要更新具有列存储索引的表,先删除列存储索引,执行任何所需的 INSERT、DELETE、UPDATE 或 MERGE 操作,然后重新生成列存储索引。
2) 对表进行分区并切换分区。对于大容量插入,先将数据插入到一个临时表中,在临时表上生成列存储索引,然后将此临时表切换到空分区。对于其他更新,将主表外的一个分区切换到一个临时表中,禁用或删除临时表上的列存储索引,执行更新操作,在临时表上重新生成或重新创建列存储索引,然后将临时表切换回主表。
alter index PK__TestTabl__ColumnStore on TestTable disable
--插入数据
insert into TestTable(id,c1,c2) select10000002,rand(),rand()
--重启
alter index PK__TestTabl__ColumnStore on TestTable rebuild
这样就可以成功插入一条数据了。
15.类型限制
下数据类型不能包括在列存储索引中:
·binary和varbinary
·ntext、text和 image
·varchar(max)和nvarchar(max)
·uniqueidentifier
·rowversion(和 timestamp)
·sql_variant
·精度大于 18 位的 decimal(和 numeric)
·标量大于 2 的 datetimeoffset
·CLR 类型(hierarchyid和空间类型)
·xml
alter table TestTable add c7 varchar(max)
--给计算列添加列存储索引
create nonclustered columnstore index PK__TestTabl__ColumnStore
on TestTable(c7)
错误信息是这样的:表 'TestTable' 中的列 'c7' 的类型不能用作索引中的键列。
16.列存储索引不支持 SEEK
如果查询应返回行的一小部分,则优化器不大可能选择列存储索引(例如:needle-in-the-haystack 类型查询)。
如果使用表提示 FORCESEEK,则优化器将不考虑列存储索引。
17.列存储索引不能与以下功能结合使用
·页和行压缩以及 vardecimal 存储格式(列存储索引已采用不同格式压缩)。
·复制
·更改跟踪
·变更数据捕获
·文件流
优势分析
列存储索引虽然有一定的限制,但是它的优点还是很突出的。
1.列存储和列分组
与传统的基于行的数据组织方式(称为“行存储”格式)不同,在具有列存储索引的分列数据库系统中,每次对一个列的数据进行分组和存储。SQL Server 查询处理可以利用新的数据布局,并显著改进查询执行时间。
2.对于静态数据的读取速度上有显著的提高。
只读取需要的列。经过高度压缩,减少了读取和移动的字节数。
3.没有键列的概念
列存储索引中没有键列的概念,因此,索引中的键列数限制 (16) 不适应于列存储索引。
4.记录大小不受900字节的限制。
索引键记录大小限制(900 字节)也不适应于列存储索引。
5.性能的大幅度提升
列存储索引可用于显著加快常见数据仓库查询的处理时间。典型的数据仓库工作负荷涉及汇总大量数据。在数据仓库和决策支持系统中通常用于提高性能的技术包括预先计算的汇总表、索引视图、OLAP 多维数据集等。
通过实例简单的描述了一下列存储索引的使用,详细说明了使用中需要注意的一些限制,也了解了列存储索引的优点。在下一个SQL Server版本中,很可能加强列存储索引的优势,减少其使用限制。
例如现在建了该索引的表就是只读表了,但是官方有提到:请勿将列存储索引创建为一种使表成为只读表的机制。在将来的版本中,不能保证限制对具有列存储索引的表进行更新。当需要只读行为时,应通过创建只读文件组并将表移到此文件组中来强制执行。
让我们共同期待功能越来越强悍的SQL Server!本文主要是参考官方文档,结合个人实践而来,如有错误,望指正。
测试实例
一.创建和使用
实践出真知,首先我们先模拟1000w测试数据。
我本地的数据库环境:
/*
Microsoft SQL Server 2012-11.0.2100.60 (Intel X86)
Feb 10201219:13:17
Copyright (c) Microsoft Corporation
Developer Edition on Windows NT 6.1<X86> (Build 7601: Service Pack 1)
*/
1.数据模拟
我们可以创建一个表:
(
id int primary key,
c1 float,c2 float,c3 float,c4 float,c5 float
)
插入10000001条的数据:
(
select1 id,rand(),rand(),rand(),rand(),rand()
union all
select id +1,rand(checksum(newid())),rand(checksum(newid())),
rand(checksum(newid())),rand(checksum(newid())),rand(checksum(newid()))
from maco where id <=10000000
)
insert into TestTable
select* from maco option (maxrecursion 0)
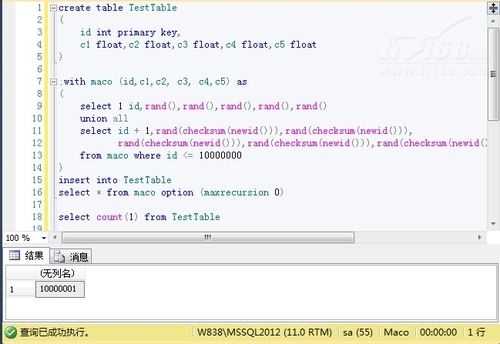
▲图A
确认一下插入数据成功:
我们可以看到表中都是一些随机数:
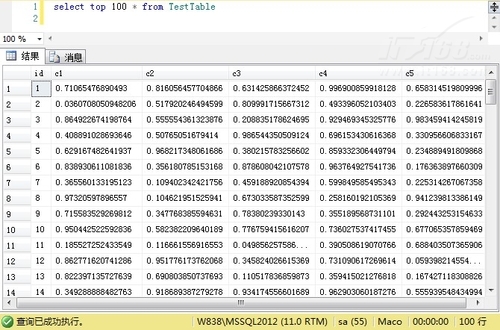
▲图B
2.创建索引
这个表我创建的时候设置了主键,默认是聚集索引,我们可以找到它的名字。
▲图C
我再新建一个列存储索引:
on TestTable(c1,c2,c3,c4,c5)
3.性能比较
测试一下两个索引的性能:逻辑读取次数 ( 66558 vs 114 )
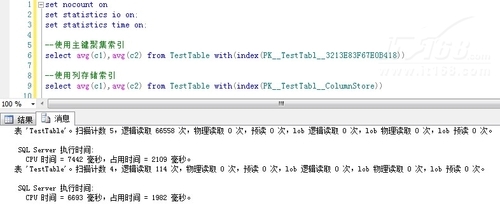
▲图D
我们可以看到I/O大量减少,那么我们多测试几次。
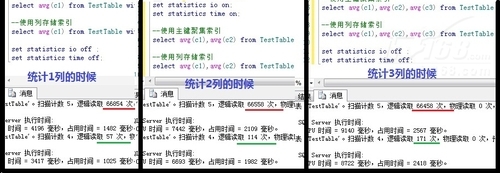
▲图E
原来的索引不管是要查多少列都读取6w多次,而列存储索引的逻辑读取次数和列数是有关系,如上图可以明显的看到要查询的列数和逻辑读取次数是成正比的。
列存储索引可以提高速度的主要原因,数据压缩是一个方便,主要还是他只读取查询中用到的列的索引页,而常规索引需要读取全部索引页,包括查询结果中不使用的列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号