
以前只是知道可变参数怎么用,但是一直对它的原理是似懂非懂,现在对计算机有了比较深刻的认识之后,回头再看,豁然开朗。
要理解可变参数,首先要理解函数调用约定, 为什么只有__cdecl的调用约定支持可变参数,而__stdcall就不支持?
实际上__cdecl和__stdcall函数参数都是从右到左入栈,它们的区别在于由谁来清栈,__cdecl由外部调用函数清栈,而__stdcall由被调用函数本身清栈, 显然对于可变参数的函数,函数本身没法知道外部函数调用它时传了多少参数,所以没法支持被调用函数本身清栈(__stdcall), 所以可变参数只能用__cdecll.
另外还要理解函数参数传递过程中堆栈是如何生长和变化的,从堆栈低地址到高地址,依次存储 被调用函数局部变量,上一函数堆栈桢基址,函数返回地址,参数1, 参数2, 参数3...,相关知识可以参考我的这篇堆栈桢的生成原理
有了上面的知识,我可以知道函数调用时,参数2的地址就是参数1的地址加上参数1的长度,而参数3的地址是参数2的地址加上参数2的长度,以此类推。
于是我们可以自己写可变参数的函数了, 代码如下:
在我们的测试函数中nCount表示后面可变参数的个数,int Sum(int nCount, )会打印后面的可变参数Int值,并且进行累加;string SumStr(int nCount, ) 会打印后面可变参数字符串内容,并连接所有字符串。
)会打印后面的可变参数Int值,并且进行累加;string SumStr(int nCount, ) 会打印后面可变参数字符串内容,并连接所有字符串。
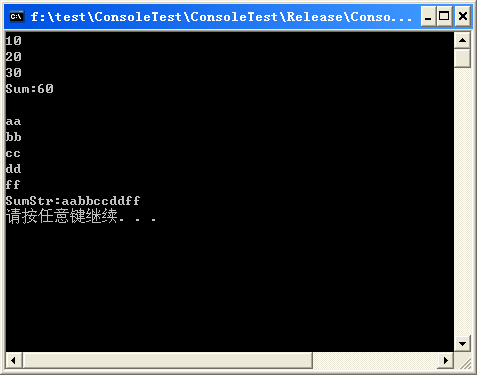
测试结果如下:
可以看到,我们上面的实现有硬编码的味道,也有没有做字节对齐,为此系统专门给我们封装了一些支持可变参数的宏:
用系统的这些宏,我们的代码可以这样写了:
可以看到,其中 va_list实际上只是一个参数指针,va_start根据你提供的最后一个固定参数来获取第一个可变参数的地址,va_arg将指针指向下一个可变参数然后返回当前值, va_end只是简单的将指针清0.
用下面的代码进行测试:
结果如下:
我们上面的例子传的可变参数都是4字节的, 如果我们的可变参数传的是一个结构体,结果会怎么样呢?
下面的例子我们传的可变参数是std::string
运行结果如下:
可以看到即使传入的可变参数是std::string, 依然可以正常工作。
我们可以反汇编下看看这种情况下的参数传递过程:

很多时候编译器在传递类对象时,即使是传值,也会在堆栈上通过push对象地址的方式来传递,但是上面显然没有这么做,因为它要满足可变参数堆栈内存连续分布的规则, 另外,可以看到最后在调用sumStdString后,由add esp, 58h来外部清栈。
一个std::string大小是28, 58h = 88 = 28 + 28 + 28 + 4.
从上面的例子我们可以看到,对于可变参数的函数,有2种东西需要确定,一是可变参数的数量, 二是可变参数的类型,上面的例子中,参数数量我们是在第一个参数指定的,参数类型我们是自己约定的。这种方式在实际使用中显然是不方便,于是我们就有了_vsprintf, 我们根据一个格式化字符串的来表示可变参数的类型和数量,比如C教程中入门就要学习printf, sprintf等。
总的来说可变参数给我们提供了很高的灵活性和方便性,但是也给会造成不确定性,降低我们程序的安全性,很多时候可变参数数量或类型不匹配,就会造成一些不容察觉的问题,只有更好的理解它背后的原理,我们才能更好的驾驭它。
要理解可变参数,首先要理解函数调用约定, 为什么只有__cdecl的调用约定支持可变参数,而__stdcall就不支持?
实际上__cdecl和__stdcall函数参数都是从右到左入栈,它们的区别在于由谁来清栈,__cdecl由外部调用函数清栈,而__stdcall由被调用函数本身清栈, 显然对于可变参数的函数,函数本身没法知道外部函数调用它时传了多少参数,所以没法支持被调用函数本身清栈(__stdcall), 所以可变参数只能用__cdecll.
另外还要理解函数参数传递过程中堆栈是如何生长和变化的,从堆栈低地址到高地址,依次存储 被调用函数局部变量,上一函数堆栈桢基址,函数返回地址,参数1, 参数2, 参数3...,相关知识可以参考我的这篇堆栈桢的生成原理
有了上面的知识,我可以知道函数调用时,参数2的地址就是参数1的地址加上参数1的长度,而参数3的地址是参数2的地址加上参数2的长度,以此类推。
于是我们可以自己写可变参数的函数了, 代码如下:
int Sum(int nCount, )
{
int nSum = 0;
int* p = &nCount;
for(int i=0; i<nCount; ++i)
{
cout << *(++p) << endl;
nSum += *p;
}
cout << "Sum:" << nSum << endl << endl;
return nSum;
}
string SumStr(int nCount,)
{
string str;
int* p = &nCount;
for(int i=0; i<nCount; ++i)
{
char* pTemp = (char*)*(++p);
cout << pTemp << endl;
str += pTemp;
}
cout << "SumStr:" << str << endl;
return str;
}
 )
){
int nSum = 0;
int* p = &nCount;
for(int i=0; i<nCount; ++i)
{
cout << *(++p) << endl;
nSum += *p;
}
cout << "Sum:" << nSum << endl << endl;
return nSum;
}
string SumStr(int nCount,
){
string str;
int* p = &nCount;
for(int i=0; i<nCount; ++i)
{
char* pTemp = (char*)*(++p);
cout << pTemp << endl;
str += pTemp;
}
cout << "SumStr:" << str << endl;
return str;
}
在我们的测试函数中nCount表示后面可变参数的个数,int Sum(int nCount,
)会打印后面的可变参数Int值,并且进行累加;string SumStr(int nCount, ) 会打印后面可变参数字符串内容,并连接所有字符串。然后用下面代码进行测试:int main()
{
Sum(3, 10, 20, 30);
SumStr(5, "aa", "bb", "cc", "dd", "ff");
system("pause");
return 0;
}
Sum(3, 10, 20, 30);
SumStr(5, "aa", "bb", "cc", "dd", "ff");
system("pause");
return 0;
}
测试结果如下:

可以看到,我们上面的实现有硬编码的味道,也有没有做字节对齐,为此系统专门给我们封装了一些支持可变参数的宏:
//typedef char * va_list;
//#define _ADDRESSOF(v) ( &reinterpret_cast<const char &>(v) )
//#define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
//#define _crt_va_start(ap,v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
//#define _crt_va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
//#define _crt_va_end(ap) ( ap = (va_list)0 )
//#define _ADDRESSOF(v) ( &reinterpret_cast<const char &>(v) )
//#define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
//#define _crt_va_start(ap,v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
//#define _crt_va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
//#define _crt_va_end(ap) ( ap = (va_list)0 )
//#define va_start _crt_va_start
//#define va_arg _crt_va_arg
//#define va_end _crt_va_end
用系统的这些宏,我们的代码可以这样写了:
//use va_arg, praram is int
int SumNew(int nCount,)
{
int nSum = 0;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
int n = va_arg(vl, int);
cout << n << endl;
nSum += n;
}
va_end(vl);
cout << "SumNew:" << nSum << endl << endl;
return nSum;
}
//use va_arg, praram is char*
string SumStrNew(int nCount,)
{
string str;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
char* p = va_arg(vl, char*);
cout << p << endl;
str += p;
}
cout << "SumStrNew:" << str << endl << endl;
return str;
}
int SumNew(int nCount,
){
int nSum = 0;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
int n = va_arg(vl, int);
cout << n << endl;
nSum += n;
}
va_end(vl);
cout << "SumNew:" << nSum << endl << endl;
return nSum;
}
//use va_arg, praram is char*
string SumStrNew(int nCount,
){
string str;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
char* p = va_arg(vl, char*);
cout << p << endl;
str += p;
}
cout << "SumStrNew:" << str << endl << endl;
return str;
}
可以看到,其中 va_list实际上只是一个参数指针,va_start根据你提供的最后一个固定参数来获取第一个可变参数的地址,va_arg将指针指向下一个可变参数然后返回当前值, va_end只是简单的将指针清0.
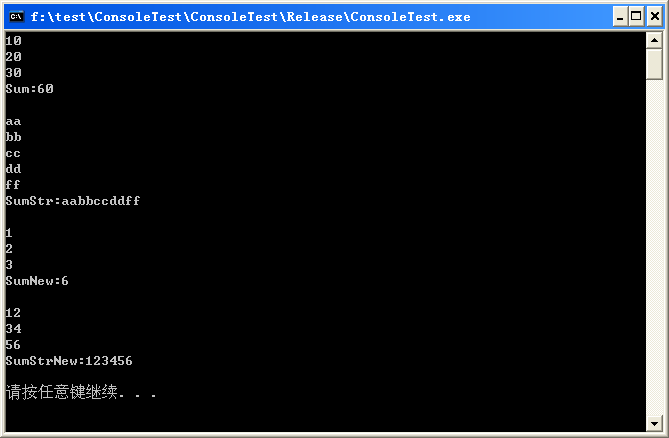
用下面的代码进行测试:
int main()
{
Sum(3, 10, 20, 30);
SumStr(5, "aa", "bb", "cc", "dd", "ff");
SumNew(3, 1, 2, 3);
SumStrNew(3, "12", "34", "56");
system("pause");
return 0;
}
{
Sum(3, 10, 20, 30);
SumStr(5, "aa", "bb", "cc", "dd", "ff");
SumNew(3, 1, 2, 3);
SumStrNew(3, "12", "34", "56");
system("pause");
return 0;
}
结果如下:

我们上面的例子传的可变参数都是4字节的, 如果我们的可变参数传的是一个结构体,结果会怎么样呢?
下面的例子我们传的可变参数是std::string
//use va_arg, praram is std::string
void SumStdString(int nCount,)
{
string str;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
string p = va_arg(vl, string);
cout << p << endl;
str += p;
}
cout << "SumStdString:" << str << endl << endl;
}
void SumStdString(int nCount,
){
string str;
va_list vl = 0;
va_start(vl, nCount);
for(int i=0; i<nCount; ++i)
{
string p = va_arg(vl, string);
cout << p << endl;
str += p;
}
cout << "SumStdString:" << str << endl << endl;
}
int main()
{
Sum(3, 10, 20, 30);
SumStr(5, "aa", "bb", "cc", "dd", "ff");
SumNew(3, 1, 2, 3);
SumStrNew(3, "12", "34", "56");
string s1("hello ");
string s2("world ");
string s3("!");
SumStdString(3, s1, s2, s3);
system("pause");
return 0;
}
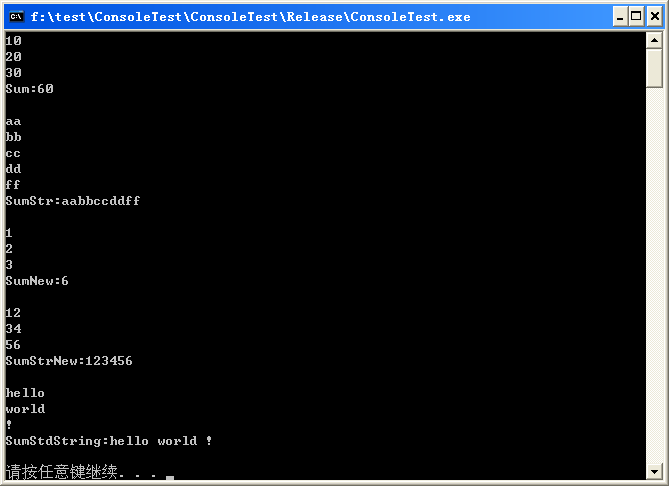
运行结果如下:

可以看到即使传入的可变参数是std::string, 依然可以正常工作。
我们可以反汇编下看看这种情况下的参数传递过程:

很多时候编译器在传递类对象时,即使是传值,也会在堆栈上通过push对象地址的方式来传递,但是上面显然没有这么做,因为它要满足可变参数堆栈内存连续分布的规则, 另外,可以看到最后在调用sumStdString后,由add esp, 58h来外部清栈。
一个std::string大小是28, 58h = 88 = 28 + 28 + 28 + 4.
从上面的例子我们可以看到,对于可变参数的函数,有2种东西需要确定,一是可变参数的数量, 二是可变参数的类型,上面的例子中,参数数量我们是在第一个参数指定的,参数类型我们是自己约定的。这种方式在实际使用中显然是不方便,于是我们就有了_vsprintf, 我们根据一个格式化字符串的来表示可变参数的类型和数量,比如C教程中入门就要学习printf, sprintf等。
总的来说可变参数给我们提供了很高的灵活性和方便性,但是也给会造成不确定性,降低我们程序的安全性,很多时候可变参数数量或类型不匹配,就会造成一些不容察觉的问题,只有更好的理解它背后的原理,我们才能更好的驾驭它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号