

前言
学习python,官方版本其实足够了。但是如果追求更好的开发体验,耐得住不厌其烦地折腾。那么我可以负责任的告诉你:IPython是我认为的唯一显著好于原版python的工具。
整理了《Python 二三事》:http://pre-sence.com/archives/python-intro 《Python 四五事》:http://pre-sence.com/archives/python-misc 并加入安装IPython部分。
写这篇随笔的原因是:忽然醒悟之前我安装IPython折腾许久不成功可能是我未能想起pip或easy_install这两个python的上帝工具。参考:Python包管理工具pip与easy_install
个人经验总结:IPython,是学习python的利器,是让Python显得友好十倍的外套,是我唯一的强烈推荐。
安装IPython
任何Linux发行版对编程者都十分友好:
Ubuntu为例: sudo apt-get install ipython
windows环境:
1、下载ez_setup.py ,右击左边链接,另存为,使用python ez_setup.py运行,或直接双击。
2、步骤1成功后,cmd下输入命令easy_install -h可以测试,正常反应说明已经可以使用easy_install了。
3、cmd下输入easy_install pip安装pip,这是因为pip正是easy_install的下一代,比easy_install好用。
4、步骤3成功后,pip install ipython。
5、如果步骤4不行,退一步,使用easy_install ipython安装。
运行IPython
cmd提示符下,输入ipython运行就可以使用除了原python外,IPython多出来的贴心的“I”了。
退出IPython
与python一样也是输入exit
Python实用技巧:
1、关于 "_" 字符使用
在 Python shell 下 _ 总是被赋予之前最后一个表达式的值(注:@pythonwood)。这里看个例子应该就能清楚:
>>> import string >>> string.letters 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' >>> print _ abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ >>>2014 2014 >>> v = _ >>> v 2014
举个实际的例子,比如你在调试时读文件的时候直接进行 f.read() ,你看了看发现输出结果很有意思,想要对它进行进一步处理,但发现读的时候忘记赋值了。以往你只能叹叹气重新开文件再读一次,现在你只要执行 result = _,把 _ 附到另外一个变量就可以了。
2、python -m
相信很多人应该用过这个东西,Python 很多标准库都提供这样的调用方式来实现一些简单的命令行功能。Python 3 现在自带 pip。比如我们想使用 Python 3 的 pip 来安装别的库,我们可以这样:
py -3 -m pip install bottle
跟你预料的一样,这样就可以了。当然你可以用个 .bat 文件来把这些包裹起来并放在 Path 上,一个简单的例子,把下面的内容写到一个叫 pip3.bat 的文件里:
@echo off
py -3 -m pip %*
并放到 Path 上,就可以方便调用了。其中 %* 负责传递所有的命令行参数。
实际上 python -m 可以用的东西还真的挺多,这里给出一个不完全的列表:
######################################################
# 最强功能
######################################################
# 局域网共享,宿舍中任意一台笔记本都可以瞬间变身web资源共享服务器
# 命令ipconfig可以看到局域网ip地址,一般是192,172这些开头的。
# 使用本机80端口,可任意设置。只共享当前运行目录。
#
python -m SimpleHTTPServer 80
#
# 本机任意浏览器输入 http://localhost 或 http://127.0.0.1 可以访问。
# (80端口浏览器默认的,不需输入)甚至在地址栏直接输入localhost即可。
# 局域网,(宿舍)任意电脑输入上面所说192或172等开头的IP地址即可访问。
######################################################
# 缩进输出 JSON
echo {"hey" : "kid"} | python -m json.tool
# 简单的执行时间测量
python -m timeit [ix*ix for ix in range(100)]
# 简单的 Profiling
python -m cProfile myscript.py
# 比较两个文件夹的区别
python -m filecmp path/to/a path/to/b
# base64 转换
echo foo bar | python -m base64
# 调用默认浏览器打开一个新标签页
python -m webbrowser -t http://google.com
# 生成程序文档
python -m pydoc myscript.py
# 类似 nose 的自动搜索 unittest
python -m unittest discover
# 调用 pdb 执行代码
python -m pdb myscript.py
IPython实用技巧:
1、Tab自动补全,一种是简单的关键字补全,另外一种是对象的方法和属性补全。
作为例子,我们先引入 sys 模块,之后再输入 sys. (注意有个点),此时按下 tab 键,IPython 会列出所有 sys 模块下的方法和属性。
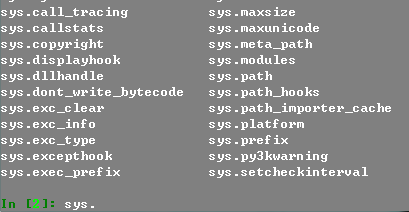
接着上面的例子,我们输入 sys?,这样会显示出 sys 模块的 docstring及相关信息。很多时候这个也是很方便的功能。

2、IPython 还有强大之处很大部分还体现在它的 magic function 中。它是指的在 IPython 环境下执行以 % 开头的一些命令来对 IPython 进行一些设定或者执行某些功能。在 IPython 中输入 %lsmagic 就能列出所有的 magic functions。在这里简单介绍下几个比较有意思的,你也可以自己通过查看文档来找找有哪些你特别用的到得。
-
之前看到能用
?来查询函数的文档,对于 magic function 也是如此。比如%run?。 -
!cd ..在命令前面加上!则它会被作为命令行命令执行,这样你就不用退出 IPython 来进行命令行操作。 -
%run foo.py在当前环境下直接执行foo.py,效果跟命令行下调用ipython foo.py相同。 -
%time foo.bar()跟timeit decorator作用相同,进行简单的 profile。 -
%hist能显示之前输入过的命令的历史,同时你可以用In[<linenumber>]来访问之前的命令。比如%exec In[10]就能执行列表中第十行。 -
%rep类似上面的_变量,但是是以字串的形式返回 -
最后,如果
%automagic是打开的状态的话,所有 magic function 不需要在前面加%就能正确调用。
在当前 IPython 版本中还有一个由于安全原因没有默认引入的 %autoreload,它的作用是在可以自动重新载入你调用的函数,以及其相关模块。接触过 django 的同学对这个应该比较熟悉,在 IPython 中的效果就是,当你在调试一个一直在反复改动的函数时,你可以开启这个功能保证每次调用都会重新读取最新的版本,让你在源码中的改动马上生效。在 IPython 中执行
import ipy_autoreload %%autoreload 2
这样 IPython 会对所有的模块都进行 autoreload。你可以通过执行 %autoreload? 来查询它的文档来进行进一步设定。如果你希望 IPython 每次启动自动载入次功能,那么可以通过配置 ipythonrc (在 Windows 下可以在 C:\Users\<username>\_ipython\ipythonrc.ini 找到) 来进行相关设置。
3、还有一个很神奇的功能。如果你的程序是由命令行开始执行的,即在命令行下输入 python foo.py(大部分 Python 程序都是),那么你还可以利用 IPython 在你的程序任意地方进行断点调试!
在你程序中任意地方,加入如下语句:
from IPython.Shell import IPShellEmbed IPShellEmbed([])()
注意:最近 IPython 发布了 0.11 版本,各方面变化都非常大,API 也经过了重新设计。如果你使用的是 0.11 那么上面两行对应的是这样的:
from IPython import embed embed()
再和平常一样运行你的程序,你会发现在程序运行到插入语句的地方时,会转到 IPython 环境下。你可以试试运行些指令,就会发现此刻 IPython 的环境就是在程序的那个位置。你可以逐个浏览当前状态下的各个变量,调用各种函数,输出你感兴趣的值来帮助调试。之后你可以照常退出 IPython,然后程序会继续运行下去,自然地你在当时 IPython 下执行的语句也会对程序接下来的运行造成影响。
这个方法我实在这里看 到的。想象一下,这样做就像让高速运转的程序暂停下来,你再对运行中的程序进行检查和修改,之后再让他继续运行下去。这里举一个例子,比如编写网页 bot ,你在每取回一个页面后你都得看看它的内容,再尝试如何处理他获得下一个页面的地址。运用这个技巧,你可以在取回页面后让程序中断,再那里实验各种处理方 法,在找到正确的处理方式后写回到你的代码中,再进行下一步。这种工作流程只有像 Python 这种动态语言才可以做到。
4、一个实际的例子
这里以一个简单的例子来讲解一下是怎样的一个情况。我们要写一个可以将简单的数据表达式,类似 1 + (2 - 3) * 456 解析成树的 Pratt Parser。首先我们需要一个 lexer 把每个 token 解析出来,那么最开始的代码就是:
# simple math expression parser
def lexer(s):
'''token generator, yields a list of tokens'''
yield s
if __name__ == '__main__':
for token in lexer("1 + (2 - 3) * 456"):
print token
明显这个没有任何意义,但现在程序已经有足够的东西能够跑起来。我们把这个程序存为 expr.py,开启一个命令行窗口,运行 ipython 然后像这样执行它:
$ ipython IPython 0.13.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. ... In [1]: run expr.py 1 + (2 - 3) * 456
在 IPython 里面用 run 跑的好处有很多,首先是你在程序执行完毕后整个程序的状态,比如最后全局变量的值,你写的函数这些你都是可以随便执行的!同样的你可以在 IPython 里面保存一些用来测试的常量,每次用 run 跑的话新的程序会被重新载入,你可以这样方便的测试每个函数,有一个非常动态的环境来调试你的程序:
In [2]: print token # 注意这里 token 就是 __main__ 里面的那个 token 的值
1 + (2 - 3) * 456
In [3]: print list(lexer('1+2+3')) # 可以运行你写的函数
['1+2+3']
然后按照之前的想法,我们尝试把这个 lexer 写出来。在这个过程中,IPython 可以用来查看函数的文档,测试如何调用某些函数,看看返回值是什么样子等等,还是跟上面的说的一样,我们有一个动态的环境可以真真正正的执行程序,你可以 在把代码写到你珍贵的主程序之前就有机会运行它,这样你可以更确认你的代码能正常工作:
In [4]: s = "foo" # 忘记判断字符串是数字的函数的名字了,用一个字符串试试看 In [5]: s.is # 开头大概是 is,这里按下 tab 键 IPython 会帮我们补全 s.isalnum s.isalpha s.isdigit s.islower s.isspace s.istitle In [6]: s.isdigit? # 结果是 isdigit,在表达式后加上问号并回车查看文档 Type: builtin_function_or_method String Form:<built-in method isdigit of str object at 0x1264f08> Docstring: S.isdigit() -> bool Return True if all characters in S are digits and there is at least one character in S, False otherwise. In [8]: s.isdigit() # 调用试试看 Out[8]: False In [9]: 'f' in 'foo' # 试试字符串能不能用 in 来判断 Out[9]: True
确认了各个步骤以后,我们把 lexer 的代码填起来。我们为了节省纵向的空间我们把很多东西写在一行里面:
# simple math expression parser (broken lexer)
def lexer(s):
'''token generator'''
ix = 0
while ix < len(s):
if s[ix].isspace(): ix += 1
if s[ix] in "+-*/()":
yield s[ix]; ix += 1
if s[ix].isdigit():
jx = ix + 1
while jx < len(s) and s[jx].isdigit(): jx += 1
yield s[ix:jx]; ix = jx
else:
raise Exception("invalid char at %d: '%s'" % (ix, s[ix]))
yield ""
if __name__ == '__main__':
print list(lexer("1 + (2 - 3) * 456"))
看起来不错,我们还是在 IPython 里执行试试,结果发现程序抛出了一个异常:
In [6]: run expr.py
------------------------------------------------------------------
Exception Traceback (most recent call last)
py/expr.py in <module>()
18
19 if __name__ == '__main__':
---> 20 print list(lexer("1 + (2 - 3) * 456"))
py/expr.py in lexer(s)
13 yield s[ix:jx]; ix = jx
14 else:
---> 15 raise Exception("invalid character at ...))
16 yield ""
17
Exception: invalid character at 3: ' '
嗯?好像程序里已经处理了空格的情况。怎么会这样?不知道你碰到异常的时候一般都怎么办。你可能会选择到处添加 print,用 IDE 断点调试。其实这种情况用 pdb 是很明智的选择,在 IPython 里我们可以非常轻松的使用它。
In [13]: pdb # 开启 pdb ,这样在异常的时候我们会自动的 break 到异常处
Automatic pdb calling has been turned ON
In [14]: run expr.py
-----------------------------------------------------------------
Exception: invalid character at 3: ' '
> py/expr.py(15)lexer()
14 else:
---> 15 raise Exception("invalid char at ...))
16 yield ""
ipdb> print ix # 这里我们可以执行任何 Python 的代码
3
ipdb> whatis ix # 也可以用 pdb 提供的命令,输入 help 可以查看所有命令
<type 'int'>
通过方便的调试和仔细检查代码,我们发现是没有正确的使用 elif 造成了问题!(我知道这个过程不是太符合情理...)。把代码里的后面的几个 if 都换成 elif 以后我们发现结果基本上是对的了。我们可以马上再跑几个类似的例子,确认不同的输入是否都有比较好的结果:
In [18]: run expr.py # 这次差不多对了,我们可以试试几个别的例子
['1', '+', '(', '2', '-', '3', ')', '*', '456', '']
In [19]: print list(lexer("1*123*87-2*5"))
['1', '*', '123', '*', '87', '-', '2', '*', '5', '']
# 跟在 shell 里面一样,你可以用上下来选取之前的记录,然后简单的修改再重新执行。
# 记得每次 run 后你的函数都是最新版本,你可以很简单的用重复的数据来测试你的函数
# IPython 甚至还实现了 Ctrl+R!自己试试看吧
In [19]: print list(lexer("1 + two"))
Exception: invalid character at 2: 't'...
在一段痛苦的调试之后,我们最终把程序写出来了。很遗憾程序超出了我预计的长度,就不贴在这里了。后面部分的开发过程跟前面基本还是一样,总结起来就是:
- 保持你的程序是一个可以运行并且有意义的状态,尽可能频繁的运行。
- 在 IPython 里查看文档,尝试小的程序片段,测试些你不确定的做法,确定之后再把东西添加到你的代码里。
- 用不同的参数在 IPython 里测试你正在编写的函数/class。
- 当遇到问题的时候,先简单的用
pdb在异常处 break,十有八九都能有些头绪。
额外的注意事项
这里举的例子是你所有的开发都是在单个 .py 文件里的。现实生活中你很有可能会横跨几个文件一起修改。请务必注意,在 IPython 里你每次 run 的时候只有被 run 的那个文件里的东西会是最后修改的版本,其 import 的东西如果在期间被修改是不会反应出来的。
这个的原理就跟你在 Python shell 里在修改前修改后重复 import 某个模块不会有作用是一样的,Python 神奇的 import 机制不会去追踪其他模块的修改。你可以手动用 reload 函数来重新载入,你也可以使用 IPython 的 autoreload 功能来让你忽略这个问题。个人来说我没怎么用过这个功能,IPython 没有默认开启它可能也是有些顾虑,请自己评估看看。
另外你应该已经注意到,run 的效果基本上就是把你的代码拷贝进 IPython 里执行一遍。对于没有 __main__ 的文件,你也可以 run,这样里面定义的函数和 class 就会反映出你的更改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号