

(MAE)Masked Autoencoders Are Scalable Vision Learners(掩码自动编码器是可扩展的视觉学习者)阅读笔记(10.27)
摘要:MAE是可扩展的计算机视觉自监督学习。原理:屏蔽输入图像的随机patch并重建缺失的像素。基于两个核心设计。一:非对称编码器-解码器体系结构,编码器仅操作未被掩码的patch,轻量级解码器从潜在表征和掩码标记中重建原始图像。二:对于输入图像的高比例屏蔽会产生一个重要而有意义的自我监督任务。结合二者能够高效有效的训练大模型(X3或者更大)并提高精度。
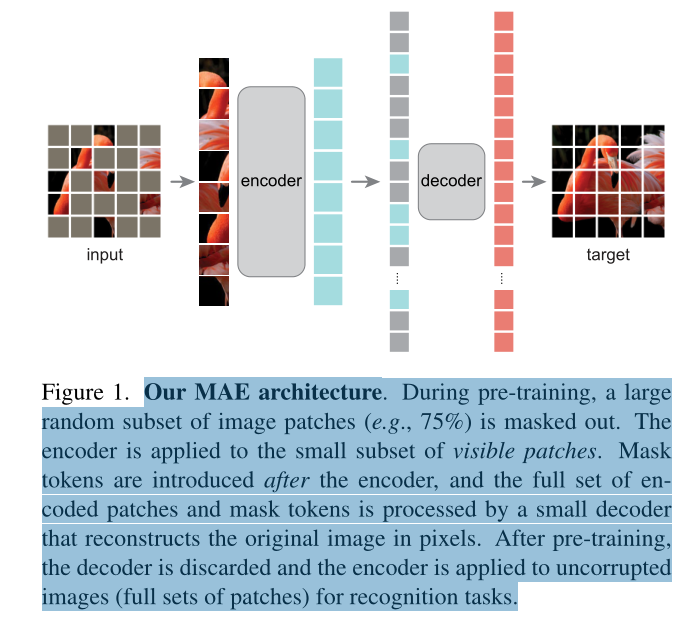
MAE架构:
预训练中,屏蔽大量的图像补丁。编码器应用位掩码的补丁。
编码器之后引入掩码令牌,有一个轻量级的解码器对于完整的编码补丁和掩码令牌进行处理,以像素为单位重建原始图像。经过预训练后,丢弃解码器,将编码器用于未损坏的图像(全套补丁)进行识别任务。
- 介绍
深度学习见证了架构能力和容量的爆发式增长。数据集从100万到数亿标记图片。NLP通过自监督训练解决数据需求。GPT和BERT中掩码自动编码的解决方案在概念上很简单:删除一部分数据,并学会预测被删除的内容。
掩码自编码器的思想是一种更通用的去噪自编码器的形式。掩码自动编码器在视觉和语言之间的不同的原因:A:直到最近,架构都是不同的。B:语言和视觉之间的信息密度是不同的。语言具有高度的语义和信息密度,而图像具有严重的空间冗余性的自然信号。一个丢失的补丁可以从相邻的补丁中恢复。为了克服这种差异并鼓励学习有用的特征,本文展示了一个在计算机视觉中工作良好的简单策略:屏蔽非常高比例的随机补丁。该策略很大程度上减少了冗余,并且创建一个有挑战的任务,只去关注全局信息而不去关注局部信息的自我监督任务。简单的用可见的补丁覆盖输出以提高视觉质量。C:自动编码器的解码器将潜在的表示映射回输入,在重建文本和图像之间起着不同的作用。在视觉中解码器对像素进行重构,其输出的语义级别比普通识别任务低,语言相反。语言中解码器可以是简单的MLP,但是对于图像而言解码器在决定学习到的潜在表征的语义级别方面起到关键作用。
基于以上分析,本文提出一个简单有效可扩展的掩码自动编码器(MAE)的视觉表示学习形式。MAE从输入图像中随机屏蔽patch并在像素空间重建缺失的patch。MAE有一个非对称编码器-解码器。编码器只处理可见patch,解码器轻量级并在潜在表示和掩码标记中重建输入。将掩码标记转移到非对称结构的小解码器可以大大减少计算量。
非常高的屏蔽率(75%)可以实现双赢:优化了精度,同时减少计算量。使得MAE可以扩展到大模型。
MAE学习的是泛化能力很强的大容量模型。不同的掩码比率还原率还是挺好的。
- 相关工作:
掩码语言建模及其自回归对应方法。这些方法保留输入序列的一部分,并训练模型来预测缺失的内容。可以很好的扩展应用到下游任务。
自动编码是学习表示的经典方法:编码器将输入映射到潜在表示和解码器重构输入。MAE是一种去噪自编码与经典的DAE许多不同。
掩模图像编码从被掩模损坏的图像中学习表示。上下文编码器使用卷积网络填充大的缺失区域。
自监督学习方法通常侧重于不同的代理任务进行训练。对比学习和相关方法强烈的依赖数据增强。
- 方法
MAE是一种简单的自动编码方法,在给定的局部观测条件下重建原始信号。非对称、编码器仅处理可见patch,解码器处理patch和掩码标记。
掩码:
根据VIT将图像划分为不重叠的patch。然后对补丁进行子集采集并屏蔽剩余patch。抽样策略:随机抽样。
具有高度遮蔽比的随机抽样很大程度消除冗余。均匀分布防止潜在的中心偏差(即在图像中心附近有很多的遮蔽块)。高度稀疏的输入为编码器的高效设计提供条件。
MAE编码器:
编码器是一个VIT,只用可见patch,添加位置编码的线性投影编码patch。屏蔽patch被移除;不使用mask 标记,可以训练一个非常大的编码器。
MAE解码器:
MAE解码器的输入是由编码器可见的patch和掩码标识组成的完整标记集。每个掩码标记都是共享,学习向量,表示存在一个要预测的patch。然后加入位置编码,掩码标记获得他们在图像中的位置信息。MAE解码器仅在预训练阶段用于图像重建(只有编码器产生识别的图像表示),可以独立于编码器设计解码器架构。使用轻量级解码器大大减少预训练的时间。
重建目标:
MAE通过预测每个被屏蔽补丁的像素值来重建输入。解码器输出的每一个元素都表示一个patch的像素值向量。解码器最后一层是一个线性投影,输出通道数是patch的像素值的数量。损失函数计算重建图像和原始图像在像素空间中的均方误差,只算掩码补丁上的损失。
本文一个研究变体:重建目标是每个被屏蔽的patch的归一化像素值。具体来说,我们计算一个补丁中所有像素的平均值和标准差,并使用它们来规范化这个补丁。在实验中,采用归一化像素作为重建目标提高了再现质量。
简单实现:
MAE预训练可以有效实现,不需要任何专门的稀疏操作。首先,我们为每个输入补丁生成一个令牌(通过添加位置编码的线性投影)。接下来,我们随机打乱令牌列表,并根据屏蔽比删除列表的最后一部分。这个过程为编码器产生一个标记的小子集,相当于没有替换的采样补丁。编码之后,我们将掩码令牌的列表附加到编码补丁的列表中,并对这个完整的列表进行反排序(反转随机排序操作),以使所有令牌与它们的目标对齐。解码器应用于这个完整的列表(添加了位置编码)。如前所述,不需要任何稀疏操作。这个简单的实现引入了微不足道的开销,因为变换和反变换操作非常快。
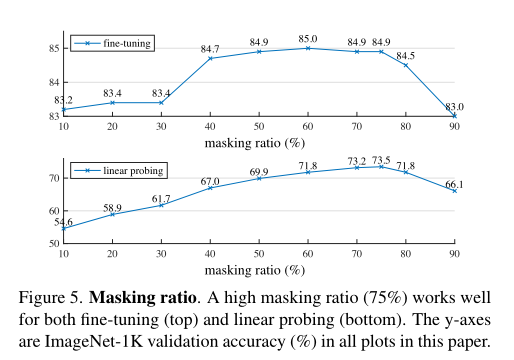
屏蔽率。高掩蔽率(75%)适用于微调(上)和线性探测(下)。y轴为本文所有图中ImageNet-1K验证精度(%)。
- 实验
本文来自博客园,作者:键盘侠牧师,转载请注明原文链接:https://www.cnblogs.com/wangzhe52xia/p/17699833.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号