

1. 了解对比Hadoop不同版本的特性,用图表的形式呈现如下表:
|
hadoop版本 |
特性 |
|
0.14.1版本
|
安全 |
|
1.0版本 |
从主干向后移植HDFS的许多性能改进 |
|
1.1版本 |
DistCp v2向后移植 |
|
1.2版本 |
HDFS HA for NameNode (manual failover) |
|
2.0版本 |
HDFS HA for NameNode (manual failover) |
|
2.2版本 |
YARN-Hadoop的通用资源管理系统,允许MapReduce和其他其他数据处理框架和服务 |
|
2.3版本 |
支持HDFS中的异构存储层次结构。 |
|
2.4版本 |
支持HDFS中的访问控制列表 |
|
2.5版本 |
使用HTTP代理服务器时的身份验证改进。 |
|
2.6版本 |
Hadoop常见 |
|
2.7版本 |
此版本放弃了对JDK6运行时的支持,并且仅与JDK 7+一起使用。 |
|
2.8版本 |
支持异步呼叫重试和故障转移,可在重试工作中用于异步DFS实现。 HDFS WebHDFS增强功能:在WebHDFS中集成CSRF预防过滤器,在WebHDFS中支持OAuth2,通过WebHDFS禁用/允许快照 |
|
2.9版本 |
共同 HADOOP资源估计器。有关更多详细信息,请参见用户文档。 基于HDFS路由器的联盟。有关更多详细信息,请参见用户文档。 YARN时间轴服务v.2。有关更多详细信息,请参见用户文档。 |
|
3.0版本 |
最低要求的Java版本从Java 7增加到Java 8 支持HDFS中的擦除编码 HDFS删除编码文档中提供了更多详细信息。、 提供了YARN Timeline Service v.2 alpha 2,以便用户和开发人员可以对其进行测试并提供反馈和建议,以使其可以替代Timeline Servicev.1.x。仅应以测试能力使用。 Shell脚本重写 2.x版本中提供的hadoop-client Maven工件将Hadoop的可传递依赖项拉到Hadoop应用程序的类路径中。如果这些传递依赖项的版本与应用程序使用的版本冲突,则可能会出现问题 HADOOP-11804添加了新的hadoop-client-api和hadoop-client-runtime工件,将Hadoop的依赖项隐藏在一个jar中。这样可以避免将Hadoop的依赖项泄漏到应用程序的类路径中。
|
|
3.1版本 |
Yarn Service框架提供了一流的支持和API,以在YARN中本地托管长期运行的服务。 YARN上一流的GPU调度和隔离(适用于docker / non-docker容器)。 ARN上一流的FPGA调度和隔离(适用于docker / non-docker容器)。 支持管理员为队列指定绝对资源(X内存,Y VCore,Z GPU等),而不是提供基于百分比的值。这为管理员提供了更好的控制,以配置给定队列所需的资源量。 提供的存储允许将HDFS外部存储的数据映射到HDFS并从中寻址。通过将新的存储类型PROVIDED引入DataNode中的媒体集,它基于异构存储而构建。 |
|
3.2版本 |
YARN中的节点属性支持 Hadoop Submarine使数据工程师可以在数据驻留的同一Hadoop YARN集群上轻松开发,训练和部署深度学习模型(在TensorFlow中)。 支持HDFS(Hadoop分布式文件系统)应用程序,以便在文件/目录上设置存储策略时在存储类型之间移动块。 ABFS文件系统连接器 增强型S3A连接器 升级YARN长期服务 |
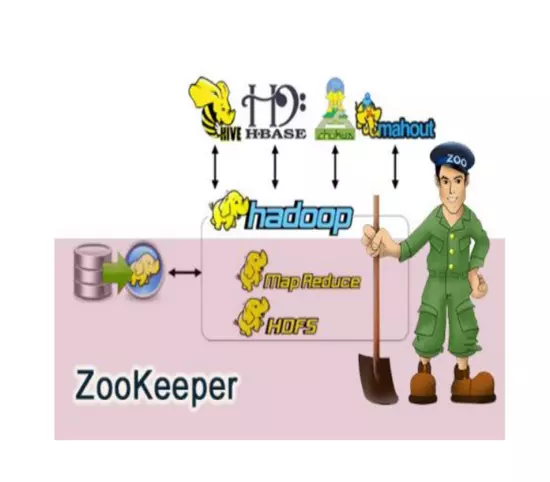
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现:
Hadoop生态圈:
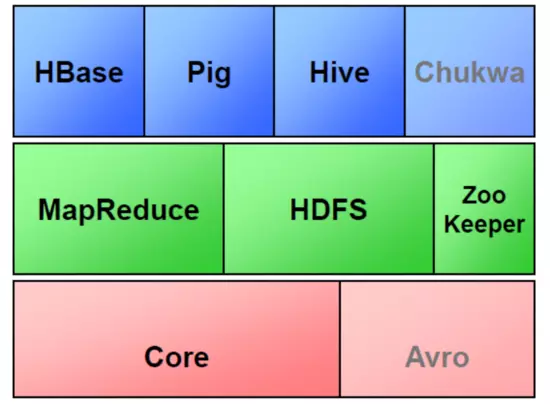
①HBase
Google Bigtable的开源实现
列式数据库
可集群化
可以使用shell、web、api等多种方式访问
适合高读写(insert)的场景
HQL查询语言
NoSQL的典型代表产品
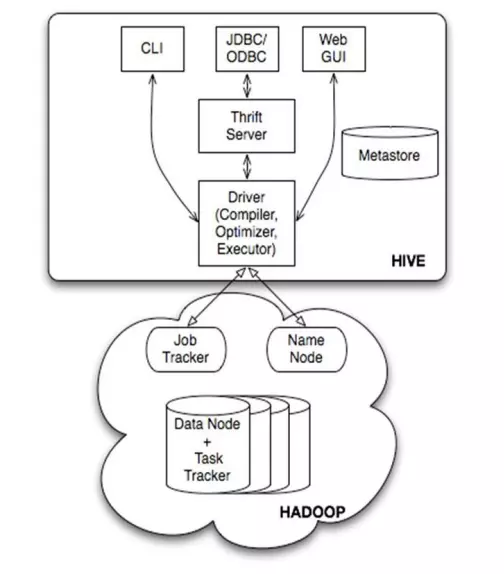
②Hive
数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
可以看成是从SQL到Map-Reduce的映射器
提供shell、JDBC/ODBC、Thrift、Web等接口
③Zookeeper
Google Chubby的开源实现
用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
应用场景:Hbase,实现Namenode自动切换
工作原理:领导者,跟随者以及选举过程
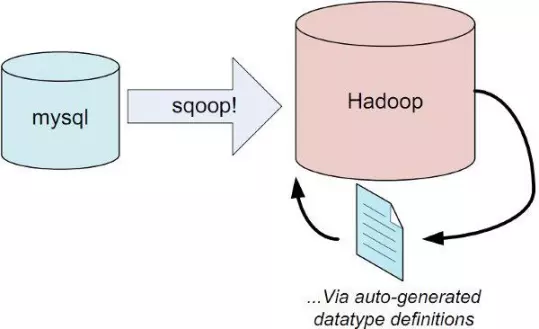
④Sqoop
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据库
⑤Chukwa
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析

⑥Pig
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼

⑦Avro
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口

⑧Cassandra
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求

Hadoop生态圈流程图
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项:
-
→Projects
→Projects List
-
一、下载
http://hadoop.apache.org/ hadoop官网
![]()
![]()
![]()
二、解压
![]()
注:使用管理员权限解压
三、配置环境变量
添加HADOOP_HOME配置:自己安装hadoop路径,我的是D:\hadoop-3.0.3
在Path中添加如下:自己安装hadoop路径/bin,如:D:/hadoop-3.0.3/bin
四、hadoop需要jdk支持,jdk路径不能有空格,如有空格,可以这样,如:”D:\Program Files"\Java\jdk1.8.0_25
五、hadoop路径下创建data用于数据存储,再在data下创建datanode目录和namenode目录
六、hadoop配置
四个hadoop路径/etc/hadoop/core-site.xml,etc/hadoop/mapred-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/yarn-site.xml
1.core-site.xml
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
myeclipse上配置hadoop时,localhost需写成自己的IP
2.mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
3.hdfs-site.xm
- <configuration>
- <!-- 这个参数设置为1,因为是单机版hadoop -->
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/D:/hadoop-3.0.3/data/namenode</value>
- </property>
- <property>
- <name>fs.checkpoint.dir</name>
- <value>/D:/hadoop-3.0.3/data/snn</value>
- </property>
- <property>
- <name>fs.checkpoint.edits.dir</name>
- <value>/D:/hadoop-3.0.3/data/snn</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/D:/hadoop-3.0.3/data/datanode</value>
- </property>
27.</configuration>
4.yarn-site.xml
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
11.</configuration>
七、修改D:/hadoop-3.0.3/etc/hadoop/hadoop-env.cmd配置,找到set JAVA_HOME=%JAVA_HOME%替换为set JAVA_HOME="D:\Program Files"\Java\jdk1.8.0_25
八、winutils中对应的hadoop版本中的bin替换自己hadoop安装目录下的bin
![]()
找到对应的版本下的bin替换hadoop中的bin
配置完成
九、启动服务
1.cmd中,D:\hadoop-3.0.3\bin> hdfs namenode -format
执行后,data下的namenode和datanode下会有current等文件,我当时安装的是hadoop3.1.1,用的winutils中的hadoop3.0.0,datanode总是没有启动没有数据,换成hadoop3.0.3,使用wintuils的hadoop3.0.0后,就可以了。
2.D:\hadoop-3.0.3\sbin启动start-all.cmd服务,会看到
- Hadoop Namenode
- Hadoop datanode
- YARN Resourc Manager
- YARN Node Manager
十、HDFS应用
![]()
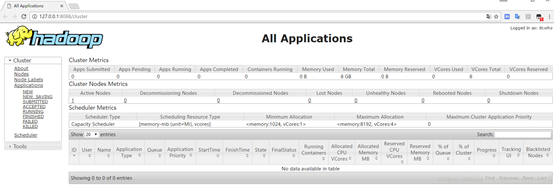
1、通过http://127.0.0.1:8088/即可查看集群所有节点状态:
2、访问http://localhost:9870/即可查看文件管理页面:
a.进入文件系统
![]()
b.创建目录
![]()
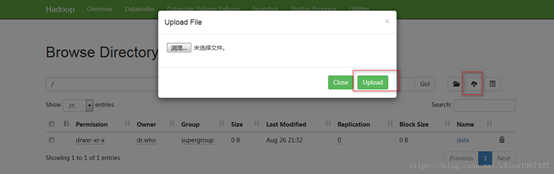
c.上传成功
![]()
注:在之前的版本中文件管理的端口是50070,在3.0.0中替换为了9870端口
![]()
d.使用hadoop命令进行文件操作
mkdir命令创建目录:hadoop fs -mkdir hdfs://ip:9000/user
![]()
put命令上传文件:hadoop fs -put D:/a.txt hdfs://ip:9000/user/z
-
![]()










 浙公网安备 33010602011771号
浙公网安备 33010602011771号