
下面几个小节分别介绍了几种聚类算法
9.4 原型聚类
原型聚类亦称“基于原型的聚类”,此类算法假设聚类结构能够通过一组原型刻画,在现实聚类任务中极为常见。通常情况下,算法先对原型进行初始化,然后对原型进行迭代更新求解。
9.4.1 k均值算法
在这个算法中,我们把所有项分为k个簇,使得相同簇中所有项彼此尽量相似,而不同簇之间彼此尽量不相似。
给定样本集D={x1,x2,...,xm},k均值算法针对聚类所得簇划分C={C1,C2,...,Ck}最小化平方误差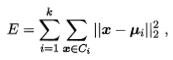
其中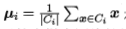 是簇Ci的均值向量,直观来看,在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E值越小则簇内样本相似度越高。
是簇Ci的均值向量,直观来看,在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E值越小则簇内样本相似度越高。
k均值算法采用了贪心策略,通过迭代优化来近似求解式。
算法步骤:1.在数据域随机生成k个初试“均值”,对均值向量尽心初始化;2.通过关联每个观测值到最近的均值,创建k个簇;3.计算新的均值向量,每个簇的形心变为新的均值;4.重复步骤2 3直至收敛,即当前均值向量均未更新。

9.4.2 学习向量量化
“学习向量量化”(简称LVQ)也是试图找到一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ假设数据样本带有类别标记,学习过程利用样本这些监督信息来辅助聚类。
给定样本集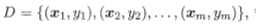 ,每个样本xj是由n个属性描述的特征向量
,每个样本xj是由n个属性描述的特征向量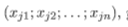 ,yi是样本xj的类别标记,LVQ的目标是学得一组n维原型向量{p1,p2,...,pq},,每个原型向量代表一个聚类簇。
,yi是样本xj的类别标记,LVQ的目标是学得一组n维原型向量{p1,p2,...,pq},,每个原型向量代表一个聚类簇。

算法步骤:1.对原型向量进行初始化,对第q个簇可以从类别标记为tq的样本中随机选取一个作为原型向量。2.对原型向量进行迭代优化,在每一轮迭代中,算法随机选取一个有标记的训练样本,找出与其距离最近的原型向量,并根据两者类别是否一致来对原型向量进行相应的更新:若最近的原型向量pi*与xj的类别标记相同,则令pi*向xj的方向靠拢,此时新原型向量为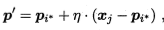
p`与xj之间的距离为 ,令学习率属于(0,1)在更新p`之后将更接近xj;类似的,若pi*与xj的类别标记不相同,则更新后的原型向量与xj之间的距离将增大为
,令学习率属于(0,1)在更新p`之后将更接近xj;类似的,若pi*与xj的类别标记不相同,则更新后的原型向量与xj之间的距离将增大为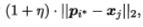 从而更远离xj。3.若算法的停止条件已满足(例如已达到最大迭代轮数,或原型向量更新很小甚至不再更新),则当前原型向量作为最终结果返回。
从而更远离xj。3.若算法的停止条件已满足(例如已达到最大迭代轮数,或原型向量更新很小甚至不再更新),则当前原型向量作为最终结果返回。
9.4.3 高斯混合聚类
高斯混合聚类理解起来较为困难,可参阅https://blog.csdn.net/lotusng/article/details/79990724此博客。
与k均值、LVQ用原型向量来刻画聚类结构不同,高斯混合聚类采用概率模型来表达聚类原型。
多元高斯分布的定义,对n维样本空间X中的随机向量x,若x服从高斯分布,其概率密度函数为: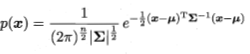
(此部分内容待续)
9.5 密度聚类
密度聚类亦称“基于密度的聚类”,此类算法假设聚类结构能够通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断拓展聚类簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算发,他基于一组“邻域”参数来刻画样本分布的紧密程度。DBSCAN先发现密度较高的点,然后把相近的高密度点逐步连成一片,进而生成各种簇。
ε-邻域:对xj属于D,其ε-邻域包含样本集D中与xj距离不大于ε的样本,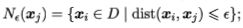
核心对象:若xj的ε-邻域至少包含MinPts个样本,即 ,则xj是一个核心对象;(MinPts为密度阈值)
,则xj是一个核心对象;(MinPts为密度阈值)
密度直达:若xj位于xi的ε-邻域中,且xi是核心对象,则称xj由xi密度直达。
密度可达:对xi与xj,若存在样本序列p1,p2,...,pn,其中p1=xi,pn=xj且pi+1由pi密度直达,则称xj由xi密度可达;
密度相连:对xi与xj,若存在xk使得xi与xj均由xk密度可达,则称xi与xj密度相连。
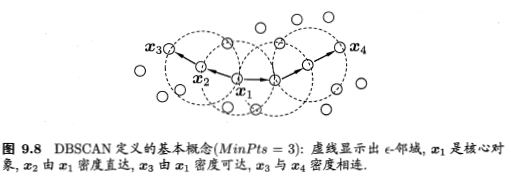
DBSCAN将“簇”定义为:由密度可达关系导出的最大的密度相连样本集合。
D中不属于任何簇的样本被认为是噪声或异常样本。
DBSCAN是靠不断连接邻域内高密度点来发现簇的,只需要定义邻域大小和密度阈值,因此可以发现不用形状不同大小的簇。

算法实现:对每个数据点为圆心,以邻域为半径画圈,然后数有多少个点,在这个圈内,这个数就是点密度值,然后选取一个点密度阈值MinPts,圈内点数小于MinPts为低密度点,大于或等于MinPtsede的为高密度点(称为核心点或核心对象)如果有一个高密度的点在另一个高密度点的圈内,我们就把这两个点连接起来,这样就可以把好多点不断串联起来。如果有低密度的点也在高密度点的圈内,把它也连到最近的高密度点上,称之为边界点。
9.6 层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构,数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。即凝聚式层次聚类:在初始阶段将每个店都视为一个簇,之后合并两个最接近的簇,直到最后只剩一个簇;分裂式层次聚类:在初始阶段将所有点视为一个点,之后每分裂出一个簇,直到最后剩下单个点的簇。
AGNES是一种采用自底向上聚合策略的层次聚类算法,他先将数据集中的每个样本看做一个初始聚类簇,然后在算法运行的每一步找出距离最近的两个聚类簇进行合并,该过程不断重读,直到达到预设的聚类簇个数。这里关键是素和计算聚类簇之间得距离,实际上,每个簇是一个样本集合,因此,只需要采用关于集合的某种距离即可。
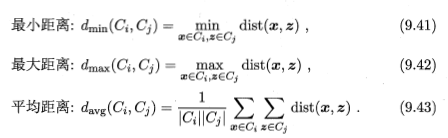
显然,最小距离由簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则有两个簇的所有样本共同决定。

算法步骤:1.初始化,将每个样本都视为一个簇;(2)计算各簇之间的距离;(3)寻找最近的两个簇,并将他们并为一类;(4)重复步骤2,3,直到所有样本归为一类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号