爬虫基础知识
技术选型
scrap vs requests+ beautifulsoup 1. requests和 beautifulsoup都是库, scrap是框架 2. scrap框架中可以加入 requests和 beautifulsoup 3. scrap基于 twisted,性能是最大的优势 4. scrap方便扩展,提供了很多内置的功能 5. scrap内置的css和 xpath selector非常方便, beautifulsoup最大的缺 点就是慢
网页分类
常见类型的服务
1.静态网页
2.动态网页
3. webservice(restapi)
爬虫能做什么
爬虫作用 1.搜索引擎-百度、 google、垂直领域搜索引擎 2.推荐引擎--今日头条 3.机器学习的数据样本 4.数据分析(如金融数据分析)、舆情分析等
正则表达式
正则表达式介绍:
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
目录
1.特殊字符
1)^ $ * ? + {2} {2,} {25}
2)[^] [a-z]
3)s S \W \W
4)Nu4E00-\u9FA5]0 \d
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
正则表达式的简单应用及 python示例:
1 import re
2 line = "XX出生于2001年6月
3 # Line = "XXX出生于2001/6/1
4 # Line = "XXX出生于2001-6-1
5 # Line = "XXX出生于2001-66-01
6 # Line = "XXX出生于2001-06”I
7
8 regex_str = ".*出生于(\d{4}[年/-]\d{1,2}([月/-]\d{1,2}|[月/-]$|$))"
9 match obj = re match(regex_str, line)
10 if match obj:
11 print(match_obj. group (1))
深度优先和广度优先
目录 1.网站的树结构
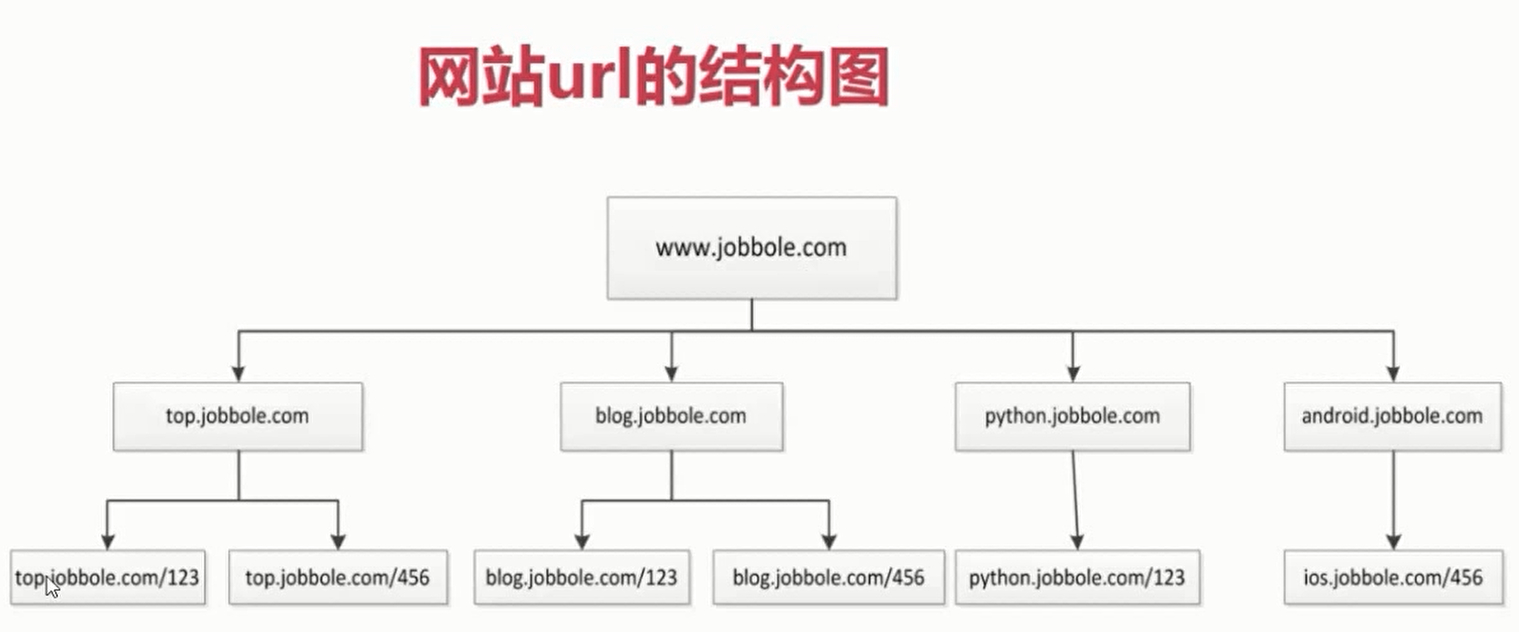
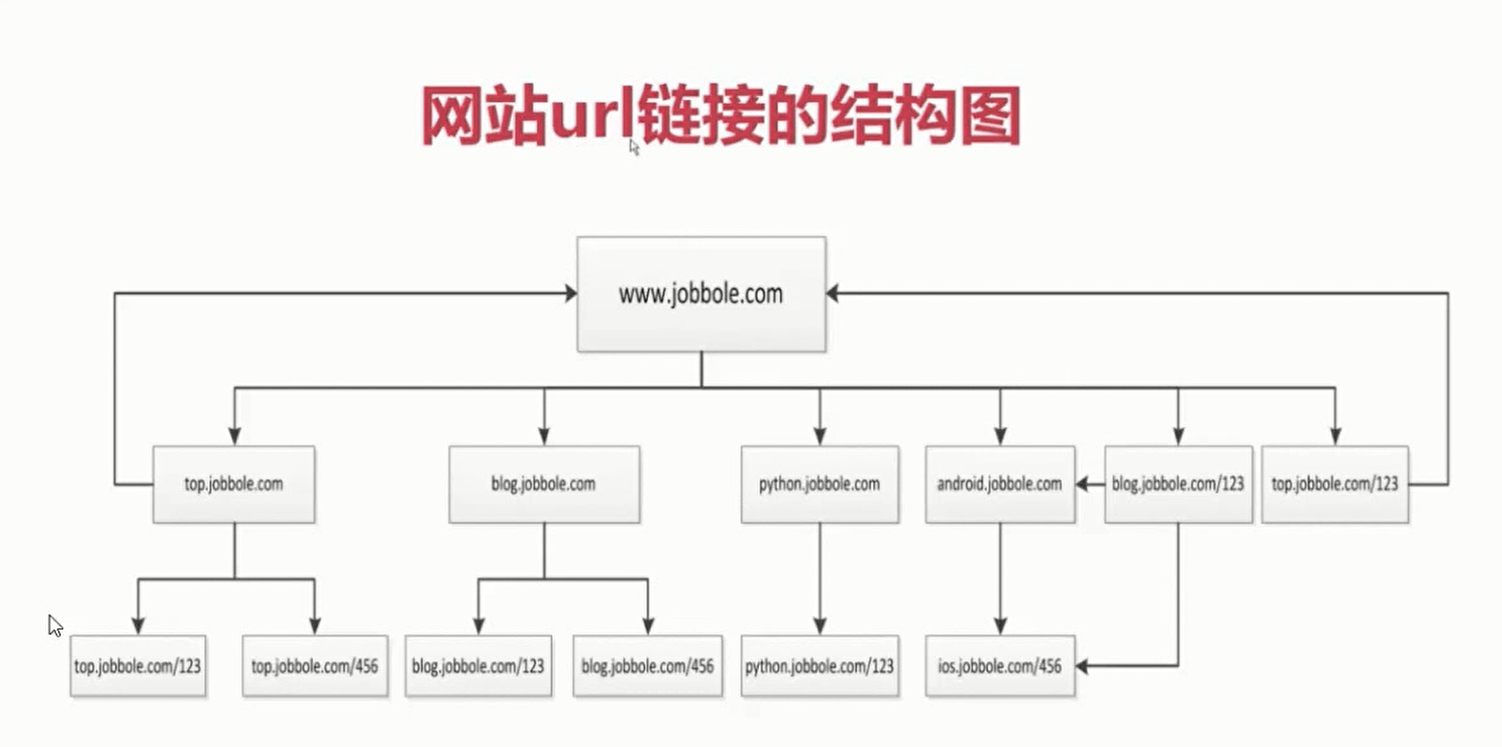
备注;由于每一个网站的子url下都会附带一些其他目录下的url,所以导致爬取产生环路,一般需要去重。
深度优先与广度优先算法
1.深度优先遍历(DFS)
(1)从某个顶点V出发,访问顶点并标记为已访问
(2)访问V的邻接点,如果没有访问过,访问该顶点并标记为已访问,然后再访问该顶点的邻接点,递归执行
如果该顶点已访问过,退回上一个顶点,再检查该顶点的邻接点是否都被访问过,如果有没有访问过的继续向下访问,如果全部都访问过继续退回到上一个顶点,继续同样的步骤。
深度优先遍历类似于树的先序遍历,深度优先遍历算法结果不唯一。
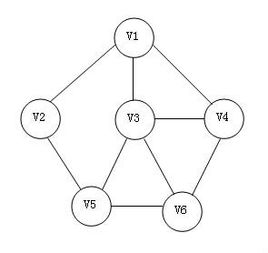
选择V1为出发点,访问V1,然后访问V1的邻接点,邻接点有V2 V3和V4,假设都从左边的邻接点开始访问
访问V1的最左边的邻接点V2,访问V2的邻接点V5
访问V5的邻接点V3,V3的左边邻接点是V1,V1已经访问过,所以访问V4
V4的左边邻接点V6,访问V6,V6的所有邻接点都已访问过,退回V4,V4的所有邻接点也都访问过退回V3,V3的邻接点全部访问过退回V5,
V5的邻接点全部访问过退回V2,V2的邻接点全部访问过退回到出发点V1,V1的全部邻接点访问过,遍历结束。
遍历序列为V1→V2→V5→V3→V4→V6
2.广度优先遍历(BFS)
(1)从某个顶点V出发,访问该顶点的所有邻接点V1,V2..VN
(2)从邻接点V1,V2...VN出发,再访问他们各自的所有邻接点
(3)重复上述步骤,直到所有的顶点都被访问过
(1)从顶点V1出发,v1入队,访问V1,V1的邻接点有V2 V3 V4,将它们入队,v1出队
队列:V2 V3 V4
(2)访问队头V2,V2的邻接点为V1(已访问过,忽略)和V5,将V5入队,V2出队
队列:V3 V4 V5
(3)访问V3,V3的邻接点为V1(访问过忽略) V4(已在队列忽略) V6 V5(已在队列,忽略),V6入队,V3出队
队列:V4 V5 V6
......
简单应用及 python示例:
深度优先:
1 def depth tree(tree node ):
2 if tree node is not none
3 print (tree node. data)
4 if tree node, left is not none:
5 return depth tree(tree node. left)
6 if tree node. right is not None:
7 return depth tree(tree node, right)
广度优先:
1 def level queue(root )
2 ”利用队列实现树的广度优先遍历”
3 if root is None:
4 return
5 my_ queue =[]
6 node = root
7 my_queue append(node)
8 while my queue:
9 node my queue. pop(o)
10 print(node elem)
11 if node lchild is not None
12 my_queue append(node lchild)
13 if node rchild is not None
14 my queue append ( node rchild)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号