
在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态(-128~127),这被称为一个字节(byte)。
也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111
字符集与字符编码
字符集:定义了文字和二进制的对应关系,为字符分配了唯一的编号,常见的 ASCII字符集,GB2312字符集,Unicode字符集
字符编码:规定了如何将文字的编号存储到内存中,本质就是如何使用二进制字节来表示字符
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的;有的字符集只管制定字符的编号,至于怎么编码,是其他人的事情
说起字符集的发展历程,可以总结为一句话:几乎都是对ASCII字符集的扩展。
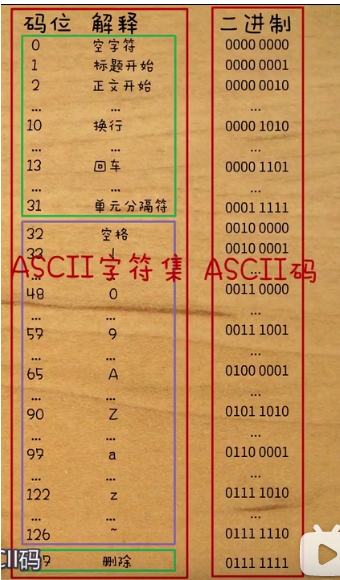
ASCLL字符集 ASCLL编码
美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。
这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
ASCII码用了1个字节,1个字节可以表示256种状态,但ASCII码只用了128种,也就是一个字节的后七位,最前面的1位都是0
可见字符/可打印字符:字母 数字和标点符号:32~126这95个字符。网络传输只能传输这95个字符,不在这个范围内的字符无法传输
控制字符:肉眼不可见的,但是能对文本进行控制的字符: 0~31、127这33个字符
base编码
ASCII 是用128(2^8)个字符,对二进制数据进行编码的方式,
base64 编码是用64(2^6)个字符,对二进制数据进行编码的方式
base32 编码就是用32(2^5)个字符,对二进制数据进行编码的方式
base16 编码就是用16(2^4)个字符,对二进制数据进行编码的方式
base系列编码之间的不同,在于用于编码的字符数量的多少
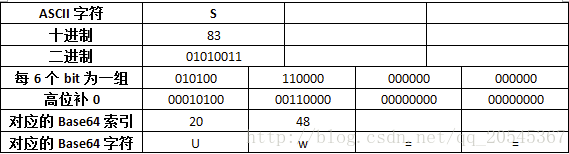
base64码表
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
另有“=”符号作为填充
使用64个可打印字符来表示二进制数据的方法

- Base64一般用于在HTTP协议下传输二进制数据,由于HTTP协议是文本协议,所以在HTTP协议下传输二进制数据需要将二进制数据转换为字符数据。然而直接转换是不行的。因为网络传输只能传输可打印字符。
- base64加密:在email传输中,加密是肯定的,但是base64加密的目的不是让用户发送非常安全的Email。这种加密方式主要就是“防君子不防小人”,达到一种一眼看上去看不出内容的效果。
- base64编码是用来解决把不可打印的内容塞进可打印内容的需求的。比如把图片存到数据库,图片数据归根到底还是一堆二进制串(总不能把这些二进制串直接存到数据库吧),用base64编码后的显示成的字符串就大大缩小的长度,可以存到数据库。
- 满足电子邮件中不能直接使用非ASCII码字符传输数据的规定,所以使用base64进行编码后传输,因为base64的64个字符肯定有对应的ascii编码。
UniCode是一个字符集
Javascript程序是使用Unicode字符集,Javascript源码文本通常是基于UTF-8编码。
但JS代码中的字符串类型是UTF-16编码的,这也是为什么会碰到api接口返回字符串在前端出现乱码,因为多数后台服务都使用utf-8编码,前后编码方式不一致。
诞生目的:把世界上所有的字符都放在一起用32位,即4个字节来表示一个字符,基本上涵盖世界上所有的字符了
Unicode规定了符号的二进制代码。这个二进制代码应该如何存储:可以使用的编码有三种,分别是:
UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号